昨天的版本只能爬在售房源,而且到最后和网站数据比,少了几百个,这肯定是哪里出错了啊,像我这种上升处女,受不了啊。
今天重新整理了下思路,从小区信息开始往下爬,一次性把在售房源数据和成交房源数据爬下来,简单粗暴。
新思路
从小区首页开始,获取深圳所有小区,并通过小区页面中在售房源和成交房源的链接,获取每个小区所有的房源。
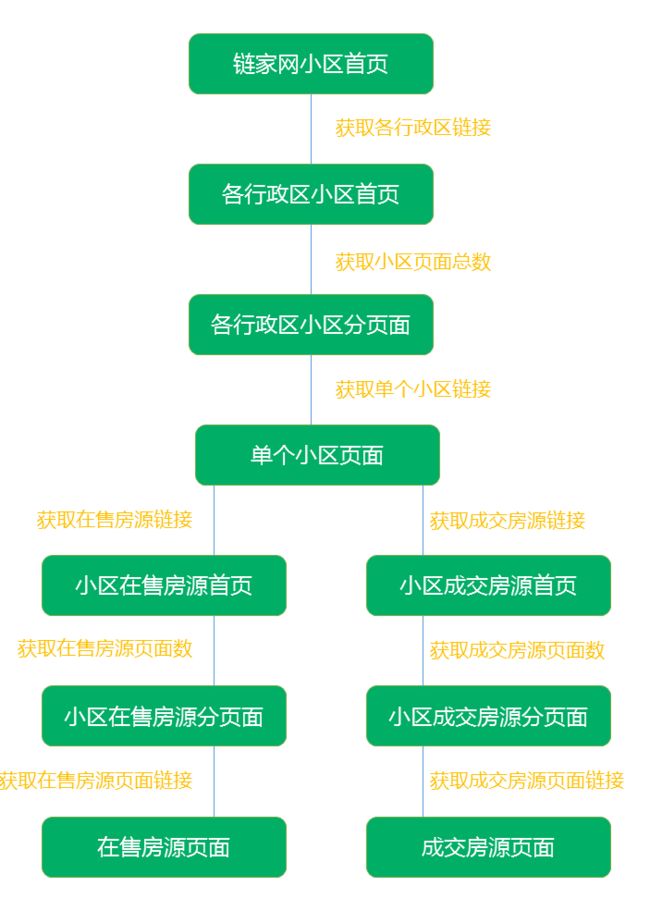
思路
以前不知道scrapy怎么同时保存2个以上的item,这次为了能同时存下小区信息,在售房源信息和成交房源信息,特意去学习了下,发现还是挺简单的,在items.py中多创建几个item类,pipelines.py中判断item的类别,采用不同的方式保存数据。
def process_item(self, item, spider):
if isinstance(item,XiaoquItem):
self.db[self.collection_xiaoqu].update({'小区链接':item['小区链接']},dict(item),True)
elif isinstance(item,ZaishouItem):
self.db[self.collection_zaishou].update({'房屋链接': item['房屋链接']}, dict(item), True)
elif isinstance(item,ChengjiaoItem):
self.db[self.collection_chengjiao].update({'房屋链接': item['房屋链接']}, dict(item), True)
else:
pass
return item
这部分就是新技能了,看起来好简单,实际很实用。
爬虫部分直接放代码了,好多哈,我学爬虫以来没一次性写过这么多行代码,成就感满满~
start_url = 'https://sz.lianjia.com/xiaoqu/'
def start_requests(self):
yield scrapy.Request(self.start_url,callback = self.parse_daqu,dont_filter=True)
def parse_daqu(self,response):
dists = response.xpath('//div[@data-role="ershoufang"]/div/a/@href').extract()
for dist in dists:
url = 'https://sz.lianjia.com'+dist
yield scrapy.Request(url,self.parse_xiaoqu,dont_filter=True)
def parse_xiaoqu(self,response):
page_info = response.xpath('//div[@class="page-box house-lst-page-box"]/@page-data').extract()[0]
page_dic = json.loads(page_info)
page_num = page_dic.get('totalPage')
for i in range(page_num + 1):
url = response.url + 'pg' + str(i) + '/'
yield scrapy.Request(url, callback=self.parse_xiaoqu_page, dont_filter=True)
def parse_xiaoqu_page(self,response):
xiaoqu_urls = response.xpath('//li[@class="clear xiaoquListItem"]/a/@href').extract()
for xiaoqu_url in xiaoqu_urls:
xiaoqu_id = xiaoqu_url.split('/')[-2]
url = 'https://sz.lianjia.com/xiaoqu/'+xiaoqu_id+'/'
yield scrapy.Request(url, callback=self.parse_xiaoqu_index, dont_filter=True)
def parse_xiaoqu_index(self,response):
item = XiaoquItem()
xiaoqu = response.xpath('//h1[@class="detailTitle"]/text()').extract()[0]
xiaoqujunjia = float(response.xpath('//span[@class="xiaoquUnitPrice"]/text()').extract()[0]) if response.xpath(
'//span[@class="xiaoquUnitPrice"]/text()').extract() else ''
xiaoquzuobiao = re.findall('resblockPosition:\'(.*?)\'', response.text, re.S)[0] if re.findall(
'resblockPosition:\'(.*?)\'', response.text, re.S) else ''
daqu = response.xpath('//div[@class="fl l-txt"]/a[3]/text()').extract()[0].rstrip('小区')
pianqu = response.xpath('//div[@class="fl l-txt"]/a[4]/text()').extract()[0].rstrip('小区')
