后台性能优化实践实战
近年来公司的业务数据量和用户流量都呈现出了非常迅猛的增长趋势,为了解决历史架构设计中的不足,应对诸多因素引发的风险并保证通天塔平台的稳定运行,通天塔后端组专项成立了一个“通天塔后端技术优化组”,号召并鼓励团队每个人积极参与进来,全盘分析和梳理、技术设计和技术Review、形成技术优化需求、排期、自测和验证效果、Code Review、制定灰度和上线计划、上线、总结经验并形成未来可借鉴的方法。
本文主要聚焦在总结公司性能优化的经验,为聚合服务的性能优化提供些参考。
优化效果
本次公司性能优化对比了优化前后的数据,约有10%~30%的提升:

优化原则
性能优化主要按下图所示 “三步走” 。

通过测试收集性能指标数据,具体分析产生性能问题的原因,对症下药解决性能问题。
从长期看,这样的优化过程是持续进行、反复迭代的。但是短期看,我们同样需要一些阶段性的里程碑来提升信心。
因此,在做公司性能优化时,我们制定了一些 优化标准 。例如:接口响应指标AVG、TP999提升10~20%,吞吐率提升(当时没有定明确的量化值,主要考虑到响应提升间接也能带来一定的吞吐率提升)。
并且,我们始终要坚持一些基本的 系统优化原则:
1.以不影响业务功能为前提。保证优化前后逻辑的一致性,从理论到实践,通过严格的论证和全面的测试。
2.注重优先级。优先考虑一些性价比高的优化,性价比太低的放到最后,甚至干脆就不考虑了,节省研发成本。
3.奥卡姆剃刀原则。即简单性原则。新产生的性能问题的原因很可能是最近的迭代造成的;非必要的功能、代码,能不加就不加。
性能测试
测试是为了收集性能数据,为后续分析调优提供基础。 公司在优化过程中,主要采取了两类性能测试方法:
1.微基准测试:针对方法级别,主要使用JMH等工具检测方法的吞吐和延迟。
2.宏基准测试:针对系统级别,主要使用forcebot(公司内部工具)压测系统整体的性能(CPU、内存、IO、JVM、延迟、吞吐等等)。开源的ab,jmeter等性能测试工具也能达到类似的效果。
对于性能指标,目前我们主要采集了如下的一些指标:
-
CPU、内存、IO等系统指标
-
接口延迟、QPS等
-
JVM堆、栈等指标采样
-
调用链延迟分析工具等
性能指标分析
收集到系统资源、JVM、应用等性能指标后,对各类性能指标的问题表现进行分析,简单总结了以下一些点:
CPU高:
-
计算任务重
-
正则表达式回溯
-
GC频繁
-
上下文切换多
-
大量异常填充栈信息
堆内存高:
-
创建对象多
-
内存泄漏
JVM吞吐低:
-
STW过多
磁盘IO高:
-
日志记录影响
网络IO高:
-
传输数据量大
应用延迟高:
-
串行IO设计影响
-
上游尾延迟影响
在公司优化过程中,最有效的还是通过调用链分析工具,帮助我们理清复杂业务逻辑中的调用关系和方法级别的延迟,更针对性地专注于优化更高优先级、最显著的性能问题。
