python进阶-xlrd读excel
原文链接:http://www.juzicode.com/archives/4557
[注] xlrd2.0以后版本只支持xls格式的excel表格,不再支持xlsx格式
xlrd可以用来读excel表格,xlwt用来写excel表格,二者都不是标准库,需要安装。
pip install xlrd,xlwt今天先介绍xlrd,我们先创建一个xls格式的文件,文件包含了3个sheet,内容是下面2张图片这样的,其中Sheet3是个空表:
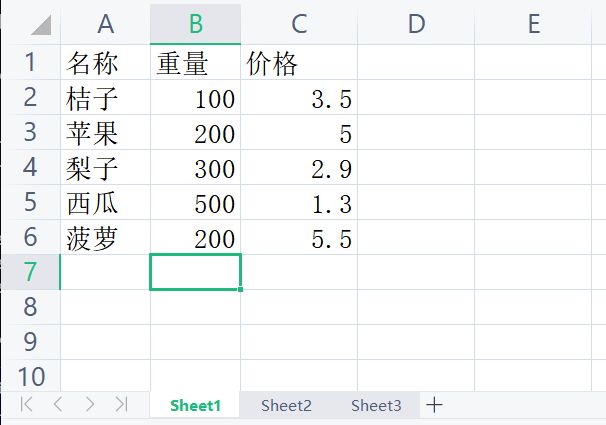
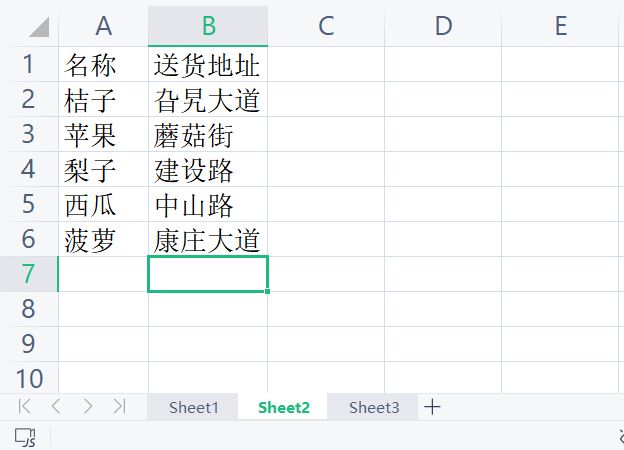
excel文件的结构:file文件–sheet表–cell单元格,所以excel文件的访问步骤也就分为:第1步先是访问excel文件本身,第2步对excel文件中的sheet进行操作,第3步才是对sheet中的cell操作。
1、打开文件
首先使用open_workbook()打开文件,创建一个wb实例。
import xlrd
wb = xlrd.open_workbook("xlrd-test.xls")运行结果:
wb:
2、sheet方法、属性
利用前面获取的wb实例,可以获取sheet相关属性或对象:
- 获取sheet的数量:wb.nsheets
- 获取sheet的名字,得到一个list:wb.sheet_names()
- 获取所有sheet对象:wb.sheets()
- sheet名称查找sheet对象:wb.sheet_by_name(“test”)
- sheet编号查找sheet对象:wb.sheet_by_index(1)
print('-----欢迎来到www.juzicode.com')
print('-----VX公众号: 桔子code或juzicode \n')
import xlrd
wb = xlrd.open_workbook("xlrd-test.xls")
print('wb:',wb)
#获取表(sheet)的数量
sheet_count= wb.nsheets
print('sheet_count:',sheet_count)
#获取所有表的名称
sheet_names=wb.sheet_names()
print('sheet_names:',sheet_names)
#获取所有表对象
sheet_objs = wb.sheets()
print('sheet_objs:',sheet_objs)
#获取单个表格对象
obj = wb.sheet_by_name("Sheet1")
print('Sheet1 obj:',obj)
obj = wb.sheet_by_index(1)
print('index=1 obj:',obj)运行结果:
-----欢迎来到www.juzicode.com
-----VX公众号: 桔子code或juzicode
wb:
sheet_count: 3
sheet_names: ['Sheet1', 'Sheet2', 'Sheet3']
sheet_objs: [Sheet 0:, Sheet 1:, Sheet 2:]
Sheet1 obj: Sheet 0:
index=1 obj: Sheet 1:
利用sheet对象获取单个sheet的名称name,行nrows、列数ncols,下面这个例子遍历上述例子中的sheet_objs:
for sheet_obj in sheet_objs:
print('sheet_obj.name:',sheet_obj.name)
print('sheet_obj.nrows:',sheet_obj.nrows)
print('sheet_obj.ncols:',sheet_obj.ncols)运行结果:
sheet_obj.name: Sheet1
sheet_obj.nrows: 6
sheet_obj.ncols: 3
sheet_obj.name: Sheet2
sheet_obj.nrows: 6
sheet_obj.ncols: 2
sheet_obj.name: Sheet3
sheet_obj.nrows: 0
sheet_obj.ncols: 0
3、cell方法、属性
