tensorflow输出网络结构_强化学习实验环境Gym和TensorFlow
强化学习算法的实现需要合适的平台和工具。本案例将首先介绍目前常用的强化学习实现平台Gym的基本使用方法,再介绍实验工具TensorFlow的基本操作方法,为之后构建和评估强大的强化学习算法打下坚实基础。

目录
1.常见强化学习实验平台介绍
2.实验平台Gym
2.1 Gym的安装
2.2 Gym中的内置环境
2.3 Gym的基本使用方法
3.实验工具TensorFlow
3.1 TensorFlow的安装
3.2 利用TensorFlow搭建全连接神经网络近似状态值函数
4.总结
1.常见强化学习实验平台介绍
我们如何去验证强化学习算法的好坏呢?就像数据集一样,我们需要一个公认的平台用于在环境中模拟、构建、渲染和实验强化学习算法。如今已有许多强化学习的实验平台:
DeepMind Lab
DeepMind Lab是基于强化学习的一个优秀研究平台,提供了丰富的模拟环境。同时它具有高度的可定制化和可扩展性,可视化内容非常丰富,且具有科幻风格和逼真效果。

Project Malmo
Project Malmo是微软公司在Minecraft基础上开发的一种强化学习实验平台,可为定制化环境提供良好的灵活性,同时还适用于复杂环境,但Malmo当前只能提供Minecraft游戏环境。

VizDoom
VizDoom是一种基于毁灭战士游戏(Doom)的强化学习实验平台,支持多智能体和竞争环境下测试智能体,但VizDoom只支持Doom游戏环境,另外可提供离屏渲染和支持单/多玩家。

OpenAI Gym
Gym是目前应用最为广泛的强化学习实验平台,下面我们将着重介绍它的使用方法。
2.实验平台Gym
OpenAI是由Elon Musk和Sam Altman创建的一个非盈利、开源的人工智能研究公司。Gym是OpenAI推出的强化学习实验环境库,利用它可以模拟现实环境,建立强化学习算法,并在这些环境中测试智能体。Gym可以兼容TensorFlow、Theano、Keras等框架下所编写的算法,除了依赖少量商业库外,整个项目是开源免费的。

2.1 Gym的安装
Gym支持Windows系统、Linux系统和MacOS系统,在Anaconda 3环境里安装Gym库(要求Python版本为 3.5+),安装命令为pip install gym。安装完成后,在Python中导入就可以了。
import gym
2.2 Gym中的内置环境
Gym库中内置了上百种强化学习的实验环境:
- 经典控制环境
- 简单文本环境
- 算法环境
- Box2D环境
- Atari游戏环境
- 机械控制环境
- ……

这些环境都封装在子模块env中,使用下列方法可以查看所有包含的环境,由于数量过多,我们只打印前10个:
from gym import envs
env_spaces = envs.registry.all()
env_ids = [env_space.id for env_space in env_spaces]
print(env_ids[:10])
['Copy-v0', 'RepeatCopy-v0', 'ReversedAddition-v0', 'ReversedAddition3-v0', 'DuplicatedInput-v0', 'Reverse-v0', 'CartPole-v0', 'CartPole-v1', 'MountainCar-v0', 'MountainCarContinuous-v0']
每一个环境都有一个形如“xxxxx-vd” 的ID,如“CartPole-v0”,ID中包含环境名称和版本号。下面我们挑选一个环境作为实验对象,进一步介绍Gym库的基本使用方法。
2.3 Gym的基本使用方法
我们挑选"CliffWalking-v0"(中文名称为“悬崖寻路”)作为实验对象,这个环境需要解决的问题是在一个4×12的网格中,智能体最开始在左下角的网格(编号为36),希望以最少的步数移动到右下角的网格(编号为47),如下图所示,37~46表示悬崖:
