RocketMQ文档
RocketMQ 01
主要内容:
- 编译安装
- HelloWorld
官方网站
http://rocketmq.apache.org
GitHub
https://github.com/apache/rocketmq
Quick Start
Linux下使用Maven编译源码安装
Rocketmq4.6+需要jdk1.8环境编译和运行

各版本要求
| Version | Client | Broker | NameServer |
|---|---|---|---|
| 4.0.0-incubating | >=1.7 | >=1.8 | >=1.8 |
| 4.1.0-incubating | >=1.6 | >=1.8 | >=1.8 |
| 4.2.0 | >=1.6 | >=1.8 | >=1.8 |
| 4.3.x | >=1.6 | >=1.8 | >=1.8 |
| 4.4.x | >=1.6 | >=1.8 | >=1.8 |
| 4.5.x | >=1.6 | >=1.8 | >=1.8 |
| 4.6.x | >=1.6 | >=1.8 | >=1.8 |
1.从GitHub上下载源码并上传到服务器
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-CqM8Ji8B-1609973544622)(image-rocketMQ/image-20200218134855528.png)]
2.在Linux上安装Maven
下载Maven
wget https://mirrors.tuna.tsinghua.edu.cn/apache/maven/maven-3/3.6.3/binaries/apache-maven-3.6.3-bin.tar.gz
添加阿里云镜像
修改maven/conf目录下的settings.xml
在mirrors节点下添加
aliyun-maven
*
aliyun maven
http://maven.aliyun.com/nexus/content/groups/public
配置maven环境变量
修改/etc/profile
export M2_HOME=/usr/local/maven
export PATH=$PATH:$M2_HOME/bin
配置java环境变量
export JAVA_HOME="/usr/java/jdk1.8.0_181-amd64"
export CLASS_PATH="$JAVA_HOME/lib"
export PATH=".$PATH:$JAVA_HOME/bin"
环境变量修完执行source /etc/profile立即生效
进入rocketmq主目录编译项目
mvn -Prelease-all -DskipTests clean install -U
3.启动nameserver
bin目录下执行
./mqnamesrv
正常提示

4.启动Broker
./mqbroker -n localhost:9876
正常提示
![]()
5.测试消息发送
使用tool.sh脚本执行测试程序
在bin目录下执行
./tools.sh org.apache.rocketmq.example.quickstart.Producer
提示如下表示成功

