一. SQL简单介绍
(1)类似linux中的shell,统一标准,能够应用于各种数据库
(2)SQL标准:SQL-92或SQL-99
(3)SQL验证:SQL_MODE约束
二. SQL常用分类
(1)DDL:数据定义语言
(2)DCL: 数据控制语言
(3)DML: 数据操作语言
(4)DQL: 数据查询语言
三. 数据类型(表的核心属性,字符集)
作用:保证数据的准确性和标准性
3.1 种类
3.1.1 数值类型
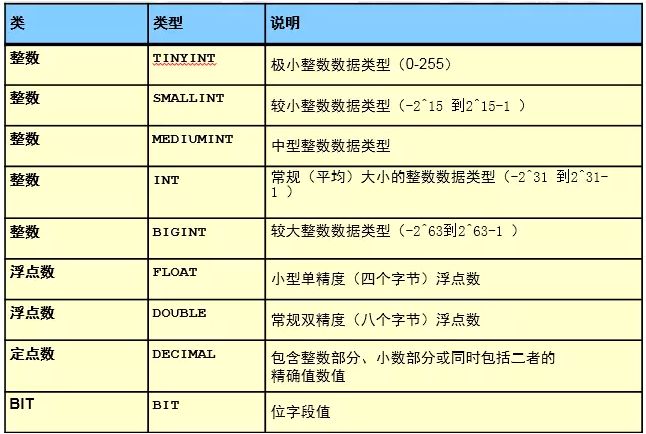

3.1.2 字符类型
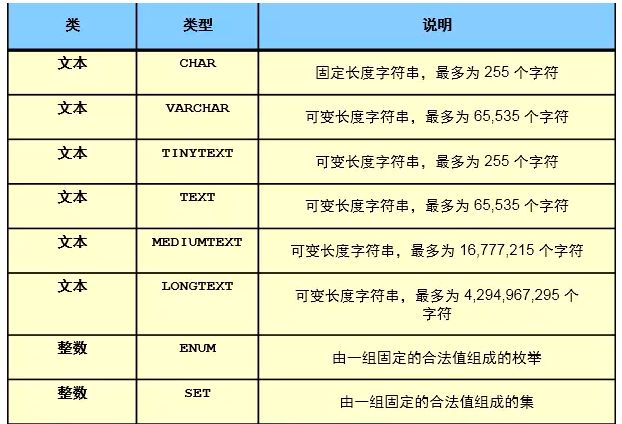

char(10)与varchar(10)的区别(括号内的数字是自己规定限制的字符长度):
char(10)类型:是定长类型,不管存储什么长度的数据,都立即分配你所指定的固定字符串长度的存储空间,若数据小于你所指定的,无法沾满则用空来填充
varchar(10)类型:可变长度类型,按需分配存储空间,在你指定的长度的字符串存储空间中只要不超过你所指定的长度,需要多少就分配多少(但每次都要计算所需要字符串长度的存储空间)在varchar类型中,除了存储字符串本身外,还会存储字符长度,对于<=255个字符的会额外占用1个字节存储长度;>255个字符的会额外占用2个字节长度存储字符长度
注意:对于char(10)与varchar(10)的数据类型,括号中表示的是最多的字符个数
基础字符:a(字母)----1字节 1(数字)----1字节 {(符号)----1字节
中文:张---gbk字符集---2字节 张---utf8---3字节 张---utf8mb4---4字节
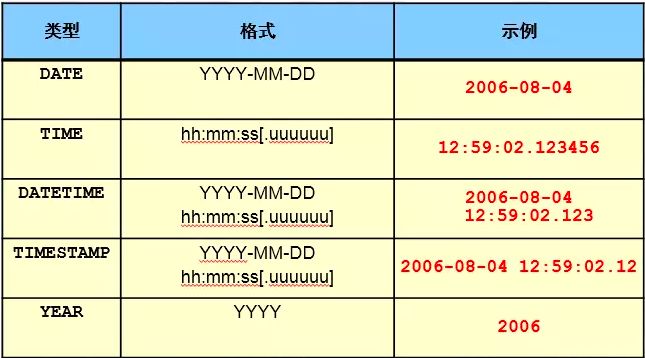
3.1.3 时间类型

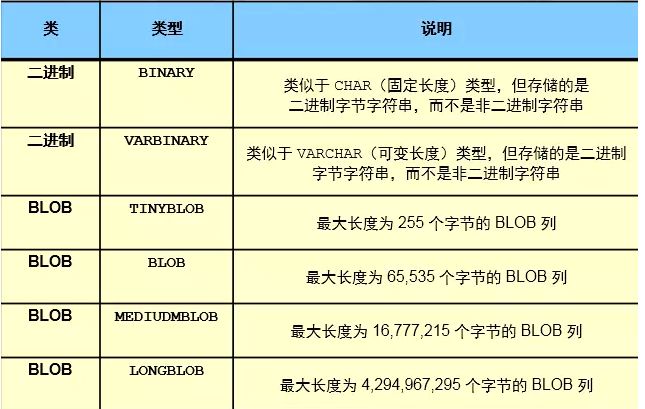
3.1.4 二进制类型
一般不使用,neo4j:图片,视频的存储应用
3.1.5 枚举类型
enum(‘bj’,‘sh’,‘tj’,...)