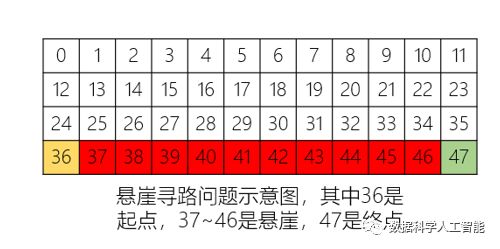
智能体可以采取上、下、左、右四种动作进行移动:
- 到达除悬崖以外的网格奖励为-1
- 到达悬崖奖励为-100并返回起点
- 离开网格的动作会保持当前状态不动并奖励-1
首先,使用make函数加载"悬崖寻路"环境,如果需要加载其它环境,只需将make函数中的参数换成其它环境的ID即可:
env = gym.make('CliffWalking-v0')
每个环境都定义了自己的状态空间和动作空间,加载环境之后使用环境的observation_space属性查看状态空间,使用action_space属性查看动作空间:
print('状态空间:',env.observation_space)
print('动作空间:',env.action_space)
状态空间: Discrete(48)
动作空间: Discrete(4)
在Gym中,离散空间一般用gym.spaces.Discrete类表示,连续空间一般用gym.spaces.Box类表示。
悬崖寻路问题中,Discrete(48)表示状态空间是离散的,取值为,Discrete(4)表示动作空间是离散的,取值为。
使用P属性可以查看采取不同动作,状态间的转移关系,其返回一个嵌套字典对象,键为状态,值还是一个字典对象,以状态30为例:
env.P[30]
{0: [(1.0, 18, -1, False)],
1: [(1.0, 31, -1, False)],
2: [(1.0, 36, -100, False)],
3: [(1.0, 29, -1, False)]}
上述字典对象中,键表示不同的动作,值为一个元组列表,其中的元素分别表示在采取键对应的动作下的转移概率,到达的状态,反馈的奖励和是否到达终点的信号。
例如,位于状态30时,0,1,2和3分别表示向上,向右,向下和向左移动,选择2即向下移动时会以概率1进入悬崖,随即回到初始状态36并反馈-100的奖励,没有到达终点。
接下来介绍使用环境的核心方法——step方法,其接受智能体的动作作为参数,并返回以下四个值:
- observation:采取当前动作后到达的状态
- reward:采取当前行动所获得的奖励
- done:布尔型变量,表示是否到达终点状态
- info:字典类型的值,包含一些调试信息,例如状态间的转移概率
每个时间步,智能体都会选择一个动作,然后返回下一状态和奖励。
使用step方法前需要利用reset方法初始化环境,该方法会返回智能体的初始状态,每当回合结束时,可以使用reset方法开始下一回合:
env.reset()
step方法需要动作作为参数,可以利用sample方法从动作空间中随机选择一个动作:
env.action_space.sample()
调用step方法后,可以使用render方法以图形化的方式显示当前环境:
env.render()
每次调用step方法只会向前进行一步,所以常常使用循环结构循环调用step方法完成整个回合。
env.reset() # 初始化环境
for t in range(10):
# 在动作空间中随机选择一个动作
action = env.action_space.sample()
# 采取一个动作
observation, reward, done, info = env.step(action)
print("action:{},observation:{},reward:{}, done:{}, info:{}".format(action, observation, reward, done, info))
# 图形化显示
env.render()

3.实验工具TensorFlow
