贝壳基于 Flink 的实时计算演进之路
简介: 贝壳找房在实时计算之路上的平台建设以及实时数仓应用。
摘要:贝壳找房大数据平台实时计算负责人刘力云带来的分享内容是贝壳找房的实时计算演进之路,内容如下:
- 发展历程
- 平台建设
- 实时数仓及其应用场景
- 事件驱动场景
- 未来规划
GitHub 地址
https://github.com/apache/flink
欢迎大家给 Flink 点赞送 star~
一、发展历程
首先是平台的发展历程。最早是因为业务方在实时计算方面有比较多的业务场景,包括业务方自研的实时任务,需要自行开发、部署及维护,我们的大数据部门也会承接客户大数据的实时开发需求。
这些看起来都是一些烟囱式的开发架构(即每个业务线之间由不同的开发团队独立建设,技术栈不同,互不联系),缺乏统一的任务管控,也很难保留开发过程中积累的技术沉淀。因此,我们在 18 年时上线了基于 Spark Streaming 的实时计算平台,统一部署管理实时计算任务。之后我们又在此基础上提供了任务开发功能 - 标准化的 SQL 语言(SQL 1.0),以提高数据开发效率。
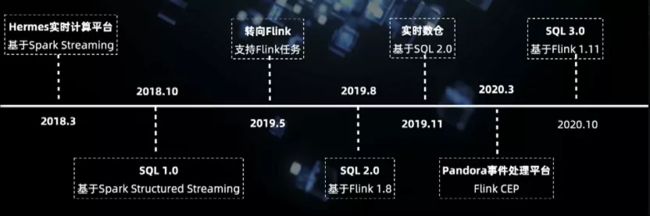
随着我们承接的任务越来越多,我们也发现了 Spark Streaming 的一些使用问题,主要是其 Checkpoint 是同步的,有时会造成比较大的延迟。此外,Kafka 消费的 Offset 数据存在 Checkpoint,很难做到任务细粒度的监控,比如消费状态的获取,于是我们开始转向 Flink。
19 年,我们的平台开始支持 Flink 任务,并且很快提供了基于 Flink 1.8 的 SQL 2.0 功能,包括 DDL 定义和维表关联。接下来,在 SQL 2.0 的基础上,我们开始了实时数仓的建设。
今年初,在收集了业务方的需求场景后,我们认为在实时事件处理方面需求明确,而且目前的实现也存在较多的弊端,因此我们开始着手事件处理平台的开发。今年发布的 Flink 1.11 在 SQL 方面有很大的提升,我们在其基础上正在开发一套统一的 SQL(3.0)。
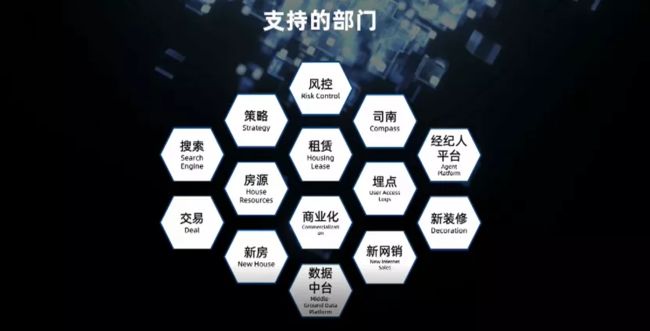
