环境
hdp21 192.168.95.21
hdp22 192.168.95.22
hdp23 192.168.95.23
hdp24 192.168.95.24
hdp25 192.168.95.25
时间网络同步、关闭selinux
创建用户hadoop,密码fujg
hadoop 用户免密登录
我准备把所有的文件都放在home目录下
Hadoop2.7.3
192.168.95.21 hdp21 主NameNode
192.168.95.22 hdp22 备用NameNode
192.168.95.23 hdp23 DataNode
192.168.95.24 hdp24 DataNode
192.168.95.25 hdp25 DataNode
1 准备
1,解压安装包到home目录
tar –zxvf hadoop-2.7.3.tar.gz –C /home/
2,修改home的权限
chmod 777 /home
3,创建目录
mkdir -pv /home/dfs/{data,name}
mkdir /home/tmp
mkdir -pv /home/hadoop-2.7.3/{journal,mapred_local,mapred_system,mr-history}
mkdir -pv /home/hadoop-2.7.3/mr-history/{done,tmp}
2 编辑配置文件
2.1 core-site.xml
fs.defaultFS
hdfs://ns
hadoop.tmp.dir
/home/tmp
io.file.buffer.size
4096
ha.zookeeper.quorum
hdp21:2181,hdp22:2181,hdp23:2181,hdp24:2181,hdp25:2181
hadoop.proxyuser.hadoop.groups
hadoop
hadoop.proxyuser.hadoop.hosts
192.168.95.21
2.2 hdfs-site.xml
dfs.nameservices
ns
dfs.ha.namenodes.ns
nn1,nn2
dfs.namenode.rpc-address.ns.nn1
hdp21:9000
dfs.namenode.http-address.ns.nn1
hdp21:50070
dfs.namenode.rpc-address.ns.nn2
hdp22:9000
dfs.namenode.http-address.ns.nn2
hdp22:50070
dfs.namenode.shared.edits.dir
qjournal://hdp23:8485;hdp24:8485;hdp25:8485/ns
dfs.journalnode.edits.dir
/home/hadoop-2.7.3/journal
dfs.ha.automatic-failover.enabled
true
dfs.client.failover.proxy.provider.ns
org.apache.hadoop.hdfs.server.namenode.ha.ConfiguredFailoverProxyProvider
dfs.ha.fencing.methods
sshfence
dfs.ha.fencing.ssh.private-key-files
/home/hadoop/.ssh/id_rsa
dfs.namenode.name.dir
file:/home/dfs/name
dfs.datanode.data.dir
file:/home/dfs/data
dfs.replication
3
dfs.webhdfs.enabled
true
dfs.client.block.write.replace-datanode-on-failure.enable
true
dfs.client.block.write.replace-datanode-on-failure.policy
NEVER
dfs.permissions
false
dfs.web.ugi
hadoop,hadoop
dfs.socket.timeout
240000
dfs.datanode.max.transfer.threads
4096
dfs.datanode.max.xcievers
4096
dfs.datanode.handler.count
50
dfs.namenode.handler.count
50
dfs.hosts
/home/hadoop-2.7.3/etc/hadoop/slaves
dfs.hosts.exclude
/home/hadoop-2.7.3/etc/hadoop/exclude-slaves
2.3 mapred-site.xml
mapreduce.framework.name
yarn
mapred.system.dir
/home/hadoop-2.7.3/mapred_system
mapred.local.dir
/home/hadoop-2.7.3/mapred_local
mapreduce.jobhistory.address
hdp21:10020
mapreduce.jobhistory.webapp.address
hdp21:19888
mapreduce.jobhistory.intermediate-done-dir
/home/hadoop-2.7.3/mr-history/tmp