对应着编号1,2,3,...
四. 表与列的属性
4.1 列属性
约束作用(一般建表时添加)
(1)not null:非空约束
- 列值不能为空,也是表设计的规范,尽可能将所有的列设置为非空。若无法保证,可以设置默认值,可以设置默认值为0。
(2)unique key:唯一键
- 列值不能重复,手机号,身份证号,银行卡号种类的列设定为UK
(3)primary key:主键约束
- 设置为主键的列,此列的值必须非空且唯一,主键在一个表中只能有一个,但是可以有多个列一起构成,一般会在表中设置自增长的id列。
(4)unsigned:无符号
- 针对数字列,非负数。一般是在int或tinyint后添加的附加属性
其他属性
(1)key:属性
- 可以在某列上建立索引,来优化查询,一般是根据需要后添加
(2)default:默认值
- 列中,没有录入值时,会自动使用default的值填充
(3)auto_increment:自增长
- 针对数字列,顺序的自动填充数据(默认是从1开始,将来可以设定起始点和偏移量)
(4)comment:注释信息
4.2 表属性
存储引擎:
InnoDB(默认的)
字符集和排序规则:
utf8
utf8mb4
五. 字符集及校对规则
5.1 字符集(charset)
- show charset;(mysql中的查看方式)
gbk:中文字符占2个字节
utf8(mb3):中文字符占3个字节
utf8mb4:中文字符占4个字节
- create database xs charset utf8mb4;
- create table t1 ()charset utf8mb4;
5.2 校对/排序规则(collation)
5.2.1 举例
- 举例数据:Asd, ads, ass, bca, cda, Cdd
- 不区分大小写:ads, Asd, ass, bca, cda, Cdd
- 区分大小写:Asd, Cdd, ads, ass, bca, cda
5.2.2 utf8mb4字符集
- show collaction(在mysql中查看方式)
(1)utf8mb4_general_ci: 通过校对默认值,不区分大小写
(2)utf8mb4_bin:区分大小写
六. DDL数据定义语言
6.1 库的定义
6.1.1 标准建库语句
- mysql> create database db charset utf8mb4;(创建)
- mysql> show create database xuexiao;(查看)
6.1.2 创建数据库方式
- create database school;
- create schema sch;
- show charset;
- show collation;
- CREATE DATABASE test CHARSET utf8;
- create database xyz charset utf8mb4 collate utf8mb4_bin;
6.1.3 建库规范
1.库名不能有大写字母
2.建库要加字符集
3.库名不能有数字开头
- 库名要和业务相关
6.1.4 删除库
- drop database oldboy;(生产中禁用)
6.1.5 修改库(一般就是修改字符集)
- SHOW CREATE DATABASE school;
- ALTER DATABASE school CHARSET utf8;
6.1.6 查询库
- show databases;
- show create database oldboy;
6.2 表的定义
6.2.1 创建表
模板
create table stu(
列1 属性(数据类型、约束、其他属性) ,
列2 属性,
列3 属性
)
实例
USE school;
CREATE TABLE stu(
id INT NOT NULL PRIMARY KEY AUTO_INCREMENT COMMENT '学号',
sname VARCHAR(255) NOT NULL COMMENT '姓名',
sage TINYINT UNSIGNED NOT NULL DEFAULT 0 COMMENT '年龄',
sgender ENUM('m','f','n') NOT NULL DEFAULT 'n' COMMENT '性别' ,
sfz CHAR(18) NOT NULL UNIQUE COMMENT '身份证',
intime TIMESTAMP NOT NULL DEFAULT NOW() COMMENT '入学时间'
) ENGINE=INNODB CHARSET=utf8 COMMENT '学生表';
建表规范
- 表名小写
- 不能是数字开头
- 注意字符集和存储引擎
- 表名和业务有关
- 选择合适的数据类型
- 每个列都要有注释
- 每个列设置为非空,无法保证非空,用0来填充。
- 必须有主键,一般是一个自增长的无关列。
6.2.2 删除表
- drop table xuesheng;(直接把整个表删除包括表定义(表中的列)和数据)
- truncate table xuesheng;(保留表结构(表定义),清空表的区和数据)