目前平台支持的部门涵盖了贝壳绝大部分的业务方,支持各种场景,包括人店相关的房源、客源、经纪人、风控以及运营等。

目前平台支持的项目有 30 多个。在 SQL2.0 后,平台上的任务数有明显增长,达到 800 多个。由于贝壳所有的流量数据、用户行为分析、以及数仓的建设都是通过平台来构建的,所以数据量很大,每天处理的消息达 2500 亿条,单任务的消息吞吐量峰值达 3 百万。
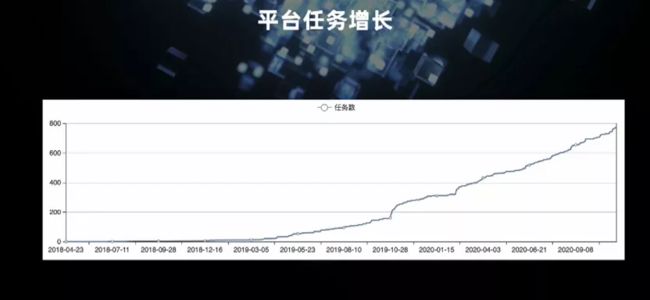
这是我们平台任务的增长情况,可以明显看到 19 年 10 月 SQL 2.0 上线且支持实时数仓开发后,任务增长势头显著。
二、平台建设

平台的功能概览包括四个方面:
- 支持任务托管的基本能力,包括任务的编辑发布、版本管理、监控报警等;
- 支持多种语言的实时任务,包括对贝壳算法相关的 Python 实时任务的良好支持;
- 根据业务场景不同,支持多种业务类型,如自定义任务、模板任务及场景任务(SQL 任务),内部通用配置化任务,如分流合并操作。目前 SQL 任务在平台占比较高,我们的目标是 80%;
- 支持公共队列(针对较数据量小的需求),对于数据量大的需求,要有稳定的资源保证,我们可以提供专有队列,运行更为可靠。

平台的整体架构与其它公司的差不多。底层是计算和存储层,计算支持 Flink 和 Spark,主要包括消息队列和各种 OLAP 存储,同时也支持 MySQL,Hive 也可以做到实时落地,维表支持 Redis,HBase 存储。ClickHouse 是目前主要的实时 OLAP 存储,由于 Doris 支持 update,同时对关联查询的支持也比较好,我们也在尝试 Doris 存储。
引擎层主要封装的是 SQL 引擎、DataStream 的通用性操作。在事件处理方面,对 Flink 的 CEP,包括对其它普通规则也做了较好的封装。
开发管理层提供了各种任务的开发、监控和资源管理。
平台之上,也是提供了对 ETL、BI、推荐、监控、风控等各种业务场景的支持。
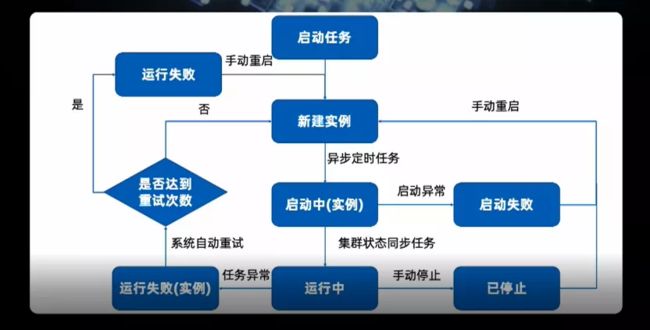
