Go语言并发与并行
首先,并行!=并发, 两者是不同的
Go语言的goroutines、信道和死锁
goroutine
Go语言中有个概念叫做goroutine, 这类似我们熟知的线程,但是更轻。
以下的程序,我们串行地去执行两次loop函数:
func loop() {
for i := 0; i < 10; i++ {
fmt.Printf("%d ", i)
}
}
func main() {
loop()
loop()
}毫无疑问,输出会是这样的:
0 1 2 3 4 5 6 7 8 9 0 1 2 3 4 5 6 7 8 9下面我们把一个loop放在一个goroutine里跑,我们可以使用关键字go来定义并启动一个goroutine:
func main() {
go loop() // 启动一个goroutine
loop()
}这次的输出变成了:
0 1 2 3 4 5 6 7 8 9可是为什么只输出了一趟呢?明明我们主线跑了一趟,也开了一个goroutine来跑一趟啊。
原来,在goroutine还没来得及跑loop的时候,主函数已经退出了。
main函数退出地太快了,我们要想办法阻止它过早地退出,一个办法是让main等待一下:
func main() {
go loop()
loop()
time.Sleep(time.Second) // 停顿一秒
}这次确实输出了两趟,目的达到了。
可是采用等待的办法并不好,如果goroutine在结束的时候,告诉下主线说“Hey, 我要跑完了!”就好了, 即所谓阻塞主线的办法,回忆下我们Python里面等待所有线程执行完毕的写法:
for thread in threads:
thread.join()是的,我们也需要一个类似join的东西来阻塞住主线。那就是信道
信道
信道是什么?简单说,是goroutine之间互相通讯的东西。类似我们Unix上的管道(可以在进程间传递消息), 用来goroutine之间发消息和接收消息。其实,就是在做goroutine之间的内存共享。
使用make来建立一个信道:那如何向信道存消息和取消息呢? 一个例子:
func main() {
var messages chan string = make(chan string)
go func(message string) {
messages <- message // 存消息
}("Ping!")
fmt.Println(<-messages) // 取消息
}默认的,信道的存消息和取消息都是阻塞的 (叫做无缓冲的信道,不过缓冲这个概念稍后了解,先说阻塞的问题)。
也就是说, 无缓冲的信道在取消息和存消息的时候都会挂起当前的goroutine,除非另一端已经准备好。
比如以下的main函数和foo函数:
var ch chan int = make(chan int)
func foo() {
ch <- 0 // 向ch中加数据,如果没有其他goroutine来取走这个数据,那么挂起foo, 直到main函数把0这个数据拿走
}
func main() {
go foo()
<- ch // 从ch取数据,如果ch中还没放数据,那就挂起main线,直到foo函数中放数据为止
}- 那既然信道可以阻塞当前的goroutine, 那么回到上一部分「goroutine」所遇到的问题「如何让goroutine告诉主线我执行完毕了」 的问题来, 使用一个信道来告诉主线即可:
var complete chan int = make(chan int)
func loop() {
for i := 0; i < 10; i++ {
fmt.Printf("%d ", i)
}
complete <- 0 // 执行完毕了,发个消息
}
func main() {
go loop()
<- complete // 直到线程跑完, 取到消息. main在此阻塞住
}如果不用信道来阻塞主线的话,主线就会过早跑完,loop线都没有机会执行、、、
其实,无缓冲的信道永远不会存储数据,只负责数据的流通,为什么这么讲呢?
