MySQL详细教程
数据库和SQL
文章目录
- 数据库和SQL
-
- 1、概述
-
- 1.1.数据库的4个基本概念
- 1.2、数据库的好处:
- 1.3、RDBMS 术语
- 1.4、SQL语言的分类
- 2、数据库的相关操作
-
- 2.1、查询已有的数据库列表
- 2.2、创建数据库
- 2.3、修改数据库
- 2.4、删除数据库
- 3、数据库表的相关操作
-
- 3.1、创建表
- MySQL常见约束条件
- 数据类型(列类型)
- 3.2、查看创建表时的语句
- 3.3、查看表结构
- 3.4、修改数据表
- 3.5、删除数据表
- 4、数据处理之查询
-
- 4.1、基本的SELECT语句
- 4.2、给列名起别名
- 4.3、去重:得到列名,将其重复的值去掉
- 4.4、concat连接
- 4.5、条件查询
- 4.6、ORDER BY子句
- 4.7、聚集函数
- 4.8、GROUP BY 语句
- 5、数据处理之增加(插入)
- 6、数据处理之删除
- 7、数据处理之修改
1、概述
1.1.数据库的4个基本概念
数据、数据库、数据库管理系统和数据库系统是与数据库技术密切相关的4个基本概念。
- 数据:
描述事物的符号记录称为数据。描述事物的符号可以是数字也可以是文字、图形、图像、音频、视频等,数据有多种形式。
- 数据库(DataBase DB):
数据库,顾名思义,是存放数据的仓库。数据库是长期存放在计算机内,有组织的、可共享的大量数据的集合。
- 数据库管理系统:
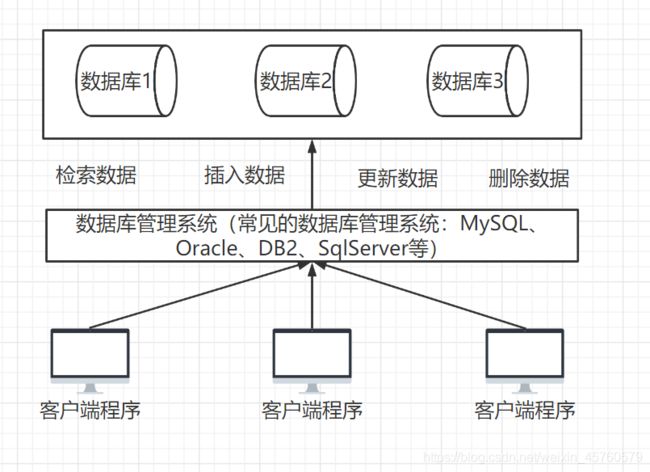
数据库管理系统是位于用户与操作系统之间的一层数据管理软件。数据库管理系统和操作系统一样是计算机的基础软件,也是一个大型复杂的软件系统。常见的数据库管理系统:MySQL、Oracle、DB2、SqlServer等
- 数据库系统
数据库系统是由数据库、数据库管理系统、应用程序和数据库管理员组成的存储、管理、处理和维护数据的系统。
数据库管理系统图片
1.2、数据库的好处:
- 实现数据持久化
- 使用完整的管理系统统一管理、易于查询
数据库的特点:
1、将数据放到表中,表再放到库中
2、一个数据库中可以有多个表,每个表都有一个的名字,用来标识自己。表名具有唯一性。
3、表具有一些特性,这些特性定义了数据在表中如何存储,类似java中 “类”的设计。
4、表由列组成,我们也称为字段。所有表都是由一个或多个列组成的,每一列类似java 中的”属性”
5、表中的数据是按行存储的,每一行类似于java中的“对象”。
SQL的特点
1、不是某个特定数据库供应商专有的语言,几乎所有DBMS都支持SQL
2、简单易学
3、虽然简单,但实际上是一种强有力的语言,灵活使
用其语言元素,可以进行非常复杂和高级的数据库操作。
1.3、RDBMS 术语
在我们开始学习MySQL 数据库前,让我们先了解下RDBMS的一些术语:
- 数据库: 数据库是一些关联表的集合。
- 数据表: 表是数据的矩阵。在一个数据库中的表看起来像一个简单的电子表格。
- 列: 一列(数据元素) 包含了相同类型的数据, 例如邮政编码的数据。
- 行:一行(=元组,或记录)是一组相关的数据,例如一条用户订阅的数据。
- 冗余:存储两倍数据,冗余降低了性能,但提高了数据的安全性。
- 主键:主键是唯一的。一个数据表中只能包含一个主键。你可以使用主键来查询数据。
- 外键:外键用于关联两个表。
- 复合键:复合键(组合键)将多个列作为一个索引键,一般用于复合索引。
