从头开始训练一个词性标注模型
文章目录
-
- 从头开始训练一个词性标注模型
- 自定义模型
-
-
- 一、导入所需要的包与模块
- 二、自定义词性
- 三、词性标注
-
- 训练模型
-
-
- 一、模型参数的注解(语种、输出目录以及训练迭代次数)
- 二、创建一个空白的语言模型
- 三、放入测试集
- 四、保存模型以及测试模型
-
- 不足的地方
- 代码
- 参考
从头开始训练一个词性标注模型
词性标注的全称为Part-Of-Speech tagging。顾名思义,词性标注是为输入文本中的单词
标注对应词性的过程。
spaCy 词性标注模型是一种统计模型,它不同于检查一个词是否属于停用词这种基于规则的检查流程。统计加预测的特性,意味着我们可以自己训练一个模型,以便获得更优的预测结果,新的预测过程与使用的数据集更加相关。所谓更优并不一定是数字层面的优化,因为目前的 spaCy 模型的通用词性标注准确率已经达到 97%。
为了使预测结果更准确,权重需要朝特定方向去优化,即增大或减小。spaCy 词性标注器的训练过程示意图如图所示。

接下来开始 spaCy 训练自定义模型。
注:本文使用 spaCy 3.0 代码实现。
自定义模型
一、导入所需要的包与模块
from __future__ import unicode_literals, print_function
import plac
import random
from pathlib import Path
import spacy
from spacy.training import Example
from spacy.tokens import Doc
二、自定义词性
spaCy 中的单词对象包含一个.tag_属性,下面是 spaCy 中的 19 个主要词性以及介绍。
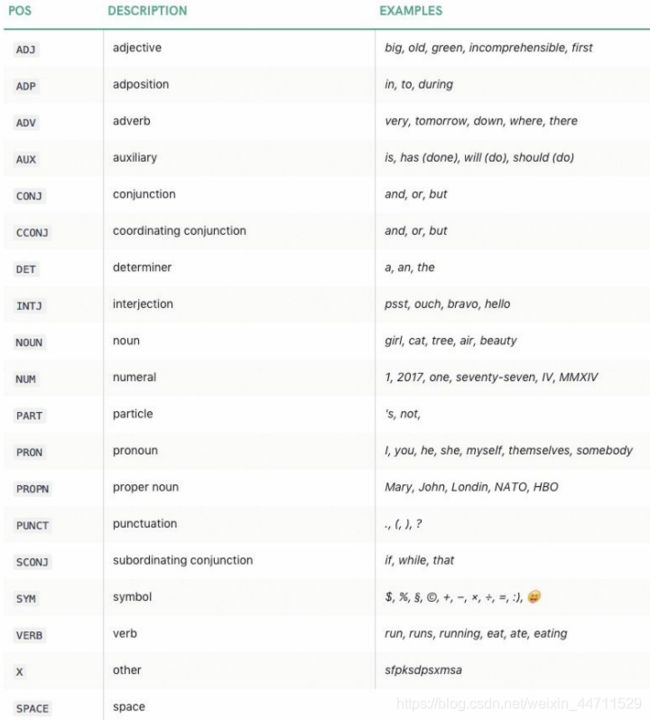
导入并初始化了 TAG_MAP 字典
TAG_MAP = {
'名词': {
'pos': 'NOUN'},
'动词': {
'pos': 'VERB'},
'形容词': {
'pos': 'ADJ'},
'判断词': {
'pos': 'AUX'},
'数词': {
'pos': 'NUM'},
'量词': {
'pos': 'DET'},
'代词': {
'pos': 'PRON'},
'副词': {
'pos': 'ADV'},
'助词': {
'pos': 'PART'}
}
三、词性标注
把自定义的词性名称映射到通用词性标注集上,
# 训练样本
TRAIN_DATA = [
('你自己的文本', {
'tags': ['代词', '动词', '数词', '量词', '名词', '名词']}),
('你自己的文本', {
'tags': ['代词', '动词', '数词', '量词', '名词', '名词']})
]
训练集可以自由发挥,数据越多,模型的训练效果越好。
训练模型
一、模型参数的注解(语种、输出目录以及训练迭代次数)
@plac.annotations(
lang=("ISO Code of language to use", "option", "l", str),
output_dir=("Optional output directory", "option", "o", Path),
n_iter=("Number of training iterations", "option", "n", int))
二、创建一个空白的语言模型
使用 add_pipeline函数创建流水线,并向其中添加标注器
def main(lang='zh', output_dir=None, n_iter=25):
nlp = spacy.blank(lang) # 创建一个空的中文模型
tagger = nlp.add_pipe('tagger') # 创建流水线
# 添加标注器
for tag, values in TAG_MAP.items():
#print("tag:",tag)
#print("values:",values)
tagger.add_label(tag)
print("3:",tagger)
optimizer = nlp.begin_training() # 模型初始化
for i in range(n_iter):
random.shuffle(TRAIN_DATA) # 打乱列表
losses = {
}
for text, annotations in TRAIN_DATA:
example = Example.from_dict(Doc(nlp.vocab, words=text, spaces=[""] * len(text)), annotations)
nlp.update([example], sgd=optimizer, losses=losses)
print(losses)
三、放入测试集
test_text = "你自己的文本"
doc = nlp(test_text)
print('Tags', [(t.text, t.tag_, TAG_MAP[t.tag_]['pos']) for t in doc])
四、保存模型以及测试模型
if output_dir is not None:
output_dir = Path(output_dir)
if not output_dir.exists():
output_dir.mkdir()
nlp.to_disk(output_dir)
print("Saved model to", output_dir)
# 测试保存模型
print("Loading from", output_dir)
nlp2 = spacy.load(output_dir)