-
从无缓冲信道取数据,必须要有数据流进来才可以,否则当前线阻塞
-
数据流入无缓冲信道, 如果没有其他goroutine来拿走这个数据,那么当前线阻塞
所以,你可以测试下,无论如何,我们测试到的无缓冲信道的大小都是0 (len(channel))
如果信道正有数据在流动,我们还要加入数据,或者信道干涩,我们一直向无数据流入的空信道取数据呢? 就会引起死锁
死锁
一个死锁的例子:
func main() {
ch := make(chan int)
<- ch // 阻塞main goroutine, 信道c被锁
}执行这个程序你会看到Go报这样的错误:
fatal error: all goroutines are asleep - deadlock!何谓死锁? 操作系统有讲过的,所有的线程或进程都在等待资源的释放。如上的程序中, 只有一个goroutine, 所以当你向里面加数据或者存数据的话,都会锁死信道, 并且阻塞当前 goroutine, 也就是所有的goroutine(其实就main线一个)都在等待信道的开放(没人拿走数据信道是不会开放的),也就是死锁咯。
我发现死锁是一个很有意思的话题,这里有几个死锁的例子:
1.只在单一的goroutine里操作无缓冲信道,一定死锁。比如你只在main函数里操作信道:
func main() {
ch := make(chan int)
ch <- 1 // 1流入信道,堵塞当前线, 没人取走数据信道不会打开
fmt.Println("This line code wont run") //在此行执行之前Go就会报死锁
}2.如下也是一个死锁的例子:
var ch1 chan int = make(chan int)
var ch2 chan int = make(chan int)
func say(s string) {
fmt.Println(s)
ch1 <- <- ch2 // ch1 等待 ch2流出的数据
}
func main() {
go say("hello")
<- ch1 // 堵塞主线
}其中主线等ch1中的数据流出,ch1等ch2的数据流出,但是ch2等待数据流入,两个goroutine都在等,也就是死锁。
其实,总结来看,为什么会死锁?非缓冲信道上如果发生了流入无流出,或者流出无流入,也就导致了死锁。或者这样理解 Go启动的所有goroutine里的非缓冲信道一定要一个线里存数据,一个线里取数据,要成对才行 。所以下面的示例一定死锁:
c, quit := make(chan int), make(chan int)
go func() {
c <- 1 // c通道的数据没有被其他goroutine读取走,堵塞当前goroutine
quit <- 0 // quit始终没有办法写入数据
}()
<- quit // quit 等待数据的写仔细分析的话,是由于:主线等待quit信道的数据流出,quit等待数据写入,而func被c通道堵塞,所有goroutine都在等,所以死锁。
简单来看的话,一共两个线,func线中流入c通道的数据并没有在main线中流出,肯定死锁。
但是,是否果真 所有不成对向信道存取数据的情况都是死锁?
如下是个反例:
func main() {
c := make(chan int)
go func() {
c <- 1
}()
}程序正常退出了,很简单,并不是我们那个总结不起作用了,还是因为一个让人很囧的原因,main又没等待其它goroutine,自己先跑完了, 所以没有数据流入c信道,一共执行了一个goroutine, 并且没有发生阻塞,所以没有死锁错误。
那么死锁的解决办法呢?
最简单的,把没取走的数据取走,没放入的数据放入, 因为无缓冲信道不能承载数据,那么就赶紧拿走!
具体来讲,就死锁例子3中的情况,可以这么避免死锁:
c, quit := make(chan int), make(chan int)
go func() {
c <- 1
quit <- 0
}()
<- c // 取走c的数据!
<-quit
另一个解决办法是缓冲信道, 即设置c有一个数据的缓冲大小:
c := make(chan int, 1)这样的话,c可以缓存一个数据。也就是说,放入一个数据,c并不会挂起当前线, 再放一个才会挂起当前线直到第一个数据被其他goroutine取走, 也就是只阻塞在容量一定的时候,不达容量不阻塞。
这十分类似我们Python中的队列Queue不是吗?
无缓冲信道的数据进出顺序
我们已经知道,无缓冲信道从不存储数据,流入的数据必须要流出才可以。
观察以下的程序:
var ch chan int = make(chan int)
func foo(id int) { //id: 这个routine的标号
ch <- id
}
func main() {
// 开启5个routine
for i := 0; i < 5; i++ {
go foo(i)
}
// 取出信道中的数据
for i := 0; i < 5; i++ {
fmt.Print(<- ch)
}
}我们开了5个goroutine,然后又依次取数据。其实整个的执行过程细分的话,5个线的数据 依次流过信道ch, main打印之, 而宏观上我们看到的即 无缓冲信道的数据是先到先出,但是 无缓冲信道并不存储数据,只负责数据的流通
缓冲信道
终于到了这个话题了, 其实缓存信道用英文来讲更为达意: buffered channel.
