第四届泰迪杯数据挖掘挑战赛B题数据预处理-数据导入(Matlab)
第四届泰迪杯数据挖掘挑战赛B题数据预处理-数据导入(Matlab)
1数据结构分析
我这次的目的是读取一个月的梯形密度表数据, 按照(日期, 车次, 车站, 上车人数)的数据库表格式保存在元胞数组中。所以拿到“旅客列车梯形密度表(31天)”的数据后,先直接打开原始的xls文件并且使用matlab函数[,,row]=xlsread(filename)查看在元胞组中,信息的结构。打开一两个后,通过观察图1和图2,就可以发现一下数据存储规律。
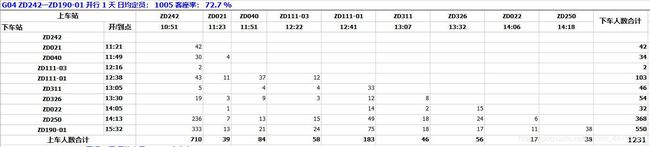
图1 xls文件的信息储存结构
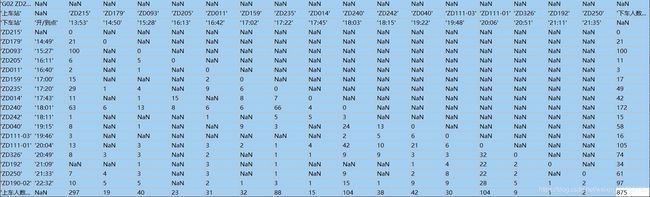
图2 元胞组的信息储存结构
(1)每一张表内储存的都是同一天的数据。
(2)每车次的信息都是一个矩形区域,该矩形长宽比为1:1。那么确定上车站和上车人数合计的位置,就可以确定这个矩形区域的位置。
(3)31张表的结构是一致的。
2代码思路
总的思路是,先读取一张表中每个车次的信息,再合并成相同日期的信息。其次对剩下的表做相同的操作,最后将31张表的信息合并得到31天的信息。
3脚本实现
由于结构的统一,所以我先写好读取一张表中的一个车次矩形区域的信息的代码,再使用for循坏就可以读取到所有信息。
前面说过,矩形区域的位置由上车站和上车人数合计的位置确定。使用strcmp函数在元胞组里找到这两个字符串的位置,即
up_station='上车站';
up_num='上车人数合计';
x1=find(strcmp(row,up_station));%row为存储一张表的元胞组
x2=find(strcmp(row,up_num));
我们也可以找到“下车总人数”的位置来确定信息的位置,但是要有两个循环,遍历一个元胞组,我不太想用。代码如下,
[n1,n2]=size(row)
k=1;
for i=1:n1
for j=1:n2
if find(row{
i,j})==1;
yy(k)=j;
k=k+1
end
end
xx(k-1)=i;
end
我不太确定这个循环是否对了,所以我用的是第一种方法,既简单,速度又快。
找到信息的位置后,我需要读取x1到x2这一列中去掉首发站的字符串作为上车站的站名,即
ZhanMing=cell(x2-x1-3,1);
ZhanMing=row(x1+2:x2-2,1);
x1上面一行就有车次的信息,不过该信息会附带首发站和终点站,可以只取这一格的前3个字符的信息,因为车次都是3个字符长度,即
CheCi=row{
x1-1,1};
CheCi=CheCi(1:3);
上车人数的信息在x2这一行,不过列是3:3:x2-x1-1。之所以不用找到“下车总人数”那一列的信息就可以定位,是因为该信息区是个正方形。那么,获得上车人数的代码为
up_num=cell(1,x2-x1-3);
up_num=row(x2,3:x2-x1-1);
再将得到的信息合并成n*4的的表,留出第一列是为了后面赋给时间的信息,这个信息可以使用文件名。
现在我们把这部分整合一下,组成一个函数read(row, x1, x2),那么在一张表里重复使用这个函数就可以得到所有车次的信息。整合读取一张的代码成为一个函数m(e),对31张表使用这个函数,救会得到我们想要的全部信息了。集体的实现看完整代码。因为这些工作实现很简单,有一点c++基础既可以了。
4总结
最后,我得到了一个名为all2.xls的文件,里面记录了24812条信息,都是按照(日期, 车次, 车站, 上车人数)的结构储存的。那么问题来了,我怎么知道我真的读取正确了呢?