这是平台任务生命周期的管理。可以看到,在启动后会新建实例,从集群拿到运行状态后会判断是否正常运行。“是”则转成运行中状态。在运行过程中会对任务做延迟和心跳的监控;如果说任务发生了异常,并且在配置中设置了延迟或心跳时长的阈值,则会尝试进行重启。用户可以在启动任务时设置重启次数,当超过该值时,则认为重启失败,将发送告警给任务负责人。
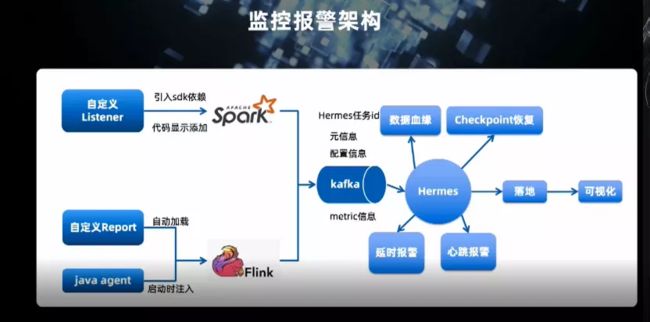
这是平台监控报警的架构。我们在 Spark 引入了 sdk 依赖,在用户开发任务时用代码显示添加就可以监听系统关心的指标。Flink 任务支持自定义 Reporter 的 metrics 的获取。我们还支持 java agent 的依赖注入,通过依赖注入我们可以获取实时任务的制定信息。在 Hermes 平台,我们可以拿到这些监控信息,来支持延时报警、心跳报警、及数据血缘基础上的流量分析,后续的有状态任务恢复也依赖这些监控指标。监控日志落入存储(InfluxDB)之后可以进行可视化处理,方便的查看历史运行状态。

这是平台监控查看页面,分别显示了数据读入、写出、及延时的情况。
三、实时数仓
我们的实时数仓目前具备以下几方面能力:首先是完善的元数据管理,包括连接管理和表管理;数仓开发人员共同构建了数据分层架构,包括 4 个分层:
- 在实时侧,分层越少越好,否则中间环节越多,出问题的概率越大;
- 在 SQL 层面,支持标准的SQL语法,维表关联,提供图形化的SQL开发环境。另外还支持丰富的内置函数,并逐步完善支持用户自定义函数(UDF)的开发;
- 数据血缘方面,平台支持图形化展示和完善的链路分析,而且能实时看到数据流的运行情况并对异常进行标示;
- 最后是多源支持,对公司内部用到的各种存储做到了较好的支持。
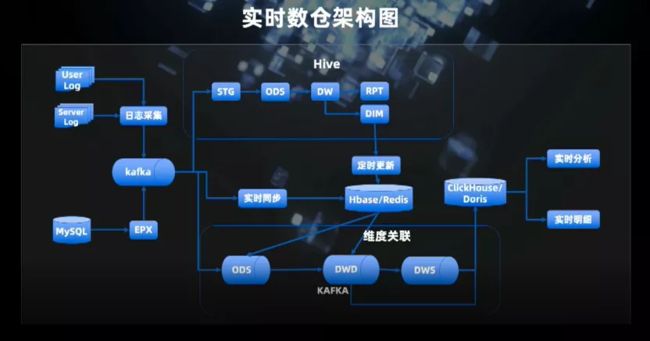
这是简易的实时数仓架构图,总体来说是属于 Lambda 架构,包括实时流和离线流,以及离线流对实时流数据覆盖的修复。从用户行为日志、后端服务器日志及业务数据库采集来的消息流,汇入并通过 ODS(Opertional Data Source)层再到 DW(Data Warehouse)层,我们支持 ODS 和 DW 层对维度进行扩充,关联维表。