缓冲这个词意思是,缓冲信道不仅可以流通数据,还可以缓存数据。它是有容量的,存入一个数据的话 , 可以先放在信道里,不必阻塞当前线而等待该数据取走。
当缓冲信道达到满的状态的时候,就会表现出阻塞了,因为这时再也不能承载更多的数据了,「你们必须把 数据拿走,才可以流入数据」。
在声明一个信道的时候,我们给make以第二个参数来指明它的容量(默认为0,即无缓冲):
var ch chan int = make(chan int, 2) // 写入2个元素都不会阻塞当前goroutine, 存储个数达到2的时候会阻塞如下的例子,缓冲信道ch可以无缓冲的流入3个元素:
func main() {
ch := make(chan int, 3)
ch <- 1
ch <- 2
ch <- 3
}如果你再试图流入一个数据的话,信道ch会阻塞main线, 报死锁。
也就是说,缓冲信道会在满容量的时候加锁。
其实,缓冲信道是先进先出的,我们可以把缓冲信道看作为一个线程安全的队列:
func main() {
ch := make(chan int, 3)
ch <- 1
ch <- 2
ch <- 3
fmt.Println(<-ch) // 1
fmt.Println(<-ch) // 2
fmt.Println(<-ch) // 3
}信道数据读取和信道关闭
你也许发现,上面的代码一个一个地去读取信道简直太费事了,Go语言允许我们使用range来读取信道:
func main() {
ch := make(chan int, 3)
ch <- 1
ch <- 2
ch <- 3
for v := range ch {
fmt.Println(v)
}
}如果你执行了上面的代码,会报死锁错误的,原因是range不等到信道关闭是不会结束读取的。也就是如果 缓冲信道干涸了,那么range就会阻塞当前goroutine, 所以死锁咯。
那么,我们试着避免这种情况,比较容易想到的是读到信道为空的时候就结束读取:
ch := make(chan int, 3)
ch <- 1
ch <- 2
ch <- 3
for v := range ch {
fmt.Println(v)
if len(ch) <= 0 { // 如果现有数据量为0,跳出循环
break
}
}以上的方法是可以正常输出的,但是注意检查信道大小的方法不能在信道存取都在发生的时候用于取出所有数据,这个例子 是因为我们只在ch中存了数据,现在一个一个往外取,信道大小是递减的。
另一个方式是显式地关闭信道:
ch := make(chan int, 3)
ch <- 1
ch <- 2
ch <- 3
// 显式地关闭信道
close(ch)
for v := range ch {
fmt.Println(v)
}被关闭的信道会禁止数据流入, 是只读的。我们仍然可以从关闭的信道中取出数据,但是不能再写入数据了。
等待多gorountine的方案
那好,我们回到最初的一个问题,使用信道堵塞主线,等待开出去的所有goroutine跑完。
这是一个模型,开出很多小goroutine, 它们各自跑各自的,最后跑完了向主线报告。
我们讨论如下2个版本的方案:
-
只使用单个无缓冲信道阻塞主线
-
使用容量为goroutines数量的缓冲信道
对于方案1, 示例的代码大概会是这个样子:
var quit chan int // 只开一个信道
func foo(id int) {
fmt.Println(id)
quit <- 0 // ok, finished
}
func main() {
count := 1000
quit = make(chan int) // 无缓冲
for i := 0; i < count; i++ {
go foo(i)
}
for i := 0; i < count; i++ {
<- quit
}
}对于方案2, 把信道换成缓冲1000的:
quit = make(chan int, count) // 容量1000其实区别仅仅在于一个是缓冲的,一个是非缓冲的。
对于这个场景而言,两者都能完成任务, 都是可以的。
-
无缓冲的信道是一批数据一个一个的「流进流出」
-
缓冲信道则是一个一个存储,然后一起流出去
Go语言的并发和并行
不知道你有没有注意到一个现象,还是这段代码,如果我跑在两个goroutines里面的话:
var quit chan int = make(chan int)
func loop() {
for i := 0; i < 10; i++ {
fmt.Printf("%d ", i)
}
quit <- 0
}
func main() {
// 开两个goroutine跑函数loop, loop函数负责打印10个数
go loop()
go loop()
for i := 0; i < 2; i++ {
<- quit
}
}我们观察下输出:
0 1 2 3 4 5 6 7 8 9 0 1 2 3 4 5 6 7 8 9这是不是有什么问题??
以前我们用线程去做类似任务的时候,系统的线程会抢占式地输出, 表现出来的是乱序地输出。而goroutine为什么是这样输出的呢?
goroutine是在并行吗?
我们找个例子测试下:
package main
import "fmt"
import "time"
var quit chan int
func foo(id int) {
fmt.Println(id)
time.Sleep(time.Second) // 停顿一秒
quit <- 0 // 发消息:我执行完啦!
}
func main() {
count := 1000
quit = make(chan int, count) // 缓冲1000个数据
for i := 0; i < count; i++ { //开1000个goroutine
go foo(i)
}
for i :=0 ; i < count; i++ { // 等待所有完成消息发送完毕。
<- quit
}
}让我们跑一下这个程序(之所以先编译再运行,是为了让程序跑的尽量快,测试结果更好):
go build test.go
time ./test
./test 0.01s user 0.01s system 1% cpu 1.016 total我们看到,总计用时接近一秒。 貌似并行了!