- 索引:使用索引可快速访问数据库表中的特定信息。索引是对数据库表中一列或多列的值进行排序的一种结构。类似于书籍的目录。
- 参照完整性: 参照的完整性要求关系中不允许引用不存在的实体。与实体完整性是关系模型必须满足的完整性约束条件,目的是保证数据的一致性。
- 表头(header): 每一列的名称;
- 列(col): 具有相同数据类型的数据的集合;
- 行(row): 每一行用来描述某条记录的具体信息;
- 值(value): 行的具体信息, 每个值必须与该列的数据类型相同;
- 键(key): 键的值在当前列中具有唯一性。
1.4、SQL语言的分类
1、DML(Data Manipulation Language):数据操纵语句,用于添加、删除、修改、查询数据库记录,并检查数据完整性
2、DDL(Data Definition Language):数据定义语句,用于库和表的创建、修改、删除。
3、DCL(Data Control Language):数据控制语句,用于定义用户的访问权限和安全级别。
1.6.1、DML
DML用于查询与修改数据记录,包括如下SQL语句:
INSERT:添加数据到数据库中
UPDATE:修改数据库中的数据
DELETE:删除数据库中的数据
SELECT:选择(查询)数据
SELECT是SQL语言的基础,最为重要。
1.6.2、DDL
DDL用于定义数据库的结构,比如创建、修改或删除
数据库对象,包括如下SQL语句:
CREATE TABLE:创建数据库表
ALTER TABLE:更改表结构、添加、删除、修改列长度
DROP TABLE:删除表
CREATE INDEX:在表上建立索引
DROP INDEX:删除索引
1.6.3、DCL
DCL用来控制数据库的访问,包括如下SQL语句:
GRANT:授予访问权限
REVOKE:撤销访问权限
COMMIT:提交事务处理
ROLLBACK:事务处理回退
SAVEPOINT:设置保存点
LOCK:对数据库的特定部分进行锁定
2、数据库的相关操作
2.1、查询已有的数据库列表
SHOW DATABASES
2.2、创建数据库
语法:CREATE DATABASE 数据库名字 [库选项];
例如:CREATE DATABASE test_table CHARSET utf8;
2.3、修改数据库
注意:数据库的名字不能修改
语法:alter database 数据库名字 [库选项];
例如:ALTER DATABASE test_table CHARSET GBk;
2.4、删除数据库
语法:drop database [if exists] 数据库名字;
例如:DROP DATABASE IF EXISTS test_table;
3、数据库表的相关操作
3.1、创建表
创建表的语句格式:
Create table [if not exists] 表名(
字段名字 数据类型 [列约束],
字段名字 数据类型 [列约束] ##最后一行不需要逗号
)[表选项];
例如:
CREATE TABLE IF NOT EXISTS `person` (
`id` INT UNSIGNED AUTO_INCREMENT,
`name` VARCHAR (10) NOT NULL,
`age` INT (3) NOT NULL,
`birthday` DATE,
PRIMARY KEY (`id`)
)ENGINE=INNODB DEFAULT CHARSET=utf8;
MySQL常见约束条件
约束条件:限制表中的数据,保证添加到数据表中的数据准确和可靠性!凡是不符合约束的数据,插入时就会失败!