TensorFlow是一个运用数据流图进行数值计算的开源软件库,其灵活的架构可以在多种平台上展开计算。TensorFlow最初用于机器学习和深度神经网络方面的研究,但这个系统的通用性使其也可广泛用于其它计算领域。
在强化学习中,面对状态空间庞大,动作空间连续的情况,会利用模型来估计价值函数,比如DQN算法,使用深度神经网络估计价值函数,这时就需要使用TensorFlow构建深度神经网络并结合Gym一起实现DQN算法。
数据流图又称为计算图,是TensorFlow的基本计算框架,用于定义深度学习的网络结构。TensorFlow中的基本数据流图为静态图,即一旦创建不支持动态修改,TensorFlow中亦引入了动态图机制(Eager)。
数据流图中包含一些操作(Operation)对象,称为计算节点,张量(Tensor)对象则是表示在不同的操作间的数据节点。在定义图的时候可以定义不同的名称域并在其中定义变量和Operation,方便后续查找。
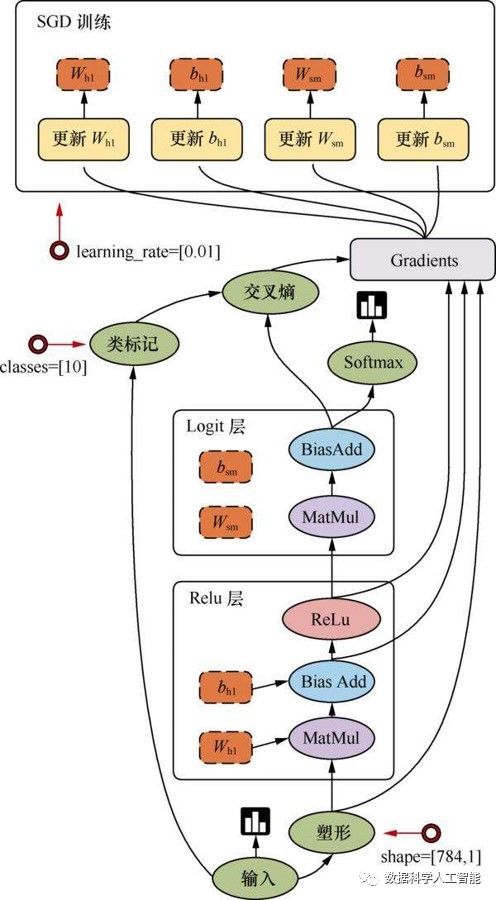
3.1 TensorFlow的安装
TensorFlow有CPU和GPU两种版本,以Anaconda3为例,在Windows系统下安装稳定CPU版本1.12,首先使用conda创建一个Python3.6的环境,然后进入这个环境,使用命令pip install tensorflow==1.12进行安装即可;在Windows系统下安装GPU版本1.12,需要依次完成以下几步:
安装VS2015
安装CUDA及CUDNN(版本必须与电脑显卡版本对应)并添加环境变量
使用conda创建一个Python3.6的环境
使用命令
pip install tensorflow-gpu==1.12进行安装
3.2 利用TensorFlow搭建全连接神经网络近似状态值函数
我们将通过一个例子为大家介绍TensorFlow搭建神经网络的方法。由于神经网络被称为“万能函数逼近器”,我们可以利用神经网络近似状态值函数,即:
其中为神经网络的参数,神经网络的输入为状态,输出为状态价值。
在这里我们以全连接神经网络为例,具体网络结构如下:
- 输入层:状态,维度为1×1
- 隐藏层:5个神经元
- 输出层:状态价值,维度为1×1
首先读取训练数据:
import numpy as np
import pandas as pd
data = pd.read_csv('./input/value_function.csv')
data.head()

上述结果可以看到数据中包含两列,state列表示状态,value列表示状态对应的价值,我们将这两列分别保存:
# 神经网络的输入数据
x = data['state'].values
# 神经网络的输出数据
y = data['value'].values
定义占位符
由于TensorFlow的基本数据流图为静态图,所以在搭建深度神经网络的时候需要先定义占位符占据固定的位置。占位符只定义Tensor的类型和维度,不进行赋值。TensorFlow中可以使用placeholder函数创建占位符,其中有一个参数shape,用于指定数据维度,若shape设置为None,则可以输入任意维度的数据。我们先利用占位符定义神经网络的输入和输出:
import tensorflow as tf
# 重置计算图
tf.reset_default_graph()
# 定义输入占位符
x_ = tf.placeholder(shape=[None, 1], dtype=tf.float32, name='x_')
# 定义输出占位符
y_ = tf.placeholder(shape=[None, 1], dtype=tf.float32, name='y_')
定义参数
在TensorFlow中,常量是数值不能改变的Tensor,一旦被赋值,就不能改变,可以使用constant函数创建TensorFlow常量。
变量是数值可变的Tensor,用于计算图中其它操作的输入,神经网络的参数都可以看作是变量,可以使用Variable函数创建TensorFlow变量。
