rabbitmq支持两个消费者同时提取数据吗_深入理解:一文讲透RabbitMQ
点击蓝色“码猿技术专栏”关注我哟
加个“星标”,每天干货推送!
![]()
- 出身:诞生于金融行业的消息队列
- 语言:Erlang
- 协议:AMQP(Advanced Message Queuing Protocol 高级消息队列协议)
- 关键词:内存队列,高可用,一条消息
队列结构

- Producer/Consumer:生产者消费者
- Exchange:交换器,可以理解为队列的路由逻辑,交换器主要有三种,图中是Direct交换器
- Queue:队列
- Binding:绑定关系,实际是交换器上映射队列的规则
发送和消费一条消息
在上图的模式下,交换器的类型为Direct,伪代码表示消息的生产和消费
消息生产
#消息发送方法
#messageBody 消息体
#exchangeName 交换器名称
#routingKey 路由键
publishMsg(messageBody,exchangeName,routingKey){
......
}
#消息发送
publishMsg("This is a warning log","exchange","log.warning");

RoutingKey=log.warning,和队列A与交换器的绑定一致,所以消息被路由到了队列A上。
消息消费
对于消息消费而言,消费者直接指定要消费的队列即可,比如指定消费队列A的数据。
需要注意的是,在消费者消费完成数据后,返回给RabbitMq ACK消息,RabbitMq会删掉队列中的该条信息。

多种消息路由模式
在Exchange这个模块上,RabbitMq主要支持了Direct,Fanout,Topic三种路由模式,RabbitMq在路由模式上下功夫,也说明了他在设计上想要满足多样化的需求。

Direct和Fanout模式比较好理解,类似于单播和广播模式,Topic模式比较有意思,它支持自定义匹配规则,按照规则把所有满足条件的消息路由到指定队列,能够帮助开发者灵活应对各类需求。
消息的存储
RabbitMQ的消息默认是在内存里的,实际上不光是消息,Exchange路由等信息实际都在内存中。内存的优点是高性能,问题在于故障后无法恢复。所以RabbitMQ也支持持久化的存储,也就是写磁盘。
要在RabbitMQ中持久化消息,要同时满足三个条件:
- 消息投体时使用持久化投递模式
- 目标交换器是配置为持久化的
- 目标队列是配置为持久化的
RabbitMQ持久化消息的方式是常见的写日志方式:
- 当一条持久化消息发送到持久化的Exchange上时,RabbitMQ会在消息提交到日志文件后,才发送响应。
- 一旦这条消息被消费后,RabbitMQ会将会把日志中该条消息标记为等待垃圾收集,之后会从日志中清除。
- 如果出现故障,自动重建Exchange,Bindings和Queue,同时通过重播持久化日志来恢复消息。
消息持久化的优缺点很明显,拥有故障恢复能力的同时,也带来了性能的急剧下降。同时,由于RabbitMQ默认情况下是没有冗余的,假设一个持久化节点崩溃,一致到该节点恢复前,消息和队列都无法恢复。
消息投递模式
1.发后即忘
RabbitMQ默认发布消息是不会返回任何结果给生产者的,所以存在发送过程中丢失数据的风险。
2.AMQP事务
AMQP事务保证RabbitMQ不仅收到了消息,并成功将消息路由到了所有匹配的订阅队列,AMQP事务将使得生产者和RabbitMQ产生同步。
虽然事务使得生产者可以确定消息已经到达RabbitMQ中的对应队列,但是却会降低2~10倍的消息吞吐量。
3.发送方确认
开启发送方确认模式后,消息会有一个唯一的ID,一旦消息被投递给所有匹配的队列后,会回调给发送方应用程序(包含消息的唯一ID),使得生产者知道消息已经安全到达队列了。
如果消息和队列是配置成了持久化,这个确认消息只会在队列将消息写入磁盘后才会返回。如果RabbitMQ内部发生了错误导致这条消息丢失,那么RabbitMQ会发送一条nack消息,当然我理解这个是不能保证的。
这种模式由于不存在事务回滚,同时整体仍然是一个异步过程,所以更加轻量级,对服务器性能的影响很小。
RabbitMQ RPC
一般的异步服务间,可能会用两组队列实现两个服务模块之前的异步通信,有趣的是RabbitMQ就内建了这个功能。
RabbitMQ支持消息应答功能,每个AMQP消息头中有一个Reply_to字段,通过该字段指定消息返回到的队列名称(这是一个私有队列)消息的生产者可以监听该字段对应的队列。

RabbitMQ集群
RabbitMQ集群的设计目标:
- 允许消费者和生产者在RabbitMQ节点崩溃的情况下继续运行
- 能过通过添加节点来线性扩展消息通信吞吐量
从实际结果看,RabbitMQ完成设计目标上并不十分出色,主要原因在于默认的模式下,RabbitMQ的队列实例子只存在在一个节点上(虽然后续也支持了镜像队列),既不能保证该节点崩溃的情况下队列还可以继续运行,也不能线性扩展该队列的吞吐量。
集群结构
RabbitMQ内部的元数据主要有:
- 队列元数据-队列名称和属性
- 交换器元数据-交换器名称,类型和属性
- 绑定元数据-路由信息
虽然RabbitMQ的队列实际只会在一个节点上,但元数据可以存在各个节点上。举个例子来说,当创建一个新的交换器时,RabbitMQ会把该信息同步到所有节点上,这个时候客户端不管连接的那个RabbitMQ节点,都可以访问到这个新的交换器,也就能找到交换器下的队列。