约束条件在创建表时可以使用, 也可以修改表的时候添加约束条件
1、约束条件分类:
1)not null :非空约束,保证字段的值不能为空 s_name VARCHAR(10) NOT NULL, #非空
2)default:默认约束,保证字段总会有值,即使没有插入值,都会有默认值!age INT DEFAULT 18, #默认约束
3)unique:唯一,保证唯一性但是可以为空,比如座位号 s_seat INT UNIQUE,#唯一约束
4)check:检查性约束【MySQL不支持,语法不报错,但无效】 s_sex CHAR(1) CHECK(s_sex=‘男’ OR s_sex=‘女’),#检查约束(Mysql无效)
5)primary key :主建约束,同时保证唯一性和非空 d INT PRIMARY KEY,#主建约束(唯一性,非空)
6)foreign key:外键约束,用于限制两个表的关系,保证从表该字段的值来自于主表相关联的字段的值! teacher_id INT REFERENCES teacher(id) #这是外键,写在列级,Mysql无效
7)自增长列 auto_increment id int primary key auto_increment,
一个表中有且只能有一个自增长列,自增长列一般和主键搭配
字符集: charset/character set 具体字符集; ##保证表中数据存储的字符集
校对集: collate 具体校对集; ## utf8mb4_general_ci
存储引擎: engine 具体的存储引擎(InnoDB和MyISAM)
注意
-
列级约束
上面6种约束都可以写,语法都支持,不报错,但外键约束写了mysql无效不起作用 -
表级约束
-
非空约束、默认约束不支持,其他都可以!
语法:
其他: 【constraint 约束名】 约束类型(字段名称) ,
外键: 【constraint 约束名】 约束类型(字段名称) foreign key(字段名称) references 关联表名(其字段名),
DROP TABLE IF EXISTS students;
CREATE TABLE students(
id INT ,
s_name VARCHAR(10) not null,# 非空约束
s_sex CHAR(1) default '男', # 默认约束
s_seat INT,
age INT ,
teacher_id INT ,
#上面是列级约束,下面有表级约束
CONSTRAINT pk PRIMARY KEY(id), #主建约束,pk是起的名,后面一样
CONSTRAINT uq UNIQUE(s_seat), #唯一约束
CONSTRAINT ck CHECK(s_sex='男' OR s_sex='女'), #检查约束
CONSTRAINT fk_students_teacher FOREIGN KEY(teacher_id) REFERENCES teacher(id) #外键约束
);
数据类型(列类型)
SQL中将数据类型分成了三大类: 数值类型, 字符串类型和时间日期类型

1、数值型
数值型数据: 都是数值
系统将数值型分为整数型和小数型.
整数型
存放整型数据: 在SQL中因为更多要考虑如何节省磁盘空间, 所以系统将整型又细分成了5类:
tinyint: 迷你整型,使用一个字节存储, 表示的状态最多为256种(常用)
smallint: 小整型,使用2个字节存储,表示的状态最多为65536种
mediumint: 中整型, 使用3个字节存储
int: 标准整型, 使用4个字节存储(常用)
bigint: 大整型,使用8个字节存储
小数型
带有小数点或者范围超出整型的数值类型.
SQL中: 将小数型细分成两种: 浮点型和定点型
浮点型: 小数点浮动, 精度有限,而且会丢失精度
定点型: 小数点固定, 精度固定, 不会丢失精度
浮点型
浮点型数据是一种精度型数据: 因为超出指定范围之后, 会丢失精度(自动四舍五入)
浮点型: 理论分为两种精度
Float: 单精度, 占用4个字节存储数据, 精度范围大概为7位左右
Double: 双精度,占用8个字节存储数据, 精度方位大概为15位左右
定点型
定点型: 绝对的保证整数部分不会被四舍五入(不会丢失精度),小数部分有可能(理论小数部分也不会丢失精度)
2、时间日期类型
时间日期, 格式是YYYY-mm-dd HH:ii:ss,表示的范围是从1000到9999年,有0值: 0000-00-00 00:00:00
日期,就是datetime中的date部分
Time:时间(段), 指定的某个区间之间, -时间到+时间
Year:年份,两种形式, year(2)和year(4): 1901-2156
3、字符串类型
在SQL中,将字符串类型分成了6类: char、varchar、text、blob、enum和set
定长字符串
定长字符串: char, 磁盘(二维表)在定义结构的时候,就已经确定了最终数据的存储长度.
