深度学习实战篇之 ( 四) -- TensorFlow学习之路(一)
内容解释
TensorFlow是一个基于数据流编程(dataflow programming)的符号数学系统,被广泛应用于各类机器学习(machine learning)算法的编程实现,其前身是谷歌的神经网络算法库DistBelief 。
Tensorflow拥有多层级结构,可部署于各类服务器、PC终端和网页并支持GPU和TPU高性能数值计算,被广泛应用于谷歌内部的产品开发和各领域的科学研究 。
TensorFlow由谷歌人工智能团队谷歌大脑(Google Brain)开发和维护,拥有包括TensorFlow Hub、TensorFlow Lite、TensorFlow Research Cloud在内的多个项目以及各类应用程序接口(Application Programming Interface, API) 。自2015年11月9日起,TensorFlow依据阿帕奇授权协议(Apache 2.0 open source license)开放源代码。

前言
深度学习的发展离不开广大科研学者的支持,同样也少不了深度学习框架的助攻,前期的文章中,我们学习了深度学习的一部分理论知识,上手了一些深度学习的实战内容,但是却没有用到大厂的深度学习平台,不能体会其中的乐趣,由于深度学习平台众多,小编就分享自己比较熟悉且是如今学术界较为常用的深度学习平台的学习历程,从本篇文章开始,小编将与大家一起学习谷歌开源的深度学习平台--TensorFlow,当然,后期也会适当分享一些Keras和Pytorch的文章,便于了解不同深度学习平台的代码有何异同有优缺点。
![]()
一、前言
![]()
1.常见深度学习框架有哪些
深度学习框架又称之为深度学习平台,其基本可以定义为:人工智能领域下,深度学习研究方向的实战平台(软件)。目前比较常用的深度学习平台有:兼具表达清晰和速度快优点的Caffe,庞大且流行的TensorFlow,上手简单的Keras,学术之星的pytorch,接口灵活的Mxnet,产业实践一体化的PaddlePaddle,全场景AI技术的Mindspore。
在小编看来,Caffe是真正意义上的第一个深度学习框架,同时也是第一个实践意义上十分容易上手和兼具现代意义的深度学习平台,其主要作者为当时Facebook的贾扬清,在早期更好的支持以卷积神经网络为基础的神经网络的模型训练, 其后也发展为支持其他序列数据的神经网络(例如,RNN,LSTM等等),随着技术的发展、自身业务发展的需要、学术需求的增长,谷歌(Google)开源了TensorFow,Keras,脸书(Facebook)推出了Pytorch,亚马逊的李沐贡献了Mxnet,百度打造了PaddlePaddle,华为开创性的提出了Mindspore,此外,还有旷世(Face++)的天元(MegEngine)等等。

