【PaddlePaddle飞桨复现论文】—— 3. 分别采用 经典生成对抗网络GAN 和 深度卷积生成对抗网络DCGAN 实现手写数字生成
1 模型概述
1.1 生成对抗网络GAN
GAN 网络顾名思义,是一种通过对抗的方式,去学习数据分布的生成模型。其中,“对抗”指的是生成网络(Generator)和判别网络(Discriminator)的相互对抗。这里以生成图片为例进行说明:
- 生成网络(G)接收一个随机的噪声z,尽可能的生成近似样本的图像,记为G(z)
- 判别网络(D)接收一张输入图片x,尽可以去判别该图像是真实样本还是网络生成的假样本,判别网络的输出 D(x) 代表 x 为真实图片的概率。如果 D(x)=1 说明判别网络认为该输入一定是真实图片,如果 D(x)=0 说明判别网络认为该输入一定是假图片。
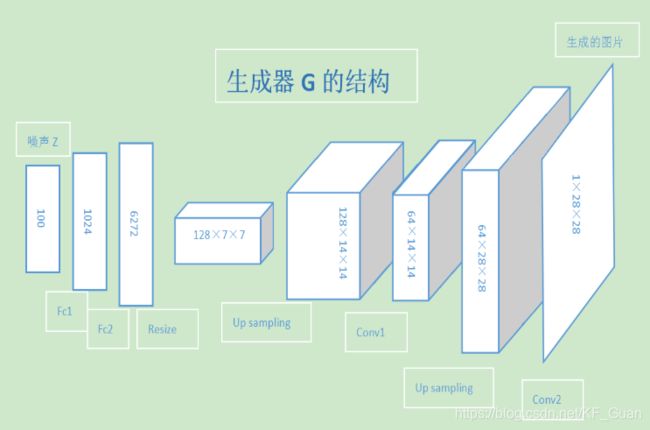
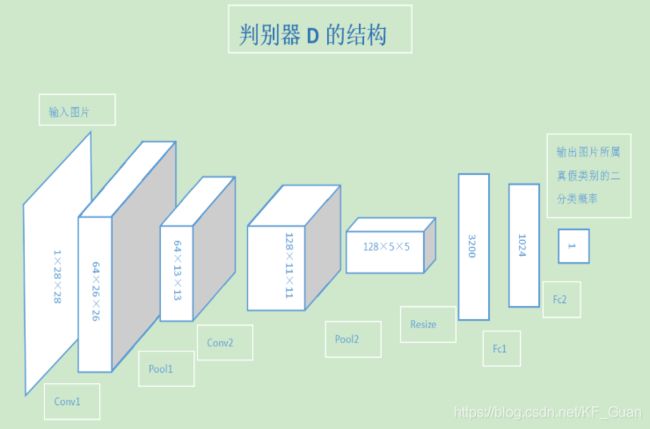
在训练的过程中,两个网络互相对抗,最终形成了一个动态的平衡,上述过程用公式可以被描述为:
min G max D V ( D , G ) = E x ∼ P data ( x ) [ log D ( x ) ] + E ≈ p z ( z ) [ log ( 1 − D ( G ( z ) ) ) ] \min _{G} \max _{D} V(D, G)=\mathbb{E}_{x \sim P_{\text {data }}(x)}[\log D(x)]+\mathbb{E}_{\approx p_{z}(z)}[\log (1-D(G(z)))] GminDmaxV(D,G)=Ex∼Pdata (x)[logD(x)]+E≈pz(z)[log(1−D(G(z)))]
在最理想的情况下,G 可以生成与真实样本极其相似的图片G(z),而 D 很难判断这张生成的图片是否为真,对图片的真假进行随机猜测,即D(G(z))=0.5。
下图展示了生成对抗网络的训练过程,假设在训练开始时,真实样本分布、生成样本分布以及判别模型分别是图中的黑线、绿线和蓝线。在训练开始时,判别模型是无法很好地区分真实样本和生成样本的。接下来当我们固定生成模型,而优化判别模型时,优化结果如第二幅图所示,可以看出,这个时候判别模型已经可以较好地区分生成数据和真实数据了。第三步是固定判别模型,改进生成模型,试图让判别模型无法区分生成图片与真实图片,在这个过程中,可以看出由模型生成的图片分布与真实图片分布更加接近,这样的迭代不断进行,直到最终收敛,生成分布和真实分布重合,判别模型无法区分真实图片与生成图片。
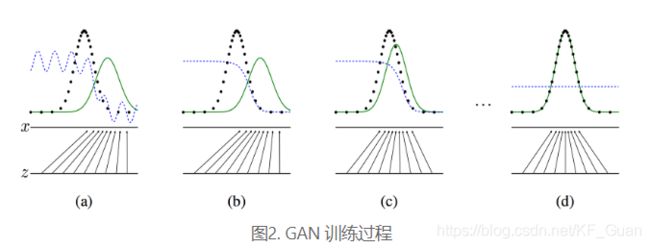
1.2 深度卷积生成对抗网络DCGAN
DCGAN 是深层卷积网络与 GAN 的结合,其基本原理与 GAN 相同,只是将生成网络和判别网络用两个卷积网络(CNN)替代。为了提高生成样本的质量和网络的收敛速度,论文中的 DCGAN 在网络结构上进行了一些改进:
- 取消 pooling 层:在网络中,所有的pooling层使用步幅卷积(strided convolutions)(判别器)和微步幅度卷积(fractional-strided convolutions)(生成器)进行替换。
- 加入 batch normalization:在生成器和判别器中均加入batchnorm。
使用全卷积网络:去掉了FC层,以实现更深的网络结构。 - 激活函数:在生成器(G)中,最后一层使用Tanh函数,其余层采用 ReLu 函数 ; 判别器(D)中都采用LeakyReLu。
DCGAN的结构如下图所示: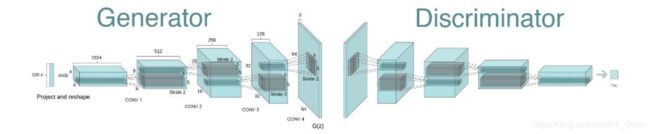
2 模型搭建
2.1 GAN模型核心代码
'''
经典GAN
'''
class G(fluid.dygraph.Layer):
def __init__(self, name_scope):
super(G, self).__init__(name_scope)
name_scope = self.full_name()
# 第一组全连接和BN层
self.fc1 = Linear(input_dim=100, output_dim=1024)
self.bn1 = fluid.dygraph.BatchNorm(num_channels=1024, act='relu')
# 第二组全连接和BN层
self.fc2 = Linear(input_dim=1024, output_dim=128*7*7)
