SpringBoot 整合ElasticSearch全文检索
ElasticSearch是一个基于Lucene的搜索服务器。它提供了一个分布式多用户能力的全文搜索引擎,基于RESTful web接口。Elasticsearch是用Java语言开发的,并作为Apache许可条款下的开放源码发布,是一种流行的企业级搜索引擎。ElasticSearch用于云计算中,能够达到实时搜索,稳定,可靠,快速,安装使用方便。官方客户端在Java、.NET(C#)、PHP、Python、Apache Groovy、Ruby和许多其他语言中都是可用的。根据DB-Engines的排名显示,Elasticsearch是最受欢迎的企业搜索引擎,其次是Apache Solr,也是基于Lucene。
ElasticSearch的核心是倒排索引
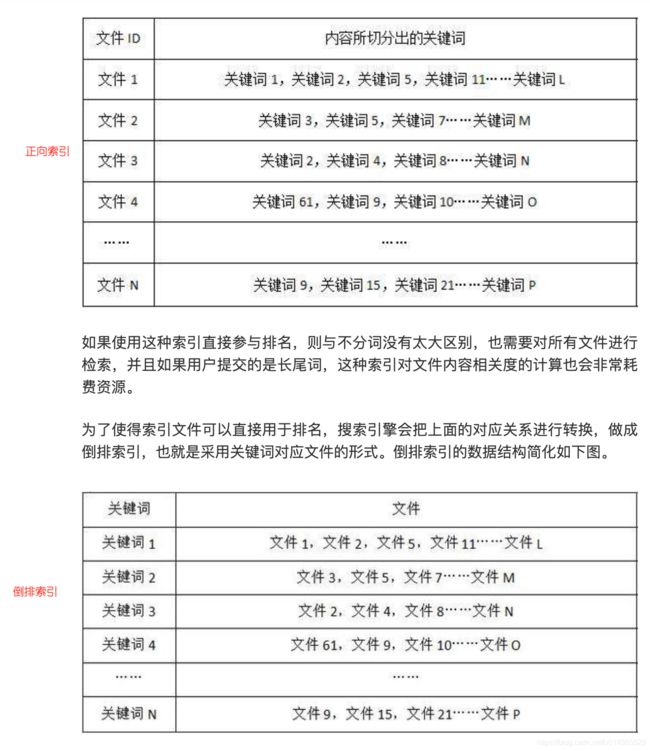
ElasticSearch中的三个重要概念
1、索引:存放数据的地方,可以理解为mysql中的一个数据库
2、类型:用于定义结构,可以理解为mysql中的表结构
3、文档:最终的数据,可以理解为mysql中具体的一行数据
比如:
吕老师:比如一首诗,有诗题、作者、朝代、字数、诗内容等字段,那么首先,我们可以建立一个名叫 Poems 的索引,然后创建一个名叫 Poem 的类型,类型是通过 Mapping 来定义每个字段的类型。
比如诗题、作者、朝代都是 Keyword 类型,诗内容是 Text 类型,而字数是 Integer 类型,***就是把数据组织成 Json 格式存放进去了

上图中keyword与text的区别是:
定义为keyword类型的不再进行分词,直接根据字符串内容建立反向索引,Text 类型在存入 Elasticsearch 的时候,会先分词,然后根据分词后的内容建立反向索引。
Elasticsearch已经把操作封装成了http的api,我们只要调用相应的api接口即可实现。
------------------------------------------ 实例 ---------------------------------------
1、下载安装Elasticsearch
下载地址:https://www.elastic.co/cn/downloads/past-releases/elasticsearch-6-8-6,解压
为了安全不允许使用root用户启动,es5之后的都不能使用添加启动参数或者修改配置文件等方法启动了,必须要创建用户
创建新用户:chown -R zhangjiguo /Users/zhangjiguo/job/program/elasticsearch-6.8.6/bin
切换到新用户下:su zhangjiguo
注意 \config\elasticsearch.yml 配置文件下的配置
cluster.name: my-application
network.host: 127.0.0.1
http.port: 9200
启动服务:进入bin目录下,执行 ./elasticsearch
启动后测试:http://127.0.0.1:9200/,如果返回一个json数据说明启动成功,如下啊
2、springboot项目中的配置
(1)引入maven依赖
org.springframework.boot
spring-boot-starter-data-elasticsearch