在复杂的神经网络结构中,层与层之间的连接、节点与节点之间的连接会存在许多的变量或操作,会导致变量出现混乱不清的情况。可以使用variable_scope函数设置变量范围,通过将相关层的变量或操作集中在一个范围内有助于更好的理解模型。
下面我们分别定义神经网络隐藏层和输出层的权重和偏置:
# 定义隐藏层的权重和偏置
with tf.variable_scope('hidden'):
# 使用截断正态分布初始化权重
w_hidden = tf.Variable(tf.truncated_normal(shape=[1, 5], dtype=tf.float32), name='w_hidden')
# 定义偏置
b_hidden = tf.Variable(tf.truncated_normal(shape=[5], dtype=tf.float32), name='b_hidden')
# 定义输出层的权重和偏置
with tf.variable_scope('out'):
# 定义权重
w_out = tf.Variable(tf.truncated_normal(shape=[5, 1], dtype=tf.float32), name='w_out')
# 定义偏置
b_out = tf.Variable(tf.truncated_normal(shape=[1], dtype=tf.float32), name='b_out')
定义前向传播
定义好神经网络的输入输出和参数后,我们定义前向传播计算。在TensorFlow中包含着基本的Tensor运算函数,例如利用matmul函数计算Tensor的乘积,利用add函数计算Tensor的和。
在前向传播的过程中,神经元的输入会经过激活函数进行非线性映射,在TensorFlow的nn模块中,封装了一些常用的激活函数,这里我们使用ReLU作为激活函数:
# 定义前向传播
layer_1 = tf.nn.relu(tf.add(tf.matmul(x_, w_hidden), b_hidden))
y_pred = tf.add(tf.matmul(layer_1, w_out), b_out)
TensorFlow常用的激活函数调用方法如下:
| 激活函数 | 调用方法 |
|---|---|
| ReLU | tf.nn.relu |
| Sigmoid | tf.nn.sigmoid |
| tanh | tf.nn.tanh |
| Softmax | tf.nn.softmax |
| Softplus | tf.nn.softplus |
定义损失函数和优化器
TensorFlow中也封装了训练神经网络时需要定义的损失函数,回归问题中常使用均方误差作为损失函数,分类问题中常使用交叉熵作为损失函数。近似值函数可以看作是回归问题,所以使用均方误差作为损失函数。
在训练神经网络时,选择适合的优化方法是十分关键的,会直接影响神经网络的训练效果。在TensorFlow的train模块中封装了梯度下降算法家族中的常用算法,这里我们使用Adam方法作为优化器。
# 定义损失函数
loss = tf.losses.mean_squared_error(predictions=y_pred, labels=y_)
# 定义优化器,学习率设为0.01,设定目标为极小化损失函数loss
train_op = tf.train.AdamOptimizer(0.01).minimize(loss)
TensorFlow常用的损失函数调用方法如下:
| 损失函数 | 调用方法 |
|---|---|
| 均方误差 | tf.losses.mean_squared_error |
| 二分类交叉熵 | tf.nn.sigmoid_cross_entropy_with_logits |
| 多分类交叉熵 | tf.nn.softmax_cross_entropy_with_logits_v2 |
