FATE实战——从零实现横向联邦之逻辑回归
从零实现横向逻辑回归联邦学习算法
本篇教程是一个从零实现横向联邦的过程,整个环节包括:
- 数据处理
- 数据上传
- 模型训练
- 模型预测
如果读者刚开始接触 FATE,建议先把官方的 demo 跑一下,比如笔者上一篇的教程就是一个 纵向 SecureBoost 的案例。
0,环境准备
这里的实验环境是单机版的 FATE,安装参考官方文档 FATE单机部署指南(建议 Docker 安装)。同时你还应该安装 fate-client 工具,注意是安装在 Docker 环境里,并正确初始化。参考:FATE Client 安装及初始化
1,数据处理
这里演示的是使用本地数据集,即威斯康星州临床科学中心的乳腺癌肿瘤数据集,你可以在 sklearn.datasets 中找到它。这个数据集共有569个样本,包括30个特征和1个标签。为了模拟业务环境,我们将前200条数据划分给参与方 host ,后269数据划分给参与方 guest,最后100条作为各方的验证数据集。(注意,虽然是横向联邦场景,但我们同样引入了 guest 和 host 概念,要知道的是不管是在参与前还是参与后它们都是平等的。)
你可以在装有 sklearn 等库的 Linux 环境中执行下面这个 split_dataset.py 文件划分数据集:
from sklearn.datasets import load_breast_cancer
import pandas as pd
breast_dataset = load_breast_cancer()
breast = pd.DataFrame(breast_dataset.data, columns=breast_dataset.feature_names)
breast = (breast-breast.mean())/(breast.std())
col_names = breast.columns.values.tolist()
columns = {
}
for idx, n in enumerate(col_names):
columns[n] = "x%d"%idx
breast = breast.rename(columns=columns)
breast['y'] = breast_dataset.target
breast['idx'] = range(breast.shape[0])
idx = breast['idx']
breast.drop(labels=['idx'], axis=1, inplace = True)
breast.insert(0, 'idx', idx)
breast = breast.sample(frac=1)
train = breast.iloc[:469]
eval = breast.iloc[469:]
breast_1_train = train.iloc[:200]
breast_1_train.to_csv('breast_1_train.csv', index=False, header=True)
breast_2_train = train.iloc[200:]
breast_2_train.to_csv('breast_2_train.csv', index=False, header=True)
eval.to_csv('breast_eval.csv', index=False, header=True)
执行后会在当前路径下生成 breast_1_train、breast_2_train 和breast_evl 三个文件,它们分别是 host 、guest 的训练数据集以及验证数据集。
2,数据上传
数据集准备好之后就需要将本地数据集上传到 Docker 环境中。笔者这里本地的文件路径是 /opt/mydata,目标上传路径是 /fate/data/mydata,执行以下命令:同步两个文件夹的数据。
[root@FATE-LSK mydata]# docker cp ./ fate:/fate/data/mydata
下一步是将 Docker 环境中的数据上传到内存中,也就是 FATE的数据库。考虑到有过个文件数据,我们使用配置文件 upload_data.json 的形式进行上传:数据上传参考:配置文件上传数据
{
"data": [
{
"file": "/fate/data/mydata/breast_1_train.csv",
"head": 1,
"work_mode": 0,
"partition": 16,
"table_name": "homo_breast_1_train",
"namespace": "homo_host_breast_train"
},
{
"file": "/fate/data/mydata/breast_2_train.csv",
"head": 1,
"work_mode": 0,
"partition": 16,
"table_name": "homo_breast_2_train",
"namespace": "homo_guest_breast_train"
},
{
"file": "/fate/data/mydata/breast_eval.csv",
"head": 1,
"work_mode": 0,
"partition": 16,
"table_name": "homo_breast_1_eval",
"namespace": "homo_host_breast_eval"
},
{
"file": "/fate/data/mydata/breast_eval.csv",
"head": 1,
"work_mode": 0,
"partition": 16,
"table_name": "homo_breast_2_eval",
"namespace": "homo_host_breast_eval"
}
]
}
通常,你只需要修改 file、table_name、name_space 即可。这里的4个数据集分别代表 host 和 guest 的训练、验证数据集。
然后,通过官方提供脚本执行数据上传指令:
python /fate/examples/scripts/upload_default_data.py -m 0 -b 0 -f 1 -c /fate/data/mydata/upload_data.json
成功执行后,会在数据集路径下查看到以下信息:

3,模型训练
