OpenCV4学习笔记(54)——基于KNN最近邻算法实现手写体数字识别
本次要整理记录的笔记是关于KNN最近邻算法,以及利用KNN最近邻算法实现手写体数字识别的相关内容。
首先先了解一下什么是KNN最近邻算法,下面引用维基百科的定义:
在模式识别领域中,最近邻居法(KNN算法,又译K-近邻算法)是一种用于分类和回归的非参数统计方法。在这两种情况下,输入包含特征空间(Feature Space)中的k个最接近的训练样本。
在k-NN分类中,输出是一个分类族群。一个对象的分类是由其邻居的“多数表决”确定的,k个最近邻居(k为正整数,通常较小)中最常见的分类决定了赋予该对象的类别。若k = 1,则该对象的类别直接由最近的一个节点赋予。
在k-NN回归中,输出是该对象的属性值。该值是其k个最近邻居的值的平均值。
KNN最近邻算法采用向量空间模型来进行分类,属于相同类别的已知样本中,彼此之间的相似度比较高,所以可以借由计算未知类别样本与已知类别样本之间的相似度,来评估未知类别样本可能的分类。通俗地来说,就是根据K个与未知样本距离最近的已知样本的分类统计来预测未知样本的类别,如果未知样本在特征空间中的K个最近邻已知样本中大多数都属于某一种类别,则认为该未知样本也属于这种类别,从而实现对未知样本的分类。
KNN最近邻算法的主要思路如下:
(1)计算未知样本数据跟每一个已知训练样本数据之间的距离;
(2)将所有训练样本数据按照上一步骤中计算得到的距离从近到远排序;
(3)选取距离最近的K个训练样本,也就是得到的最近邻样本,并统计这些最近邻样本的所属类别;
(4)将最近邻样本中出现几率最大的类别作为未知样本的预测类别。
(5)得到对未知样本的预测结果。
KNN最近邻算法可以通过以下例子来帮助理解:
测试样本(绿色圆形)要么被归类为第一类的蓝色方形、要么归类为第二类的红色三角形。如果k=3(实线圆圈)它被分配给第二类(红色三角形),因为有2个三角形和只有1个正方形在内侧圆圈之内。如果k=5(虚线圆圈)它被分配到第一类(蓝色方形),因为有3个正方形与2个三角形在外侧圆圈之内。

可见,在KNN最近邻算法中,K值的选取可谓是至关重要,K值会关系最后预测结果的正确与否。有时候我们需要经过多次设置K值来选取一个合适的值,而K值是否合适,则是取决于数据。一般情况下,如果K值设置过小,会导致噪声的影响非常大,而如果K值设置过大,则会导致样本数据中不同类别的差距变小,这些情况都会很大程度上影响KNN最近邻算法的准确性。
对于样本数据中存在多维特征,而且各种特征的取值范围都不相同时,尽量先将特征值进行归一化后再进行预测,因为特征尺度或特征重要程度不一致都会影响KNN最近邻算法的准确性。如果是对于二分类问题,那么K最好是设为奇数,这样就不会出现两种类别的投票数相同的问题。
在OpenCV中已经封装好了KNN最近邻算法,我们可以使用Ptr来创建一个KNN指针,然后再通过knn->setDefaultK(K)来设置K值,注意在进行分类问题时还需要指定knn->setIsClassifier(true)。当我们获取了训练的数据集和标签集,就可以通过knn->train()进行训练。下面以手写体数字识别为例,利用KNN最近邻算法训练一个0~9手写体数字的识别分类器,代码演示如下:
//读取OpenCV自带的一张手写体数字图,尺寸为Size(2000,1000),其中每个数字为(20,20)的区域,总共有 [(1000/20)x(2000/20)] 共5000个数字
Mat train_image = imread("D:\\opencv_c++\\opencv_tutorial\\data\\images\\digits.png");
cvtColor(train_image, train_image, COLOR_BGR2GRAY);
int height = train_image.rows;
int width = train_image.cols;