| 多分类稀疏交叉熵 | tf.nn.sparse_softmax_cross_entropy_with_logits |
TensorFlow常用的优化器调用方法如下:
| 优化器 | 调用方法 |
|---|---|
| 梯度下降 | tf.train.GradientDescentOptimizer |
| 动量法 | tf.train.MomentumOptimizer |
| RMSprop | tf.train.RMSPropOptimizer |
| Adam | tf.train.AdamOptimizer |
| Adadelta | tf.train.AdadeltaOptimizer |
| Adagrad | tf.train.AdagradOptimizer |
创建会话训练网络
为了执行数据流图的计算,数据流图必须在会话(Session)中启动,会话将图的操作分配给CPU、GPU等设备上执行。
要启动计算图,首先利用Session类创建一个会话对象,再调用run方法执行计算图,会话使用完毕后调用close方法关闭会话以释放资源。我们也可以利用Python中的上下文管理协议with…as自动关闭会话。
下面我们创建一个会话并开始训练网络:
# 设定迭代轮数
training_epochs = 500
# 设定batch大小
batch_size = 10
# 创建会话
with tf.Session() as sess:
# 变量初始化
sess.run(tf.global_variables_initializer())
for epoch in range(training_epochs):
for i in range(10):
# 将所有训练数据分割为batch,batch大小为10,共10个
# 将batch_x、batch_y转换成与占位符x_、y_相同的维度
batch_x = x[i*batch_size:(i+1)*batch_size].reshape(-1, 1)
batch_y = y[i*batch_size:(i+1)*batch_size].reshape(-1, 1)
# 使用参数feed_dict传入数据,进行反向转播更新参数
_, cost = sess.run([train_op, loss], feed_dict={x_:batch_x, y_:batch_y})
# 每20轮输出训练集的损失函数值
if epoch % 20 == 0:
print("epoch", epoch, "training loss", sess.run(loss, feed_dict={x_:x.reshape(-1, 1), y_:y.reshape(-1, 1)}))
print("隐藏层权重:",w_hidden.eval())
print("隐藏层偏置:",b_hidden.eval())
print("输出层权重:",w_out.eval())
print("输出层偏置:",b_out.eval())
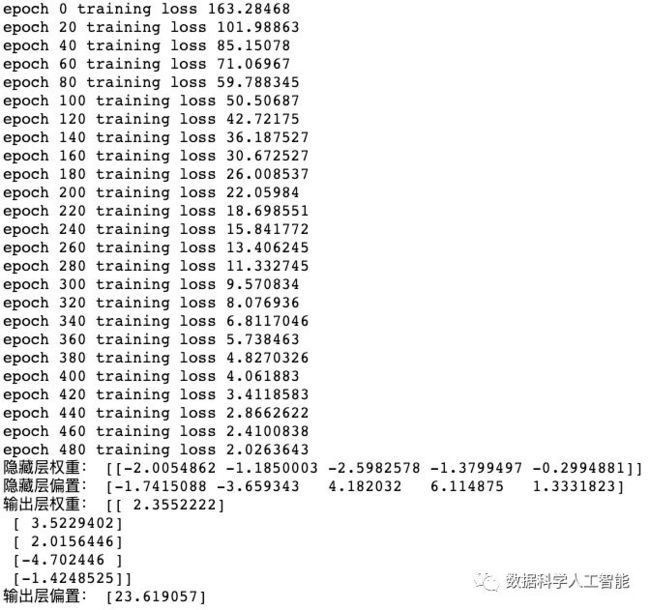
可以看到随着训练轮数不断增加,训练集损失不断下降,并且最后输出了神经网络的参数,至此就完成了一个全连接神经网络的训练。
4.总结
本案例首先介绍了使用最为广泛的强化学习实验平台OpenAI Gym的基本使用方法,包括Gym的安装和内置环境的使用等,之后的案例中我们都会使用Gym作为强化学习算法的实验评估,进行算法的评估和调试。
然后我们介绍了实验工具TensorFlow,通过一个例子讲解搭建神经网络的流程。之后的强化学习算法实践中我们会利用TensorFlow搭建深度神经网络并与Gym相结合来实现一些经典的强化学习算法。
希望大家通过本案例可以对TensorFlow和Gym有一个基本的了解,为之后的强化学习算法实践做好准备!
“查看本案例完整的数据、代码和报告请登录数据酷客(cookdata.cn)案例板块。