我们看到,总计用时接近一秒。 貌似并行了!
并行和并发
从概念上讲,并发和并行是不同的, 简单来说看这个图片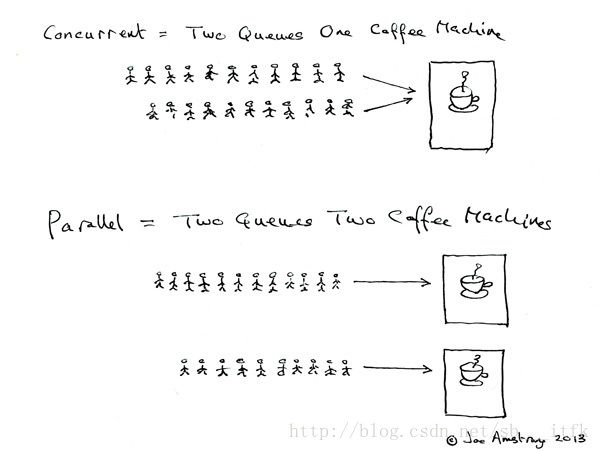
- 两个队列,一个Coffee机器,那是并发
- 两个队列,两个Coffee机器,那是并行
更多的资料: 并发不是并行, 当然Google上有更多关于并行和并发的区别。
那么回到一开始的疑问上,从上面的两个例子执行后的表现来看,多个goroutine跑loop函数会挨个goroutine去进行,而sleep则是一起执行的。
这是为什么?
默认地, Go所有的goroutines只能在一个线程里跑 。
也就是说, 以上两个代码都不是并行的,但是都是是并发的。
如果当前goroutine不发生阻塞,它是不会让出CPU给其他goroutine的, 所以例子一中的输出会是一个一个goroutine进行的,而sleep函数则阻塞掉了 当前goroutine, 当前goroutine主动让其他goroutine执行, 所以形成了逻辑上的并行, 也就是并发。
真正的并行
为了达到真正的并行,我们需要告诉Go我们允许同时最多使用多个核。
回到起初的例子,我们设置最大开2个原生线程, 我们需要用到runtime包(runtime包是goroutine的调度器):
import (
"fmt"
"runtime"
)
var quit chan int = make(chan int)
func loop() {
for i := 0; i < 100; i++ { //为了观察,跑多些
fmt.Printf("%d ", i)
}
quit <- 0
}
func main() {
runtime.GOMAXPROCS(2) // 最多使用2个核
go loop()
go loop()
for i := 0; i < 2; i++ {
<- quit
}
}这下会看到两个goroutine会抢占式地输出数据了。
我们还可以这样显式地让出CPU时间:
func loop() {
for i := 0; i < 10; i++ {
runtime.Gosched() // 显式地让出CPU时间给其他goroutine
fmt.Printf("%d ", i)
}
quit <- 0
}
func main() {
go loop()
go loop()
for i := 0; i < 2; i++ {
<- quit
}
}观察下结果会看到这样有规律的输出:
0 0 1 1 2 2 3 3 4 4 5 5 6 6 7 7 8 8 9 9其实,这种主动让出CPU时间的方式仍然是在单核里跑。但手工地切换goroutine导致了看上去的“并行”。
其实作为一个Python程序员,goroutine让我更多地想到的是gevent的协程,而不是原生线程。
关于runtime包对goroutine的调度,在stackoverflow上有一个不错的答案:http://stackoverflow.com/questions/13107958/what-exactly-does-runtime-gosched-do
一个小问题
我在Segmentfault看到了这个问题: http://segmentfault.com/q/1010000000207474
题目说,如下的程序,按照理解应该打印下5次 "world"呀,可是为什么什么也没有打印
package main
import (
"fmt"
)
func say(s string) {
for i := 0; i < 5; i++ {
fmt.Println(s)
}
}
func main() {
go say("world") //开一个新的Goroutines执行
for {
}
}楼下的答案已经很棒了,这里Go仍然在使用单核,for死循环占据了单核CPU所有的资源,而main线和say两个goroutine都在一个线程里面, 所以say没有机会执行。解决方案还是两个:
- 允许Go使用多核(runtime.GOMAXPROCS)
- 手动显式调动(runtime.Gosched)
runtime调度器
runtime调度器是个很神奇的东西,但是我真是但愿它不存在,我希望显式调度能更为自然些,多核处理默认开启。
关于runtime包几个函数:
Gosched让出cpuNumCPU返回当前系统的CPU核数量GOMAXPROCS设置最大的可同时使用的CPU核数Goexit退出当前goroutine(但是defer语句会照常执行)
总结
我们从例子中可以看到,默认的, 所有goroutine会在一个原生线程里跑,也就是只使用了一个CPU核。
在同一个原生线程里,如果当前goroutine不发生阻塞,它是不会让出CPU时间给其他同线程的goroutines的,这是Go运行时对goroutine的调度,我们也可以使用runtime包来手工调度。
本文开头的两个例子都是限制在单核CPU里执行的,所有的goroutines跑在一个线程里面,分析如下:
- 对于代码例子一(loop函数的那个),每个goroutine没有发生堵塞(直到quit流入数据), 所以在quit之前每个goroutine不会主动让出CPU,也就发生了串行打印
- 对于代码例子二(time的那个),每个goroutine在sleep被调用的时候会阻塞,让出CPU, 所以例子二并发执行。
那么关于我们开启多核的时候呢?Go语言对goroutine的调度行为又是怎么样的?