如上图所示,队列A的实例实际只在一个RabbitMQ节点上,其它节点实际存储的是只想该队列的指针。
为什么RabbitMQ不在各个节点间做复制了,《RabbitMQ实战》给出了两个原因:
- 存储成本-RabbitMQ作为内存队列,复制对存储空间的影响,毕竟内存是昂贵而有限的
- 性能损耗-发布消息需要将消息复制到所有节点,特别是对于持久化队列而言,性能的影响会很大
我理解成本这个原因并不完全成立,复制并不一定要复制到所有节点,比如一个队列可以只做两个副本,复制带来的内存成本可以交给使用方来评估,毕竟在内存中没有堆积的情况下,实际上队列是不会占用多大内存的。
还有一点是RabbitMQ本身并没有保证消息消费的有序性,所以实际上队列被Partition到各个节点上,这样才能真正达到线性扩容的目的(以RabbitMQ的现状来说,单队列实际是无法扩容的,只有在业务层做切分)。
注:RabbitMQ集群中的节点可以是内存节点也可以是磁盘节点,但要求至少有一个磁盘节点,这样出现故障时才能恢复数据。
镜像队列
镜像队列架构
RabbitMQ自己也考虑到了我们之前分析的单节点长时间故障无法恢复的问题,所以RabbitMQ 2.6.0之后它也支持了镜像队列,换个说法也就是副本。
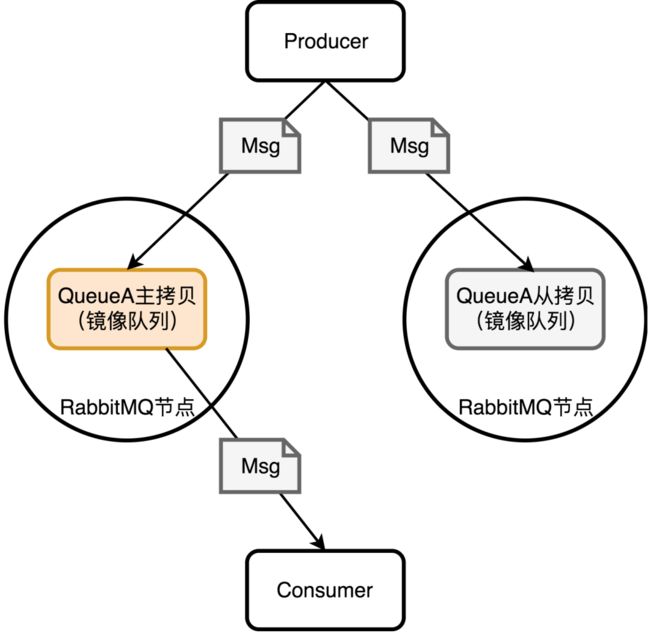
除了发送消息,所有的操作实际都在主拷贝上,从拷贝实际只是个冷备(默认的情况下所有RabbitMQ节点上都会有镜像队列的拷贝),如果使用消息确认模式,RabbitMQ会在主拷贝和从拷贝都安全的接受到消息时才通知生产者。
从这个结构上来看,如果从拷贝的节点挂了,实际没有任何影响,如果主拷贝挂了,那么会有一个从新选主的过程,这也是镜像队列的优点,除非所有节点都挂了,才会导致消息丢失。重新选主后,RabbitMQ会给消费者一个消费者取消通知(Consumer Cancellation),让消费者重连新的主拷贝。
镜像队列原理
1.RabbitMQ结构

- AMQPQueue:负责AMQP协议相关的消息处理,包括接收消息,投递消息,Confirm消息等
- BackingQueue:提供AMQQueue调用的接口,完成消息的存储和持久化工作
BackingQueue由Q1,Q2,Delta,Q3,Q4五个子队列构成,在Backing中,消息的生命周期有四个状态:
- Alpha:消息的内容和消息索引都在RAM中。(Q1,Q4)
- Beta:消息的内容保存在Disk上,消息索引保存在RAM中。(Q2,Q3)
- Gamma:消息的内容保存在Disk上,消息索引在DISK和RAM上都有。(Q2,Q3)
- Delta:消息内容和索引都在Disk上。(Delta)
这里以持久化消息为例(可以看到非持久化消息的生命周期会简单很多),从Q1到Q4,消息实际经历了一个RAM->DISK->RAM这样的过程,BackingQueue这么设计的目的有点类似于Linux的Swap,当队列负载很高时,通过将部分消息放到磁盘上来节省内存空间,当负载降低时,消息又从磁盘回到内存中,让整个队列有很好的弹性。因此触发消息流动的主要因素是:1.消息被消费;2.内存不足。
RabbitMQ会更具消息的传输速度来计算当前内存中允许保存的最大消息数量(Traget_RAM_Count),当:内存中保存的消息数量+等待ACK的消息数量>Target_RAM_Count时,RabbitMQ才会把消息写到磁盘上,所以说虽然理论上消息会按照Q1->Q2->Delta->Q3->Q4的顺序流动,但是并不是每条消息都会经历所有的子队列以及对应的生命周期。
从RabbitMQ的Backing Queue结构来看,当内部不足时,消息要经历多个生命周期,在Disk和RAM之间置换,者实际会降低RabbitMQ的处理性能(后续的流控就是关联的解决方法)。
2.镜像队列结构