self.bn2 = fluid.dygraph.BatchNorm(num_channels=128*7*7, act='relu')
# 第一组卷积(上采样扩特征)
self.conv1 = Conv2D(num_channels=128, num_filters=64, filter_size=5, padding=2)
self.bn3 = fluid.dygraph.BatchNorm(num_channels=64, act='relu')
# 第二组卷积(上采样扩特征)
self.conv2 = Conv2D(num_channels=64, num_filters=1, filter_size=5, padding=2, act='tanh')
def forward(self, z):
z = fluid.layers.reshape(z, shape=[-1, 100])
y = self.fc1(z)
y = self.bn1(y)
y = self.fc2(y)
y = self.bn2(y)
y = fluid.layers.reshape(y, shape=[-1, 128, 7, 7])
y = fluid.layers.image_resize(y, scale=2)
y = self.conv1(y)
y = self.bn3(y)
y = fluid.layers.image_resize(y, scale=2)
y = self.conv2(y)
return y
class D(fluid.dygraph.Layer):
def __init__(self, name_scope):
super(D, self).__init__(name_scope)
name_scope = self.full_name()
# 第一组卷积池化
self.conv1 = Conv2D(num_channels=1, num_filters=64, filter_size=3)
self.bn1 = fluid.dygraph.BatchNorm(num_channels=64, act='leaky_relu')
self.pool1 = Pool2D(pool_size=2, pool_stride=2)
# 第二组卷积池化
self.conv2 = Conv2D(num_channels=64, num_filters=128, filter_size=3)
self.bn2 = fluid.dygraph.BatchNorm(num_channels=128, act='leaky_relu')
self.pool2 = Pool2D(pool_size=2, pool_stride=2)
# 全连接输出层
self.fc1 = Linear(input_dim=128*5*5, output_dim=1024)
self.bnfc1 = fluid.dygraph.BatchNorm(num_channels=1024, act='leaky_relu')
self.fc2 = Linear(input_dim=1024, output_dim=1)
def forward(self, img):
y = self.conv1(img)
y = self.bn1(y)
y = self.pool1(y)
y = self.conv2(y)
y = self.bn2(y)
y = self.pool2(y)
y = fluid.layers.reshape(y, shape=[-1, 128*5*5])
y = self.fc1(y)
y = self.bnfc1(y)
y = self.fc2(y)
return y
2.2 DCGAN模型核心代码
'''
DCGAN
'''
gf_dim = 64 # 生成器的feature map的基础通道数量,生成器中所有的feature map的通道数量都是基础通道数量的倍数
df_dim = 64 # 判别器的feature map的基础通道数量,判别器中所有的feature map的通道数量都是基础通道数量的倍数
gfc_dim = 1024 * 2 # 生成器的全连接层维度
dfc_dim = 1024 # 判别器的全连接层维度
img_dim = 28 # 输入图片的尺寸
class G(fluid.dygraph.Layer):
def __init__(self, name_scope):
super(G, self).__init__(name_scope)
name_scope = self.full_name()
