一.明确爬取需求
今天要爬的是cnvd,网站叫国家信息安全漏洞共享平台,我们要爬的页面是漏洞列表页面,我们看图说话。

微信截图_20180916225155.png
大致分析一下爬取步骤:
1.爬取 漏洞列表首页,获取总页数,今天更新到5647页了。
2。循环遍历漏洞列表的每一页,获取详细的漏洞内容,点开一个看看里边都有啥?

微信截图_20180917222956.png
门前大桥下,游过一群鸭,你猜多少只?来数数啊。漏洞标题,CNVD_ID,公开日期,危害级别,影响产品,漏洞描述,参考链接,漏洞解决方案,厂商补丁。大概就是这些了,话不多说,咱开干呗!
二.干活了
用requests简单写了个初级crawler,循环获取漏洞列表中的每一页,但是只获取了8页就gg了,Are you kidding me?政府网站竟然也加了反爬,让我来研究研究 。
网页拉到最底下,发现网站服务由知道创宇公司的加速乐产品提供。百度加速乐,发现其对一些政府网站做了反爬优化,不过对cnvd没做的太过分。那就加个cookies池吧,F12查看cookie,发现有三组cookie,用selenium获取cookie,存为json文件。
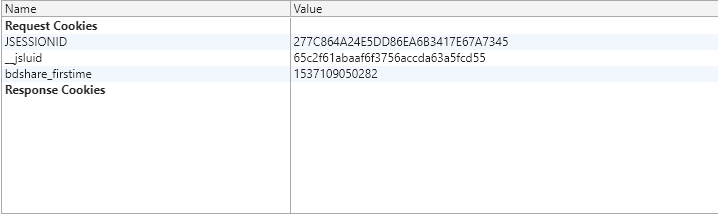
微信截图_20180917225603.png
新建get_cnvd_cookie.py,直接贴代码,这个挺简单,大家自己看啊!
# _*_ coding: utf-8 _*_
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
from selenium.webdriver.chrome.options import Options
import json
import time
if __name__ == '__main__':
list = []
for i in range(500):
chrome_options = Options()
chrome_options.add_argument('--headless')
driver = webdriver.Chrome(chrome_options=chrome_options)
driver.get('http://www.cnvd.org.cn/flaw/show/CNVD-2018-17745')
ck = driver.get_cookies()
name = []
value = []
for c in ck:
name.append(c['name'])
value.append(c['value'])
dd = dict(zip(name, value))
with open('cnvd_cookies.json', 'a+', encoding='utf-8') as file:
line = json.dumps(dd, ensure_ascii=False) + '\n'
file.write(line)
driver.close()
time.sleep(0.1)
有点犯懒了,手动将生成的内容改为cnvd_pool列表,也就是CNVD_POOL = []中加入刚才生成的cookies。
下边开始上主代码,时间不早了,先更一波,明天再做解读。
# -*- coding: utf-8 -*-
"""
cnvd crawler
"""
import re
import time
import random
import json
import requests
from bs4 import BeautifulSoup
from settings import CNVD_POOL
class CnvdSpider:
def __init__(self):
headers = {
'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8',
'Accept-Encoding': 'gzip, deflate',
'Accept-Language': 'zh-CN,zh;q=0.9',
'Host': 'www.cnvd.org.cn',
'Proxy-Connection': 'keep-alive',
'Referer': 'http://www.cnvd.org.cn/flaw/list.htm?flag=true',
'Upgrade-Insecure-Requests': '1',
'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) '
'Chrome/68.0.3440.106 Safari/537.36',
}
self.start_url = 'http://www.cnvd.org.cn/flaw/list.htm?flag=true'
self.session = requests.session()
self.session.headers.update(headers)
self.update_session()
with open('vulnerabilitys.json', 'w+', encoding='utf-8') as file:
pass
self.start_time = time.time()
def update_session(self):
req_msg = random.choice(CNVD_POOL)
print('cookies: ', req_msg)
# 传入cookieJar
requests.utils.add_dict_to_cookiejar(self.session.cookies, req_msg)
def crawl_list_page(self):
data = {'max': 100, 'offset': 0}
response = self.session.post(self.start_url, data=data)
response.encoding = 'utf-8'
# print(response.text)
soup = BeautifulSoup(response.text, 'lxml')
# get_text() 必须加括号
last_page = soup.select_one('.pages > a:nth-of-type(10)').get_text()
for page in range(int(last_page)):
data['offset'] = page * 100
while True:
try:
resp = self.session.post(self.start_url, data=data)
except:
self.update_session()
continue
if resp.text != '':
break
else:
# time.sleep(1)
self.update_session()
with open('logs.txt', 'a', encoding='utf-8') as file:
file.writelines('页码:-------------------->max={}&offset={}\n'.format(data['max'], data['offset']))