模型的训练过程是通过 flow job submit -c {conf.json} -d {dsl.json} 命令进行的。
其中 conf 设置了集群基本信息、算法参数等;dsl 设置了训练各个过程的组件情况。
本例中使用横向逻辑回归,具体配置参考:
homo_lr_train_dsl.json,homo_lr_train_conf.json
同样是在当前路径 /fate/data/mydata 下 vim 出两个文件,这里贴出 homo_lr_train_dsl.json 的配置,注意没有做任何修改。
{
"components": {
"reader_0": {
"module": "Reader",
"output": {
"data": [
"data"
]
}
},
"dataio_0": {
"module": "DataIO",
"input": {
"data": {
"data": [
"reader_0.data"
]
}
},
"output": {
"data": [
"data"
],
"model": [
"model"
]
}
},
"scale_0": {
"module": "FeatureScale",
"input": {
"data": {
"data": [
"dataio_0.data"
]
}
},
"output": {
"data": [
"data"
],
"model": [
"model"
]
}
},
"homo_lr_0": {
"module": "HomoLR",
"input": {
"data": {
"train_data": [
"scale_0.data"
]
}
},
"output": {
"data": [
"data"
],
"model": [
"model"
]
}
},
"evaluation_0": {
"module": "Evaluation",
"input": {
"data": {
"data": [
"homo_lr_0.data"
]
}
},
"output": {
"data": [
"data"
]
}
}
}
}
贴出 homo_lr_train__conf.json 的配置,修改了 name 和 name_space 。
{
"dsl_version": 2,
"initiator": {
"role": "guest",
"party_id": 10000
},
"role": {
"guest": [
10000
],
"host": [
9999
],
"arbiter": [
9999
]
},
"job_parameters": {
"common": {
"job_type": "train",
"backend": 0,
"work_mode": 0
}
},
"component_parameters": {
"common": {
"dataio_0": {
"with_label": true,
"output_format": "dense"
},
"homo_lr_0": {
"penalty": "L2",
"tol": 1e-05,
"alpha": 0.01,
"optimizer": "sgd",
"batch_size": -1,
"learning_rate": 0.15,
"init_param": {
"init_method": "zeros"
},
"max_iter": 30,
"early_stop": "diff",
"encrypt_param": {
"method": null
},
"cv_param": {
"n_splits": 4,
"shuffle": true,
"random_seed": 33,
"need_cv": false
},
"decay": 1,
"decay_sqrt": true
},
"evaluation_0": {
"eval_type": "binary"
}
},
"role": {
"host": {
"0": {
"reader_0": {
"table": {
"name": "homo_breast_1_train",
"namespace": "homo_host_breast_train"
}
},
"evaluation_0": {
"need_run": false
}
}
},
"guest": {
"0": {
"reader_0": {
"table": {
"name": "homo_breast_2_train",
"namespace": "homo_guest_breast_train"
}
}
}
}
}
}
}
下一步便可以执行提交 job 命令:
flow job submit -c homo_lr_train_conf.json -d homo_lr_train_dsl.json
执行成功后,模型便训练好了,你可以在 fate_board 中查看输出信息。
4,模型评估
其实,官方针对业务场景提供了多种模型训练、评估、预测的配置,对横向逻辑回归来讲,可以参考这里:dsl_v2_homo_LR
我们这里使用 eval_conf 和 eval_dsl 的评估配置文件,即 host 和 guest 提供训练和验证的数据集,产生一个训练模型和一个验证模型,并最终输出一个(评估)结果。:
配置可分别参考以下链接:
homo_lr_eval_conf.json,homo_lr_eval_dsl.json
同样是在当前路径 /fate/data/mydata 下 vim 出两个文件。这里仍然贴出 homo_lr_eval_conf.json 的信息,仅改动了 table_name 和 namespace
{
"dsl_version": 2,
"initiator": {
"role": "guest",
"party_id": 10000
},
"role": {
"guest": [
10000
],
"host": [
9999
],
"arbiter": [
9999
]
},
"job_parameters": {
"common": {
"job_type": "train",
"backend": 0,
"work_mode": 0
}
},
"component_parameters": {
"common": {
"dataio_0": {
"with_label": true,
"output_format": "dense"
},