2.0.2.RELEASE
(2)application.properties中的配置
#elasticsearch集群名称,默认的是elasticsearch
spring.data.elasticsearch.cluster-name=my-application
#节点的地址 注意api模式下端口号是9300,千万不要写成9200, 集群节点地址列表,多个节点用英文逗号(,)分隔
spring.data.elasticsearch.cluster-nodes=127.0.0.1:9300
#是否开启本地存储
spring.data.elasticsearch.repositories.enable=true
(3)a创建ES文档和映射 (索引对应的实体类)
首先创建一个JAVA对象,然后通过注解来声明字段的映射属性。
spring提供的注解有@Document、@Id、@Field,其中@Document作用在类,@Id、@Field作用在成员变 量,@Id标记一个字段作为id主键。
@Data@Accessors(chain = true)
@Document(indexName = “blog”, type = “java”)
public class BlogModel implements Serializable {
private static final long serialVersionUID = 637219780396477491L;
@Id
private String id;
private String title;
private String desc;
private Integer type;
}
(4)Repository接口
Spring Data 的强大之处,就在于你不用写任何DAO处理,自动根据方法名或类的信息进行CRUD操作。只要你定义 一个接口,然后继承Repository提供的一些子接口,就能具备各种基本的CRUD功能。我们只需要定义接口,然后继承它就OK了

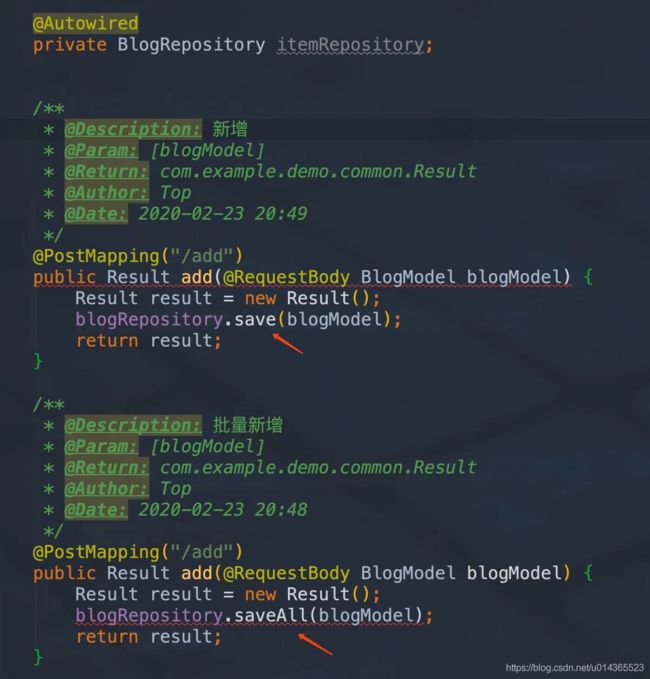
(5)新增数据
(5)修改数据
elasticsearch中本没有修改,它的修改原理是该是先删除在新增
修改和新增是同一个接口,区分的依据就是id。
(6)查询数据(基本查询、自定义查询)
(a)基本查询

(b)自定义查询:
NativeSearchQueryBuilder:Spring提供的一个查询条件构建器,帮助构建json格式的请求体
QueryBuilders.matchQuery(“title”, “小米手机”):利用QueryBuilders来生成一个查询。QueryBuilders提供了大量的静态方法,用于生成各种不同类型的查询:
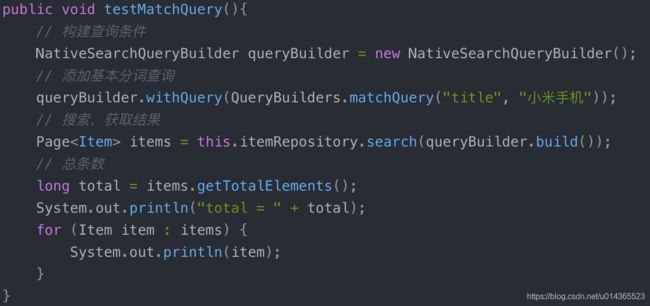
利用NativeSearchQueryBuilder可以方便的实现分页:

排序也通用通过NativeSearchQueryBuilder完成:
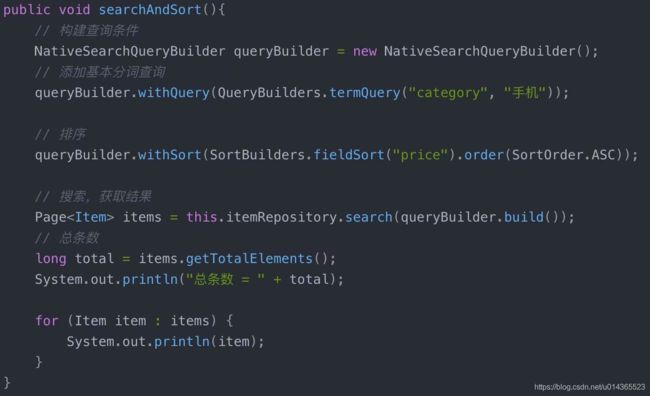
---------------------------------- 高级功能 1 --------------------------------
聚合(牛逼!!solr无此功能)
聚合可以让我们极其方便的实现对数据的统计、分析。例如:
什么品牌的手机最受欢迎?
