
pandas支持三种数据类型,分别是Series、DataFrame和Panel。DataFrame用的比较多,Panel用的比较少
1.Series
1.1创建Series
序列Series相当于python中的一维数组(列表)。通过函数创建Series:
pandas.Series(data,index,dtype,copy)
index是Series的索引,若未指定,则为[0,1,2,....];dtype指定数据类型,若未指定,则推断数据类型;copy复制数据,默认False;data可以包含三种:分别是:
| 方式 | 说明 |
|---|---|
| 通过列表创建 | 可以通过python列表或者numpy array创建 |
| 通过字典创建 | 通过python字典创建 |
| 通过标量创建 | 通过常数创建 |
例程:
#coding=utf-8
import numpy as np
import pandas as pd
#创建空的Series
print("Series为空:")
print(pd.Series())
#通过list创建Series
print("通过list创建Series:")
print(pd.Series([10,20,30,40],index=[1,2,3,4]))
#通过numpy创建Series
print("通过numpy创建Series")
print(pd.Series(np.arange(10)))
#通过字典创建Series:
print("通过字典创建Series")
print(pd.Series({'a':1,"b":2,'c':3},index=list('badc')))
#通过常量创建Series:
print("通过常量创建Series")
print(pd.Series(4,index=["a","b","c","d"]))
1.2访问Series
1.2.1通过位置访问:
#coding=utf-8
import numpy as np
import pandas as pd
s=pd.Series([10,20,30,40],index=['a','b','c','d'])
print(s[1]) #20访问第二个元素
print(s[:3]) #10 20 30访问前三个元素
print(s[-2:]) #30 40访问后两个元素
print(s[[0,2,1]]) #10 30 20访问多个任意位置元素,注意此时索引为数组
1.2.2通过标签(索引)访问:
#coding=utf-8
import numpy as np
import pandas as pd
s=pd.Series([10,20,30,40],index=['a','b','c','d'])
print(s['a']) #访问索引a对应的元素,访问一个元素
print(s[['a','b','c']]) #访问索引a,b,c对应的元素,访问多个元素,此时索引为数组
1.3序列基本属性和方法

2.DataFrame
2.1创建DataFrame
DataFrame是一个二维数据结构,类似于一个电子表格。DataFrame通过下列函数创建:
pandas.DataFrame(Data, index, columns, dtype, copy)
index为行标签,columns是列标签,当没有指定时,默认都为np.arange(n)
#coding=utf-8
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
#通过列表创建
data = [['Alex',10],['Bob',12],['Clarke',13]]
print(pd.DataFrame(data, columns=['Name', 'Age']))
#通过字典创建
data = {'Name':['Tom','Jack','Steve','Ricky'],'Age':[28,34,29,42]}
print(pd.DataFrame(data, index=['rank1','rank2','rank3','rank4']))
#通过字典的Series创建
data = {'one':pd.Series([1,2,3],index=['a','b','c']),
'two':pd.Series([1,2,3,4],index=['a','b','c','d'])}
print(pd.DataFrame(data))
2.2访问DataFrame
2.2.1列访问
- 列选择
df = pd.DataFrame(data, columns=list('ABCD'))
df['A'] #访问列A
- 列增加
df = pd.DataFrame(data, columns=list('ABCD'))
df['E'] = df['A'] + df['B'] #增加列E
- 列删除
df = pd.DataFrame(data, columns=list('ABCD'))
del df['A'] #删除列A
df.pop('B') #删除列B
2.2.2行访问
- 基于标签选择
