本文将介绍如何清洗nginx日志并存储到mysql中,附带azkaban定时任务协作完成对
access.log的清洗任务。
1. 查看nginx日志格式
cd /var/log/nginx
[root@FantJ nginx]# cat access.log
140.205.205.25 - - [19/Aug/2018:03:41:59 +0800] "GET / HTTP/1.1" 404 312 "-" "Scrapy/1.5.0 (+https://scrapy.org)" "-"
185.55.46.110 - - [19/Aug/2018:03:56:16 +0800] "GET / HTTP/1.0" 404 180 "-" "-" "-"
80.107.89.207 - - [19/Aug/2018:03:56:25 +0800] "GET / HTTP/1.1" 404 191 "-" "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_11_6) AppleWebKit/601.7.7 (KHTML, like Gecko) Version/9.1.2 Safari/601.7.7" "-"
140.205.205.25 - - [19/Aug/2018:04:13:52 +0800] "HEAD / HTTP/1.1" 404 0 "-" "Go-http-client/1.1" "-"
139.162.88.63 - - [19/Aug/2018:04:31:56 +0800] "GET http://clientapi.ipip.net/echo.php?info=1234567890 HTTP/1.1" 404 207 "-" "Go-http-client/1.1" "-"
......
我们需要根据这个格式来写正则表达式,对数据进行过滤。上面是我的日志格式。
log_format main '$remote_addr - $remote_user [$time_local] "$request" '
'$status $body_bytes_sent "$http_referer" '
'"$http_user_agent" "$http_x_forwarded_for"';
这是我nginx的日志配置。(centos版本默认配置)。
2. 正则表达式测试
public static void main(String[] args) {
Pattern p = Pattern.compile("([^ ]*) ([^ ]*) ([^ ]*) (\\[.*\\]) (\\\".*?\\\") (-|[0-9]*) (-|[0-9]*) (\\\".*?\\\") (\\\".*?\\\")([^ ]*)");
Matcher m = p.matcher("202.173.10.31 - - [18/Aug/2018:21:16:28 +0800] \"GET / HTTP/1.1\" 404 312 \"http://www.sdf.sdf\" \"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/56.0.2924.87 Safari/537.36\" \"-\"\n");
while (m.find()) {
System.out.println(m.group(1));
System.out.println(m.group(2));
System.out.println(m.group(3));
System.out.println(m.group(4));
System.out.println(m.group(5));
System.out.println(m.group(6));
System.out.println(m.group(7));
System.out.println(m.group(8));
System.out.println(m.group(9));
System.out.println(m.group(10));
System.out.println(m.toString());
}
}
控制台输出:
202.173.10.31
-
-
[18/Aug/2018:21:16:28 +0800]
"GET / HTTP/1.1"
404
312
"http://www.xxx.top"
"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/56.0.2924.87 Safari/537.36"
证明我们的正则可以使用。
3. Spark程序实现
上一章我介绍了RDD和DF之间的转换和临时表Sql的执行,这章节增加了对RDD数据的持久化操作,我将把RDD数据集存储到mysql中。
3.1 创建mysql表
CREATE TABLE `access` (
`remote_addr` varchar(255) DEFAULT NULL,
`remote_user` varchar(255) DEFAULT NULL,
`time_local` varchar(255) DEFAULT NULL,
`request` varchar(255) DEFAULT NULL,
`status` varchar(255) DEFAULT NULL,
`byte_sent` varchar(255) DEFAULT NULL,
`refere` varchar(255) DEFAULT NULL,
`http_agent` varchar(255) DEFAULT NULL,
`http_forward_for` varchar(255) DEFAULT NULL
) ENGINE=InnoDB DEFAULT CHARSET=utf8;
CREATE TABLE `acc_addr_count` (
`remote_addr` varchar(255) DEFAULT NULL,
`count` int(11) DEFAULT NULL
) ENGINE=InnoDB DEFAULT CHARSET=latin1;
第一个表是log的全部数据内容,第二个表是对ip数目做一统计。这两个表都在我的数据库nginx中。
3.2 编写DBHelper.java
public class DBHelper {
private String url = "jdbc:mysql://192.168.27.166:3306/nginx";
private String name = "com.mysql.jdbc.Driver";
private String user = "root";
private String password = "xxx";
//获取数据库连接
public Connection connection = null;
public DBHelper(){
try {
Class.forName(name);
connection = DriverManager.getConnection(url,user,password);
} catch (Exception e) {
e.printStackTrace();
}
}
public void close() throws SQLException {
this.connection.close();
}
}
3.3 编写实体类(javaBean)
我将用反射的方法完成对整条log的清洗,用动态元素创建来完成对
acc_addr_count表的收集。(不清楚这两种方法的可先看下上一章)
NginxParams.java
public class NginxParams implements Serializable {
private String remoteAddr;
private String remoteUser;
private String timeLocal;
private String request;
private String status;
private String byteSent;
private String referer;
private String httpUserAgent;
private String httpForwardedFor;
setter and getter ...methods...
