hdfs读写流程_5000 字干货 | 大数据之 HDFS 图文详解


全文没有代码,不要慌,主要是概念结合图片进行理解,觉得对你有用的话,坚持看完并提出建议。
大纲
- HDFS 基本概念及特性
- NameNode 和 DataNode
- 数据冗余备份
- 数据副本存放策略
- 机架感知
- FsImage 和 EditLog
- SecondaryNameNode
- HDFS 读写步骤
- 安全模式
- 几个问答题
什么是 HDFS
The Hadoop Distributed File System (HDFS) is a distributed file system designed to run on commodity hardware.
从以上官方描述可以看出,HDFS 是 Hadoop 分布式文件系统,并且运行在普通硬件上。这就意味着 HDFS 不需要优秀的硬件资源、高昂的硬件成本,只需要简单的物理机组成分布式集群,HDFS 使用横向拓展(增加机器)来提高存储容量,而非纵向扩展(提高单个机器的配置)。
HDFS 并非唯一的分布式文件系统,还有 GFS、TFS 等,但 HDFS 是使用最多的开源分布式文件存储系统,具有高度容错(highly fault-tolerant)及低成本的特点。
HDFS 的使命
- 接受硬件故障
HDFS 可以运行在成百上千台廉价的物理机上,存储着海量的数据,机器出故障是常见的一件事, 作为一个优秀的文件存储系统,HDFS 能够接受机器故障,它会进行故障检测以及恢复故障文件。 - 流式数据访问
运行在 HDFS 上的应用程序能够访问数据流,HDFS 主要用于批处理。
看到流数据访问时,卡了我很久,没明白流式数据、实时数据、流式计算、实时计算有什么区别,经过一番查阅,发现这些概念或许不应该放在一起作比较。
流式数据:理解为不是一次性加载完的数据,比如看电影,数据是一帧一帧过来的,动态的;
实时数据:实时产生的数据,和流式数据区别不大,有时候也会叫做 实时流数据;
实时计算:处理实时数据,区别与离线计算(处理历史数据);
流式计算:这与实时计算不应该一起比较,实时计算强调的是数据的实时性,而流式计算强调的是计算方法,理解为 Java8 中的流式数据处理;
- 支持大数据集
HDFS 存储的典型文件是 GB 或 TB 大小,一个磁盘无法存储大文件,HDFS 将文件切分成小块,分别存储在不同服务器的磁盘上,通过网络进行连接。 - 简单的一致性模型(write-once-read-many)
HDFS 通常是一次写入,多次读取,不支持随机写操作,可以在文件末尾追加。这种方式简化了数据一致性问题。 - 移动计算比移动数据更划算
针对海量数据的处理,如果需要将数据移动到计算程序所在的节点,受网络的限制,计算将变得非常缓慢。HDFS 提供接口将计算程序移动到数据所在的位置,移动应用程序比移动海量数据效率高得多。 - 跨硬件和平台的可移植性
HDFS 易于从一个平台移植到另一个平台,这有助于 HDFS 成为大量应用程序的首选。HDFS 由 Java 编写,只要支持 Java 语言的机器便可以运行 HDFS NameNode 或 DataNode,这也是利用了 Java 的跨平台特性。
NameNode 和 DataNode
HDFS 是 master/slave 架构,在分布式中,一主多从的架构很常见。NameNode 主要存储和管理数据的元信息以及接受客户端的请求,DataNode 主要存储文件,所有的元信息都存储在一个 NameNode 节点上,这样极大地简化了架构的复杂性。