所有对镜像队列主拷贝的操作,都会通过Guarented Multicasting(GM)同步到各个Salve节点,Coodinator负责组播结果的确认。
GM是一种可靠的组播通信协议,保证组组内的存活节点都收到消息。

GM的主播并不是由Master节点来负责通知所有Slave的(目的是为了避免Master压力过大,同时避免Master失效导致消息无法最终Ack),RabbitMQ把一个镜像队列的所有节点组成一个链表,由主拷贝发起,由主拷贝最终确认通知到了所有的Slave,而中间由Slave接力的方式进行消息传播。
从这个结构来看,消息完成整个镜像队列的同步耗时理论上是不低的,但是由于RabbitMQ消息的消息确认本身是异步的模式,所以整体的吞吐量并不会受到太大影响。
流控
当RabbitMQ出现内存(默认是0.4)或者磁盘资源达到阈值时,会触发流控机制,阻塞Producer的Connection,让生产者不能继续发送消息,直到内存或者磁盘资源得到释放。
RabbitMQ基于Erlang/OTP开发,一个消息的生命周期中,会涉及多个进程间的转发,这些Erlang进程之间不共享内存,每个进程都有自己独立的内存空间,如果没有合适的流控机制,可能会导致某个进程占用内存过大,导致OOM。因此,要保证各个进程占用的内容在一个合理的范围,RabbitMQ的流控采用了一种信用证机制(Credit),为每个进程维护了四类键值对:
- {credit_from,From}-该值表示还能向消息接收进程From发送多少条消息
- {credit_to,To}-表示当前进程再接收多少条消息,就要向消息发送进程增加Credit数量
- credit_blocked-表示当前进程被哪些进程block了,比如进程A向B发送消息,那么当A的进程字典中{credit_from,B}的值为0是,那么A的credit_blocked值为[B]
- credit_deferred-消息接收进程向消息发送进程增加Credit的消息列表,当进程被Block时会记录消息信息,Unblock后依次发送这些消息
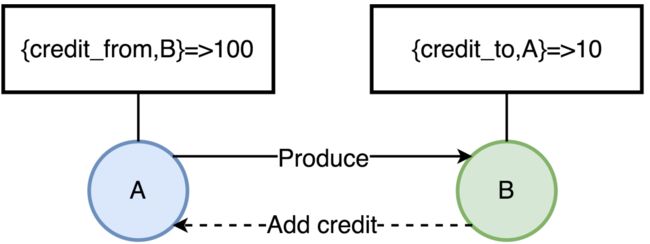
如图所示,A进程当前可以发送给B的消息有100条,每发一次,值减1,直到为0,A才会被Block住。B消费消息后,会给A增加新的Credit,这样A才可以持续的发送消息。这里只画了两个进程,多进程串联的情况下,这中影响也就是从底向上传递的。
想学习Java工程化、分布式架构、高并发、高性能、深入浅出、微服务架构、Spring,MyBatis,Netty源码分析等技术可以加群:479499375,群里有阿里大牛直播讲解技术,以及Java大型互联网技术的视频免费分享给大家,欢迎进群一起深入交流学习。
总结
注:本文基于的RabbitMQ材料可能较为陈旧,新的RabbitMQ可能会有不同的功能特性
整体来看,RabbitMQ的功能比较丰富(可惜没有看到延迟,优先级等功能),更适用于偏实时的业务场景,与Kafka这样的队列定位上有明显的区别。它本身应该是一个简单健壮的组件,但如果要应用在一个大规模的分布式系统中,实际还是需要做一些外部的再次开发,以解决我们前面提到的队列存储单点,流控等问题。直观上看它的运维成本是会比较高的,需要使用方有一定的经验。
原文:https://sq.163yun.com/blog/article/229026816937607168
作者:Java大蜗牛
end
往期推荐
不懂分布式事务,别说你懂微服务!
宕机了,Redis数据丢了怎么办?
单线程的Redis有哪些 "慢" 动作?
头秃系列,二十三张图带你从源码分析Spring Boot 启动流程~
头秃了,Spring Boot 自动配置源码解析~
三十二张图告诉你,Jenkins构建SpringBoot有多简单~
一次打包引发的思考,原来maven还可以这么玩
分享几个压箱底儿的实用工具~
好文章!点个在看!