Kafka的生产者与消费者
写了一个kafka的demo,kafka生产者和消费者,消费者用线程池创建多个消费者,并且创建的消费者大于或者等于小于partition个数,验证了kafka消费端负载的算法,算法见:http://blog.csdn.net/qq_20641565/article/details/59746101
创建一个maven工程,程序的结构如下:
pom文件
<project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0modelVersion>
<groupId>kafka-newgroupId>
<artifactId>kafka-newartifactId>
<version>0.0.1-SNAPSHOTversion>
<dependencies>
<dependency>
<groupId>org.apache.kafkagroupId>
<artifactId>kafka_2.11artifactId>
<version>0.10.1.1version>
dependency>
<dependency>
<groupId>org.apache.hadoopgroupId>
<artifactId>hadoop-commonartifactId>
<version>2.2.0version>
dependency>
<dependency>
<groupId>org.apache.hadoopgroupId>
<artifactId>hadoop-hdfsartifactId>
<version>2.2.0version>
dependency>
<dependency>
<groupId>org.apache.hadoopgroupId>
<artifactId>hadoop-clientartifactId>
<version>2.2.0version>
dependency>
<dependency>
<groupId>org.apache.hbasegroupId>
<artifactId>hbase-clientartifactId>
<version>1.0.3version>
dependency>
<dependency>
<groupId>org.apache.hbasegroupId>
<artifactId>hbase-serverartifactId>
<version>1.0.3version>
dependency>
<dependency>
<groupId>org.apache.hadoopgroupId>
<artifactId>hadoop-hdfsartifactId>
<version>2.2.0version>
dependency>
<dependency>
<groupId>jdk.toolsgroupId>
<artifactId>jdk.toolsartifactId>
<version>1.7version>
<scope>systemscope>
<systemPath>${JAVA_HOME}/lib/tools.jarsystemPath>
dependency>
<dependency>
<groupId>org.apache.httpcomponentsgroupId>
<artifactId>httpclientartifactId>
<version>4.3.6version>
dependency>
dependencies>
<build>
<plugins>
<plugin>
<groupId>org.apache.maven.pluginsgroupId>
<artifactId>maven-compiler-pluginartifactId>
<configuration>
<source>1.7source>
<target>1.7target>
configuration>
plugin>
plugins>
build>
project>MyProducer类
package com.lijie.kafka;
import java.util.Properties;
import java.util.UUID;
import org.apache.kafka.clients.producer.KafkaProducer;
import org.apache.kafka.clients.producer.ProducerRecord;
/**
*
* @author Lijie
*
*/
public class MyProducer {
public static void main(String[] args) throws Exception {
produce();
}
public static void produce() throws Exception {
//topic
String topic = "mytopic";
//配置
Properties properties = new Properties();
properties.put("bootstrap.servers", "192.168.80.123:9092");
//序列化类型
properties.put("value.serializer","org.apache.kafka.common.serialization.StringSerializer");
properties.put("key.serializer", "org.apache.kafka.common.serialization.StringSerializer");
//创建生产者
KafkaProducer pro = new KafkaProducer<>(properties);
while (true) {
//模拟message
String value = UUID.randomUUID().toString();
//封装message
ProducerRecord pr = new ProducerRecord(topic, value);
//发送消息
pro.send(pr);
//sleep
Thread.sleep(1000);
}
}
}
MyConsumer类
package com.lijie.kafka;
import java.util.HashMap;
import java.util.List;
import java.util.Map;
import java.util.Properties;
import java.util.concurrent.ExecutorService;
import java.util.concurrent.Executors;
import kafka.consumer.Consumer;
import kafka.consumer.ConsumerConfig;