soup = BeautifulSoup(response.text,'lxml')
xiaoquinfo = [i.text for i in soup.select('div.xiaoquInfo div')]
xiaoqudetail = {}
for i in xiaoquinfo:
key = i[:4]
data = i[4:]
xiaoqudetail[key] = data
xiaoqudetail['小区'] = xiaoqu
xiaoqudetail['小区均价'] = xiaoqujunjia
xiaoqudetail['小区坐标'] = xiaoquzuobiao
xiaoqudetail['小区链接'] = response.url
xiaoqudetail['大区'] = daqu
xiaoqudetail['片区'] = pianqu
for key in item.fields:
if key in xiaoqudetail.keys() and (xiaoqudetail[key] != '暂无信息' and '暂无数据'):
item[key] = xiaoqudetail[key]
else:
item[key] = ''
yield item
on_sale = response.xpath('//div[@class="goodSellHeader clear"]/a/@href').extract()
if on_sale:
yield scrapy.Request(on_sale[0], callback=self.parse_onsale, dont_filter=True)
else:
pass
sold = response.xpath('//div[@id="frameDeal"]/a[@class="btn-large"]/@href').extract()
if sold:
yield scrapy.Request(sold[0], callback=self.parse_sold, dont_filter=True)
else:
pass
def parse_onsale(self,response):
page_info = response.xpath('//div[@class="page-box house-lst-page-box"]/@page-data').extract()[0]
page_dic = json.loads(page_info)
page_num = page_dic.get('totalPage')
for i in range(1, page_num + 1):
url = response.url + 'pg' + str(i) + '/'
yield scrapy.Request(url, callback=self.parse_onsale_page, dont_filter=True)
def parse_sold(self,response):
page_info = response.xpath('//div[@class="page-box house-lst-page-box"]/@page-data').extract()[0]
page_dic = json.loads(page_info)
page_num = page_dic.get('totalPage')
for i in range(1,page_num+1):
url = response.url+'pg'+str(i)+'/'
yield scrapy.Request(url,callback=self.parse_sold_page,dont_filter=True)
def parse_onsale_page(self,response):
urls = response.xpath('//ul[@class="sellListContent"]/li/a/@href').extract()
for url in urls:
yield scrapy.Request(url,callback=self.onsale_page,dont_filter=True)
def parse_sold_page(self,response):
urls = response.xpath('//ul[@class="listContent"]/li/a/@href').extract()
for url in urls:
yield scrapy.Request(url,callback=self.sold_page,dont_filter=True)
def onsale_page(self,response):
item = ZaishouItem()
soup = BeautifulSoup(response.text, 'lxml')
title = soup.select('div.title h1')[0].text
price = float(soup.select('span.total')[0].text) if soup.select('span.total') else ''
unitprice = float(soup.select('span.unitPriceValue')[0].text.rstrip('元/平米')) if soup.select(
'span.unitPriceValue') else ''
houseID = soup.select('div.houseRecord span.info')[0].text.rstrip('举报') if soup.select(