3.1、操作行列
通过row_values(行号,起始列,终止列)获取某行的值,其中不包含终止列,左闭右开区间。
通过col_values(列号,起始行,终止行)获取某列的值,其中不包含终止行,左闭右开区间。
row_values = sheet_obj.row_values(0, 1, 3) # 第0行,第1~3列(不含第3表)
print('row_values:',row_values)
col_values = sheet_obj.col_values(1, 0, 5) # 第1列,第0~5行(不含第5行)
print('col_values:',col_values)运行结果:
row_values: ['重量', '价格']
col_values: ['重量', 100.0, 200.0, 300.0, 500.0]
3.2、操作cell
使用cell的坐标位置(x,y)访问特定cell,cell的行列编号是从0开始的,最左上角为(0,0)。
1) 、获取cell值:
sheet_obj.cell_value(1, 2)
sheet_obj.cell(1, 2).value
sheet_obj.row(1)[2].value
sheet_obj.col(2)[1].value
2)、 获取cell类型:
sheet_obj.cell(1, 2).ctype
sheet_obj.cell_type(1, 2)
sheet_obj.row(1)[2].ctype
sheet_obj.col(2)[1].ctype
print('访问cell(0,0)')
cell_type = sheet_obj.cell_type(0,0)
print('cell_type:',cell_type)
cell_value = sheet_obj.cell_value(0,0)
print('cell_value:',cell_value)
print('type(cell_value):',type(cell_value))
print('访问cell(1,1)')
cell_type = sheet_obj.cell_type(1,1)
print('cell_type:',cell_type)
cell_value = sheet_obj.cell_value(1,1)
print('cell_value:',cell_value)
print('type(cell_value):',type(cell_value))运行结果:
cell_type: 2
cell(1, 2).ctype: 2
row(1)[2].ctype: 2
col(2)[1].ctype: 2
type(cell_value):
cell_value: 3.5
cell(1, 2).value: 3.5
row(1)[2].value : 3.5
col(2)[1].value: 3.5
从上面的例子看读出cell的ctype为2,对应的Python类型为float,
ctype和Python内置数据类型对比:
#类型对比:
cell_type = sheet_obj.cell_type(0,0)
print('cell_type(0,0):',cell_type)
cell_value = sheet_obj.cell_value(0,0)
print('type(cell_value(0,0)):',type(cell_value))
cell_type = sheet_obj.cell_type(1,2)
print('cell_type(1,2):',cell_type)
cell_value = sheet_obj.cell_value(1,2)
print('type(cell_value(1,2)):',type(cell_value))运行结果显示,ctype=1对应str,ctype=2对应float:
cell_type(0,0): 1
type(cell_value):
cell_type(1,2): 2
type(cell_value):
扩展阅读:
- https://xlrd.readthedocs.io/en/stable/changes.html xlrd版本变更
- http://www.python-excel.org/ 更多的excel表格python库