目前 DWD(Data Warehouse Detail)层的数据直接送入 ClickHouse,ClickHouse 现在是我们 OLAP 引擎的一个主力存储。从 DWD 到 ClickHouse 的存储只满足了部分业务场景,还存在一些问题。比如我们需要做数据汇总,那么我们现在 DWS(Data Warehouse Service)层在这方面还稍微欠缺。目前明细数据进入了 ClickHouse,我们首先对那些应该汇总的数据存了明细,这样会导致存储量比较大,查询效率较低。后续我们会考虑引入 Doris,因为它可以在实时计算侧做实时聚合,依托 Doris 对 Update 的支持,就可以完善 DWS 功能。
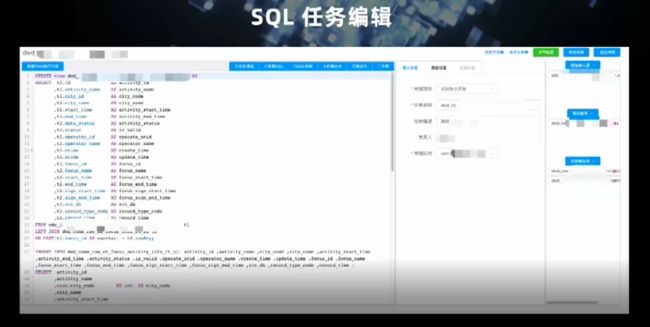
这里展示的是我们的 SQL 编辑器。可以看到左边是正在编辑的 SQL,我们支持 Flink 执行计划的查看、任务调试。右侧一列可以定义源表、维表、输出表。可以在自定义的数据源基础上定义流表,并自动生产 DDL。同时,对于某些自动生成 DDL 难以支持的场景,用户可以在左边的编辑区域自行编写 DDL。
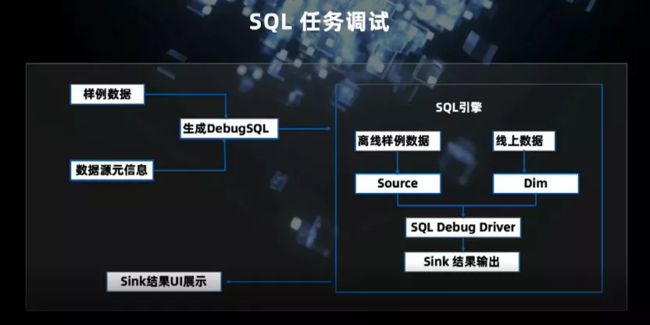
任务调式分为手动和自动两种方式。手动方式需准备样例数据,拷贝到开发界面;自动方式则会从 SQL 任务的上游获取样例数据。元数据信息(kafka、HBase、ClickHouse 等)是动态获得的,元信息和样例共同生成的 DebugSQL 去调用 SQL 引擎的公共服务。SQL 引擎得到样例数据后,比如,如果有关联维表的操作,则会关联线上维表,在 SQL 引擎中执行调试,将结果送给 UI 端进行展示。
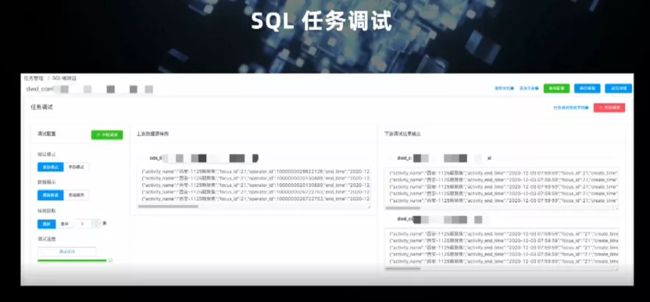
这是一个完整的调试界面,可以看到左侧是自动获取的样例数据,右侧是下游的输出。
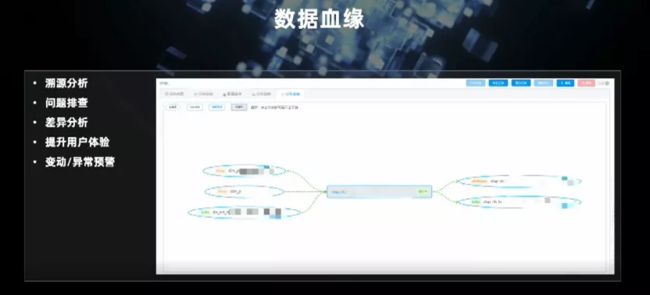
根据元数据的定义及上报的指标等监控数据,我们可以生成一个实时数据血缘链路。图中的箭头展示了数据流转的健康状况,未来会对血缘链路上的数据监控做得更细致。数据血缘满足了 4 个方面的需求:溯源分析、问题排查、数据差异分析、提升用户体验。在血缘链路上还可以进行比较复杂的异常预警,例如,数据源字段的变更对下游的影响。