df = pd.DataFrame({'one' : pd.Series([1, 2, 3], index=['a', 'b', 'c']),
'two' : pd.Series([1, 2, 3, 4], index=['a', 'b', 'c', 'd'])})
df.loc['b'] #访问index为b的行
df.loc['b', 'one']#访问index为b的行的one列
- 基于整数选择
df = pd.DataFrame({'one' : pd.Series([1, 2, 3], index=['a', 'b', 'c']),
'two' : pd.Series([1, 2, 3, 4], index=['a', 'b', 'c', 'd'])})
df.iloc[2] #访问第三行
df.iloc[2,0:1]#访问第三行的第一列
- 切片
df = pd.DataFrame({'one' : pd.Series([1, 2, 3], index=['a', 'b', 'c']),
'two' : pd.Series([1, 2, 3, 4], index=['a', 'b', 'c', 'd'])})
df[2:4] #访问第三行和第四行
- 附加行
df = pd.DataFrame({'one' : pd.Series([1, 2, 3], index=['a', 'b', 'c']),
'two' : pd.Series([1, 2, 3, 4], index=['a', 'b', 'c', 'd'])})
df2 = pd.DataFrame({'one' : pd.Series([4], index=['e']),
'two' : pd.Series([5], index=['e'])})
df.append(df2) #增加1行到df,形成新的dataFrame,原df未改变
- 删除行
df = pd.DataFrame({'one' : pd.Series([1, 2, 3], index=['a', 'b', 'c']),
'two' : pd.Series([1, 2, 3, 4], index=['a', 'b', 'c', 'd'])})
df.drop('a') #删除标签为a的行
2.3DataFrame基本属性和方法
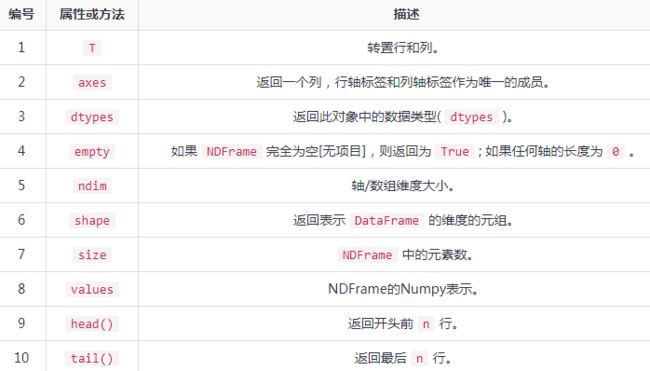
3.聚合函数
聚合函数采用轴参数,轴可以通过名称或整数来指定,默认为axis=0是按列来统计,可以指定axis=1按行来统计。
下图列出了一些重要的用于描述统计信息的函数:
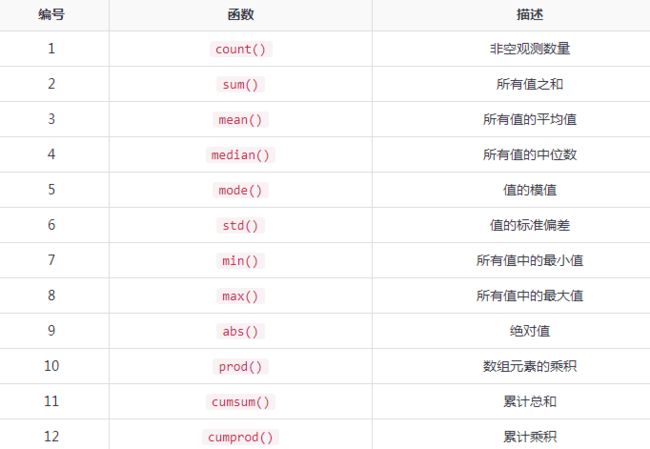
describe函数用于计算DataFrame列的统计信息摘要:
d = {'Name':pd.Series(['Tom','James','Ricky','Vin','Steve','Minsu','Jack',
'Lee','David','Gasper','Betina','Andres']),
'Age':pd.Series([25,26,25,23,30,29,23,34,40,30,51,46]), 'Rating':pd.Series([4.23,3.24,3.98,2.56,3.20,4.6,3.8,3.78,2.98,4.80,4.10,3.65])}
df = pd.DataFrame(d)
print df.describe()
运行结果为:

4.函数运用
根据函数运用的对象分为3种方法:
| 方法 | 说明 |
|---|---|
| pipe | 对整个DataFrame运用 |
| apply | 对行或列运用 |
| applymap | 对单个元素运用 |
- pipe
def adder(ele1,ele2):
return ele1+ele2
df = pd.DataFrame(np.random.randn(5,3),columns=['col1','col2','col3'])
df.pipe(adder,2) #df+2
- apply
df = pd.DataFrame(np.random.randn(5,3),columns=['col1','col2','col3'])
df.apply(np.mean)#对每列运用mean函数,可以传入参数axis=1对每行运用函数
- applymap
df = pd.DataFrame(np.random.randn(5,3),columns=['col1','col2','col3'])
df.applymap(lambda x:x*100) #对每个元素乘以100
5.重建索引
- 通过reindex方法修改index或者columns重建索引
df = pd.DataFrame(np.random.randn(5,3),columns=['col1','col2','col3'])
print(df.reindex(index=[0,1,2],columns=['col1','col4']))#新的col4列的值为NAN
- 通过reindex_like方法复制其他df的索引