//将所有数字裁剪出来存放到一个vector中
vector<Mat>train_vec;
for (int row = 0; row <= height-20; row += 20)
{
for (int col = 0; col <= width - 20; col += 20)
{
Rect digit_rect(col, row, 20, 20);
Mat digit = train_image(digit_rect).clone();
train_vec.push_back(digit);
}
}
//制作训练数据集和标签
Mat train_data = Mat::zeros(Size(400, 5000), CV_8UC1);
Mat labels = Mat::zeros(Size(1, 5000), CV_8UC1);
//将所有裁剪出来的手写数字图转化成一行400个像素排列
for (int i = 0; i < train_vec.size(); i++)
{
train_vec[i] = train_vec[i].reshape(1, 1);
}
//制作训练数据集,为一个5000行400列的Mat对象
for (int r = 0;r < 5000; r++)
{
for (int c = 0; c < 400; c++)
{
train_data.at<uchar>(r, c) = train_vec[r].at<uchar>(0, c);
}
}
//制作标签集,每个数字有500张图像
for (int j = 0; j < 5000; j++)
{
int label = j / 500;
labels.at<uchar>(j, 0) = label;
}
//创建KNN指针并设置训练参数
Ptr<ml::KNearest> knn = ml::KNearest::create();
int K = 5;
knn->setDefaultK(K); //设置选取的最近邻样本数K
knn->setIsClassifier(true); //设置是否进行分类训练
train_data.convertTo(train_data, CV_32F);
labels.convertTo(labels, CV_32F);
Ptr<ml::TrainData> data = ml::TrainData::create(train_data, ml::ROW_SAMPLE, labels);
knn->train(data);
knn->save("knn_digits_model.yml");
//使用训练集进行测试,计算正确率
Mat results = Mat::zeros(labels.size(), CV_32F);
knn->findNearest(train_data, K, results);
float acc=0;
for (int n = 0; n < labels.rows; n++)
{
int result = results.at<float>(n, 0);
int label = labels.at<float>(n, 0);
if (result == label)
{
acc++;
}
}
acc = acc / 5000 * 100;
cout << "正确率: " << acc << "%" << endl;
我们使用的训练数据是OpenCV自带的一张手写数字图,如下(看着感觉要瞎。。。):
我们先将这张图中的每个小数字进行裁剪、生成图像集,并和标签集联合在一起制作成数据集(为一个Mat对象),使用Ptr将制作好的数据集Mat对象转化为ml模块的训练数据类型TrainData,也就是将训练数据和标签进行关联,并以指针形式返回。其中第一个参数是训练的图像集,第二个参数是样本数据的组织形式(OpenCV中有按行排列和按列排列的数据组织格式),第三个参数是标签集。返回的TrainData类的指针就是我们需要的训练数据了。