char(L): L代表length, 可以存储的长度, 单位为字符, 最大长度值可以为255.
char(4): 在UTF8 环境下,需要4 * 3 = 12个字节
变长字符串
变长字符串: varchar, 在分配空间的时候, 按照最大的空间分配: 但是实际上最终用了多少,是根据具体的数据来确定.
varchar(L): L表示字符长度 理论长度是65536个字符, 但是会多处1到2个字节来确定存储的实际长度: 但是实际上如果长度超过255,既不用定长也不用变长, 使用文本字符串text
varchar(10): 的确存了10个汉字, utf8环境, 10 * 3 + 1 = 31(bytes)
存储了3个汉字: 3 * 3 + 1 = 10(bytes)
定长与变长的存储实际空间(UTF8)
文本字符串
如果数据量非常大, 通常说超过255个字符就会使用文本字符串
文本字符串根据存储的数据的格式进行分类: text和blob
Text: 存储文字(二进制数据实际上都是存储路径)
Blob: 存储二进制数据(通常不用)
枚举字符串
枚举: enum, 事先将所有可能出现的结果都设计好, 实际上存储的数据必须是规定好的数据中的一个.
枚举的使用方式
定义: enum(可能出现的元素列表); //如enum(‘男’,’女’,’不男不女’,’妖’,’保密’);
使用: 存储数据,只能存储上面定义好的数据
集合字符串
集合跟枚举很类似: 实际存储的是数值,而不是字符串(集合是多选)
集合使用方式:
定义: Set(元素列表)
使用: 可以使用元素列表中的元素(多个), 使用逗号分隔
3.2、查看创建表时的语句
语法:show create table 表名
3.3、查看表结构
语法:desc 表名
或 describe 表名
或 show columns from 表名
例如:
DESC person;
DESCRIBE person;
SHOW COLUMNS FROM person;
3.4、修改数据表
注意:数据表 可以修改的部分:表结构和字段
1、修改表名
语法:rename table 老表名 to 新表名;
例如:RENAME TABLE person TO man;
2、修改表选项:字符集、校对集和存储引擎
语法:alter table 表名 表选项 [=] 值;
例如:ALTER TABLE man ENGINE=MYISAM;
3、修改表字段
新增字段:
语法:alter table 表名 add [column] 字段名 数据类型 [列属性] [位置];
例如: ALTER TABLE man ADD COLUMN new_id INT(4) FIRST;
ALTER TABLE man ADD COLUMN age2 INT(5) AFTER age;
重命名字段:
语法:alter table 表名 change 旧字段 新字段名 数据类型 [属性] [位置]
例如:ALTER TABLE man CHANGE age age1 INT;
删除字段:
语法:alter table 表名 drop 字段名;
例如: ALTER TABLE man DROP age2;
3.5、删除数据表
语法:drop table [if exists] 表名1,表名2...; ##可以一次性删除多张表
例如:DROP TABLE IF EXISTS man;
4、数据处理之查询
下图是,本人操作时经常用到的几个表,在这里给出来,在下面会用到
user表

jobs表
employees表
departments表

小伙伴可以将这几个表导入到自己的数据库
CREATE DATABASE /*!32312 IF NOT EXISTS*/`myemployees` /*!40100 DEFAULT CHARACTER SET gb2312 */;
USE `myemployees`;
/*Table structure for table `departments` */
DROP TABLE IF EXISTS `departments`;
CREATE TABLE `departments` (
`department_id` int(4) NOT NULL AUTO_INCREMENT,
`department_name` varchar(3) DEFAULT NULL,
`manager_id` int(6) DEFAULT NULL,
`location_id` int(4) DEFAULT NULL,
PRIMARY KEY (`department_id`),
KEY `loc_id_fk` (`location_id`),
CONSTRAINT `loc_id_fk` FOREIGN KEY (`location_id`) REFERENCES `locations` (`location_id`)
) ENGINE=InnoDB AUTO_INCREMENT=271 DEFAULT CHARSET=gb2312;
/*Data for the table `departments` */