文件以 block(块)的形式存储在 DataNode 上,一个大文件存储到 HDFS 上时,会被切分成很多 block,这个过程是由 HDFS 自己完成的。单个 block 默认大小 128M,每个 block 默认备份三份,存储在不同的节点,冗余备份保证了 HDFS 文件的可靠性。
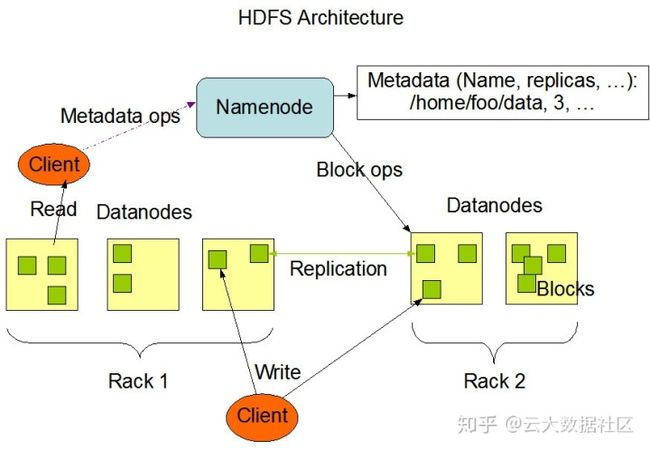
NameNode:
- 接受用户请求;
- 维护文件系统的目录结构;
- 管理文件与 block 之间的关系以及 block 与 DataNode 之间的关系;
DataNode:
- 存储文件;
- 文件被分成 block 存储在磁盘上;
- 为保证数据安全,文件会有多个副本,默认是 3 份;
注意点
- 目录仅仅是元信息,没有冗余备份,文件才有备份;
- 一个物理节点可以作为一个 DataNode,也可以在一个节点上启动两个 DataNode,只是通常不会这么做;
- HDFS 不支持硬链接或软连接;
- HDFS 中的 block 大小以及备份的数量都是可配置的;
Blockreport
NameNode 会与 DataNode 之间会通过心跳机制进行通信,每个 DataNode 会定期向 NameNode 发送心跳以及 Blockreport ,Blockreport 上包含了该 DataNode 上的 block 列表,这种心跳机制也是 NameNode 检测 DataNode 是否存活的依据。
默认发送心跳的时间是 3 秒,默认判断 DataNode 是否存活的时间是 10 分钟,也就是 10 分钟接收不到该 DataNode 的心跳,则认为它已经宕机,不会再与该 DataNode 发送读写操作。
重写副本的触发条件:DataNode 节点不可用、某一个备份文件处于故障状态、DataNode 磁盘出现故障、备份数量发生改变。
数据冗余备份
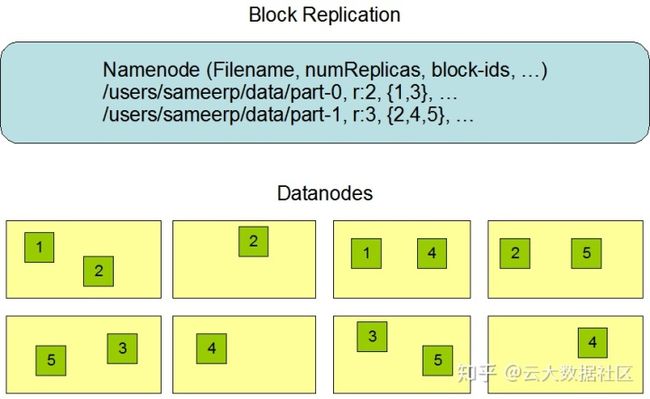
一个文件的元信息如下图所示,包含了文件名,备份的份数,对应的 block id。
以文件 part-0 为例,备份数是 2,block id 是 1 和 3,在 Datanodes 中可以找到,id 为 1 的 block 有两个,id 为 3 的 block 有两个,分别存储在不同 Datanode。两个不同 block id 组合起来就是一个完整的名称为 part-0 的文件。
数据副本存放策略
大型 HDFS 实例通常分布运行在由许多机架组成的集群中,一个机房中有很多机架,一个机架上有多个服务器,不同机架的机器通信需要经过交换机,受带宽等因素的影响,需要更高的网络通信成本。所以默认 3 个副本的情况下,采用如下的放置策略:
- 在机架 1 上放置第一个副本;
- 在另一个机架 2 上放置第二副本;
- 副本三与副本二放置在同一个机架上;
- 如果有更多的副本,则随机选择机架,每个机架的副本数量有个上限值,计算方式通常是:(replicas - 1) / racks + 2
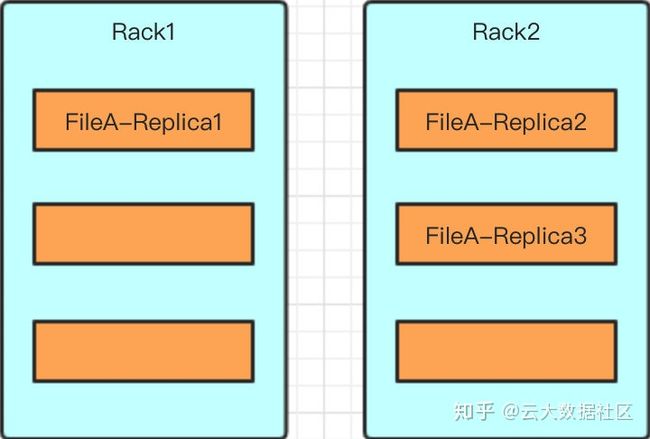
这样放置的好处:
- 避免一个机架出故障,导致所有数据丢失;
- 同一个机架上的节点通信网络会比不同机架节点通信更好,副本二与副本三放置在同一个机架能够节省带宽;
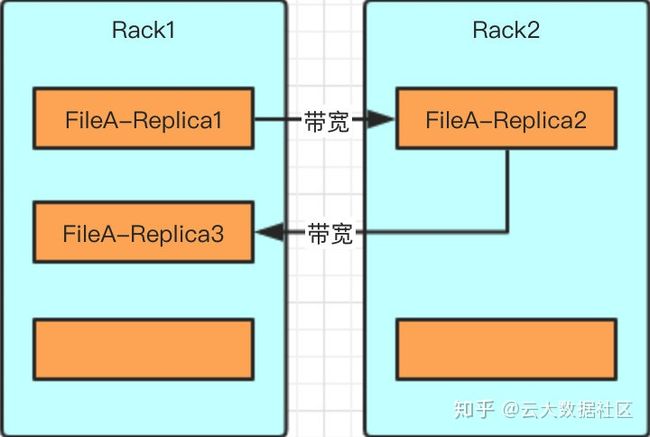
从单个文件看来,考虑带宽似乎没有多大意义,但是对于大规模数据的情况下,请求并发量大时,网络是非常重要的一个因素,特别是对于写请求,这里要了解 HDFS 写的流程,先简单介绍写流程,后面会详细讲解。