'div.houseRecord span.info') else ''
infos = [i.text.strip() for i in soup.select('div.introContent div.content ul li')]
info = {}
for i in infos:
key = i[:4]
data = i[4:]
info[key] = data
info['标题'] = title
info['总价'] = price
info['单价'] = unitprice
info['链家编号'] = houseID
info['小区'] = soup.select('div.communityName > span.label')[0].text if soup.select('div.communityName > span.label') else ''
info['房屋链接'] = response.url
info['建筑面积'] = float(info['建筑面积'].rstrip('㎡')) if '㎡' in info['建筑面积'] else ''
info['套内面积'] = float(info['套内面积'].rstrip('㎡')) if '㎡' in info['套内面积'] else ''
info['挂牌时间'] = datetime.datetime.strptime(info['挂牌时间'],'%Y-%m-%d') if info['挂牌时间'] != '暂无数据' else ''
info['关注'] = int(soup.select('span#favCount')[0].text)
info['带看'] = int(soup.select('span#cartCount')[0].text)
for key in item.fields:
if key in info.keys() and (info[key] != '暂无信息' and '暂无数据'):
item[key] = info[key]
else:
item[key] = ''
yield item
def sold_page(self,response):
item = ChengjiaoItem()
soup = BeautifulSoup(response.text, 'lxml')
title = soup.select('div.house-title')[0].text
chengjiaoriqi = soup.select('div.house-title > div.wrapper > span')[0].text.split(' ')[0]
zongjia = float(soup.select('span.dealTotalPrice > i')[0].text)
danjia = float(soup.select('div.price > b')[0].text)
daikan = int(soup.select('div.msg > span:nth-of-type(4) > label')[0].text)
guanzhu = int(soup.select('div.msg > span:nth-of-type(5) > label')[0].text)
xiaoqu = title.split(' ')[0]
infos = [i.text.strip() for i in soup.select('div.introContent div.content ul li')]
info = {}
for i in infos:
key = i[:4]
data = i[4:]
info[key] = data
info['标题'] = title
info['总价'] = zongjia
info['单价'] = danjia
info['成交日期'] = chengjiaoriqi
info['小区'] = xiaoqu
info['房屋链接'] = response.url
info['建筑面积'] = float(info['建筑面积'].rstrip('㎡')) if '㎡' in info['建筑面积'] else ''
info['套内面积'] = float(info['套内面积'].rstrip('㎡')) if '㎡' in info['套内面积'] else ''
info['挂牌时间'] = datetime.datetime.strptime(info['挂牌时间'], '%Y-%m-%d') if info['挂牌时间'] != '暂无数据' else ''
info['关注'] = guanzhu
info['带看'] = daikan
for key in item.fields:
if key in info.keys() and (info[key] != '暂无数据' and '暂无信息'):
item[key] = info[key]
else:
item[key] = ''
yield item
知识点
1、网页解析依然用的xpath和美丽汤结合,怎么方便怎么来。
2、网页上比较结构化的数据,比如


这类的可以一次性把所有字段转成词典,就不需要用选择器一个个的挑出来了。词典可以对应item.fields中的key,第一次用都快爽哭了,想想以前不懂事,泪目啊
3、可以建多个item类,一次处理多种数据。
结果
跑完以后,抓下来26300个在售二手房数据

55000个成交二手房数据

成交二手房链接不知道为什么有2000多个404,其实链接都能打开没问题,可还是出现了错误,不过,不管了,任性!

后续计划
要开始分析了~
号外号外
晚上发现,链家的反爬虫又回来了。。。。