insert into `departments`(`department_id`,`department_name`,`manager_id`,`location_id`) values (10,'Adm',200,1700),(20,'Mar',201,1800),(30,'Pur',114,1700),(40,'Hum',203,2400),(50,'Shi',121,1500),(60,'IT',103,1400),(70,'Pub',204,2700),(80,'Sal',145,2500),(90,'Exe',100,1700),(100,'Fin',108,1700),(110,'Acc',205,1700),(120,'Tre',NULL,1700),(130,'Cor',NULL,1700),(140,'Con',NULL,1700),(150,'Sha',NULL,1700),(160,'Ben',NULL,1700),(170,'Man',NULL,1700),(180,'Con',NULL,1700),(190,'Con',NULL,1700),(200,'Ope',NULL,1700),(210,'IT ',NULL,1700),(220,'NOC',NULL,1700),(230,'IT ',NULL,1700),(240,'Gov',NULL,1700),(250,'Ret',NULL,1700),(260,'Rec',NULL,1700),(270,'Pay',NULL,1700);
/*Table structure for table `employees` */
DROP TABLE IF EXISTS `employees`;
CREATE TABLE `employees` (
`employee_id` int(6) NOT NULL AUTO_INCREMENT,
`first_name` varchar(20) DEFAULT NULL,
`last_name` varchar(25) DEFAULT NULL,
`email` varchar(25) DEFAULT NULL,
`phone_number` varchar(20) DEFAULT NULL,
`job_id` varchar(10) DEFAULT NULL,
`salary` double(10,2) DEFAULT NULL,
`commission_pct` double(4,2) DEFAULT NULL,
`manager_id` int(6) DEFAULT NULL,
`department_id` int(4) DEFAULT NULL,
`hiredate` datetime DEFAULT NULL,
PRIMARY KEY (`employee_id`),
KEY `dept_id_fk` (`department_id`),
KEY `job_id_fk` (`job_id`),
CONSTRAINT `dept_id_fk` FOREIGN KEY (`department_id`) REFERENCES `departments` (`department_id`),
CONSTRAINT `job_id_fk` FOREIGN KEY (`job_id`) REFERENCES `jobs` (`job_id`)
) ENGINE=InnoDB AUTO_INCREMENT=209 DEFAULT CHARSET=gb2312;
/*Data for the table `employees` */
insert into `employees`(`employee_id`,`first_name`,`last_name`,`email`,`phone_number`,`job_id`,`salary`,`commission_pct`,`manager_id`,`department_id`,`hiredate`) values (100,'Steven','K_ing','SKING','515.123.4567','AD_PRES',24000.00,NULL,NULL,90,'1992-04-03 00:00:00'),(101,'Neena','Kochhar','NKOCHHAR','515.123.4568','AD_VP',17000.00,NULL,100,90,'1992-04-03 00:00:00'),(102,'Lex','De Haan','LDEHAAN','515.123.4569','AD_VP',17000.00,NULL,100,90,'1992-04-03 00:00:00'),(103,'Alexander','Hunold','AHUNOLD','590.423.4567','IT_PROG',9000.00,NULL,102,60,'1992-04-03 