因为写副本的过程类似于流水线,先写副本一,但这里写完后就将写成功的结果返回给客户端了。之后由副本一将内容写到副本二,接着由副本二将内容写到副本三。
假设副本三和副本一放置在一个机架上,那么就会产生两次不同机架间的写操作。而目前的情况是副本二和副本三在同一个机架,机架间的写操作只会发生在副本一到副本二之间,副本二和副本三的写操作是在同一个机架,节省了网络流量。
话不多说,用图说话:

机架感知
了解 HDFS 默认三份备份后,会想到一个问题,NameNode 怎么知道 DataNode 在哪个机架呢?写文件时怎么能正确知道 DataNode 是否满足上面的备份策略呢?
Hadoop 组件有机架感知(Rack Awareness)功能,默认是关闭的,可以通过配置文件开启,在 core-site.xml 文件中有此配置项:net.topology.script.file.name,以下是官方文档对该配置项的描述。
net.topology.script.file.name
The default implementation of the DNSToSwitchMapping. It invokes a script specified in net.topology.script.file.name to resolve node names. If the value for net.topology.script.file.name is not set, the default value of DEFAULT_RACK is returned for all node names.
该配置项的值是一个脚本的路径,当没有配置时,默认值为 DEFAULT_RACK,DEFAULT_RACK 就是将所有 DataNode 认为是一个机架,物理上它们可能是在不同机架。此时 HDFS 并不知道每个 DataNode 对应的真实 rack,就会将副本随机写到 DataNode 上,不一定满足上面提到的副本放置策略。
开启机架感知后,指定的脚本接受一个入参,DataNode 的 ip,计算完返回一个结果,DataNode 所在的机架 id,格式如下:/myrack/myhost eg: /192.168.100.0/192.168.100.5
NameNode 在启动时,会判断该配置是否为空,如果不为空,说明开启了机架感知。NameNode 会根据配置找到该脚本,当接受到 DataNode 的心跳时,会运行该脚本,将其 ip 作为入参,将输出的结果作为该 DataNode 的 rack id,保存为一个 map 的形式存放在内存中。
开启机架感知后,NameNode 就能够正确识别每个 DataNode 所属的机架,能够轻松实现上述的副本存放策略。
读取时如何选择副本
为了最大的减少带宽和延迟,HDFS 读取文件采用就近原则,如果与客户端在同一机架上的 DataNode 上存有副本,则直接读取该副本。如果 HDFS 是跨数据中心的,则优先选择同一数据中心的副本。
FsImage 和 EditLog
对元数据的每一次更改都会记录在名为 EditLog 的文件中,该文件由 NameNode 维护,存储在 NameNode 节点的本地磁盘,比如在 HDFS 中新建一个文件、修改备份因子都会记录在 EditLog 文件中。
整个文件系统的信息,包括文件与 block 的映射和文件系统的属性,存储在一个名为 FsImage 的文件中,该文件也存储在 NameNode 的本地磁盘。