调优策略
这里主要介绍对问题表现的分析后进行的一些系统优化。
1
优化设计
设计层面的优化,需要我们对自身的应用架构足够熟悉,缩小可能存在瓶颈的范围。然后再借助压测、调用链分析等工具,进一步确诊问题点。
6.1.1 多任务RPC查询调度编排优化
对于公司(存在大规模扇出依赖查询的聚合服务也是类似)来说,有大量的上游依赖需要进行RPC调用来获取外部数据,再结合系统内部数据进行聚合。为了只关注我们的优化点,我们把这个过程简化为如下图所示:
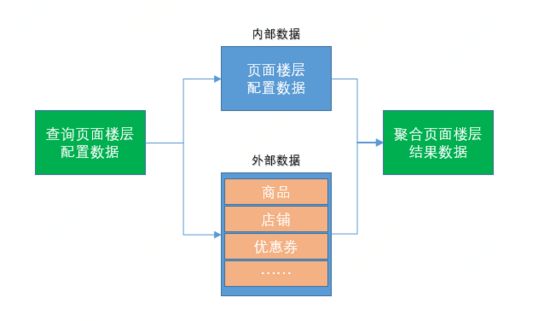
图6.1.1.a:公司数据聚合过程
对于外部数据的获取,我们可以使用线程池去做一次并行查询。对于简单的页面来说这是一种非常理想的情况,但是实际情况往往复杂得多。当配置的页面复杂度提高后,外部数据之间也会存在着依赖关系,依赖之间必须串行执行,一次并行查询无法解决问题。如下示意图展示了外部数据的依赖关系及我们优化前的设计:
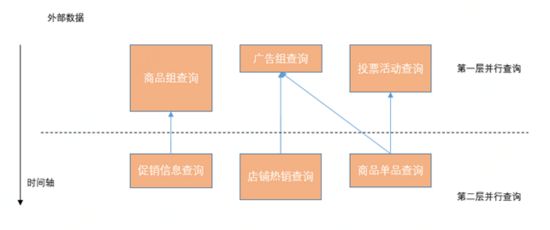
图6.1.1.b:优化前外部数据查询示意图
如上图所示,优化前的设计,我们人为根据外部数据的依赖关系,将RPC调用拆分为多个并行阶段,也是权衡了公司早期的活动复杂度、流量以及系统实现复杂度等因素的设计。这种设计的问题就是,第二阶段的整体开始查询时间依赖于第一阶段最慢的那个查询节点的结束时间,即使第二阶段的查询节点完全不依赖于第一阶段最慢的那个查询节点。通过调用链分析工具分析RPC调用的延迟和时间轴上的关系,也证实了我们这一观点。因此我们进行了RPC调度的设计优化,基于Sirector并行任务编排组件(公司内部组件,可以理解为类似于JDK的Fork/Join组件),根据页面的楼层配置,动态构建出RPC查询任务依赖的DAG图,RPC调用自然地沿着DAG图的方向执行,消除了人为的阶段划分。
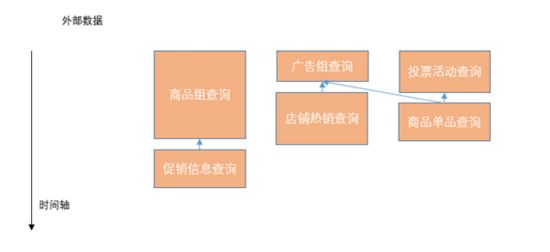
图6.1.1.c:优化后外部数据查询示意图
优化编排后对接口响应的均值和TP999都有很大的贡献。
6.1.2 单任务RPC查询并行优化
通过调用链分析工具,我们也发现部分RPC查询任务内部存在串行查询的情况。以商品促销信息查询为例,入参是一箩筐商品sku,分批串行查询促销信息。优化过程如下图所示,在上游接口提供方可接受的并行度范围内进行并行查询。
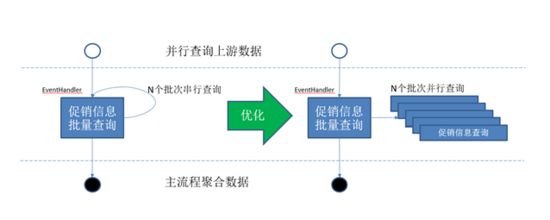
图6.1.2.a:RPC查询并行优化示意图
6.1.3 虚拟机减压,冷数据优化
公司是一个高并发高流量的系统,使用缓存技术来缓存活动配置等内部数据。对于大流量的系统,使用缓存技术就无需多言了。但是,随着业务的不断增长,缓存的量也越来越大,这给JVM堆内存造成了很大的压力。那么是否真的所有数据都要缓存?是否可以进行冷热数据的拆分呢?