00:00:00'),(104,'Bruce','Ernst','BERNST','590.423.4568','IT_PROG',6000.00,NULL,103,60,'1992-04-03 00:00:00'),(105,'David','Austin','DAUSTIN','590.423.4569','IT_PROG',4800.00,NULL,103,60,'1998-03-03 00:00:00'),(106,'Valli','Pataballa','VPATABAL','590.423.4560','IT_PROG',4800.00,NULL,103,60,'1998-03-03 00:00:00'),(107,'Diana','Lorentz','DLORENTZ','590.423.5567','IT_PROG',4200.00,NULL,103,60,'1998-03-03 00:00:00'),(108,'Nancy','Greenberg','NGREENBE','515.124.4569','FI_MGR',12000.00,NULL,101,100,'1998-03-03 00:00:00'),(109,'Daniel','Faviet','DFAVIET','515.124.4169','FI_ACCOUNT',9000.00,NULL,108,100,'1998-03-03 00:00:00'),(110,'John','Chen','JCHEN','515.124.4269','FI_ACCOUNT',8200.00,NULL,108,100,'2000-09-09 00:00:00');
/*Table structure for table `job_grades` */
DROP TABLE IF EXISTS `jobs`;
CREATE TABLE `jobs` (
`job_id` varchar(10) NOT NULL,
`job_title` varchar(35) DEFAULT NULL,
`min_salary` int(6) DEFAULT NULL,
`max_salary` int(6) DEFAULT NULL,
PRIMARY KEY (`job_id`)
) ENGINE=InnoDB DEFAULT CHARSET=gb2312;
/*Data for the table `jobs` */
insert into `jobs`(`job_id`,`job_title`,`min_salary`,`max_salary`) values ('AC_ACCOUNT','Public Accountant',1000,9000),('AC_MGR','Accounting Manager',8200,16000),('AD_ASST','Administration Assistant',3000,6000),('AD_PRES','President',20000,40000),('AD_VP','Administration Vice President',15000,30000),('DDF','FFF',1000,2000),('FI_ACCOUNT','Accountant',4200,9000),('FI_MGR','Finance Manager',8200,16000),('HR_REP','Human Resources Representative',4000,9000),('IT_PROG','Programmer',4000,10000),('MK_MAN','Marketing Manager',9000,15000),('MK_REP','Marketing Representative',4000,9000),('PR_REP','Public Relations Representative',4500,10500),('PU_CLERK','Purchasing Clerk',2500,5500),('PU_MAN','Purchasing Manager',8000,15000),('SA_MAN','Sales Manager',10000,20000),('SA_REP','Sales Representative',6000,12000),('SH_CLERK','Shipping Clerk',2500,5500),('ST_CLERK','Stock Clerk',2000,5000),('ST_MAN','Stock Manager',5500,8500);
/*Table structure for table `locations` */
4.1、基本的SELECT语句
SELECT 列名
FROM 表明;
SELECT 是标识选择那些列
FROM 是标识选择那个表
- 查询全部列 可以将所有的列名,都写上,也可以用 * 号来代替
SELECT *
FROM USER
- 查询特定列 则将要选择的列名写在SELECT 后面即可,中间要是有多个列,则用逗号隔开
SELECT name,pw
FROM USER
- 查询常量值
SELECT 100