我们可以在Golang官方网站的这里 找到一句话:
When a coroutine blocks, such as by calling a blocking system call, the run-time automatically moves other coroutines on the same operating system thread to a different, runnable thread so they won’t be blocked.
也就是说:
当一个goroutine发生阻塞,Go会自动地把与该goroutine处于同一系统线程的其他goroutines转移到另一个系统线程上去,以使这些goroutines不阻塞
开启多核的实验
仍然需要做一个实验,来测试下多核支持下goroutines的对原生线程的分配, 也验证下我们所得到的结论“goroutine不阻塞不放开CPU”。
实验代码如下:
package main
import (
"fmt"
"runtime"
)
var quit chan int = make(chan int)
func loop(id int) { // id: 该goroutine的标号
for i := 0; i < 10; i++ { //打印10次该goroutine的标号
fmt.Printf("%d ", id)
}
quit <- 0
}
func main() {
runtime.GOMAXPROCS(2) // 最多同时使用2个核
for i := 0; i < 3; i++ { //开三个goroutine
go loop(i)
}
for i := 0; i < 3; i++ {
<- quit
}
}多跑几次会看到类似这些输出(不同机器环境不一样):
0 0 0 0 0 1 1 0 0 1 0 0 1 0 1 2 1 2 1 2 1 2 1 2 1 2 2 2 2 2
0 0 0 0 0 0 0 0 0 0 1 1 1 1 1 1 1 1 1 1 2 2 2 2 2 2 2 2 2 2
0 0 0 0 0 0 0 1 1 1 1 1 0 1 0 1 0 1 2 1 2 1 2 2 2 2 2 2 2 2
0 0 0 0 0 0 0 1 1 1 1 1 1 1 1 1 1 0 2 0 2 0 2 2 2 2 2 2 2 2
0 0 0 0 0 0 0 1 0 0 1 0 1 2 1 2 1 2 1 2 1 2 1 2 1 2 1 2 2 2执行它我们会发现以下现象:
- 有时会发生抢占式输出(说明Go开了不止一个原生线程,达到了真正的并行)
- 有时会顺序输出, 打印完0再打印1, 再打印2(说明Go开一个原生线程,单线程上的goroutine不阻塞不松开CPU)
那么,我们还会观察到一个现象,无论是抢占地输出还是顺序的输出,都会有那么两个数字表现出这样的现象:
- 一个数字的所有输出都会在另一个数字的所有输出之前
原因是, 3个goroutine分配到至多2个线程上,就会至少两个goroutine分配到同一个线程里,单线程里的goroutine 不阻塞不放开CPU, 也就发生了顺序输出。
Go语言并发的设计模式和应用场景
以下设计模式和应用场景来自Google IO上的关于Goroutine的PPT:https://talks.golang.org/2012/concurrency.slide
本文的示例代码在: https://github.com/hit9/Go-patterns-with-channel
生成器
在Python中我们可以使用yield关键字来让一个函数成为生成器,在Go中我们可以使用信道来制造生成器(一种lazy load类似的东西)。
当然我们的信道并不是简单的做阻塞主线的功能来使用的哦。
下面是一个制作自增整数生成器的例子,直到主线向信道索要数据,我们才添加数据到信道
func xrange() chan int{ // xrange用来生成自增的整数
var ch chan int = make(chan int)
go func() { // 开出一个goroutine
for i := 0; ; i++ {
ch <- i // 直到信道索要数据,才把i添加进信道
}
}()
return ch
}
func main() {
generator := xrange()
for i:=0; i < 1000; i++ { // 我们生成1000个自增的整数!
fmt.Println(<-generator)
}
}这不禁叫我想起了Python中可爱的xrange, 所以给了生成器这个名字!