为什么会有这个问题,是因为我写的第一个代码得到的结构命名为all1.xls。我以为我做好了,谁知道里面多了很大重复的信息,是因为我忘记matlab会保存工作变量,所以它会把较长的信息重复读取。
回答之前的问题,我检查了all2.xls里的首尾和中间随机几处的信息,发现这和原始信息是一致的。然后我在代码实现的过程中就发现,一张表有62到87个车次,一个车次有4~20个车站。所以一张表大概会有700到800个记录,有一个最多1042个记录,31张表大概会有21700到24800个记录。而24812个记录我认为是比较可信的。
5完整代码
这是一个matlab的m文件。
%运行代码前,要将代码放在和处理数据相同的文件夹
%记得修改第四行的路径,选择你想保存位置的路径
%33行的路径是处理信息文件夹的路径,这个很重要,错的话,脚本就运行错误
savepath=('D:\all2.xls');%结果输出位置
n1=31;%原始数据xls文件的个数n1
for e1=1:n1
n2=length(m1(e1));
m(e1)=n2;
end
ALL(1:m(1),:)=m1(1);
for e2=2:n1
k1=sum(m(1:e2-1))+1;
k2=sum(m(1:e2));
ALL(k1:k2,:)=m1(e2);
end
n5=length(ALL);
file1=cell(n5+1,4);
file1(1,1:4)={
'日期','车次','车站','上车人数'};
file1(2:n5+1,1)=ALL(:,1);
file1(2:n5+1,2)=ALL(:,2);
file1(2:n5+1,3)=ALL(:,3);
file1(2:n5+1,4)=ALL(:,4);
xlswrite(savepath,file1);%输出xls文件结果
function f=m1(e)
%Input e为取值1~31,指定读取第几个文件的信息
%Output f为n*4的cell类型矩阵,里面包含(日期,车次,站名,上车人数)的信息
%filepath为原始数据所在位置
filepath=('D:\旅客列车梯形密度表(31天)\*.xls');
dirs=dir(filepath);
n1=length(dirs);%计算文件夹里xls文档的个数
filename=dirs(e).name;
[~,~,row]=xlsread(filename);
n2=length(row);%读取xls文件,获得它的维度n2
up_station='上车站';
up_num='上车人数合计';
x1=find(strcmp(row,up_station));
x2=find(strcmp(row,up_num));
x3=x2-x1-3;
%查找第一块信息
all=read(row,x1(1),x2(1));
%合并第一块信息
ALL(1:x3(1),:)=all;
k=length(x1);
%下面的for循坏是合并第2到k-1块的信息
for i=2:k-1
all=read(row,x1(i),x2(i));
K1=sum(x3(1:i-1))+1;
K2=sum(x3(1:i));
ALL(K1:K2,:)=all;
end
%合并第k块的信息
all=read(row,x1(k),x2(k));
K11=sum(x3(1:k-1))+1;
K22=sum(x3(1:k));
ALL(K11:K22,:)=all;
filename=filename(1:8);
ALL(:,1)={
filename};
f=ALL;
function A=read(row,x1,x2)
%Input row为储存xls文件信息的元胞组
% x1,x2为要读取信息的坐标,x1为‘上车站’的行坐标,x2为‘上车人数‘的行坐标
%Output A为n*4的cell类型矩阵,里面包含(日期,车次,站名,上车人数)的信息
%获得车次
CheCi=row{
x1-1,1};
CheCi=CheCi(1:3);
%获得第车站名
ZhanMing=cell(x2-x1-3,1);
ZhanMing=row(x1+2:x2-2,1);
%获得每站上车人数
up_num=cell(1,x2-x1-3);
up_num=row(x2,3:x2-x1-1);
%转置up_num
up_num=up_num';
%将获得信息合并
all=cell(x2-x1-3,4);
all(:,2)={
CheCi};
all(:,3)=ZhanMing(:,:);
all(:,4)=up_num(:,:);
A=all;
end
end