这些手机的平均价格、最高价格、最低价格?
这些手机每月的销售情况如何?
聚合基本概念
Elasticsearch中的聚合,包含多种类型,最常用的两种,一个叫桶,一个叫度量:
桶(bucket)
桶的作用,是按照某种方式对数据进行分组,每一组数据在ES中称为一个桶,例如我们根据国籍对人划分,可以得到中国桶、英国桶,日本桶……或者我们按照年龄段对人进行划分:010,1020,2030,3040等。
Elasticsearch中提供的划分桶的方式有很多:
Date Histogram Aggregation:根据日期阶梯分组,例如给定阶梯为周,会自动每周分为一组
Histogram Aggregation:根据数值阶梯分组,与日期类似
Terms Aggregation:根据词条内容分组,词条内容完全匹配的为一组
Range Aggregation:数值和日期的范围分组,指定开始和结束,然后按段分组
……
综上所述,我们发现bucket aggregations 只负责对数据进行分组,并不进行计算,因此往往bucket中往往会嵌套另一种聚合:metrics aggregations即度量
度量(metrics)
分组完成以后,我们一般会对组中的数据进行聚合运算,例如求平均值、最大、最小、求和等,这些在ES中称为度量
比较常用的一些度量聚合方式:
Avg Aggregation:求平均值
Max Aggregation:求最大值
Min Aggregation:求最小值
Percentiles Aggregation:求百分比
Stats Aggregation:同时返回avg、max、min、sum、count等
Sum Aggregation:求和
Top hits Aggregation:求前几
Value Count Aggregation:求总数
……
注意:在ES中,需要进行聚合、排序、过滤的字段其处理方式比较特殊,因此不能被分词。这里我们将color和make这两个文字类型的字段设置为keyword类型,这个类型不会被分词,将来就可以参与聚合
2.5.2 聚合为桶
桶就是分组,比如这里我们按照品牌brand进行分组:
/**
* @Description:按照品牌brand进行分组
* @Author: https://blog.csdn.net/chen_2890
*/
@Test
public void testAgg(){
NativeSearchQueryBuilder queryBuilder = new NativeSearchQueryBuilder();
// 不查询任何结果
queryBuilder.withSourceFilter(new FetchSourceFilter(new String[]{""}, null));
// 1、添加一个新的聚合,聚合类型为terms,聚合名称为brands,聚合字段为brand
queryBuilder.addAggregation(
AggregationBuilders.terms(“brands”).field(“brand”));
// 2、查询,需要把结果强转为AggregatedPage类型
AggregatedPage aggPage = (AggregatedPage) this.itemRepository.search(queryBuilder.build());
// 3、解析
// 3.1、从结果中取出名为brands的那个聚合,
// 因为是利用String类型字段来进行的term聚合,所以结果要强转为StringTerm类型
StringTerms agg = (StringTerms) aggPage.getAggregation(“brands”);
// 3.2、获取桶
List
// 3.3、遍历
for (StringTerms.Bucket bucket : buckets) {
// 3.4、获取桶中的key,即品牌名称
System.out.println(bucket.getKeyAsString());
// 3.5、获取桶中的文档数量
System.out.println(bucket.getDocCount());
}
}
显示的结果:
关键API:
AggregationBuilders:聚合的构建工厂类。所有聚合都由这个类来构建,看看他的静态方法:
(1)统计某个字段的数量
ValueCountBuilder vcb= AggregationBuilders.count(“count_uid”).field(“uid”);
(2)去重统计某个字段的数量(有少量误差)
CardinalityBuilder cb= AggregationBuilders.cardinality(“distinct_count_uid”).field(“uid”);
(3)聚合过滤
FilterAggregationBuilder fab= AggregationBuilders.filter(“uid_filter”).filter(QueryBuilders.queryStringQuery(“uid:001”));
(4)按某个字段分组
TermsBuilder tb= AggregationBuilders.terms(“group_name”).field(“name”);
(5)求和
SumBuilder sumBuilder=AggregationBuilders.sum(“sum_price”).field(“price”);
(6)求平均
AvgBuilder ab= AggregationBuilders.avg(“avg_price”).field(“price”);
(7)求最大值
MaxBuilder mb= AggregationBuilders.max(“max_price”).field(“price”);