@Override
public String toString() {
return "NginxParams{" +
"remoteAddr='" + remoteAddr + '\'' +
", remoteUser='" + remoteUser + '\'' +
", timeLocal='" + timeLocal + '\'' +
", request='" + request + '\'' +
", status='" + status + '\'' +
", byteSent='" + byteSent + '\'' +
", referer='" + referer + '\'' +
", httpUserAgent='" + httpUserAgent + '\'' +
", httpForwardedFor='" + httpForwardedFor + '\'' +
'}';
}
}
3.4 编写清洗代码
NginxLogCollect.java
public class NginxLogCollect implements Serializable {
static DBHelper dbHelper = null;
public static void main(String[] args) {
SparkConf conf = new SparkConf().setAppName("NginxLogCollect").setMaster("local");
JavaSparkContext sc = new JavaSparkContext(conf);
sc.setLogLevel("ERROR");
SQLContext sqlContext = new SQLContext(sc);
JavaRDD lines = sc.textFile("C:\\Users\\84407\\Desktop\\nginx.log");
JavaRDD nginxs = lines.map((Function) line -> {
Pattern p = Pattern.compile("([^ ]*) ([^ ]*) ([^ ]*) (\\[.*\\]) (\\\".*?\\\") (-|[0-9]*) (-|[0-9]*) (\\\".*?\\\") (\\\".*?\\\")([^ ]*)");
Matcher m = p.matcher(line);
NginxParams nginxParams = new NginxParams();
while (m.find()){
nginxParams.setRemoteAddr(m.group(1));
nginxParams.setRemoteUser(m.group(2));
nginxParams.setTimeLocal(m.group(4));
nginxParams.setRequest(m.group(5));
nginxParams.setStatus(m.group(6));
nginxParams.setByteSent(m.group(7));
nginxParams.setReferer(m.group(8));
nginxParams.setHttpUserAgent(m.group(9));
nginxParams.setHttpForwardedFor(m.group(10));
}
return nginxParams;
});
/**
* 使用反射方式,将RDD转换为DataFrame
*/
DataFrame nginxDF = sqlContext.createDataFrame(nginxs,NginxParams.class);
/**
* 拿到一个DataFrame之后,就可以将其注册为一个临时表,然后针对其中的数据执行sql语句
*/
nginxDF.registerTempTable("nginxs");
DataFrame allDF = sqlContext.sql("select * from nginxs");
//统计ip访问数
DataFrame addrCount = sqlContext.sql("select remoteAddr,COUNT(remoteAddr)as count from nginxs GROUP BY remoteAddr ORDER BY count DESC");
/**
* 将查询出来的DataFrame ,再次转换为RDD
*/
JavaRDD allRDD = allDF.javaRDD();
JavaRDD addrCountRDD = addrCount.javaRDD();
/**
* 将RDD中的数据进行映射,映射为NginxParams
*/
JavaRDD map = allRDD.map((Function) row -> {
NginxParams nginxParams = new NginxParams();
nginxParams.setRemoteAddr(row.getString(4));