6.2.3 修改表(添加删除列)
添加列
(1)在xs表中添加手机号列“shouji”
- ALTER TABLE xs ADD shouji CHAR(11) NOT NULL UNIQUE KEY COMMENT '手机号';
(2)在xs表中,sex列后添加列“微信”
- ALTER TABLE xs ADD 微信 VARCHAR(64) NOT NULL UNIQUE KEY COMMENT '微信号' AFTER sex;
(3)在xs表中的第一列位置添加列“qq号”
- ALTER TABLE xs ADD qq VARCHAR(64) NOT NULL UNIQUE KEY COMMENT 'qq号' first;
删除列
ALTER TABLE stu DROP num;
ALTER TABLE stu DROP qq;
ALTER TABLE stu DROP wechat;
修改列属性
(1)只改属性不改列名
- ALTER TABLE xs MODIFY ssname VARCHAR(64) NOT NULL COMMENT '姓名';
(2)列名与属性都改
- ALTER TABLE xs CHANGE sname ssname VARCHAR(32) NOT NULL COMMENT '姓名';
6.2.4 查询列(属性)
use school
show tables;
desc stu;
show create table stu;
CREATE TABLE ceshi LIKE stu;
七. 数据控制语言
7.1 赋予权限
- grant all on wordpress.* to wordpress@'10.0.0.%' identified by '123';
(grant+权限+on+对象范围+to +用户@网段 +identified by '密码';)
7.2 收回权限
- revoke delete on wordpress.* from dev@'10.0.0.%';
(revoke +权限+on+对象范围+from+用户@网段)
7.3 权限查询
- show grants for dev@'10.0.0.%';
(show+grants+for+用户@网段)
八. DML数据操作语言
DML语句用作表中数据行的增删改查
8.1 insert(录入数据)
--- 最标准的insert语句
INSERT INTO stu(id,sname,sage,sg,sfz,intime)
VALUES
(1,'zs',18,'m','123456',NOW());
SELECT * FROM stu;
--- 省事的写法
INSERT INTO stu
VALUES
(2,'ls',18,'m','1234567',NOW());
--- 针对性的录入数据
INSERT INTO stu(sname,sfz)
VALUES ('w5','34445788');
--- 同时录入多行数据
INSERT INTO stu(sname,sfz)
VALUES
('w55','3444578d8'),
('m6','1212313'),
('aa','123213123123');
SELECT * FROM stu;
8.2 update(修改数据)
DESC stu;
SELECT * FROM stu;
UPDATE stu SET sname='zhao4' WHERE id=2;
(修改stu表中的sname数据行为zhao4)
注意:update语句必须要加where,不然整个数据列都会被改动。
8.3 delete(删除数据)
- DELETE FROM stu WHERE id=3;
(也必须由where指定具体修改什么,危险操作)
8.4 全表删除(delete与truncate的区别)
全表删除命令
- DELETE FROM stu
- truncate table stu;
区别 - delete: DML操作, 清空整表的所有数据,是逻辑性质删除,逐行进行删除,速度慢.并且表所占用的空间不会立即释放。
- truncate: DDL操作,清空整表的所有数据,按区删除,属于物理删除,对与表段中的数据页进行清空,速度快.并且表所占用空间会被立即释放。
8.5 使用update代替delete实现伪删除
(1)在xs表中添加一个状态列state
- ALTER TABLE xs ADD state TINYINT NOT NULL DEFAULT 1 ;
- SELECT * FROM stu;(查看)
(2)用UPDATE 替代 DELETE - 原语句:delete from xs where id=6;
- 改写后:update xs set state=0 where id=6;
(3)业务语句查询调整 - 原语句:select * from xs;
- 改写后:SELECT * FROM xs WHERE state=1;
九. DQL数据查询语言
9.1 select 子句应用(单表)
9.1.1 select 子句执行逻辑