注意用于训练的图像集必须先转化为CV_32F,标签集必须先转化为CV_32F或CV_32S。
经过训练,并保存为一个.yml文件,这就是我们得到的手写数字体的识别分类器模型了,后续我们就可以加载这个模型来实现手写体数字识别。
在训练过程结束后,我们使用原有的训练集作为测试数据,测试一下得到的模型在训练数据集上的正确率,运行效果如下:

我们的手写体数字识别模型在训练数据上的准确率在96.4%左右,这个准确率看起来好像还行,但其实因为用来测试的数据本身就是训练数据,所以这个准确率其实并不可靠,还需要使用其他训练数据集之外的样本来测试才可以得到比较靠谱的准确率。但这里作为演示,就只是使用OpenCV自带的数据来做测试了,下面给出加载模型并进行预测的演示代码:
//读入预测图像
Mat test_image = imread("D:\\opencv_c++\\opencv_tutorial\\data\\images\\9_99.png");
cvtColor(test_image, test_image, COLOR_BGR2GRAY);
//必须先将预测图像缩放到和训练图像一样的尺寸
resize(test_image, test_image, Size(20, 20));
imshow("test_image", test_image);
//再将预测图像转化成以行来组织的数据,并转化为CV_32F类型,否则进行预测时会报错
test_image = test_image.reshape(1, 1);
test_image.convertTo(test_image, CV_32F);
//加载训练好的knn模型
Ptr<ml::KNearest> knn_test = ml::KNearest::load("knn_digits_model.yml");
Mat results = Mat::zeros(Size(test_image.rows,1), CV_32F);
knn_test->findNearest(test_image, 5, results);
cout << "预测手写数字结果: "<< results.at<float>(0, 0) << endl;
我们使用knn_test->findNearest()来对测试样本进行预测,其参数含义如下:
(1)参数samples:需要预测的数据,每一行为一个样本;
(2)参数K:选择的最近邻数据样本的数量,和训练模型时的K一样即可;
(3)参数result:预测结果,每一行都是对一个输入数据样本的预测结果;
(4)参数neighborResponses:最近邻的K个元素;
(5)参数dist:预测样本与最近邻K个元素的距离。
预测结果如下:
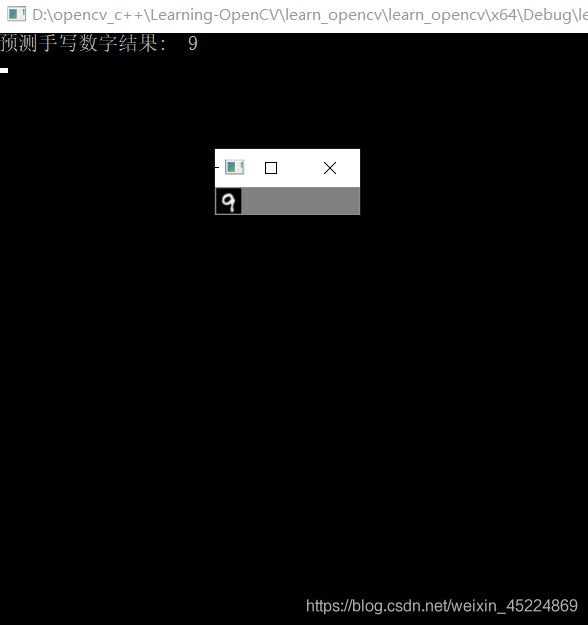
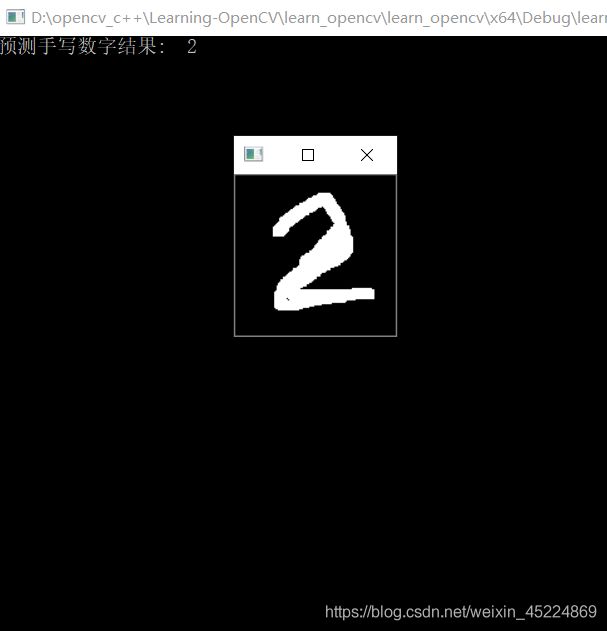
这里输入的测试图像,也都是从OpenCV自带的那张亮瞎眼的数字图中裁剪下来的,总的来说对于自带的数据,该模型的预测效果还是可以的。但是经过测试,如果用的是我们自己的手写数字图,那么准确率其实有些堪忧。
那么经过了上述的制作训练图像集、制作标签集、制作训练数据集、训练模型、保存模型、加载模型、对输入图像进行预测等等一系列操作,我们就实现了一个简易的手写体数字识别小程序。但是这个小程序只能用于静态识别,下次的笔记就来整理一个通过鼠标书写数字作为预测样本的实时手写体数字识别小程序的实现。那本次笔记整理到此结束,谢谢阅读~
PS:本人的注释比较杂,既有自己的心得体会也有网上查阅资料时摘抄下的知识内容,所以如有雷同,纯属我向前辈学习的致敬,如果有前辈觉得我的笔记内容侵犯了您的知识产权,请和我联系,我会将涉及到的博文内容删除,谢谢!