【机器学习】实战系列一——波士顿房价预测(一文学会)
系列文章目录
学习笔记:
【机器学习】第一章——机器学习分类和性能度量
【机器学习】第二章——EM(期望最大化)算法
【机器学习】第六章——概率无向图模型
实战系列:
【机器学习】实战系列一——波士顿房价预测(一文学会)
【机器学习】实战系列二——梯度下降(一文学会)
【机器学习】实战系列三——支持向量机(一文学会)
【机器学习】实战系列四——聚类实验(一文学会)
【机器学习】实战系列五——天文数据挖掘实验(天池比赛)
文章目录
- 系列文章目录
- 前言
- 开源
- 一、相关理论及知识点
- 二、实验流程
-
- 1.引入库
- 2.读入数据
- 3. 查看各个特征的散点分布
- 4. 定义特征值和目标值
- 5. 特征值的描述性统计
- 6.拆分训练集和测试集
- 7. 线性回归模型预测
- 8. 开始预测
- 9. 预测结果与分析
- 10. 结果可视化
- 三、总结
前言
本文带领你踏入机器学习的大门,笔者打算将学习机器学习这门课程中所完成的实验写成一个系列文章,称为机器学习实战教学,希望你能在实战过程中感受到机器学习的魅力。
【注】本文实验环境为Jupyter Notebook
开源
完整代码已开源至github
https://github.com/TommyGong08/BIT-CS-Code/tree/master/Machine_Learning/lab1_Boston
如果对你有帮助的话,欢迎star和follow~
一、相关理论及知识点
(1)线性回归的原理
(2)平均绝对误差,均分误差的理解
(3)sklearn 中线性回归函数的应用
二、实验流程
- 数据理解
- 数据读入,使用 pandas 读入数据并输出读入的数据
- 定义特征值,目标值 使用’crim’, ‘rm’, 'lstat’作为特征值,
- 区分训练集和测试集
- 线性回归
- 预测
- 求取预测值和真实值的mae
- 获取均分误差
1.引入库
代码如下(示例):
# 查看当前kernel下已安装的包 list packages
import pandas as pd
import matplotlib.pyplot as plt
import matplotlib
import numpy as np
2.读入数据
代码如下(示例):
data = pd.read_csv('../boston.csv')
print(data) #可以输出数据康康
# 检查有无数据有误空值
data.isnull().any().sum()
3. 查看各个特征的散点分布
代码如下(示例):
pd.plotting.scatter_matrix(data, alpha=0.7, figsize=(10,10), diagonal='kde')
结果如图:

4. 定义特征值和目标值
选取crim , rm, lstat作为特征值, medv作为目标值
feature = data[['crim','rm','lstat','medv']]
y = np.array(feature['medv'])
feature=feature.drop(['medv'],axis=1)
X = np.array(feature)
print(feature.shape)
print(y.shape)
结果如图:
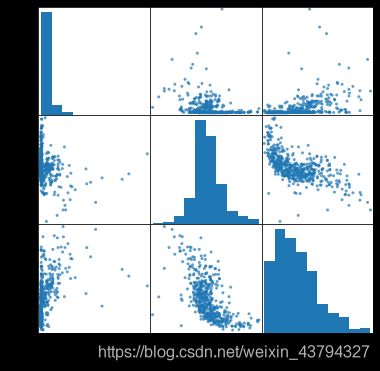
5. 特征值的描述性统计
# 输出特征值的描述性统计
pd.plotting.scatter_matrix(feature, alpha=0.7, figsize=(6,6), diagonal='hist')
6.拆分训练集和测试集
from sklearn.cross_validation import train_test_split
x_train, x_test, y_train, y_test = train_test_split(X, y,test_size = 0.3, random_state = 8)
print(x_test.shape)
7. 线性回归模型预测
# 线性回归模型预测房价, cv = 5表示计算5个连续次的分数,每次有不同的分割
from sklearn import linear_model
from sklearn.linear_model import LinearRegression
lr = LinearRegression()
lr.fit(x_train, y_train)
8. 开始预测
# 分别在测试集和训练集上预测
y_pred_test = lr.predict(x_test)
y_pred_train = lr.predict(x_train)
print(x_train.shape)
print(y_pred_test)
9. 预测结果与分析
# 输出pre与real的mae和mse
from sklearn.metrics import mean_squared_error,mean_absolute_error
test_mae = mean_absolute_error(y_pred_test, y_test)
test_mse = mean_squared_error(y_pred_test, y_test)
print("mae: " + str(test_mae))
print("mse: " + str(test_mse))
train_mae = mean_absolute_error(y_pred_train, y_train)
train_mse = mean_squared_error(y_pred_train, y_train)
print("mae: " + str(train_mae))
print("mse: " + str(train_mse))
10. 结果可视化
# 画出预测曲线与真实曲线
plt.plot(y_pred_test, label = 'y_test_pred')
plt.plot(y_test, label = "y_test_real")
plt.legend()
plt.show()

三、总结
-
通过本次实验,了解了线性回归的原理,掌握线性回归在数据分析中的重要应用。
-
学习 python 语言和常用的 pandas、sklearn 库,可以对机器学习和数据处理有一定了解
-
接触 Jupyter Notebook,多掌握了一项实用的工具,总之收获颇多