其实,为了满足用户个性化的需求,对于特定楼层(如小院feed流),公司预定义了一部分活动作为个性化楼层的数据源。这类活动不会单独对外投放,因此可以作为冷数据从在线活动池中拆分出去,通过RPC查询接口按需查询这部分数据。
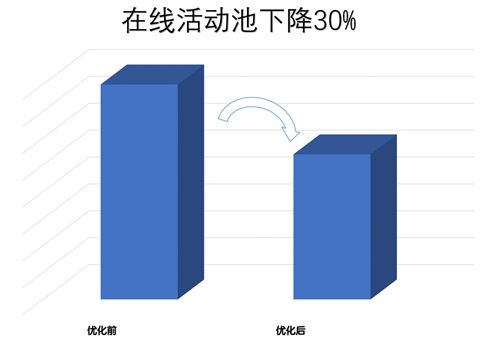
图6.1.3.a:冷数据优化示意图
如上图所示,优化后减轻了虚拟机的内存压力。
6.1.4 尾延迟优化
尾延迟优化主要参考了Jeff Dean的论文《The Tail At Scale》,采用发送hedged-request备份请求的方式,来解决扇出依赖较多,因集群规模扩大后,上游小概率的长尾传导至下游后放大产生长尾概率的问题,平滑尾延迟。只适用于上游长尾特征明显的情况。为了对上游不造成太大影响,我们也启用了限流策略,控制备份请求的发送量。
由于我们的RPC框架不支持请求取消,而且实现要注意的细节问题较多,目前处于小流量实验阶段。
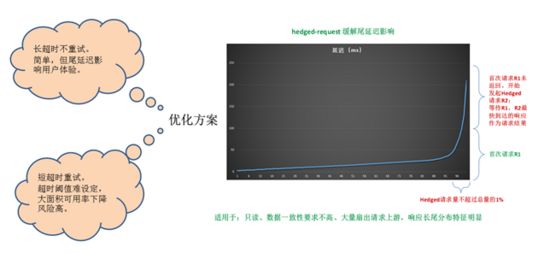
图6.1.4.a: 尾延迟优化示意图
优化组件
组件层面的优化,主要做了一些组件的替换升级、参数调优,变更代价小,有较 高的性价比。
6.2.1 JVM优化
JVM优化主要是进行了从JDK1.6到JDK1.8的升级,默认的Parallel垃圾回收器吞吐优先,不太适合我们的应用场景,因此改成了响应优先的G1;
另外由于JVM的sychronized(即使业务代码没用到,很多框架也有用到)锁优化在偏向锁升级过程中需要进入全局安全点,会有很短的STW。考虑到公司应用的高并发场景,我们也关闭了偏向锁来提高吞吐;
从部署环境的角度考虑,当前我们使用的JVM实现无法感知到自己处于Docker容器环境,获取的CPU核数是物理机的核数,远超分配给我们的容器核数。这导致了一些依赖于CPU资源限制推导的虚拟机默认参数会非常不合理。比如,JVM默认的GC线程数会偏大,在GC纯本地计算阶段会有大量无意义的线程切换影响吞吐,因此我们手动设置了GC线程数,向容器核数对齐。
6.2.2 日志框架优化
结合线程栈和磁盘IO分析,发现之前的日志框架(log4j/logback)都使用了同步模式。并发量大时锁竞争激烈,上下文切换造成额外开销;另外,同步模式下,磁盘较低的IOPS影响应用的响应时间。因此我们切换到了log4j2框架上来,并结合LMAX Disruptor,开启了全异步的日志模式,同时log4j2的对象复用机制减少了框架本身产生的内存垃圾,降低日志框架造成尾延迟的概率,将日志对应用的影响降到最低。