doc = nlp2(test_text)
print('Tags', [(t.text, t.tag_, TAG_MAP[t.tag_]['pos']) for t in doc])
模型的效果如下
# 我喜欢吃苹果
Tags [('我', '代词', 'PRON'), ('喜', '动词', 'VERB'), ('欢', '动词', 'VERB'), ('吃', '动词', 'VERB'), ('苹', '名词', 'NOUN'), ('果', '名词', 'NOUN')]
不足的地方
从效果可以看出模型把每个字都标注了词性,但无法将整个词语进行标注,后续会继续尝试。
代码
# -*- coding: utf-8 -*-
"""
Created on Sat Apr 15 23:57:49 2021
@author: 94036
使用 spaCy 3.0 进行词性标注
"""
from __future__ import unicode_literals, print_function
import plac
import random
from pathlib import Path
import spacy
from spacy.training import Example
from spacy.tokens import Doc
#=======================自定义词性=============================#
TAG_MAP = {
'名词': {
'pos': 'NOUN'},
'动词': {
'pos': 'VERB'},
'形容词': {
'pos': 'ADJ'},
'判断词': {
'pos': 'AUX'},
'数词': {
'pos': 'NUM'},
'量词': {
'pos': 'DET'},
'代词': {
'pos': 'PRON'},
'副词': {
'pos': 'ADV'},
'助词': {
'pos': 'PART'}
}
#=========================词性标注=============================#
TRAIN_DATA = [
('你自己的文本', {
'tags': ['代词', '动词', '数词', '量词', '名词', '名词']}),
('你自己的文本', {
'tags': ['代词', '动词', '数词', '量词', '名词', '名词']})
]
#==========================训练模型============================#
# 模型参数的注解
@plac.annotations(
lang=("ISO Code of language to use", "option", "l", str),
output_dir=("Optional output directory", "option", "o", Path),
n_iter=("Number of training iterations", "option", "n", int))
# 模型进行训练
def main(lang='zh', output_dir=None, n_iter=25):
nlp = spacy.blank(lang) # 创建一个空的中文模型
tagger = nlp.add_pipe('tagger') # 创建流水线
# 添加标注器
for tag, values in TAG_MAP.items():
print("tag:",tag)
print("values:",values)
tagger.add_label(tag)
print("3:",tagger)
optimizer = nlp.begin_training() # 模型初始化
for i in range(n_iter):
random.shuffle(TRAIN_DATA) # 打乱列表
losses = {
}
for text, annotations in TRAIN_DATA:
example = Example.from_dict(Doc(nlp.vocab, words=text, spaces=[""] * len(text)), annotations)
nlp.update([example], sgd=optimizer, losses=losses)
print(losses)
# 测试样本
test_text = "你自己的文本"
doc = nlp(test_text)
print('Tags', [(t.text, t.tag_, TAG_MAP[t.tag_]['pos']) for t in doc])
# 将模型保存到输出目录
if output_dir is not None:
output_dir = Path(output_dir)
if not output_dir.exists():
output_dir.mkdir()
nlp.to_disk(output_dir)
print("Saved model to", output_dir)
# 测试保存模型
print("Loading from", output_dir)
nlp2 = spacy.load(output_dir)
doc = nlp2(test_text)
print('Tags', [(t.text, t.tag_, TAG_MAP[t.tag_]['pos']) for t in doc])
if __name__ == '__main__':
plac.call(main)
参考
1、【法】巴格夫·斯里尼瓦萨-德西坎 《自然语言处理与计算语言学》 人民邮电出版社