结果:
这里小伙伴,一定很好奇,这两个表里没有100啊,怎么还出现了呢?这里没有也会显示,即结果中列名和表里的名字是一样的。
- 查询表达式
SELECT 100*20
结果 :
注意
• SQL 语言大小写不敏感。
• SQL 可以写在一行或者多行
• 关键字不能被缩写也不能分行
• 各子句一般要分行写。
• 使用缩进提高语句的可读性。
• 当你想要执行语句的时候,选中要执行的语句,点击F9 即可运行
4.2、给列名起别名
列的别名:
• 重命名一个列。
• 便于计算。
• 方式一:紧跟列名,
• 方式二:也可以在列名和别名之间加入关键字‘AS’,别名使用双引号**,**以便在别名中包含空格或特殊的字符并区分大小写。
注意:如果写的别名中有特殊符号,要将他用双引号,包起来
例如:
SELECT `name` "out put",pw 密码
FROM USER
这里的out put 就是特殊符号
SELECT `name` AS 姓名,pw AS 密码
FROM USER
SELECT `name` 姓名,pw 密码
FROM USER
这两个结果都是如下:

4.3、去重:得到列名,将其重复的值去掉
案例:查询员工表中涉及到的所有的部门编号
SELECT department_id
FROM `employees`
结果中有好多重复的部门id ,这是就要用 distinct
SELECT DISTINCT department_id
FROM `employees`
结果:

4.4、concat连接
+号的作用
java中的+号:
- 运算符,当两个操作数为数值型的时候,将数相加
- 连接符,只要有一个操作符为字符串,最终就会拼接成字符串
mysql中的+号
仅仅只有一个功能 : 运算符
select 100+90; 两个操作数都为数值型,则做加法运算
select ‘123’+90; 结果为213 只要其中一个为字符型,试图将字符型数值转换为数值型
如果转换成功,则继续做加法运算
select ‘john’+90; 结果为90 如果转换失败,则,字符型数值为0,
select null+90; 结果为null 只要其中一方为null,则结果为null
案例:查询员工名和姓,连接成一个字段,并显示为 姓名
如果像下面这样做,等到的结果则是错的:
SELECT last_name+first_name AS 姓名
FROM `employees`

那么怎样解决呢?下面给出方法:
用concat进行连接
SELECT CONCAT(last_name,first_name) AS 姓名
FROM `employees`
结果:
4.5、条件查询
如果需要有条件地从表中选取数据,可将 WHERE 子句添加到 SELECT 语句中。WHERE 子句也可以运用于 SQL 的 DELETE 或者 UPDATE 命令。
| 查询条件 | 谓词 |
|---|---|
| 比较 | =,>,<,>=,<=,!=,<>,!>,!< |
| 确定范围 | BETWEEN AND,NOT BETWEEN AND |
| 确定集合 | IN,NOT IN |
| 字符匹配 | LIKE, NOT LIKE |
| 空值 | IS NULL, IS NOT NULL |
| 多重条件(逻辑运算) | AND, OR , NOT |
1)比较大小
(下面案例中需要的表,在上面已经给出,可参考)
案例1:查询工作表中最低工资等于4000的job_id
SELECT job_id
FROM `jobs`
WHERE min_salary=4000;
2)确定范围
案例1:查询工作表中最低工资在4000到5000之间的job_id和job_title
SELECT job_id,job_title
FROM `jobs`
WHERE min_salary BETWEEN 4000 AND 5000;
3)确定集合
IN 操作符允许在 WHERE 子句中规定多个值。IN运算符是一个逻辑运算符,用于将值与一组值进行比较。 如果值在值集内,则IN运算符返回true。否则,它返回false或unknown。
与IN相对的谓词是NOT IN,用于查找属性值不属于指定集合的元组。
案例1:查询employees表中job_id为AD_VP,IT_PROG,ST_MAN的名 和 姓
注意:这里的IN里面的是单引号
SELECT first_name,last_name
FROM `employees`
WHERE job_id IN('AD_VP','IT_PROG','ST_MAN');
4)字符匹配
SQL LIKE 子句中使用百分号(%)字符来表示任意字符,类似于UNIX或正则表达式中的星号 (*)。如果没有使用百分号(%), LIKE 子句与等号(=)的效果是一样的。
%(百分号)代表任意长度的字符串,例如a%b 表示以a开头,b结尾的任意长度的字符串,如acb,addgb,ab等都满足
_(下横线) 表示以a开头,b结尾的长度为3的任意字符串,如acb,akb
LIKE子句需要编写在WHERE字句中.