6.接受消息
./tools.sh org.apache.rocketmq.example.quickstart.Consumer
控制台rocketmq-console编译安装
下载
https://github.com/apache/rocketmq-externals
中文指南
https://github.com/apache/rocketmq-externals/blob/master/rocketmq-console/doc/1_0_0/UserGuide_CN.md
上传到服务器并解压缩
编译
进入rocketmq-console目录
执行编译
mvn clean package -Dmaven.test.skip=true
启动
编译成功后在rocketmq-console/target目录下执行rocketmq-console-ng-1.0.1.jar
启动时,直接动态添加nameserver地址或编辑application.properties添加属性
java -jar rocketmq-console-ng-1.0.1.jar --rocketmq.config.namesrvAddr=127.0.0.1:9876
启动成功后访问服务器8080端口即可
pom.xml依赖
<dependency>
<groupId>org.apache.rocketmqgroupId>
<artifactId>rocketmq-clientartifactId>
<version>4.6.1version>
dependency>
安装启动常见错误
编译时包无法在mirror上找到 提示502错误
**原因:**网络不好或maven仓库服务器出错
重试即可,或者欢迎镜像仓库
发送失败提示connect to null failed
./tools.sh org.apache.rocketmq.example.quickstart.Producer
22:49:02.470 [main] DEBUG i.n.u.i.l.InternalLoggerFactory - Using SLF4J as the default logging framework
RocketMQLog:WARN No appenders could be found for logger (io.netty.util.internal.PlatformDependent0).
RocketMQLog:WARN Please initialize the logger system properly.
java.lang.IllegalStateException: org.apache.rocketmq.remoting.exception.RemotingConnectException: connect to
null failed
**原因:**不知道nameserver在哪儿
在tools脚本中添加
export NAMESRV_ADDR=localhost:9876
启动broker失败 Cannot allocate memory
**原因:**jvm启动初始化内存分配大于物理内存
[root@node-113b bin]# ./mqbroker -n localhost:9876
Java HotSpot(TM) 64-Bit Server VM warning: INFO: os::commit_memory(0x00000005c0000000, 8589934592, 0) failed
; error='Cannot allocate memory' (errno=12)#
# There is insufficient memory for the Java Runtime Environment to continue.
# Native memory allocation (mmap) failed to map 8589934592 bytes for committing reserved memory.
# An error report file with more information is saved as:
# /usr/local/rocketmq/bin/hs_err_pid1997.log
修改启动脚本中的jvm参数
runbroker.sh broker
runserver.sh nameserver
默认数值给的都很大,改小即可
JAVA_OPT="${JAVA_OPT} -server -Xms256m -Xmx256m -Xmn128m -XX:MetaspaceSize=64m -XX:MaxMetaspaceSize=100m"
启动broker成功但提示:Failed to obtain the host name
[root@node-113b bin]# ./mqbroker -n localhost:9876
22:30:42.307 [main] ERROR RocketmqCommon - Failed to obtain the host name
java.net.UnknownHostException: node-113b: node-113b: No address associated with hostname
at java.net.InetAddress.getLocalHost(InetAddress.java:1505) ~[na:1.8.0_181]
at org.apache.rocketmq.common.BrokerConfig.localHostName(BrokerConfig.java:189) [rocketmq-common-4.6
.1.jar:4.6.1] at org.apache.rocketmq.common.BrokerConfig.(BrokerConfig.java:38) [rocketmq-common-4.6.1.jar:4
.6.1] at org.apache.rocketmq.broker.BrokerStartup.createBrokerController(BrokerStartup.java:110) [rocketmq
-broker-4.6.1.jar:4.6.1] at org.apache.rocketmq.broker.BrokerStartup.main(BrokerStartup.java:58) [rocketmq-broker-4.6.1.jar:4
.6.1]Caused by: java.net.UnknownHostException: node-113b: No address associated with hostname
at java.net.Inet6AddressImpl.lookupAllHostAddr(Native Method) ~[na:1.8.0_181]
at java.net.InetAddress$2.lookupAllHostAddr(InetAddress.java:928) ~[na:1.8.0_181]
at java.net.InetAddress.getAddressesFromNameService(InetAddress.java:1323) ~[na:1.8.0_181]
at java.net.InetAddress.getLocalHost(InetAddress.java:1500) ~[na:1.8.0_181]
... 4 common frames omitted
The broker[DEFAULT_BROKER, 192.168.150.213:10911] boot success. serializeType=JSON and name server is localh
ost:9876
**原因:**无法解析当前的主机名
hosts里添加映射即可
192.168.150.213 node-113b
linux日期校准
安装ntpdate
yum install ntpdate
ntpdate ntp1.aliyun.com
RocketMQ 01
官网首页
Apache RocketMQ™ is a unified messaging engine, lightweight data processing platform.
Apache RocketMQ™ 是一个标准化的消息引擎,轻量级的处理平台
unified messaging engine :标准化消息引擎
lightweight data processing platform:轻量级处理平台
生词:
Community:社区
unified :统一的;一致标准的
messaging :消息传递,收发
engine:引擎
platform:平台
processing :处理、计算

Low Latency
低延迟
More than 99.6% response latency within 1 millisecond under high pressure.
在高压力下,1毫秒的延迟内可以响应超过99.6%的请求
Finance Oriented
金融方向,面向金融
High availability with tracking and auditing features.
系统具有高可用性支撑了追踪和审计的特性
Industry Sustainable
行业可发展性
Trillion-level message capacity guaranteed.
保证了万亿级别的消息容量。
生词:
Low Latency :低延迟
high pressure:高压
Oriented :面向
Finance : 金融
tracking :追踪
auditing :审计
Industry :产业、行业
Sustainable:可持续发展
Trillion-level : 万亿级别
capacity : 容量
guaranteed:有保证的