df1 = pd.DataFrame(np.random.randn(10,3),columns=['col1','col2','col3'])
df2 = pd.DataFrame(np.random.randn(7,3),columns=['col1','col2','col3'])
df1 = df1.reindex_like(df2) #复制df2的索引,只保留前7行
print df1
此外,reindex_like方法还提供额外参数method(ffill,bfill,nearst)和limit(填充行数)
df1 = pd.DataFrame(np.random.randn(10,3),columns=['col1','col2','col3'])
df2 = pd.DataFrame(np.random.randn(7,3),columns=['col1','col2','col3'])
df2 = df2.reindex_like(df1,method='ffill')#向前填充
df2 = df2.reindex_like(df1,method='ffill',limit=2)仅向前填充2行
- 通过rename方法重命名索引
df1 = pd.DataFrame(np.random.randn(10,3),columns=['col1','col2','col3'])
df1 = df1.rename(index={0:'timo',1:'anni',2:'fiona',3:'jinx'})#将前4行的行索引修改
rename方法还可以通过传递参数inplace为True来改变原df,默认为false则会复制原df,不会修改原df。
6.迭代
6.1迭代列名
df1 = pd.DataFrame(np.random.randn(10,3),columns=['col1','col2','col3'])
for col in df1:
print col
6.2迭代行
- iteritems() - 将列迭代为(key,value)对
将列名作为键(key),行名和对应的值组成Series对象作为值(value)
- iterrows - 将行迭代为(key, value)对
将行名作为索引(key),列名和对应的值组成Series对象作为值(value)
- itertuples - 以namedtuples的形式迭代行
返回一个命名元组的迭代器,第一个元素是行的索引,后面的是行的各个值
df = pd.DataFrame(np.random.randn(4,3),columns = ['col1','col2','col3'])
for col, row_value in df.iteritems():
print col, row_value
for row, col_value in df.iterrows():
print row, col_value
for row_tup in df.itertuples():
print row_tup
7.日期功能
- 使用date_range创建日期
datelist = pd.date_range('20181101', periods=5)
print(datelist) #从1101开始,默认以天为单位打印5个数据
datelist = pd.date_range('20181101', periods=5, freq='M')
print(datelist)#从1130开始,以月为单位打印5个数据
- bdate_range
bdate_range和date_range创建日期一样,区别是不包括星期六和星期日
start = pd.datetime(2018,11,1) #datetime用于创建某一天
end = pd.datetime(2018,11,11)
datelist = pd.bdate_range(start, end)
print(datelist) #从1101开始,默认以天为单位打印到1111,但是跳过之间的周六周日
8.时间差(timedelta)
时间差是两个时间的差值,可以为正,也可以为负。
- 创建时间差
#通过字符串创建时间差
timediff = pd.Timedelta("2 days 30 seconds")
print(timediff)
#通过整数创建时间差
timediff = pd.Timedelta(2,unit='D')
print(timediff)
timediff = pd.Timedelta(days=2)
print(timediff)
- 时间差加减法运算
s = pd.Series(pd.date_range('2012-1-1', periods=3, freq='D'))
td = pd.Series([ pd.Timedelta(days=i) for i in range(3) ])#创建时间差
df = pd.DataFrame(dict(A = s, B = td))
df['C']=df['A']+df['B']#列A的日期加上时间差成为列C的日期
df['D']=df['C']-df['B']#列C的日期减上时间差成为列D的日期,与A相同
print(df)