import kafka.consumer.KafkaStream;
import kafka.javaapi.consumer.ConsumerConnector;
/**
*
* @author Lijie
*
*/
public class MyConsumer {
public static void main(String[] args) {
consumer();
}
public static void consumer() {
String topic = "mytopic";
//配置文件
Properties properties = new Properties();
properties.put("group.id", "lijieGroup");
properties.put("zookeeper.connect", "192.168.80.123:2181");
properties.put("auto.offset.reset", "largest");
properties.put("auto.commit.interval.ms", "1000");
// properties.put("value.serializer",
// "org.apache.kafka.common.serialization.StringSerializer");
// properties.put("key.serializer", "org.apache.kafka.common.serialization.StringSerializer");
//设置消费者的配置文件
ConsumerConfig config = new ConsumerConfig(properties);
//创建连接器
ConsumerConnector conn = Consumer.createJavaConsumerConnector(config);
//key为topic value为partition的个数
Map map = new HashMap();
//封装对应消息的的topic和partition个数
map.put(topic, 3);
//获取partition的流, key为对应的topic名字,value为每个partition的流,这里有三个partiiton所以list里面有三个流
Mapbyte[], byte[]>>> createMessageStreams = conn
.createMessageStreams(map);
//取出对应topic的流的list
Listbyte[], byte[]>> list = createMessageStreams.get(topic);
//用线程池创建3个对应的消费者
ExecutorService executor = Executors.newFixedThreadPool(3);
//执行消费
for (int i = 0; i < list.size(); i++) {
executor.execute(new ConsumerThread("消费者" + (i + 1), list.get(i)));
}
}
}
ConsumerThread类
package com.lijie.kafka;
import kafka.consumer.ConsumerIterator;
import kafka.consumer.KafkaStream;
import kafka.message.MessageAndMetadata;
/**
*
* @author Lijie
*
*/
public class ConsumerThread implements Runnable {
//当前消费者的名字
private String consumerName;
//当前消费者的流
private KafkaStream<byte[], byte[]> stream;
//构造函数
public ConsumerThread(String consumerName, KafkaStream<byte[], byte[]> stream) {
super();
this.consumerName = consumerName;
this.stream = stream;
}
@Override
public void run() {
//获取当前数据的迭代器
ConsumerIterator<byte[], byte[]> iterator = stream.iterator();
//消费数据
while (iterator.hasNext()) {
//取出消息
MessageAndMetadata<byte[], byte[]> next = iterator.next();
//获取topic名字
String topic = next.topic();
//获取partition编号
int partitionNum = next.partition();
//获取offset
long offset = next.offset();
//获取消息体
String message = new String(next.message());
//测试打印
System.out
.println("consumerName: "+ consumerName + "topic: " + topic + " ,partitionNum: "
+ partitionNum + " ,offset: " + offset + " ,message: " + message);
}
}
}
执行结果:

按照上面的结果可以发现,我创建的topic是mytopic,并且创建的3个partition,消费者1消费partition0,消费者2消费partition1,消费者3消费partition2,一个消费者对应一个partition
如果我把消费者改成4个,但是我的partition还是只有3个,那么回怎么样呢?
如图:
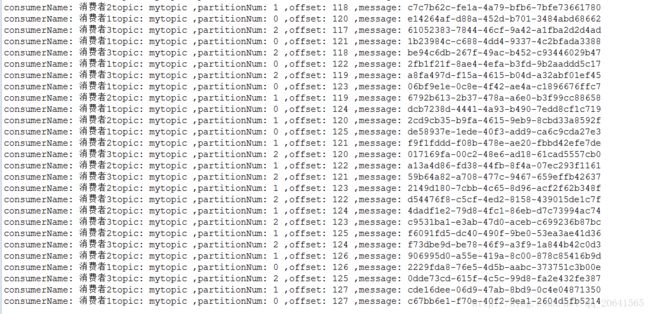
结果和上面一样,而消费者4没有效果
但是如果我把消费者设置为小于partition的个数,比如2个,又会怎样么?
如图:

可以看到消费者1会消费两个partition,分别是partition1和partition0,而消费者2只会消费partition2
这个现象正好验证了我上一篇博客,kafka消费者和partition个数的负载算法,详情见:http://blog.csdn.net/qq_20641565/article/details/59746101
当然,在kafka里面,默认的生产者生产数据会均衡的放到各个partition当中,如果我们需要指定特定消息到特定的partition里面,我们需要自定义partition