MapReduce实战-词频统计、文件合并排序
文章目录
- 环境搭建
- 词频统计
-
- 输入
- 源码
- 输出
- 合并
-
- 输入
- 源码
- 输出
- 排序
-
- 输入
- 源码
- 输出

环境搭建
hadoop伪分布式集群环境,包括设置JAVA_HOME、HADOOP_HOME等。
可参考使用docker部署hadoop集群-手把手复现
词频统计
统计所有输入文件中每个单词出现的次数。
如输入:
file1.txt
Hello World
file2.txt
Bye World
输出:
Bye 1
Hello 1
World 2
输入
- 创建输入文件
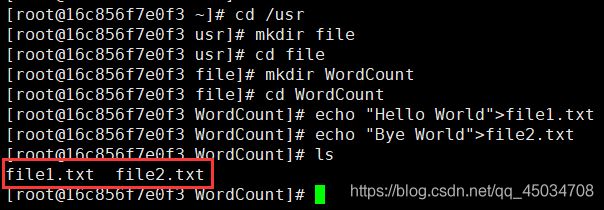
cd /usr
mkdir file #新建目录
cd file
mkdir WordCount
cd WordCount
echo "Hello World">file1.txt
echo "Bye World">file2.txt #file1、2作为输入文件
- 传入hdfs输入文件夹
hdfs dfs -mkdir -p /user/root #若无root用户文件夹则先创建
hadoop fs -mkdir WordCount #创建一个目录(可自定义)
hadoop fs -mkdir WordCount/input #输入文件夹
hadoop fs -ls WordCount #查看文件
hadoop fs -put /usr/file/WordCount/file*.txt WordCount/input #上传
hadoop fs -ls WordCount/input
#hadoop fs -rmr wc/output #若存在则删除输出目录

源码
- 源代码
cd /usr/file/WordCount
vi WordCount.java
import java.io.IOException;
import java.util.StringTokenizer;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
public class WordCount {
public static class TokenizerMapper extends Mapper<Object, Text, Text, IntWritable> {
private final static IntWritable one = new IntWritable(1);
private Text word = new Text();
public void map(Object key, Text value, Context context) throws IOException, InterruptedException {
StringTokenizer itr = new StringTokenizer(value.toString());
while (itr.hasMoreTokens()) {
word.set(itr.nextToken());
context.write(word, one);
}
}
}
public static class IntSumReducer
extends Reducer<Text, IntWritable, Text, IntWritable> {
private IntWritable result = new IntWritable();
public void reduce(Text key, Iterable<IntWritable> values, Context context) throws IOException, InterruptedException {
int sum = 0;
for (IntWritable val : values) {
sum += val.get();
}
result.set(sum);
context.write(key, result);
}
}
public static void main(String[] args) throws Exception {
Configuration conf = new Configuration();
if (args.length != 2) {
System.err.println("usage: WordCount " );
System.exit(2);
}
Job job = Job.getInstance(conf,"WordCount");
job.setJarByClass(WordCount.class);
job.setMapperClass(WordCount.TokenizerMapper.class);
job.setCombinerClass(WordCount.IntSumReducer.class);
job.setReducerClass(WordCount.IntSumReducer.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
FileInputFormat.addInputPath(job, new Path(args[0]));
FileOutputFormat.setOutputPath(job, new Path(args[1]));