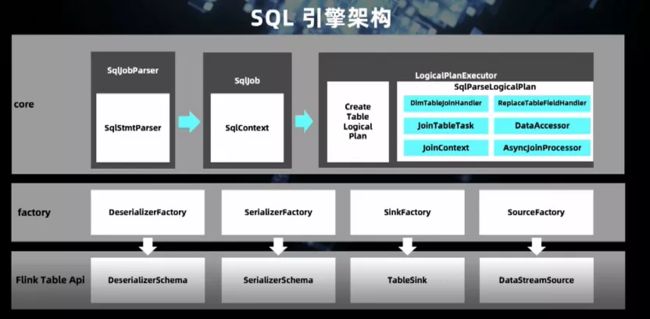
这是我们 SQL2.0 引擎的大致架构,通过 Antlr4 扩展标准 SQL 的语法,从而支持 Flink 的各种源,维表和下游存储表的定义。通过 SqljobParser 内置的 SqlStmtParser 生成 SqlContext,在逻辑计划(Logical Plan)中做解析。如果遇到维表,则经过一系列维表关联的流程。上图中下半部分是底层 API 架构。
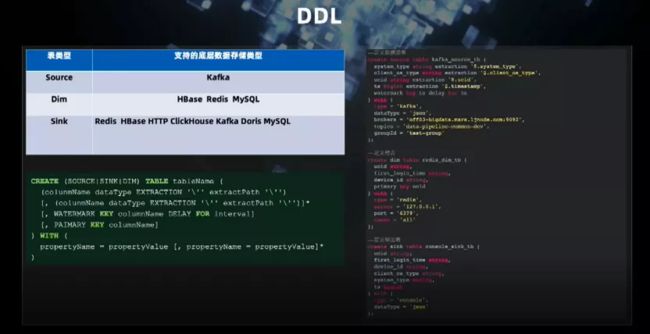
这是平台 DDL 样例。对于源表(Source),支持 Kafka,未来在新版本的 Flink 之上将可以支持更多种源。对于维表(Dim),支持 HBase、Redis、MySQL。数据存储表(Sink)支持图中所列五种。表格下面的是 DDL 定义的语法规则,右边是一些表定义的样例,分别是 Kafka 源表、维表和输出表(输出到控制台)。
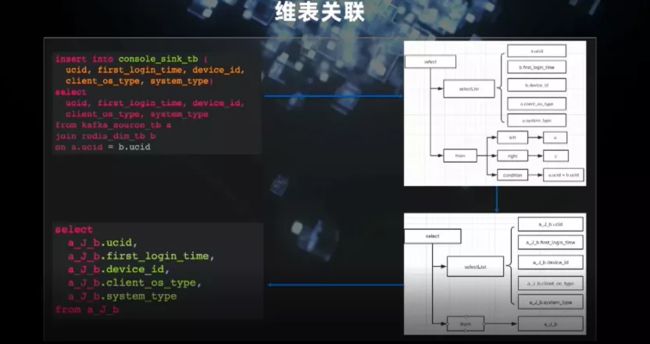
再看我们的维表关联,从 SQL 引擎结构可以看出,输入的 SQL 进行解析,当有维表关联时(包含 join 字段),我们会从语法层面做转换。我们在表的层面定义了流和维关联之后的表的形态,左下角是其生成过程。关联维表、流维转换、用异步 IO 获取数据等过程不在这里细说。
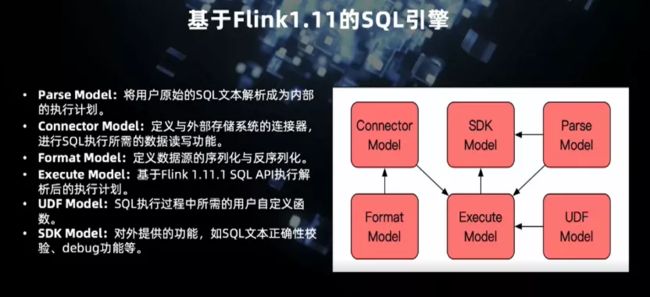
随着 Flink 社区新版本的发布,在 SQL 方面的支持越来越强,我们目前正在做基于 Flink1.11 的新版 SQL 引擎,也会将之前的 SQL 引擎统一。因为 Flink1.11 支持DDL,所以这部分我们不会再做,而是直接使用其新特性:
- 解析模块(Parse Model)将用户原始的 SQL 解析成内部的执行计划,完全依赖于 Flink SQL。Connector Model 完成目前 Flink 尚未支持的 Connector 开发。
- Format Model 实现数据源字段的序列化和反序列化。
- 执行模块(Execute Model)基于 Flink1.11 SQL API 执行解析后的执行计划。