(8)求最小值
MinBuilder min=AggregationBuilders.min(“min_price”).field(“price”);
(9)按日期间隔分组
DateHistogramBuilder dhb= AggregationBuilders.dateHistogram(“dh”).field(“date”);
(10)获取聚合里面的结果
TopHitsBuilder thb= AggregationBuilders.topHits(“top_result”);
(11)嵌套的聚合
NestedBuilder nb= AggregationBuilders.nested(“negsted_path”).path(“quests”);
(12)反转嵌套
AggregationBuilders.reverseNested(“res_negsted”).path("kps ");
AggregatedPage:聚合查询的结果类。它是Page的子接口:
AggregatedPage在Page功能的基础上,拓展了与聚合相关的功能,它其实就是对聚合结果的一种封装。
而返回的结果都是Aggregation类型对象,不过根据字段类型不同,又有不同的子类表示
2.5.3 嵌套聚合,求平均值
代码:
/**
* @Description:嵌套聚合,求平均值
* @Author: https://blog.csdn.net/chen_2890
*/
@Test
public void testSubAgg(){
NativeSearchQueryBuilder queryBuilder = new NativeSearchQueryBuilder();
// 不查询任何结果
queryBuilder.withSourceFilter(new FetchSourceFilter(new String[]{""}, null));
// 1、添加一个新的聚合,聚合类型为terms,聚合名称为brands,聚合字段为brand
queryBuilder.addAggregation(
AggregationBuilders.terms(“brands”).field(“brand”)
.subAggregation(AggregationBuilders.avg(“priceAvg”).field(“price”)) // 在品牌聚合桶内进行嵌套聚合,求平均值
);
// 2、查询,需要把结果强转为AggregatedPage类型
AggregatedPage aggPage = (AggregatedPage) this.itemRepository.search(queryBuilder.build());
// 3、解析
// 3.1、从结果中取出名为brands的那个聚合,
// 因为是利用String类型字段来进行的term聚合,所以结果要强转为StringTerm类型
StringTerms agg = (StringTerms) aggPage.getAggregation(“brands”);
// 3.2、获取桶
List
// 3.3、遍历
for (StringTerms.Bucket bucket : buckets) {
// 3.4、获取桶中的key,即品牌名称 3.5、获取桶中的文档数量
System.out.println(bucket.getKeyAsString() + “,共” + bucket.getDocCount() + “台”);
// 3.6.获取子聚合结果:
InternalAvg avg = (InternalAvg) bucket.getAggregations().asMap().get(“priceAvg”);
System.out.println(“平均售价:” + avg.getValue());
}
}
---------------------------------- 高级功能 2 --------------------------------
springboot整合elasticsearch并高亮显示
public class EsController {
@Autowired
ESConfig esConfig;
@RequestMapping("/getes")
@ResponseBody
public Map getEs(String prod_name) throws Exception {
//读取那个索引
SearchRequestBuilder searchRequestBuilder=esConfig.getClient().prepareSearch("blog");
searchRequestBuilder.setTypes("log");
//设置每批读取的数据量
searchRequestBuilder.setSize(1000);
//默认是查询所有
//searchRequestBuilder.setQuery(QueryBuilders.queryStringQuery("*:*"));
//设置search context维护3分钟的有效期
searchRequestBuilder.setScroll(TimeValue.timeValueMillis(3));
//查询时间范围内的数据
//RangeQueryBuilder builder=QueryBuilders.rangeQuery("crawlerdate").from("2019-02-21").to("2019-03-01");
//根据prod_name来精确查询
MatchPhraseQueryBuilder builder=null;
if(!StringUtils.isEmpty(prod_name)){