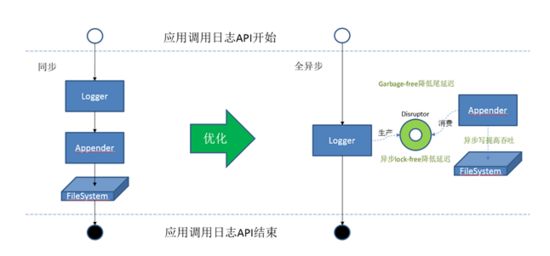
图6.2.2.a:日志框架优化示意图
6.2.3 线程池优化
原先线程池设置有一些不合理的地方。比如:线程数设置过大,导致CPU切换开销大,占用内存资源;核心线程数与最大线程数之间差值较大、线程池没有预热,造成突发流量增大时,同时申请线程资源时响应时长产生明显的抖动。
因此我们通过压测去合理设定线程池大小,减小核心线程数与最大线程数之间的差值,有些直接设置为相等,设置线程池预热核心线程,改善上述问题。
3
优化代码
代码层面的优化,带来的提升表现在更微观的层面,我们可以通过JMH等工具做一些微基准测试来对比优化前后的效果。 对于高流量的应用,微观层面的优化也可以带来一定的吞吐提升。
6.3.1 深拷贝优化
为了避免对共享资源造成污染,公司代码中使用了深拷贝方式来保护共享资源。原先通过序列化-反序列化的方式实现,这种方式拷贝流程长、中间对象多,GC有额外的压力。优化后我们使用Cloning深拷贝工具,直接进行对象到对象的拷贝,缩短了拷贝流程,同时也不要求POJO实现Cloneable接口,避免了使用原型模式过多的限制。
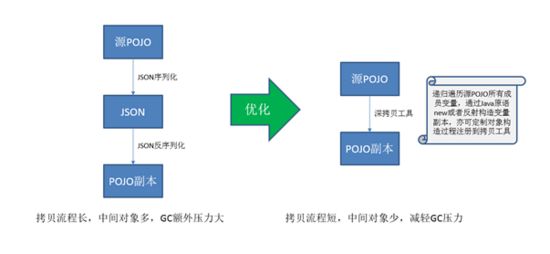
图6.3.1.a:深拷贝优化示意图
6.3.2 对象重用&无竞争
公司灰度功能采用了随机灰度的策略,代码中使用Random对象,这里存在一些代码重用和竞争的问题,优化过程如下图所示
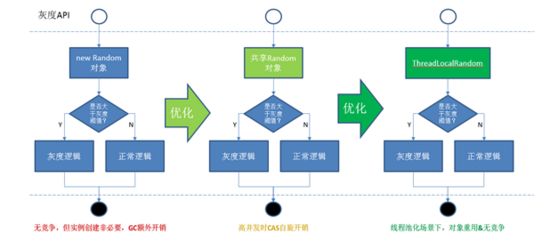
图6.3.2.a 对象重用&无竞争优化示意图
6.3.3 其他代码优化
虽然“不提倡过早优化”这句话老生常谈,但并不意味着我们写每一行代码时可以很随意,我们完全可以选择更优的实现方式。各种编码规约,设计模式其实就是前人总结出来的宝贵经验,帮助我们更好地编码实现。
其实,代码层面可注意的优化点非常多,这里只列出一些供参考:
-
正则表达式使用独占模式
-
JIT优化内联:短方法;尽量private/static/final修饰方法
-
锁优化:锁分离;细粒度锁;乐观锁;无锁(不可变模型/ThreadLocal等)
-
时间换空间:数据压缩降低网络IO;String常量池重用
-
空间换时间:哈希表;缓存等
公司本轮的优化基本达到了预期目标。 总体而言,设计层面的优化难度较高,对于聚合应用而言效果最显著; 组件、代码层面的优化也有不错的效果,但更多的需要通过微基准测试去验证。 最后,也是我们觉得最重要的一点就是: 系统优化必须保证系统的稳定性和正确性,必须通过严格的验证和测试,否则,宁可不优化。