- EditLog:保存元数据更改记录,一个文件只记录一段时间的信息,该文件会在某些时刻合并到 FsImage,FsImage 中的信息要比 EditLog 记录的信息慢一步。
- FsImage:保存文件系统目录树以及文件和 block 的对应关系,理解为元数据镜像文件,某个时刻整个 HDFS 系统文件信息的快照;
假设没有 EditLog,每次写操作对元数据进行了更改,都通过写 FsImage 的方式进行,那么必定会大大降低写操作效率。因为 FsImage 中存储的是 HDFS 文件系统所有的元数据信息,随着数据量增大,该文件也会增大,每次都对它进行写操作,耗时会很长,所以通过 EditLog 作为临时文件就解决了该问题,只需要定期将 EditLog 中的内容合并到 FsImage 即可。
如果对元数据的修改每次都以写磁盘上文件的方式进行,那必定会降低读写效率,NameNode 实际上将 FsImage 和 EditLog 中记录的元数据信息加载到内存中。
当 NameNode 启动时,会从磁盘读取 FsImage 文件将元信息加载到内存,再读取 EditLog 文件中的信息将元数据同步至最新状态,NameNode 只会在启动的时候合并 FsImage 和 EditLog 文件。
如果长时间没有重启 NameNode,EditLog 文件将会变得非常大,写数据将会越来越慢,对于高并发、数据量大的场景,写操作很慢肯定是不能容忍的。只有下一次重启 NameNode 时才会将 EditLog 合并到 FsImage,但生产环境是很少重启的,必须保证服务不间断,并且 EditLog 文件非常大的话,会导致 NameNode 重启时间变长。
那么这个问题如何解决呢?HDFS 引入了 SecondaryNameNode。
SecondaryNameNode
SecondaryNameNode 不是 NameNode 的备份,不是为了做高可用(HA)的。
checkpoint 是触发 FsImage 和 EditLog 文件进行合并的条件,形成新的 FsImage,也就是检查点。到达 checkpoint 时,会将 FsImage 和 EditLog 文件读取到内存,并通过 http 的方式发送给 SecondaryNamenode,由 SecondaryNamenode 完成合并,再发回给 NameNode。
checkpoint 的触发条件有两个:
- 指定时间间隔,通过
dfs.namenode.checkpoint.period进行配置,默认是一小时; - 指定 EditLog 文件大小,通过
dfs.namenode.checkpoint.txns进行配置,默认是 1 百万条事务记录;
只要达到任何一个触发条件,就会将 EditLog 合并到 FsImage。
FsImage 和 EditLog 合并过程
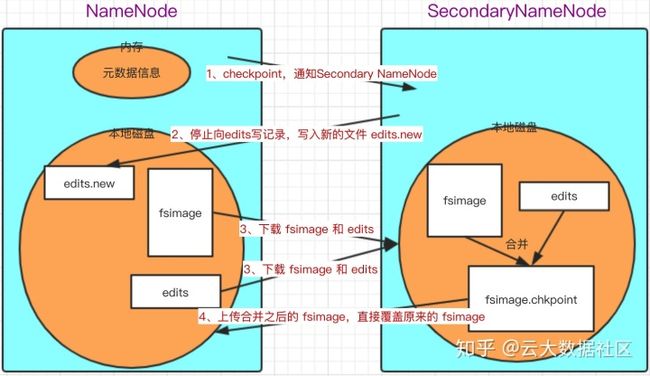
- 检查是否触发 checkpoint 条件;
- 触发 checkpoint,NameNode 停止向 edits 中写新的记录,另外生成一个 edits.new 文件,将新的事务记录在此文件中;
- SecondaryNameNode 通过 HTTP 请求,从 NameNode 下载 fsimage 和 edits 文件,合并生成 fsimage.chkpoint 文件;
- SecondaryNameNode 再将新生成的 fsimage.chkpoint 上传到 NameNode 并重命名为 fsimage,直接覆盖旧的 fsimage,实际上中间的过程还有一些 MD5 完整性校验,检查文件上传下载后是否完整;