- select 列1 from 表 where 条件 group by 条件 having 条件 order by 条件 limit 条件(顺序不可乱)
9.1.2 select单独使用(mysql独家)
-- select @@xxx 查看系统参数
1. SELECT @@port; #显示连接端口
2. SELECT @@basedir; #显示软件安装目录
3. SELECT @@datadir; #显示数据存放目录
4. SELECT @@socket; #显示socket文件
5. SELECT @@server_id; #显示服务id
6. SELECT @@innodb_flush_log_at_trx_commit; #显示innodb_log_buffer向innodb_log_file的刷写策略
7. SHOW VARIABLES LIKE '%trx%' #模糊查询参数方式
9.1.3 select +函数()
1. select now(); #显示当前时间
2. select database(); #显示当前处于哪个库
3. select user(); #显示哪个用户登录数据库
4. select 16*16; #用于计算(显示计算结果)
5. select concat("hello world") #显示出括号内容
6. select concat(user,"@",host) from mysql.user; #显示出mysql.user中调出的用户与主机名(用@连接起来,语句拼接)
7. select group_concat(user,"@",host) from mysql.user; #与上诉显示结果一样,只不过是一行显示(列转行)
9.2 from子句应用(单表)
use world; #进入world库中
show tables; #显示库中的所有表
desc city; #以表结构形式显示city表的所有数据
select * from city; #查看city中所有数据(相当于cat文件)
select name,countrycode from city; #从city表中调取国家代码与名称信息(相当于awk文件)
9.3 where子句应用
9.3.1 等值查询
- select * from city where countrycode='CHN';(查询中国城市信息)
9.3.2 不等值查询
- select * from city where population<100;(查询人口是小于100人的城市)
- select * from city where id<10;(查询id小于10的城市信息)
- select * from city where countrycode !='CHN';(查询不是中国城市的信息)
9.3.3 模糊查询
- select * from city where countrycode like 'CH%';(查询国家代号是CH打头的城市信息,尽量避免like前带%的模糊查询)
9.3.4 逻辑连接符(and)
- select * from city where countrycode='CHN' and population>5000000;(查询中国人口超过500万的城市)
- select * from city where population>5000000 and population<6000000;
(查询人口数在500万到600万之间的城市)
9.3.5 逻辑连接符(or)
- select * from city where district='shandong' or district='hebei';(查询山东省或河北省的信息)
9.3.6 where配合between and使用
- select * from city where population between 5000000 and 6000000;(查询人口数在500万到600万之间的城市)
9.3.7 where配合in的使用
- select * from city where district in('shandong','hebei');(查询山东省或河北省的信息)
9.4 group by分组几句+聚合函数的应用
9.4.1 什么是分组
以查询的某个项进行合理分组,以便更直观的显示
9.4.2 常用的聚合函数
COUNT()---用于计数
MAX()---最大值
MIN()---最小值
AVG()---平均数
SUM()---求和
GROUP_CONCAT()---列转行
9.4.3 应用举例
- select countrycode,COUNT(id) from city GROUP BY countrycode;(统计每个国家的城市个数)
- select countrycode,SUM(population) from city GROUP BY countrycode;(统计每个国家的总人口数)
- select district,COUNT(NAME),SUM(population) from city where countrycode='CHN' GROUP BY district;(统计中国各个城市的个数及人口数)