2.深度学习平台的特点
深度学习平台的特点较多,小编这里主要重点表述它们之间的不同。
1.Caffe框架主要支持以卷积神经网络的(CNN)为代表的神经网络模型,在深度学习早期有着较多的使用,不需要编写太多复杂的代码即可构建神经网络模型,主要在文件中进行参数的改动,如今在工业界依然还有较多的身影,但在学术界的地位相对趋于弱势。
2.TensorFlow为谷歌重磅开源且力推的深度学习开发的利器,其在工业界和学术界的地位非常深厚,具有上手简单,代码易读等优点,但构建一个神经网络相对caffe来说略显复杂,其在学术界的地位在近两年有被Pytorch挑战。
3.Keras是目前小编用过代码量最少的框架,严格来说起不算是一个框架,更像是一个高级的基于python的神经网络API(底层为TensorFlow等深度学习框架的封装接口),其构建常见神经网络模型的代码量远远少于其余框架,新学者用其课迅速体验深度学习的训练过程,用于后期的部署demo展示也同样较为简单。
4.Pytorch为近期升起的学术之星,近年来人工智能顶会论文开源的深度学习代码多为Pytorch,有着逐渐取代TensorFlow在学术界的地位,其代码简洁易懂,且易于调试,十分受人欢迎。
5.Paddle是国内第一个开源深度学习框架,是国内框架孤独的先行者,该框架如今在国内的产学界都有着一定的地位,其在提升预训练模型精度上有着不错的体验,与其他深度学习框架的代码大同小异,有着良好的开源社区,免费的GPU使用,推荐同学们都可以学学。
6.Mindspore是华为公司开创性提出的全场景AI计算框架,其有着其他深度学习平台缺乏的前沿技术,例如在内存管理,分布式训练,嵌入式平台移植等都取得了不错的成绩,华为勇闯无人区技术的精神和强大的工程师团队令小编深深折服,同学们想不断的在人工智能的浪潮中越战越勇,时刻不断学习前沿技术,华为的产品和技术路线关注是非常不错的选择。
3.为什么要学习深度学习框架
小编始终认为学习一个新的东西的时候,我们最好还是问问为什么要学习它,它到底有着怎样的魅力吸引着我们去学习呢?学会不断审问自己,我们才会在后期的学习过程中走的更远,不至于迷茫。问题还是回到原点,我们为什么需要学习或者说使用这些深度学习平台呢?同学们也许已经学习过深度学习实战盘文章的前面几篇文章,例如第一篇第二篇我们都未曾采用深度学习框架,而是直接使用pyton代码就实现了简单的深度学习代码(不包括训代码),那么为什么我们还是要学会用深度学习框架呢?
1.首先回答不用深度学习框架是否可以编写神经网络代码?答案是可以,而且最开始的研究者正是这样做的,但是这些做对于如今的学习者有着不太友好的缺点,就是神经网络中所有的东西都要自己去实现一遍,对于一些比较难实现的部分,可能无法做的更好(比如说代码质量差),同样,如果每个人都写一套自己的深度学习代码,那么就会不断的重复造轮子,浪费了时间也不一定有效,开源深度学习平台的好处在于其后有着实力雄厚的深度学习开发工程师,他们对代码的理解,构造,优化,内存管理,加速,网络构建逻辑都有着严格甚至优秀的指导路线,因此,对于每一个开发者自己写出来的代码,基于深度学习平台出来的代码无疑是最好使用和便于分享的高质量代码。
2.深度学习平台的使用在一定程度上大大节省了产学两界的开发时间和训练时间,甚至是部署时间,研究者通常只需要提供idea(想法)就可以很快的通过深度学习平台搭建自己想要的网络结构,进而快速训练验证自己的想法,何乐为不为呢?
![]()
二、TensorFlow 简介
![]()
什么是TensorFlow
TensorFlow(TF)是谷歌开源的深度学习平台,如今已经升级为Tf2.0了,在代码风格上,越来越趋近于Pytorch,但是由于TF2.0的转化需要一定的时间,现在好多代码依旧研习TF1的版本的代码,小编最常用的版本为Tf1.12-1.14版本,以后的代码也会用1的版本进行编写。从TF的英文单词来看,由Tensor(张量)和Flow(流)组成,TF的代码核心正是基于此,首先,我们了解下张量为何?我们以前学过的向量,矩阵等的数据表示在TF中统称为张量,我们所熟知的这些数据在TF的代码中都会被转换成张量的表示,Flow(流)表示的是数据的流动,也就是计算,总的来说可以简单的理解为,TF的代码即可认为是以Tensor为数据格式进行流动计算的过程。
TensorFlow三要素
1.计算图(graph):以一个个操作(operation,简单理解为加减乘除)节点为基础构成的图结构,用来表示计算任务。
2.张量(Tensor):使用tensor来表示数据,其具有维度和大小。
3.会话(session):用来执行图,进而开始深度学习代码的训练过程
TensorFlow 代码运行流程
1.数据预处理:通常为处理为支持网络模型输入的tensor数据格式
2.构建图:构建一个需要计算的任务,即图结构,表现为神经网络模型 的构建方式,数据是如何进行训练的过程。
3.会话创建:开启会话进而执行图结构开始训练过程,训练结束后关闭会话
![]()
三、TensorFlow 基本使用
![]()
安装TensorFlow
TensorFlow的安装方式,特别是GPU版本的安装,小编已经在这篇文章中进行讲解了(python环境搭建(番外篇)---那些年走过的路),大家一定要先去安装好后才继续下面操作,当然,作为学习者,安装过程的踩坑,我觉得是必要的。跟着小编来做一下测试:
#1.检查tf是否安装成功,查看版本,检测GPU是否可用
import tensorflow as tf
tf_version = tf.__version__
print("\n当前tf的版本为:{}".format(tf_version))
即可以小编的tf版本为 1.12.0