- 将 edits.new 文件重命名为 edits 文件,旧的 edits 文件已经合并到 fsimage;
注:SecondaryNameNode 也会将 fsimage 等信息载入内存,上图把这一块省略了。
读写详细步骤
读操作(简略版)
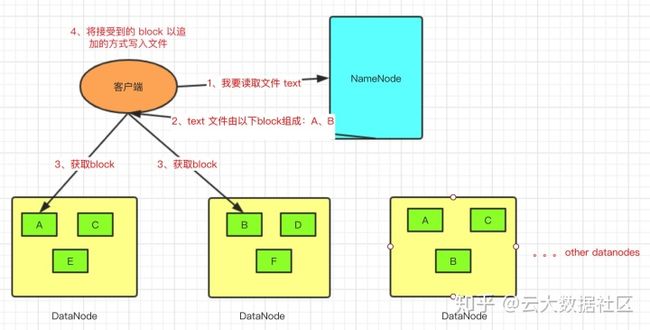
- Client 向 NameNode 发起读请求;
- NameNode 将请求文件的元信息返回给 Client;
- Client 根据元信息去对应的 datanode 上取 block,并以追加的方式写文件,完成 block 的拼接工作;
- 最后组成完整的文件;
读取 block 并不是一整块拿下来,读取文件都是以二进制流的方式,所以会先创建文件,再将数据内容追加写入文件。
写操作(简略版)
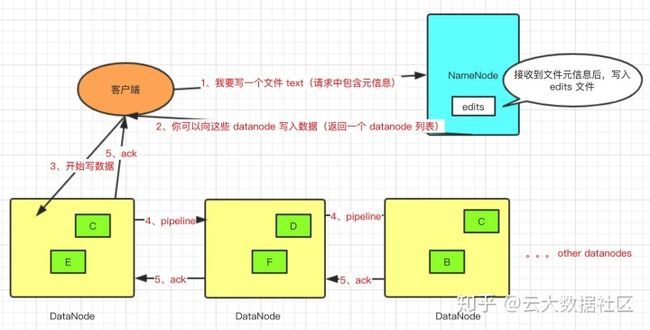
1、客户端发起写文件请求,会带上元数据信息;
2、NameNode 接受到请求后,会做一些校验工作,如文件是否存在、客户端是否有写权限等,并将写操作记录到 edits 文件中,如果写失败,比如断电了,edits 文件中还记录了上一次操作的信息,能够复原上一次操作;
3、NameNode 将返回每个 block 存放的 DataNode 列表;
4、客户端从 block 所属的 DataNode 列表中,假设备份 3 份,根据就近原则开始写操作,比如选择 DataNode1,在写的同时,DataNode1 会将文件信息传递给 DataNode2,DataNode2 接收到后再传递给 DataNode3,DataNode 接收到信息后,再依次返回确认信息,就像流水线一样,1 -> 2 -> 3,这个过程叫 Replication Pipelining。
5、DataNode 写完之后,会将结果返回给客户端,收到一个成功的结果,客户端就认为写操作已经完成了,剩余两个备份会异步进行。假设 2 -> 3 的过程中写失败了, 3 号机器宕机,2 号收不到成功确认 ack,则会告知 NameNode,NameNode 再重新指定一个 DataNode 进行写操作,1、2 随机选择一个作为写操作的发起端,保证最后是 3 份备份。
使用 Pipeline 的方式进行写操作,不需要客户端写三份备份,因为客户端写文件时是通过网络传输,所有备份由客户端写的话将严重影响写操作的速度。
安全模式
NameNode 启动时,会从磁盘读取 FsImage 和 EditLog 文件至内存,然后等待 DataNode 发送 Blockreport,此时 NameNode 处于只读状态,这时不能进行写操作,这个过程 NameNode 处于安全模式。当 DataNode 将 block 的信息发送给 NameNode,大多数 block 处于可用状态时,NameNode 会自动退出安全模式。也可以通过 hdfs 命令行或 NameNode 页面对安全模式进行开关操作。
问答形式
HDFS 中的文件写入只支持单个写入者,而且写操作总是以「只添加」方式在文件末尾写数据吗?
- HDFS 的目标应用场景就是一次写入,多次读取 ;
- 如果要支持随机写,分布式数据的一致性就会受到挑战;随机写文件会破坏原文件元数据,元数据的改动会导致校验和的改动,而 hadoop 会依赖校验和等信息进行文件拆分,以及校验文件合法性,随机写会造成效率很低。
- 如果一定要保证实时的数据一致性,性能牺牲会很大,不适合大数据量少写多读的场景。
为什么HDFS中块(block)不能设置太大,也不能设置太小?