System.exit(job.waitForCompletion(true) ? 0 : 1);
}
}
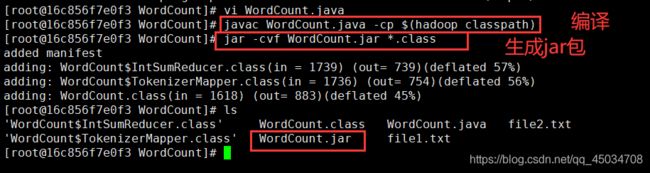
- 编译打包
javac WordCount.java -cp $(hadoop classpath)
jar -cvf WordCount.jar *.class
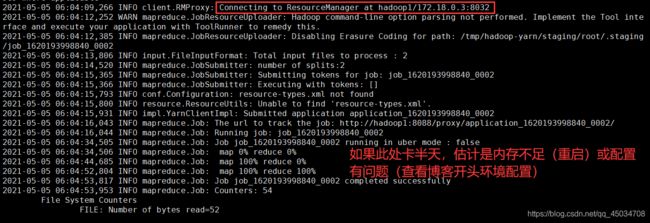
输出
#hadoop jar jar包位置 主类名 参数1(输入路径) 参数2(输出路径)
hadoop jar /usr/file/WordCount/WordCount.jar WordCount WordCount/input WordCount/output
#查看输出
hadoop fs -cat WordCount/output/*

合并
对输入文件进行合并,剔除其中重复的内容。
如输入:
file1.txt
20150101 x
20150102 y
20150103 x
20150104 y
20150105 z
20150106 x
file2.txt
20150101 y
20150102 y
20150103 x
20150104 z
20150105 y
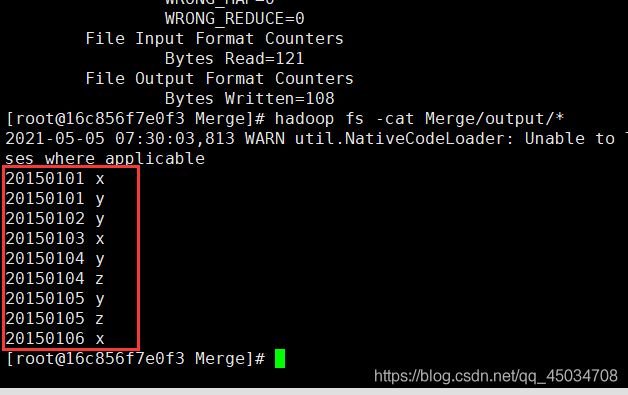
输出:
20150101 x
20150101 y
20150102 y
20150103 x
20150104 y
20150104 z
20150105 y
20150105 z
20150106 x
输入
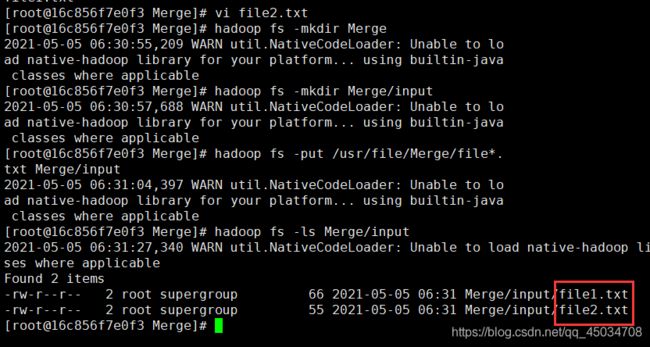
cd /usr/file #没有则新建一个目录
mkdir Merge
cd Merge
vi file1.txt#内容就是上面的file1.txt
vi file2.txt
hadoop fs -mkdir Merge
hadoop fs -mkdir Merge/input
hadoop fs -put /usr/file/Merge/file*.txt Merge/input
hadoop fs -ls Merge/input
(
插播反爬信息)博主CSDN地址:https://wzlodq.blog.csdn.net/
源码
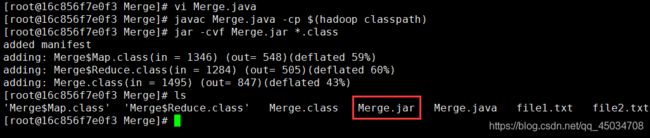
vi Merge.java
javac Merge.java -cp $(hadoop classpath)
jar -cvf Merge.jar *.class
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import java.io.IOException;
public class Merge {
public static class Map extends Mapper<Object, Text, Text, Text> {
private static Text text = new Text();
public void map(Object key, Text value, Context content) throws IOException, InterruptedException {
text = value;
content.write(text, new Text(""));
}
}
public static class Reduce extends Reducer<Text, Text, Text, Text> {
public void reduce(Text key, Iterable<Text> values, Context context) throws IOException, InterruptedException {
context.write(key, new Text(""));
}
}
public static void main(String[] args) throws Exception {
Configuration conf = new Configuration();
if (args.length != 2) {
System.err.println("usage: Merge " );
System.exit(2);
}
Job job = Job.getInstance(conf,"Merge");
job.setJarByClass(Merge.class);
job.setMapperClass(Merge.Map.class);
job.setReducerClass(Merge.Reduce.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(Text.class);
FileInputFormat.addInputPath(job, new Path(args[0]));
FileOutputFormat.setOutputPath(job, new Path(args[1]));
System.exit(job.waitForCompletion(true) ? 0 : 1);
}
}