- select countrycode,GROUP_CONCAT(NAME) from city GROUP BY countrycode;(统计各个国家的城市名列表)
9.5 having子句应用(一般在group by筛选过后再筛选一遍)打印
- select district,COUNT(NAME),SUM(population) from city where countrycode='CHN' GROUP BY district HAVING SUM(population)>8000000;(统计中国每个省的城市个数,省总人口数,只显示人口数大于800万的省)
9.6 order by子句应用(默认增序输出)
- select district,COUNT(NAME),SUM(population) from city where countrycode='CHN' GROUP BY district HAVING SUM(population)>8000000 ORDER BY SUM(population) DESC;(统计中国各个省的城市个数,省总人口数,只显示人口数大于800万的省,降序输出)
- select * from city where countrycode='CHN' order by population DESC;(查询中国所有城市信息,并以人口降序输出)
9.7 limit子句应用(显示前几行或跳过前几行再显示后几行,应用于order by之后)
9.7.1 格式显示
LIMIT 10 OFFSET 0=LIMIT 10(显示前10行)
LIMIT 5 OFFSET 5=LIMIT 5,5(跳过前5行,再显示后5行)
9.7.2 例子
- select * from city where countrycode='CHN' order by population DESC limit 10 offset 0;(查询中国所有城市信息,并以人口降序输出,只显示前10行)
9.8 distinct子句应用(去重复)
- select DISTINCT countrycode from city;(查询所有国家的代号信息,有的代号一样,这里就去重复了)
9.9 union与union all子句应用(联合查询)
9.9.1 举例
---查看山东省或河北省信息
(原语句):
- select * from city where district='shandong' or district='hebei';
(union all优化):
- select * from city where district='shandong' union all select * from city where district='hebei';
---查看中国或美国的所有信息
(原语句):
- select * from city where countrycode in('CHN','USA');
(union all优化):
- select * from city where countrycode='CHN' union all select * from city where countrycode='USA';
9.9.2 说明
一般情况下,我们会将in或or的语句改写为union all语句来提高性能(并不是所有语句越复杂性能越差,这就是个实例)
9.9.3 union与union all的区别
union带有去重复的功能(隐含了排序功能,更耗费资源);而union all则没有去重复功能
十. 多表连接查询
10.1 多表连接作用
业务需要的数据来自多张表,则需要各张表的关联项来进行选取所需
10.2 多表连接类型
- 内连接(重要)
- 外连接(一般)
- 全连接(普通)
- 笛卡尔(普通)
10.3 多表连接基本语法(内连接类型)
- 传统连接(普通)
- 自连接(普通)
- join uing(普通)
- join on (重要)
10.4 join on语法过程(内连接)
两表
select ---(显示内容,看题意)
from 第一表
join 第二表
on 第一表的内容=第二表的内容(两表的关联列)
where 条件
group by 条件
having 条件
order by 条件
limit 条件
多表
select (显示内容看要求)
from 第一表
join 第二表
on 第一表内容=第二表内容(第一第二表的关联列)
join 第三表
on 第二表的内容=第三表的内容(第二第三表的关联列)
join ----
on ----
where 条件
group by 条件
having 条件
order by 条件
limit 条件
10.5 多表连接查询套路
- 根据要求找到关联列
- 找到表与表的关联列
- 列名调用时,需要添加关联列,例如:a.id b.name
10.6 给与如下关联,进行后续多表连接案例
1. course(课程表)与sc(成绩表)关联列为cno(课程编号)