服务化
比如我们加载一个网站的时候,例如我们登入新浪微博,我们的消息数据应该来自一个独立的服务,这个服务只负责 返回某个用户的新的消息提醒。
如下是一个使用示例:
func get_notification(user string) chan string{
/*
* 此处可以查询数据库获取新消息等等..
*/
notifications := make(chan string)
go func() { // 悬挂一个信道出去
notifications <- fmt.Sprintf("Hi %s, welcome to weibo.com!", user)
}()
return notifications
}
func main() {
jack := get_notification("jack") // 获取jack的消息
joe := get_notification("joe") // 获取joe的消息
// 获取消息的返回
fmt.Println(<-jack)
fmt.Println(<-joe)
}多路复合
上面的例子都使用一个信道作为返回值,可以把信道的数据合并到一个信道的。 不过这样的话,我们需要按顺序输出我们的返回值(先进先出)。
如下,我们假设要计算很复杂的一个运算 100-x , 分为三路计算, 最后统一在一个信道中取出结果:
func do_stuff(x int) int { // 一个比较耗时的事情,比如计算
time.Sleep(time.Duration(rand.Intn(10)) * time.Millisecond) //模拟计算
return 100 - x // 假如100-x是一个很费时的计算
}
func branch(x int) chan int{ // 每个分支开出一个goroutine做计算并把计算结果流入各自信道
ch := make(chan int)
go func() {
ch <- do_stuff(x)
}()
return ch
}
func fanIn(chs... chan int) chan int {
ch := make(chan int)
for _, c := range chs {
// 注意此处明确传值
go func(c chan int) {ch <- <- c}(c) // 复合
}
return ch
}
func main() {
result := fanIn(branch(1), branch(2), branch(3))
for i := 0; i < 3; i++ {
fmt.Println(<-result)
}
}select监听信道
Go有一个语句叫做select,用于监测各个信道的数据流动。
如下的程序是select的一个使用例子,我们监视三个信道的数据流出并收集数据到一个信道中。有了select, 我们在 多路复合中的示例代码中的函数fanIn还可以这么来写(这样就不用开好几个goroutine来取数据了):
func fanIn(branches ... chan int) chan int {
c := make(chan int)
go func() {
for i := 0 ; i < len(branches); i++ { //select会尝试着依次取出各个信道的数据
select {
case v1 := <- branches[i]: c <- v1
}
}
}()
return c
}用select的时候,有时需要超时处理, 其中的timeout信道相当有趣:结束标志
在Go并发与并行笔记一我们已经讲过信道的一个很重要也很平常的应用,就是使用无缓冲信道来阻塞主线,等待goroutine结束。
这样我们不必再使用timeout。
那么对上面的timeout来结束主线的方案作个更新:菊花链
简单地来说,数据从一端流入,从另一端流出,看上去好像一个链表,不知道为什么要取这么个尴尬的名字。。
菊花链的英文名字叫做: Daisy-chain, 它的一个应用就是做过滤器,比如我们来筛下100以内的素数(你需要先知道什么是筛法)
程序有详细的注释,不再说明了。随机数生成器
信道可以做生成器使用,作为一个特殊的例子,它还可以用作随机数生成器。如下是一个随机01生成器:定时器
我们刚才其实已经接触了信道作为定时器, time包里的After会制作一个定时器。
看看我们的定时器吧!
/*
* 利用信道做定时器
*/
package main
import (
"fmt"
"time"
)
func timer(duration time.Duration) chan bool {
ch := make(chan bool)
go func() {
time.Sleep(duration)
ch <- true // 到时间啦!
}()
return ch
}
func main() {
timeout := timer(time.Second) // 定时1s
for {
select {
case <- timeout:
fmt.Println("already 1s!") // 到时间
return //结束程序
}
}
}TODO
Google的应用场景例子。
本篇主要总结了使用信道, goroutine的一些设计模式。
间接转载地址: https://blog.csdn.net/sb___itfk/article/details/79045906