mapreduce.jobhistory.done-dir
/home/hadoop-2.7.3/mr-history/done
mapred.child.java.opts
-Xmx200M
mapred.reduce.child.java.opts
-Xmx200M
mapred.map.child.java.opts
-Xmx200M
2.4 yarn-site.xml
yarn.nodemanager.aux-services
mapreduce_shuffle
yarn.nodemanager.aux-services.mapreduce_shuffle.class
org.apache.hadoop.mapred.ShuffleHandler
yarn.resourcemanager.ha.enabled
true
yarn.resourcemanager.ha.automatic-failover.enabled
true
yarn.resourcemanager.ha.rm-ids
rm1,rm2
yarn.resourcemanager.zk-address
hdp23:2181,hdp24:2181,hdp25:2181
yarn.resourcemanager.hostname.rm1
hdp21
yarn.resourcemanager.hostname.rm2
hdp22
yarn.resourcemanager.cluster-id
yrc
yarn.nodemanager.resource.memory-mb
512
2.5 slaves
hdp23
hdp24
hdp25
2.6 修改hadoop-env.sh
vim /home/hadoop-2.7.3/etc/hadoop/hadoop-env.sh
把原来的export JAVA_HOME=${JAVA_HOME}
修改为export JAVA_HOME= /usr/local/jdk1.7.0_71
即真实的jdk安装路径
2.7 复制配置到其他节点
cd /home/
scp -r hadoop-2.7.3/ hdp22:/home/
scp -r hadoop-2.7.3/ hdp23:/home/
scp -r hadoop-2.7.3/ hdp24:/home/
scp -r hadoop-2.7.3/ hdp25:/home/
3 环境变量
su root
vim /etc/profile.d/hadoop.sh
export HADOOP_HOME=/home/hadoop-2.7.3
export PATH=$PATH:${HADOOP_HOME}/bin:${HADOOP_HOME}/sbin
复制到其他节点:scp /etc/profile.d/hadoop.sh hdp22: /etc/profile.d/
执行使配置立即生效 . /etc/profile.d/hadoop.sh
4 为启动准备
4.1 zookeeper
启动zookeeper,zk-bat.sh start
Zookeeper已经安装完成 zk-bat.sh是我写的启动脚本
4.2 创建zk命名空间
在主NameNode节点上执行(创建命名空间):
hdfs zkfc -formatZK
4.3 JournalNode
在各个DataNode节点上执行(启动journalnode):
hadoop-daemon.sh start journalnode
使用jps查看服务是否启动
4.4 格式化hdfs
格式化namenode和journalnode目录
hdfs namenode -format ns
4.5 启动namenode
1,在主namenode节点启动namenode进程(hdp21,只在一个NameNode上执行即可)
hadoop-daemon.sh start namenode
2,复制主NameNode(在hdp22上,把备namenode节点的目录格式化并把元数据从主namenode节点copy过来,并且这个命令不会把journalnode目录再格式化了):
hdfs namenode –bootstrapStandby
3,启动备namenode进程(在hdp22上执行)
hadoop-daemon.sh start namenode
4,在两个NameNode上都执行:
hadoop-daemon.sh start zkfc
4.6 启动DataNode
在所有的DataNode上执行(启动datanode):
hadoop-daemon.sh start datanode
6 启停
启动
start-dfs.sh
停止
stop-dfs.sh
7 监控等
hdp21主NameNode
Hdfs浏览器访问地址:
http://hdp21:50070
hdp22备NameNode
Hdfs浏览器访问地址:
http://hdp22:50070
测试NameNode双机
杀掉主NameNode,即hdp21上的NameNode进程,浏览器查看hdp22的状态
1.在hdp21上jps,找到NameNode进程id并杀掉
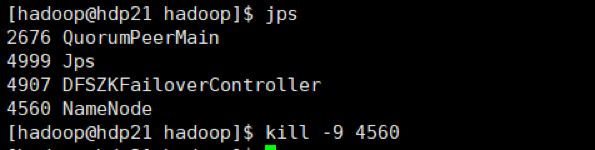
图片 1.png
2.浏览器查看备NameNode状态

[图片上传中...(2.png-f1916-1516245036237-0)]
备用NameNode已经启动了!!!