前面我们已经了解过,HDFS 读取数据时是读取 block,再将不同 block 组成完整的文件。
首先得了解寻址时间在这里是指 HDFS 找到目标文件块(block)所需要的时间,如果文件非常多,寻址时间就会更长,如果单个 block 非常大,网络传输的时间就会更长,得出以下结论:
- 文件块越大,寻址时间越短,但磁盘传输时间越长;
- 从磁盘传输的时间明显大于寻址时间,导致程序在处理这块数据时,变得非常慢;
- MapReduce 中的 map 任务通常一次只处理一个 block 的数据,如果块过大,运行速度会变慢;
- 文件块越小,寻址时间越长,但磁盘传输时间越短;
- 存放大量小文件会占用 NameNode 中大量内存来存储元数据,而 NameNode 的内存是有限的,这样不合理;
- 文件块过小,大量小文件导致寻址时间增长,程序花很多时间找 block 位置;
因此,block 适当设置大一些,减少寻址时间,那么传输一个由多个 block 组成的文件的时间主要取决于磁盘的传输速率。
为什么HDFS文件块(block)大小设定为128M?
1、HDFS 中平均寻址时间大概为 10ms;
2、经过前人的大量测试发现,寻址时间为传输时间的 1% 时,为最佳状态;
所以最佳传输时间为 10ms/0.01=1000ms=1s
3、目前磁盘的传输速率普遍为 100MB/s
计算出最佳 block 大小:100MB/s * 1s = 100MB
所以设定 block 大小为 128MB(程序员的世界中,整数都是 2^n)
ps:实际在工业生产中,磁盘传输速率为 200MB/s 时,一般设定 block 大小为 256MB;磁盘传输速率为 400MB/s 时,一般设定 block 大小为 512M;
如果我要存的文件确实都是小文件,那如何处理呢?
存大量小文件也没有关系,因为即使有很多小文件,NameNode 的元数据信息也不会特别特别大,大多数情况都是能存储下来的,只是 HDFS 比较适合存储大文件。
如果某个文件没有达到 block 大小(默认 128M),那么会占用多少空间呢?
文件内容在 DataNode 上占用实际大小的空间。
为什么需要有 FsImage 和 EditLog 来存储元数据?
单独存在磁盘上?
存储在磁盘上的话会导致访问速度非常慢,每次请求文件时都需要访问 NameNode,如果存在磁盘上,NameNode 还需要从磁盘访问元数据信息,如果多个读操作同时请求,延迟将非常高。
单独存在内存中?
存在内存中显然不行,一方面是内存容量问题,尽管一个 block 元信息只占用约 150 byte,但是面对大量文件,内存容量会不够;其次,内存中无法持久化数据,如果机器宕机,内存数据将丢失,元信息都丢失,整个 HDFS 将无法使用。
存一部分内存中作为缓存,比如到了 100M 就刷到磁盘中?
数据分开存储存在的问题是如何保证一致性,并且缓存中的数据也存在丢失的情况,如果机器宕机,缓存中丢失的数据仍然无法恢复。
思考完这几个问题更能理解 HDFS 元数据的管理。
NameNode 维护了哪些信息?
NameNode 维护了两套数据,一个是文件目录与 block 数据块之间的关系,另一个是 block 与 datanode 节点之间的关系。
前一个数据关系是静态的,存放在磁盘上,通过 fsimage 和 edits 文件来维护,这里就涉及到元信息如何保存一致性的问题,就是使用这两个文件以及 SecondaryNameNode 实现的。
后一个数据关系是动态的,不会持久化到磁盘,每当集群启动的时候,会自动建立这些信息
NameNode 已经有 DataNode 的元信息,为什么 DataNode 还需要向 NameNode 定期汇报 block 信息?
因为 datanode 上的数据可能会被手动删除,比如手动去 datanode 上删除掉对应的 block,此时 namenode 中还有该元信息,误以为 block 还存在。
参考来源:
https://hadoop.apache.org/docs/stable/hadoop-project-dist/hadoop-hdfs/HdfsDesign.html
https://blog.csdn.net/l1028386804/article/details/51935169
https://juejin.im/post/5d885bbcf265da039e12fa13
https://www.maiyewang.com/?p=21911
推荐阅读:
http://weixin.qq.com/r/xDk3L4bERNs7rcJM92zW (二维码自动识别)
云大数据社区
微信扫一扫,关注公众号