self.crawl_detailed_page(resp)
break
def crawl_detailed_page(self, response):
print('crawl_detailed_page: {}'.format(response.url))
response.encoding = 'utf-8'
soup = BeautifulSoup(response.text, 'lxml')
detailed_pages = soup.select('.tlist tbody > tr > td:nth-of-type(1) > a')
left_url = 'http://www.cnvd.org.cn'
for page in detailed_pages:
while True:
try:
resp = self.session.get(left_url + page.attrs['href'])
except:
self.update_session()
continue
if resp.text != '':
break
else:
# time.sleep(1)
self.update_session()
self.get_detailed_info(resp, page.attrs['title'])
def get_detailed_info(self, response, title):
take_time = int((time.time() - self.start_time) / 60)
print('time:{}min. get_detailed_info: {}'.format(take_time, response.url))
left_url = 'http://www.cnvd.org.cn'
detailed_dict = {
"number": None, "title": title, "openTime": None, "serverity": None, "products": None,
"cve": None, "description": None, "referenceLink": None, "formalWay": None,
"patch": None,}
response.encoding = 'utf-8'
soup = BeautifulSoup(response.text, 'lxml')
trs = soup.select('.gg_detail tbody tr')
for tr in trs:
name = tr.find('td').get_text()
if name == 'CNVD-ID':
value = tr.select_one('td:nth-of-type(2)').get_text().strip()
detailed_dict['number'] = value
elif name == '公开日期':
value = tr.select_one('td:nth-of-type(2)').get_text().strip()
detailed_dict['openTime'] = value
elif name == '危害级别':
value = tr.select_one('td:nth-of-type(2)').get_text().strip()
detailed_dict['serverity'] = value[:1]
elif name == '影响产品':
value = tr.select_one('td:nth-of-type(2)').get_text()
pattern=re.compile('(\S.*?)\s\s', re.S)
value_dict = re.findall(pattern, value+' ')
detailed_dict['products'] = value_dict
elif name == 'CVE ID':
value = tr.select_one('td:nth-of-type(2)').get_text().strip()
cve_href = tr.select_one('td:nth-of-type(2) a').attrs['href']
detailed_dict['cve'] = value
cve_dict = {'id': value, 'href': cve_href}
detailed_dict['cve'] = cve_dict
elif name == '漏洞描述':
value = tr.select_one('td:nth-of-type(2)').get_text()\
.replace('\r\n', '').replace('\t', '').strip()
detailed_dict['description'] = value
elif name == '参考链接':
try:
value = tr.select_one('td:nth-of-type(2) a').get_text().strip()
detailed_dict['referenceLink'] = value
except AttributeError:
pass
elif name == '漏洞解决方案':
value = tr.select_one('td:nth-of-type(2)').get_text().strip()
pattern = re.compile('\t(http.*)', re.S)
value = re.findall(pattern, value)
detailed_dict['formalWay'] = value
elif name == '厂商补丁':
try:
href = tr.select_one('td:nth-of-type(2) a').attrs['href']
value = tr.select_one('td:nth-of-type(2)').get_text().strip()
patch_dict = {'patchName': value, 'href': left_url+href}
detailed_dict['patch'] = patch_dict
except AttributeError:
pass
# 写入json文件
with open('vulnerabilitys.json', 'a', encoding='utf-8') as file:
line = json.dumps(detailed_dict, ensure_ascii=False) + '\n'
file.write(line)
with open('logs.txt', 'a', encoding='utf-8') as file:
file.writelines('漏洞详细信息url----->{}\n'.format(response.url))
if __name__ == '__main__':
a = CnvdSpider()
a.crawl_list_page()