nginxParams.setRemoteUser(row.getString(5));
nginxParams.setTimeLocal(row.getString(8));
nginxParams.setRequest(row.getString(6));
nginxParams.setStatus(row.getString(7));
nginxParams.setByteSent(row.getString(0));
nginxParams.setReferer(row.getString(2));
nginxParams.setHttpUserAgent(row.getString(3));
nginxParams.setHttpForwardedFor(row.getString(1));
return nginxParams;
});
/**
* 将数据collect回来,然后打印
*/
// List nginxParamsList = map.collect();
// for (NginxParams np:nginxParamsList){
// System.out.println(np);
// }
dbHelper = new DBHelper();
String sql = "INSERT INTO `access` VALUES (?,?,?,?,?,?,?,?,?)";
map.foreach((VoidFunction) nginxParams -> {
PreparedStatement pt = dbHelper.connection.prepareStatement(sql);
pt.setString(1,nginxParams.getRemoteAddr());
pt.setString(2,nginxParams.getRemoteUser());
pt.setString(3,nginxParams.getTimeLocal());
pt.setString(4,nginxParams.getRequest());
pt.setString(5,nginxParams.getStatus());
pt.setString(6,nginxParams.getByteSent());
pt.setString(7,nginxParams.getReferer());
pt.setString(8,nginxParams.getHttpUserAgent());
pt.setString(9,nginxParams.getHttpForwardedFor());
pt.executeUpdate();
});
String addrCountSql = "insert into `acc_addr_count` values(?,?)";
addrCountRDD.foreach((VoidFunction) row -> {
System.out.println("row.getString(0)"+row.getString(0));
System.out.println("row.getString(1)"+row.getLong(1));
PreparedStatement pt = dbHelper.connection.prepareStatement(addrCountSql);
pt.setString(1,row.getString(0));
pt.setString(2, String.valueOf(row.getLong(1)));
pt.executeUpdate();
});
}
}
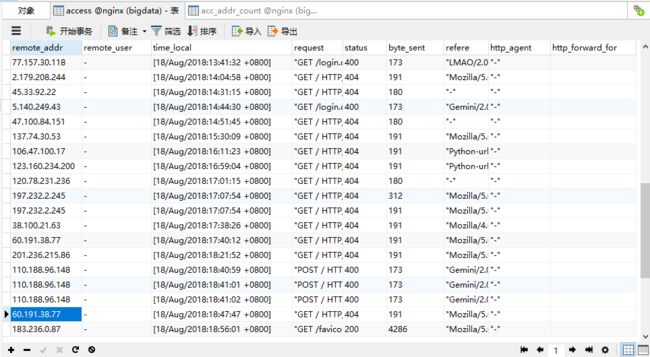
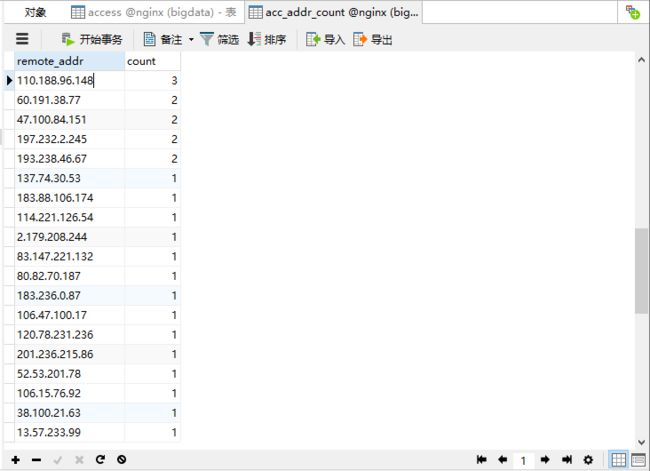
4. 执行完后查看数据库:
5. 总结
5.1 集群中执行
上面例子执行在本地,如果打包运行在服务器,需要执行脚本。
/home/fantj/spark/bin/spark-submit \
--class com.fantj.nginxlog.NginxLogCollect\
--num-executors 1 \
--driver-memory 100m \
--executor-memory 100m \
--executor-cores 3 \
--files /home/fantj/hive/conf/hive-site.xml \
--driver-class-path /home/fantj/hive/lib/mysql-connector-java-5.1.17.jar \
/home/fantj/nginxlog.jar \
并修改setMaster()和sc.textFile()的参数。
5.2 定时任务实现
我们可以将执行脚本打包写一个azkaban的定时job,然后做每天的数据统计。当然,这里面还有很多细节,比如nginx日志按天分割等。但是都是一些小问题。(不熟悉azkaban的:Azkaban 简单入门)