builder= QueryBuilders.matchPhraseQuery("prod_name",prod_name);
}else{
//默认是查询所有
//searchRequestBuilder.setQuery(QueryBuilders.queryStringQuery("*:*"));
//这里你可以使用jdbc去连接数据库做查询 然后展现到前段页面 因为我这里没写也就不贴代码了
builder=QueryBuilders.matchPhraseQuery("prod_name","");
}
//根据prod_name来查询
//MatchQueryBuilder builder = QueryBuilders.matchQuery("prod_name", "幻想笔记本电脑");
//设置高亮字段
HighlightBuilder highlightBuilder=new HighlightBuilder()
.field("prod_name")
.preTags("").postTags("");
//获得首次查询结果
SearchResponse response=searchRequestBuilder.highlighter(highlightBuilder).setQuery(builder).setPostFilter(builder).get();
System.out.println("命中总数量:"+response.getHits().getTotalHits());
SearchHits hits = response.getHits();
List> list=new ArrayList<>(15);
for (SearchHit hit:hits){
Map sourceAsMap = hit.getSourceAsMap();
if(!StringUtils.isEmpty(prod_name)){
Text[] prod_names = hit.getHighlightFields().get("prod_name").getFragments();
String hight="";
if(prod_names!=null){
for (Text str:prod_names){
hight+=str;
}
}
sourceAsMap.put("prod_name",hight);
}
list.add(sourceAsMap);
}
SearchResponse response1=esConfig.getClient().prepareSearch("blog").setTypes("log")
.setQuery(builder).setPostFilter(builder).get();
Map map=new HashMap<>();
map.put("code",0);
map.put("msg","");
map.put("count",response1.getHits().getTotalHits());
map.put("data",list);
return map;
}
}
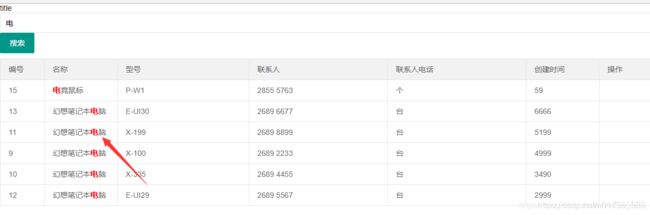
---------------------------------- 高级功能 3 --------------------------------
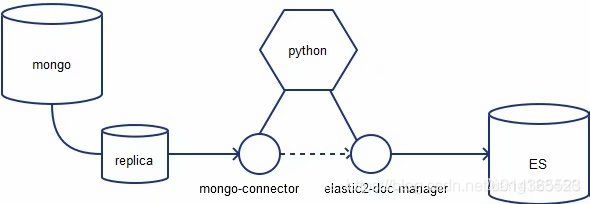
从MongoDB拿出数据到ElasticSearch,使用SpringBoot2.x调用
ES是用于记录和分析数据的流行框架,MongoDB是用于存储和查询数据的著名NoSQL数据库。随着我们的Web基础架构的改进,我们如何将数据从mongoDB导出到ES以进行搜索分析,以下是5中解决方案:
1、由Web服务器同步
我们可以使用Mongoosastic模块进行双面存储。当需要存储一个文档时,Mongoosastic可以将更改同时提交给mongo和ES。
优点是数据可以同时存储在mongo和ES中,缺点是可能在CUD操作效率中引起开销。当一种类行的DB存储失败时,可能会发生数据不一致。并且服务器框架不够灵活,无法进行数据库迁移。
2、手动将数据从Mongo加载到ES
一旦您想将mongo中的数据导出到另一个ES服务器,Transporter工具是同步数据的不错选择。Transporter还可以从其他类型的数据存储中导出数据。重要的是要知道同步工具只同步一次。这里需要定期的进行同步操作。
3、ES的插件
ES的插件名为:elasticsearch-river-mongodb,并在ES1.x中广泛应用,我们通过添加mongodb输入和ES输出插件来利用logstash中的缓冲、输入、输出和过滤功能来完成这项工作。 但现在不推荐使用ES2.x的河流机制。
4、Mongo - ES连接器(推荐的方式)
mongo-connector是一个实时同步服务,创建一个从MongoDB簇到一个或多个目标系统的管道,目标系统包括:Solr,Elasticsearch,或MongoDB集群。 该工具在MongoDB与目标系统间同步数据,并跟踪MongoDB的oplog,保持操作与MongoDB的实时同步。
mongo-connector工具是基于python开发的实时同步服务工具。它要求mongo要在replica-set(副本集)模式运行。
同步资料:https://www.jianshu.com/p/1a305f191fca
参考资料:
https://linux.cn/article-11125-1.html
https://user.qzone.qq.com/1051199599/infocenter
https://segmentfault.com/a/1190000019041032