如上图所示,即可认为tf环境搭建成功,可以接着往下走了。
tf 声明常量
# 声明常量操作
# 声明常量
a = tf.constant(3)
b = tf.constant(6)
# 计算操作
c = a + b
# 开启会话,运行完后自动关闭
with tf.Session() as sess:
result = sess.run(c)
print("a+b 的结果是:{}".format(result))
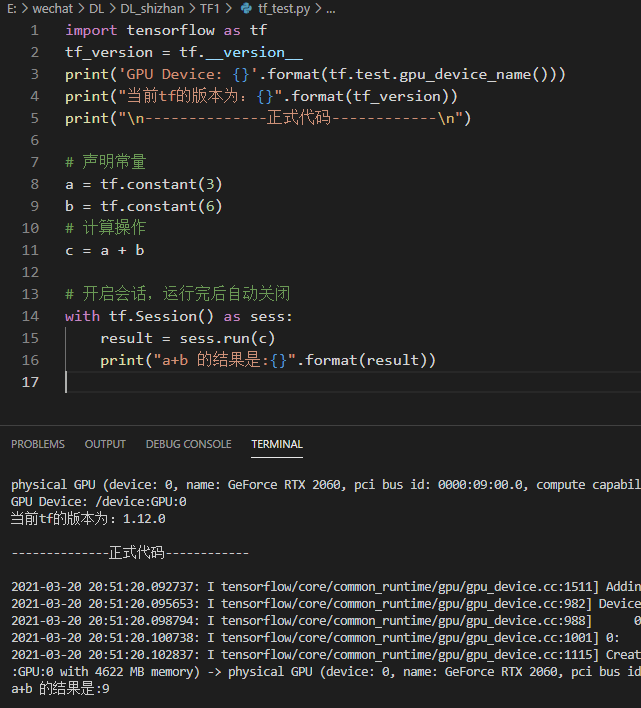
如上如所示,我们用tf声明了两个常量,操作为做加法,最后开启会话进行执行,进入打印输出结果,比较简单,此处要思考的地方为,为什么开启会话,而不是直接执行,如果我们这样做:
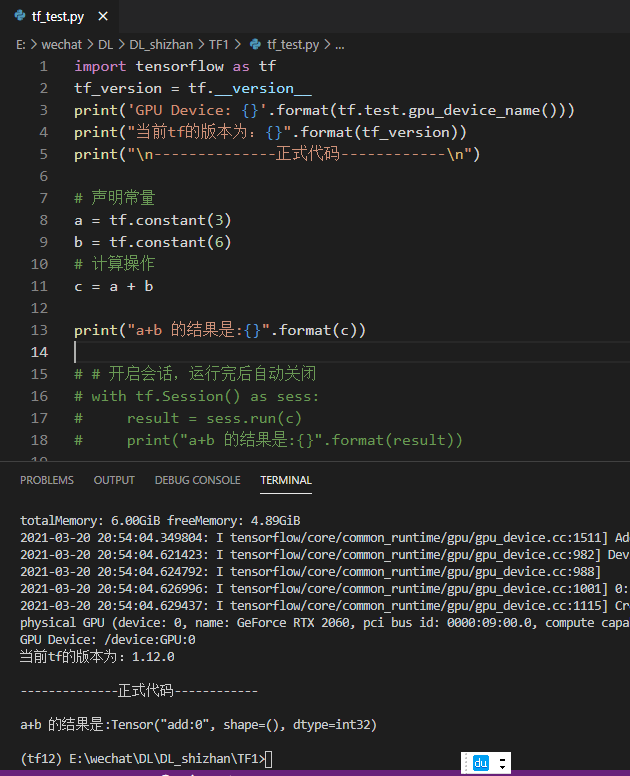
如上如发现,不开启会话,直接运行并不能实现加法操作,因此必须先开启会话才可以执行,这也是tf的执行机制,开启后执行run语句才可以真正的执行我们想要的操作。
TensorFlow 变量操作
import tensorflow as tf
# 声明变量
a = tf.Variable(5, name="counter0")
b = tf.Variable(7, name="counter1")
# 计算操作
c = tf.add(a,b)
# 由于之前是变量,随意必须先初始化才可以进行会话
init_op = tf.initialize_all_variables()
# 开启会话,运行完后自动关闭
with tf.Session() as sess:
sess.run(init_op)
result = sess.run(c)
print("a+b 的结果是:{}".format(result))


结语
本周的分享就到这里了,作为深度学习平台的第一篇文章,我们做了一个概括性的分享,并对TensorFlow平台的一些基本使用进行讲解,下期我们继续对TensorFlow设计深度学习的一些操作进行分享,同学们记得下来一定实操学习哦。
周末愉快,我们下期再会!
编辑:玥怡居士|审核:小圈圈居士
▼
往期精彩回顾
▼
深度学习实战篇之 ( 三) -- 初识人脸检测
深度学习实战篇之(二)----- 梯度下降算法代码实现
深度学习实战篇之(一)----- Python感知机实现
过去的一年,我们都做了啥:
【年终总结】2021,辞旧迎新再出发
【年终总结】辞旧迎新,2020,我们再出发
![]()

扫
码
关
注
IT进阶之旅
![]()
我就知道你“在看”