- UDF 模块是专门处理 UDF 的解析,如参数调用的合法验证、权限验证、细致的数据权限限制。
- SDK Model 是对外提供的标准化服务,如 SQL 文本开发的验证,debug 功能等。

客户实时热力图是我们正在跟业务方沟通的一个需求场景,能实时获取用户线上的行为,使经纪人对客户行为有一个比较全面的实时掌控,促进客户维护的转化率。另一方面,也使客户更方便地了解房源热度状态,促使用户做出购买决策。
四、事件驱动

先了解一下事件驱动型和数据分析型的区别:
- 事件驱动是根据事件流中的事件实时触发外部计算和外部状态的更新,主要关注实时事件触发的外部变化,重在单独事件以及外部动作的触发。
- 数据分析型主要是从原始数据中提取有价值的信息,重在分析。

在我们跟业务方的沟通过程中,我们发现很多场景中他们希望实时获取用户的行为。比较典型的是风控场景,根据用户线上的行为模式判断其是否触发风控规则。此外,我们的实时运营,根据用户线上行为给用户进行积分的增加及信息推送。搜索推荐也是我们非常关心的,即用户在搜索之前的实时行为。综合这些,我们提取出三方面问题:
- 一是用户行为事件缺乏统一的抽象和管理,开发效率低,周期长,各部门存在重复建设;
- 二是规则逻辑与业务系统是耦合的,难以实现灵活的变化,对于复杂的规则或场景,业务方缺乏相关的技能和知识储备,如对 CEP 的支持;
- 第三是缺乏统一的下游动作触发的配置。
基于以上三个痛点,我们构建了事件处理平台,抽象成三个模块,事件管理,规则引擎和动作触发。
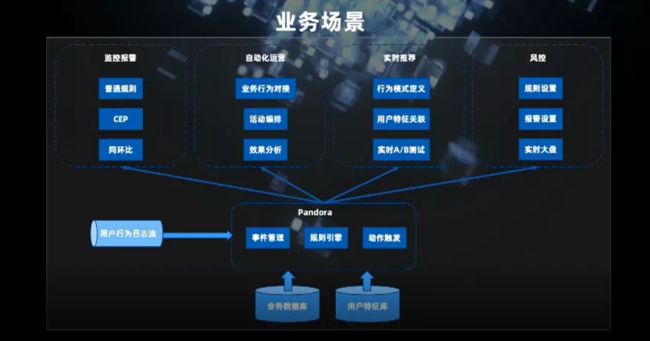
这是事件处理平台所支持的业务场景。
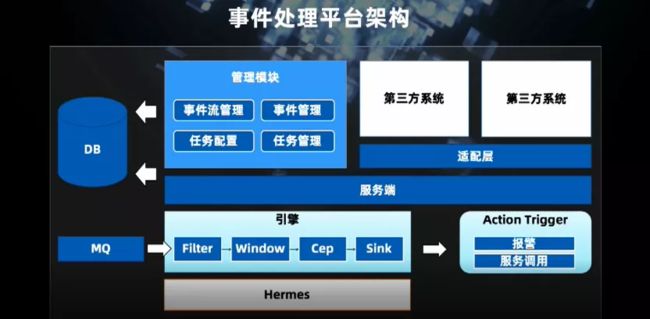
这是事件处理平台的架构,总体来说就是管理模块,引擎和动作触发。在中间这里我们提供了一个适配层,可以跟第三方系统进行集成。
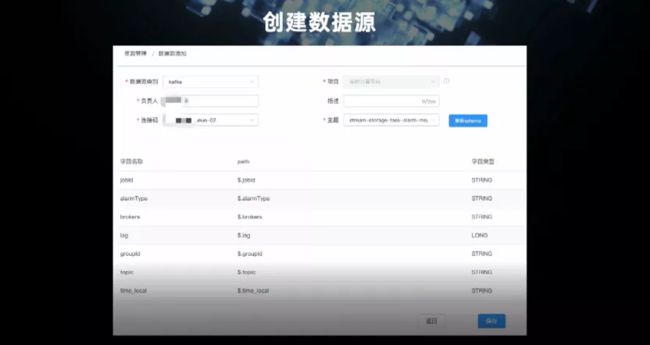
这是我们事件处理的操作流程,首先是创建数据源,与实时计算平台类似,主要支持 Kafka,在 Kafka 消息流上定义我们的数据格式。