案例1:查询在employees表中所有名为John的job_id
SELECT job_id
FROM `employees`
WHERE first_name LIKE 'John';
案例2:查询在employees中所有名不为John的job_id
SELECT job_id
FROM `employees`
WHERE first_name NOT LIKE 'John';
案例3:查询employees中名的第一个字符为A的job_id
SELECT job_id
FROM `employees`
WHERE first_name LIKE 'A%';
如果用户要查询的字符串本身就含有通配符%或_ 这时就要使用换码字符 \ 对通配符进行转义
案例4:查询employees表中job_id为FI_ACCOUNT的名和姓
SELECT first_name,last_name
FROM `employees`
WHERE job_id LIKE 'FI\_ACCOUNT';
SELECT first_name,last_name
FROM `employees`
WHERE job_id='FI_ACCOUNT';
5)涉及空值的查询
要确定表达式或列的值是否为NULL,请使用IS NULL运算符
如果表达式的结果为NULL,则IS NULL运算符返回true; 否则它返回false。
要检查表达式或列是否不为NULL,请使用IS NOT运算符
如果表达式的值为NULL,则IS NOT NULL返回false; 否则它返回true
案例1:查询depratment表中manager_id为null 的department_id
SELECT department_id
FROM `departments`
WHERE manager_id IS NULL;
6)多重条件查询
逻辑运算符AND和OR可用来连接多个查询条件,AND的优先级高于OR,但是用户可以用括号改变优先级
案例1:查询employees表中manager_id大于100并且department_id为60的first_name
SELECT first_name
FROM `employees`
WHERE manager_id>100 AND department_id=60;
4.6、ORDER BY子句
ORDER BY 关键字用于对结果集按照一个列或者多个列进行排序。
ORDER BY 关键字默认按照升序(ASC)对记录进行排序。如果需要按照降序对记录进行排序,可以使用 DESC 关键字。
案例1:查询jobs表中的全部数据,查询结果按照最低工资的降序排列
SELECT *
FROM `jobs`
ORDER BY min_salary DESC;
4.7、聚集函数
MySQL提供了许多聚合函数,包括AVG,COUNT,SUM,MIN,MAX等。除COUNT函数外,其它聚合函数在执行计算时会忽略NULL值。
AVG()函数
AVG()函数计算一组值的平均值。它计算过程中是忽略NULL值的。
COUNT() 函数
COUNT() 函数返回匹配指定条件的行数。
SUM()函数
SUM()函数返回一组值的总和,SUM()函数忽略NULL值。如果找不到匹配行,则SUM()函数返回NULL值。
MAX()函数
MAX()函数返回一组值中的最大值。
MIN()函数
MIN()函数返回一组值中的最小值,
HAVING
在 SQL 中增加 HAVING 子句原因是,WHERE 关键字无法与聚合函数一起使用。
HAVING 子句可以让我们筛选分组后的各组数据。
语法:
SELECT column_name, 聚合函数(column_name)
FROM table_name
WHERE column_name operator value
GROUP BY column_name
HAVING 聚合函数(column_name) operator value
4.8、GROUP BY 语句
GROUP BY 语句用于结合聚集函数,根据一个或多个列对结果集进行分组。分组是使用数据库时必须处理的最重要任务之一。 要将行分组,请使用GROUP BY子句。GROUP BY子句是SELECT语句的可选子句,它根据指定列中的匹配值将行组合成组,每组返回一行。
经常将GROUP BY与MIN MAX AVG SUM COUNT等聚合函数结合使用,以计算为每个分组提供信息的度量。
SELECT
column1,
column2,
聚合函数(column3)
FROM
table1
GROUP BY
column1,
column2;
5、数据处理之增加(插入)
语法:
INSERT INTO 表名
VALUES (<常量1>,<常量2>...) #可以一次性插入多条记录
INSERT INTO 表名(<属性列>,<属性列>...)
VALUES (<常量1>,<常量2>...) #插入一条记录
案例1:插入一条工作记录
INSERT INTO jobs
VALUES ('DDF','FFF',1000,2000);
6、数据处理之删除
语法:
DELETE
FROM <表名>
WHERE <条件>
案例1:删除employees表中first_name为Peter的记录
DELETE
FROM `employees`
WHERE first_name='Peter';
7、数据处理之修改
语法:
UPDATE 表名
SET 列名=值
WHERE 条件 #建议都有where: 要不然是更新全部
案例1:修改jobs表中job_id为AC_ACCNOUNT的最低工资为1000
UPDATE jobs
SET min_salary=1000
WHERE job_id='AC_ACCOUNT';