"homo_lr_0": {
"penalty": "L2",
"tol": 1e-05,
"alpha": 0.01,
"optimizer": "sgd",
"batch_size": 320,
"learning_rate": 0.15,
"init_param": {
"init_method": "zeros"
},
"max_iter": 3,
"early_stop": "diff",
"encrypt_param": {
"method": null
},
"cv_param": {
"n_splits": 4,
"shuffle": true,
"random_seed": 33,
"need_cv": false
},
"validation_freqs": 1
},
"evaluation_0": {
"eval_type": "binary"
}
},
"role": {
"guest": {
"0": {
"reader_0": {
"table": {
"name": "homo_breast_2_train",
"namespace": "homo_guest_breast_train"
}
},
"reader_1": {
"table": {
"name": "homo_breast_1_eval",
"namespace": "homo_host_breast_eval"
}
}
}
},
"host": {
"0": {
"reader_0": {
"table": {
"name": "homo_breast_1_train",
"namespace": "homo_host_breast_train"
}
},
"reader_1": {
"table": {
"name": "homo_breast_1_eval",
"namespace": "homo_host_breast_eval"
}
},
"evaluation_0": {
"need_run": false
}
}
}
}
}
}
这里贴出 homo_lr_eval_dsl.json 信息,没做任何改动
{
"components": {
"reader_0": {
"module": "Reader",
"output": {
"data": [
"data"
]
}
},
"reader_1": {
"module": "Reader",
"output": {
"data": [
"data"
]
}
},
"dataio_0": {
"module": "DataIO",
"input": {
"data": {
"data": [
"reader_0.data"
]
}
},
"output": {
"data": [
"data"
],
"model": [
"model"
]
}
},
"dataio_1": {
"module": "DataIO",
"input": {
"data": {
"data": [
"reader_1.data"
]
},
"model": [
"dataio_0.model"
]
},
"output": {
"data": [
"data"
],
"model": [
"model"
]
}
},
"scale_0": {
"module": "FeatureScale",
"input": {
"data": {
"data": [
"dataio_0.data"
]
}
},
"output": {
"data": [
"data"
],
"model": [
"model"
]
}
},
"scale_1": {
"module": "FeatureScale",
"input": {
"data": {
"data": [
"dataio_1.data"
]
},
"model": [
"scale_0.model"
]
},
"output": {
"data": [
"data"
],
"model": [
"model"
]
}
},
"homo_lr_0": {
"module": "HomoLR",
"input": {
"data": {
"train_data": [
"scale_0.data"
],
"validate_data": [
"scale_1.data"
]
}
},
"output": {
"data": [
"data"
],
"model": [
"model"
]
}
},
"homo_lr_1": {
"module": "HomoLR",
"input": {
"data": {
"test_data": [
"scale_1.data"
]
},
"model": [
"homo_lr_0.model"
]
},
"output": {
"data": [
"data"
],
"model": [
"model"
]
}
},
"evaluation_0": {
"module": "Evaluation",
"input": {
"data": {
"data": [
"homo_lr_0.data",
"homo_lr_1.data"
]
}
},
"output": {
"data": [
"data"
]
}
}
}
}
然后同样提交模型:
flow job submit -c homo_lr_eval_conf.json -d homo_lr_eval_dsl.json
执行成功后,在面板查看输出信息。下面是完整的算法流程:
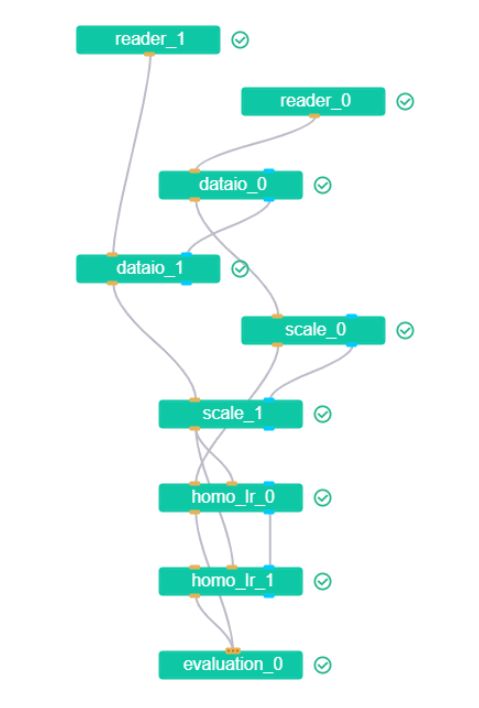

通过实验结果我们发现:
guest 方:看得到 eval 输出(即 Evaluation scores、Confusion Matrix、PSI Summary、Quantile Distribution 以及各种曲线),homo_0 模型有权重、Performance scores、LOSS、KS;homo_1 仅有权重信息。因为这里的 homo_1是预测模型,只要知道结果即可。
host 方:看不到 eval 输出,homo_0 模型仅有权重和一个 LOSS,homo_1 仅有权重信息。
arbiter 方:不参与数据读取、DTable 数据输入、特征工程, homo_0 模型仅有权重和一个LOSS,homo_1仅有权重信息,看得到 eval 输出,但没有内容(即理解为可以看但不看)。
注意,这里的 arbiter 是作为可信第三方存在的,有些场景下完全可以不要。
<全文完>