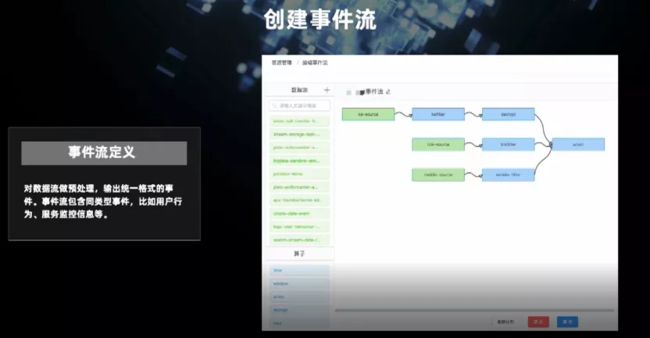
在数据源基础上创建事件流,事件流包含了同类事件,我们实现了一些算子,可以在数据源的基础上做一些操作。从右侧可以看到,在多个数据源上进行了一些过滤、加解密的操作,最终通过 union 算子汇总成一个统一格式的同类事件的事件流,方便后续使用。
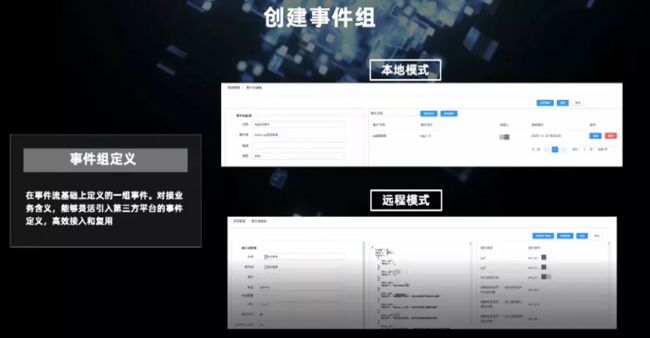
在事件流的基础上可以定义单个的事件,之后可以创建事件组,以对接我们的业务含义,即明确具体的业务是做什么的,如用户的点击、浏览、分享、关注等事件。创建事件组有两种方式:
- 一是本地方式,即可以根据事件的各个字段和维度设定条件;
- 二是远程方式,这与我们的埋点系统(用户行为日志)直接连通,可以直接得到用户事件的定义。
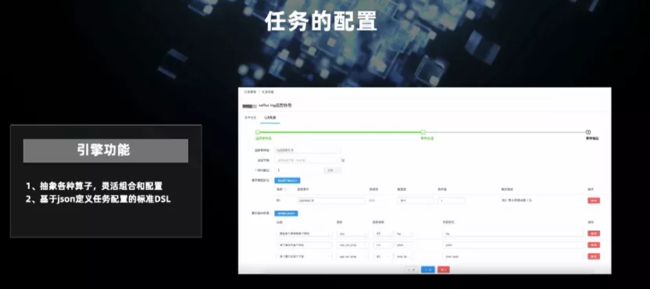
任务配置过程分几个部分,这是 log 监控的任务样例。上图展示的是事件处理的规则设置部分。这是一个 CEP 事件,可以定义事件窗口,获取具体事件,在此之上定义 CEP 的模式,还可以定义事件的输出,例如需要输出哪些字段。
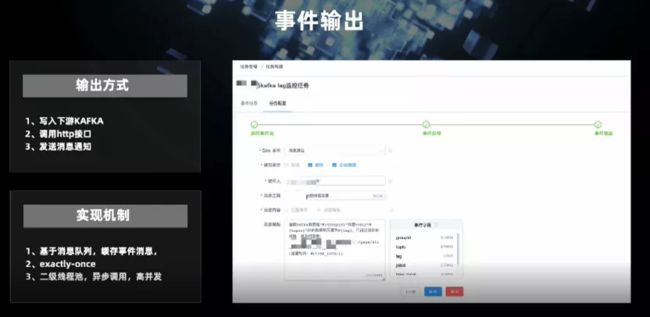
这是触发动作调用,支持消息发送,服务调用及落地 Kafka。截图展示的是消息发送的样例。
五、未来规划
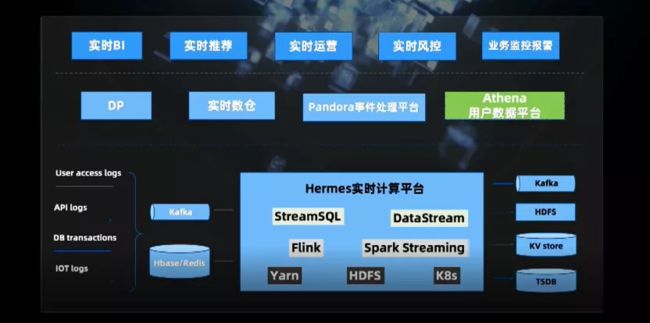
这是我们实时计算的整体架构,下部是 Hermes 实时计算平台,主要包括任务管控、SQL 引擎、CEP 引擎等各种能力。Data Pipeline、实时数仓及事件处理平台的任务都是通过此平台进行管控。未来我们计划做的是用户数据平台,如各业务方对用户的线上行为的历史查询,以及在全平台用户数据的综合分析。
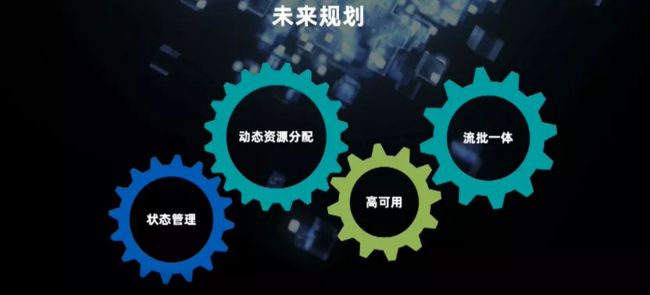
对未来的规划主要有以上几个方向,包括状态的管理及恢复、动态的资源分配(动态的配置、动态的资源调整)。为了保持任务的稳定性,我们在也计划在高可用性方面做一些调研。在流批一体方面,会借用数据湖的能力,提供对历史和实时数据的混合查询的支持。
原文链接
本文为阿里云原创内容,未经允许不得转载。