self.fc1 = Linear(input_dim=100, output_dim=gfc_dim)
self.bn1 = fluid.dygraph.BatchNorm(num_channels=gfc_dim, act='relu')
self.fc2 = Linear(input_dim=gfc_dim, output_dim=gf_dim * 2 * img_dim // 4 * img_dim // 4)
self.bn2 = fluid.dygraph.BatchNorm(num_channels=gf_dim * 2 * img_dim // 4 * img_dim // 4, act='relu')
self.deconv1 = fluid.dygraph.Conv2DTranspose(
num_channels=gf_dim*2,
num_filters=gf_dim*2,
filter_size=5,
stride=2,
dilation=1,
padding=2,
output_size=[14, 14],
act='relu'
)
self.deconv2 = fluid.dygraph.Conv2DTranspose(
num_channels=gf_dim*2,
num_filters=1,
filter_size=5,
stride=2,
dilation=1,
padding=2,
output_size=[28, 28],
act='tanh'
)
def forward(self, z):
z = fluid.layers.reshape(z, shape=[-1, 100])
y = self.fc1(z)
y = self.bn1(y)
y = self.fc2(y)
y = self.bn2(y)
y = fluid.layers.reshape(y, shape=[-1, gf_dim*2, img_dim//4, img_dim//4])
y = self.deconv1(y)
y = self.deconv2(y)
return y
class D(fluid.dygraph.Layer):
def __init__(self, name_scope):
super(D, self).__init__(name_scope)
name_scope = self.full_name()
self.conv1 = Conv2D(
num_channels=1,
num_filters=df_dim,
filter_size=5,
stride=1,
padding=0,
act='leaky_relu'
)
self.pool1 = Pool2D(
pool_size=2,
pool_stride=2
)
self.conv2 = Conv2D(
num_channels=df_dim,
num_filters=df_dim * 2,
filter_size=5,
stride=1,
padding=0,
)
self.pool2 = Pool2D(
pool_size=2,
pool_stride=2
)
self.bn1 = fluid.dygraph.BatchNorm(num_channels=df_dim*2, act='leaky_relu')
self.fc1 = Linear(input_dim=2048, output_dim=dfc_dim)
self.bn2 = fluid.dygraph.BatchNorm(num_channels=dfc_dim, act='leaky_relu')
self.fc2 = Linear(input_dim=dfc_dim, output_dim=1, act='sigmoid')
def forward(self, img):
y = self.conv1(img)
y = self.pool1(y)
y = self.conv2(y)
y = self.pool2(y)
y = self.bn1(y)
y = fluid.layers.reshape(y, [y.shape[0], -1])
y = self.fc1(y)
y = self.bn2(y)
y = self.fc2(y)
return y
3 模型训练以及结果
GAN:
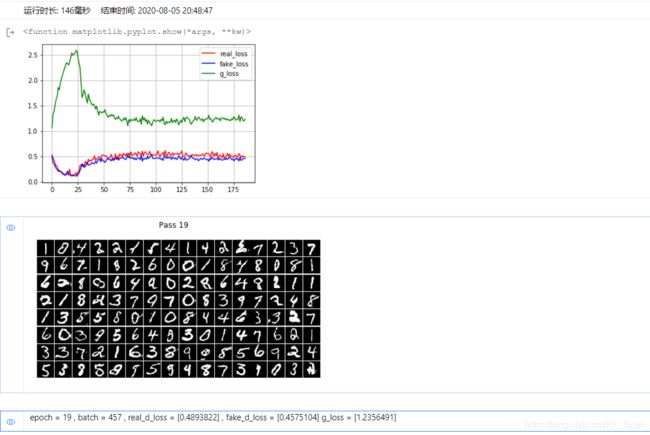
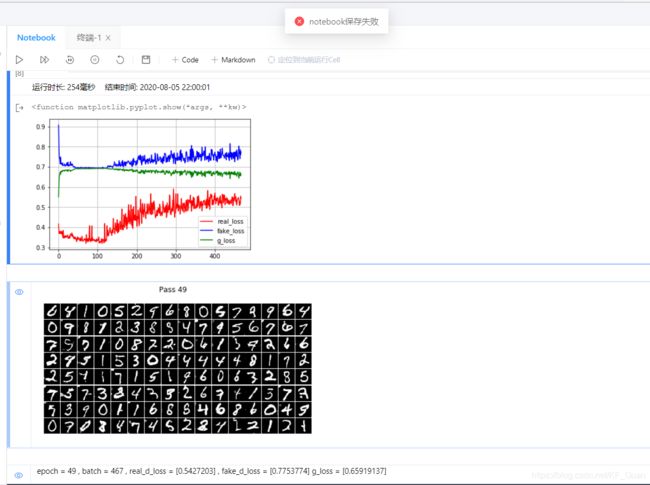
DCGAN:
点击链接获取完整代码:https://aistudio.baidu.com/aistudio/projectdetail/688344