2. course(课程表)与teacher(教师表)关联列为tno(教师编号)
3. sc(成绩表)与student(学生表)关联列为sno(学生编号)
10.7 多表连接查询案例
(1)查询张三学习了几门课程
---分析:
1. 由题意看出需要的是学生表与课程表
2. 但学生表与课程表并没有关联列,而成绩表与课程表有关联列,所以需要成绩表进行过渡(三标连接)
3. 再分析题意,需要的是学生学习了几门课程,而课程同样在成绩表中也能显示,同时成绩表与学生表是有关联列的,所以直接应用学生表与成绩表两表关联即可
---答题:
select student.sname,COUNT(sc.cno) from student join sc on student.sno=sc.sno where student.sname='zhang3';
(2)统计oldguo老师教的学生个数
select teacher.tname,COUNT(student.sno)
from teacher
join course
on teacher.tno=course.tno
join sc
on course.cno=sc.cno
join student
on sc.sno=student.sno
where teacher.tname='oldguo';
(3)统计每位老师所教的课程的平均分,并按平均分排序
select teacher.tname,AVG(sc.score)
from teacher
join course
on teacher.tno=course.tno
join sc
on course.cno=sc.cno
group by teacher.tno,teacher.tname
order by AVG(sc.score);
(4)统计zhang3学习的课程名称
select student.sname,GROUP_CONCAT(course.cname)
from student
join sc
on student.sno=sc.sno
join course
on sc.cno=course.cno
where student.sname='zhang3';
(5)查询oldguo所教不及格的学生
select teacher.tname,GROUP_CONCAT(student.sname)
from teacher
join course
on teacher.tno=course.tno
join sc
on course.cno=sc.cno
join student
on sc.sno=student.sno
where teacher.tname='oldguo' and sc.score<60;
(6)查询所有老师所教的学生不及格的信息
select teacher.tname,GROUP_CONCAT(student.sname)
from teacher
join course
on teacher.tno=course.tno
join sc
on course.cno=sc.cno
join student
on sc.sno=student.sno
where sc.scroe<60
GROUP BY teacher.tname;
10.8 别名(表别名,列别名)
表别名
(1)表别名举例(查询所有老师所教学生不及格的信息)
select a.tname,GROUP_CONCAT(d.sname)
from teacher AS a
join course AS b
on a.tno=b.tno
join sc AS c
on b.cno=c.cno
join student AS d
on c.sno=d.sno
where c.score<60
GROUP BY a.tname;
(2)表别名说明
1. AS可以省略,直接加别名即可,但是为了区分最好加上
2. 表别名一般是在from后的表或join后的表定义的别名
3. 表别名定义后在select,where,group by,having以及order by后都可以应用
列别名
(1)列别名举例(统计每位老师所教课程的平均分,并按平均分排序)
select a.tname AS 讲师,AVG(c.score) AS 平均分
from teacher as a
join course as b
on a.tno=b.tno
join sc as c
on b.cno=c.cno
GROUP BY a.tno
ORDER BY 平均分;
(2)列别名说明
1. 列别名一般是在select后定义的别名
2. 结果集显示会以别名的形式展示
3. 在having与order by字句中应用
十一. 外连接简介
11.1 A left join B(左外连接)
应用方式:
...
A left join B
on A表中的所有条件列=B表中符合两表的关联条件的列(A.xx=B.yy)
and 条件(进行过滤所需,外连接没有where等字句赛选条件,只有and来代替)
11.2 A right join B(右外连接)
应用方式:
...