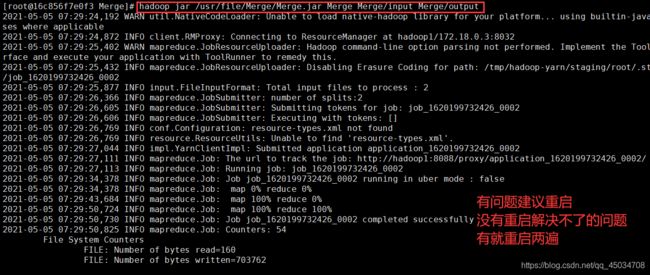
输出
hadoop jar /usr/file/Merge/Merge.jar Merge Merge/input Merge/output
hadoop fs -cat Merge/output/*
排序
读取所有输入文件中的整数,进行升序排序后,输出到一个新文件。
输入:
file1.txt
33
37
12
40
file2.txt
4
16
39
5
file3.txt
1
45
25
输出:
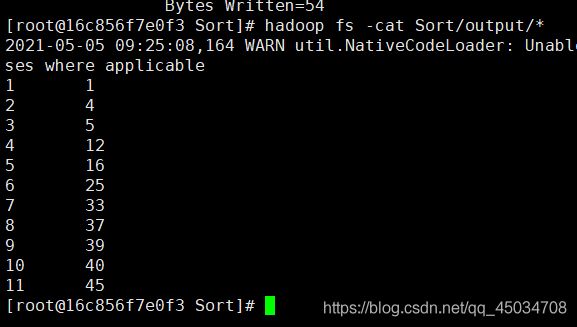
输出的数据格式为每行两个整数,第一个整数位第二个整数的排序为此,第二个整数为原待排列的整数。
1 1
2 4
3 5
4 12
5 16
6 25
7 33
8 37
9 39
10 40
11 45
输入
cd /usr/file #没有则新建一个目录
mkdir Sort
cd Sort
vi file1.txt#内容就是上面的file1.txt
vi file2.txt
vi file3.txt
hadoop fs -mkdir Sort
hadoop fs -mkdir Sort/input
hadoop fs -put /usr/file/Sort/file*.txt Sort/input
hadoop fs -ls Sort/input

源码
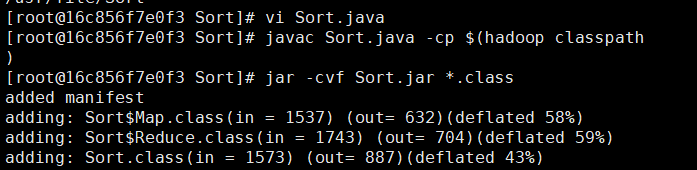
vi Sort.java
javac Sort.java -cp $(hadoop classpath)
jar -cvf Sort.jar *.class
import java.io.IOException;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
public class Sort {
public static class Map extends Mapper<Object,Text,IntWritable,IntWritable>{
private static IntWritable data=new IntWritable();
public void map(Object key,Text value,Context context) throws IOException, InterruptedException{
String line=value.toString();
data.set(Integer.parseInt(line));
context.write(data, new IntWritable(1));
}
}
public static class Reduce extends Reducer<IntWritable,IntWritable,IntWritable,IntWritable>{
private static IntWritable linenum=new IntWritable(1);
public void reduce(IntWritable key,Iterable <IntWritable>values,Context context) throws IOException, InterruptedException{
for(IntWritable num:values){
context.write(linenum, key);
linenum=new IntWritable(linenum.get()+1);
}
}
}
public static void main(String[] args) throws IOException, ClassNotFoundException, InterruptedException{
Configuration conf=new Configuration();
if(args.length!=2){
System.err.println("Usage:Sort " );
System.exit(2);
}
Job job=Job.getInstance(conf,"Sort");
job.setJarByClass(Sort.class);
job.setMapperClass(Sort.Map.class);
job.setReducerClass(Sort.Reduce.class);
job.setOutputKeyClass(IntWritable.class);
job.setOutputValueClass(IntWritable.class);
FileInputFormat.addInputPath(job,new Path(args[0]));
FileOutputFormat.setOutputPath(job,new Path(args[1]));
System.exit(job.waitForCompletion(true)?0:1);
}
}
输出
hadoop jar /usr/file/Sort/Sort.jar Sort Sort/input Sort/output
hadoop fs -cat Sort/output/*
原创不易,请勿转载(
本不富裕的访问量雪上加霜)
博主首页:https://wzlodq.blog.csdn.net/
如果文章对你有帮助,记得一键三连❤