A right join B
on A表中符合两表的关联条件的列=B表中所有条件列(A.xx=B.yy)
and 条件
11.3 结论
- 多表连接中,小表驱动大表
- 通过left/right join强制选定驱动表
十二. 元数据获取
12.1 元数据包含内容
基表---数据字典信息(列结构frm),系统状态信息,对象状态信息,不能直接操作,只能用专门的管理命令进行修改(DDL语句,DCL语句等),视图information_schema与show语句查询。基表就相当于linux中的inode,存放各种属性信息。
12.2 获取方式
1. show database; #查看数据库中所有库的信息
2. show tables; #查看库下所有表
3. show tables from ...; #查询某个指定库下的所有表
4. show create database world; #查看world库的建库语句
5. show create table world.city; #查看world库下city表的建表语句
6. show grants for root@'localhost'; #查看用户权限信息
7. show charset; #查看字符集
8. show collation; #查看校对规则
9. show processlist; #查看数据库连接情况
10. show index from ... #查看某个表的索引情况
11. show status; #查看数据库状态信息
12. show status like '%lock%' #模糊查看数据库某些状态信息
13. show variables; #查看数据库所有配置信息
14. show variables like '%lock%' #模糊查找数据库默写配置信息
15. show engines; #查看数据库支持的所有的存储引擎
16. show engines innodb status \G; #查看关于innodb引擎所有状态信息
17. show binary logs; #列举出所有二进制日志
18. show master status; #查看数据路的日志位置信息
19. show binlog events in ... ; #查看二进制日志事件
20. show slave status \G; #查看数据库从库状态
21. show relaylog events; #查看从库relaylog事件信息
22. desc (show colums from city) #查看表的列定义信息
12.3 视图views:information_schema(虚拟库)查询
12.3.1 创建视图test
create view test as select
country.name as co_name,country.Surface Area,city.name as ci_name,city.Population
from city join country
on city.xountrycode=country.code
where city.population<100;
12.3.2 查看视图test
- select * from test;
12.3.3 tables视图的作用和结构
(1)tables视图作用
- 存储整个数据库的所有表的元数据查询方式
(2)tables下重要列
1. table_schema:表所在的库名
2. table_name:表名
3. engine:表的引擎
4. table_rows:表的行数
5. avg_row_length:表中行的平均行(字节)
6. index_length:索引的占用空间大小(字节)
12.3.4 tables视图查询举例
(1)查询world库下所有表名
- show tables from world;
(2)查询整个数据库中的所有库和对应表的信息
select table_schema,GROUP_CONCAT(table_name)
from information_schema.tables
GROUP BY table_schema;
(3)统计所有库下表的个数
select table_schema,COUNT(table_name)
from information_schema.tables
GROUP BY table_schema;
(4) 查询所有innodb引擎的表所在的库
select table_schema,table_name.ENGINE
from information_schema.tables
where ENGINE='innodb';
(5)统计每张表的实际占用空间大小情况
(AVG_ROW_LENGTH*TABLE_ROWS+INDEX_LENGTH)统计大小默认为字节,其中AVG_ROW_LENGTH与TABLE_ROWS可以互换位置
select table_name,AVG_ROW_LENGTH*TABLE_ROWS+INDEX_LENGTH
from information_schema.tables;
(6)统计world库下每张表的磁盘空间
select table_name,CONCAT((AVG_ROW_LENGTH*TABLE_ROWS+INDEX_LENGTH)/1024," KB") as size_KB
from information_schema.tables
where table_schema='world';
(7)统计每个库(所有库)的总的磁盘空间占用(数据库查询,如下命令是最准确的数据量级查询,与
linux中的“du -sh”的区别很大,linux中的查询结果还包含了很多日志之类的文件,并不是真正的数据量级)
select table_schema
CONCAT(SUM(AVG_ROW_LENGTH*TABLE_ROWS+INDEX_LENGTH)1024," KB") AS Total_KB
from information_schema.tables
GROUP BY table_schema;
linux命令行:
mysql -uroot -p123 -e "select table_schema CONCAT(SUM(AVG_ROW_LENGTH*TABLE_ROWS+INDEX_LENGTH)1024," KB") AS Total_KB from information_schema.tables GROUP BY table_schema;"
(8)对整个数据库下的所有表进行分库分表备份(生成单独备份语句)
模板语句:
mysqldump -uroot -p123 world city >/tmp/world_city.sql
分析:
实际上就是进行上述的一个批量的语句拼接过程(CONCAT)
答题:
select CONCAT("mysqldump -uroot -p123 ",table_schema," ",table_name," >/tmp",table_schema,"_",table_name,".sql")
from information_schema.tables
where table_schema NOT IN('information_schema','performance_schema','sys')
INTO OUTFILE '/tmp/bak.sh';
(9)进行模仿一下模板语句的批量操作
模板语句:
alter table world.city discard tablespace;
操作:
select CONCAT("alter table ",table_schema,".",table_name," discard tablespace")
from information_schema.tables
where table_schema='world'
INTO OUTFILE '/tmp/dis.sql';