Vendor Neutral
中立厂商
Neutral:中立的
Vendor :厂商
A new open distributed messaging and streaming standard since latest 4.1 version.
在最新的4.1版本开放了一个新的分布式消息和流标准
BigData Friendly
对大数据友好
Batch transferring with versatile integration for flooding throughput.
批量传输与多功能集成支撑了海量吞吐。
Massive Accumulation
大量的积累
Given sufficient disk space, accumulate messages without performance loss.
只要给与足够的磁盘空间,就可以累积消息而不会造成性能损失。
生词:
standard : 标准
since : 自……以来
latest :最新的
version:版本
BigData :大数据
Batch :批量
transferring :转移、传输
versatile:多功能的
integration :集成
flooding:淹没、泛洪、泛滥
throughput:吞吐量
flooding throughput: 海量吞吐
Massive :大量的
Accumulation : 积累
sufficient:足够的
disk space:磁盘空间
accumulate :积累
performance loss:性能损失
RocketMQ 02
主流的MQ有很多,比如ActiveMQ、RabbitMQ、RocketMQ、Kafka、ZeroMQ等。
之前阿里巴巴也是使用ActiveMQ,随着业务发展,ActiveMQ IO 模块出现瓶颈,后来阿里巴巴 通过一系列优化但是还是不能很好的解决,之后阿里巴巴把注意力放到了主流消息中间件kafka上面,但是kafka并不能满足他们的要求,尤其是低延迟和高可靠性。
所以RocketMQ是站在巨人的肩膀上(kafka)MetaQ的内核,又对其进行了优化让其更满足互联网公司的特点。它是纯Java开发,具有高吞吐量、高可用性、适合大规模分布式系统应用的特点。 RocketMQ目前在阿里集团被广泛应用于交易、充值、流计算、消息推送、日志流式处理、binglog分发等场景。
消息队列介绍
消息队列是《数据结构》中先进先出的一种数据结构,在当前的架构中,作为中间件提供服务。
消息中间件功能
应用解耦
AB应用不在互相依赖
流量削峰
流量达到高峰的时候,通常使用限流算法来控制流量涌入系统,避免系统被击瘫,但是这种方式损失了一部分请求
此时可以使用消息中间件来缓冲大量的请求,匀速消费,当消息队列中堆积消息过多时,我们可以动态上线增加消费端,来保证不丢失重要请求。
大数据处理
消息中间件可以把各个模块中产生的管理员操作日志、用户行为、系统状态等数据文件作为消息收集到主题中
数据使用方可以订阅自己感兴趣的数据内容互不影响,进行消费
异构系统
跨语言
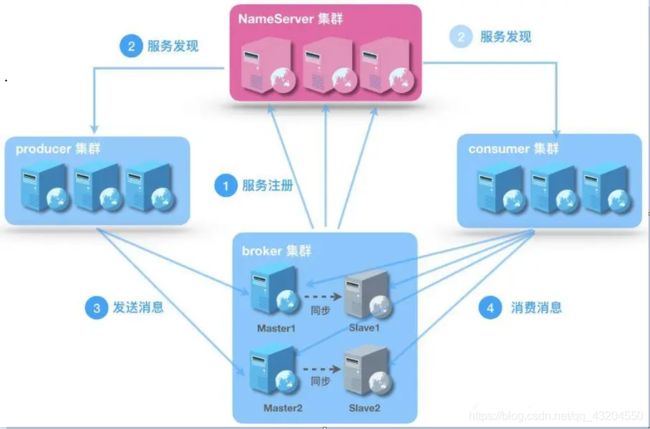
RocketMQ 角色
CAP
broker
- Broker面向producer和consumer接受和发送消息
- 向nameserver提交自己的信息
- 是消息中间件的消息存储、转发服务器。
- 每个Broker节点,在启动时,都会遍历NameServer列表,与每个NameServer建立长连接,注册自己的信息,之后定时上报。
broker集群
- Broker高可用,可以配成Master/Slave结构,Master可写可读,Slave只可以读,Master将写入的数据同步给Slave。
- 一个Master可以对应多个Slave,但是一个Slave只能对应一个Master
- Master与Slave的对应关系通过指定相同的BrokerName,不同的BrokerId来定义BrokerId为0表示Master,非0表示Slave
- Master多机负载,可以部署多个broker
- 每个Broker与nameserver集群中的所有节点建立长连接,定时注册Topic信息到所有nameserver。
producer
- 消息的生产者
- 通过集群中的其中一个节点(随机选择)建立长连接,获得Topic的路由信息,包括Topic下面有哪些Queue,这些Queue分布在哪些Broker上等
- 接下来向提供Topic服务的Master建立长连接,且定时向Master发送心跳
consumer
消息的消费者,通过NameServer集群获得Topic的路由信息,连接到对应的Broker上消费消息。
注意,由于Master和Slave都可以读取消息,因此Consumer会与Master和Slave都建立连接。
nameserver
底层由netty实现,提供了路由管理、服务注册、服务发现的功能,是一个无状态节点
nameserver是服务发现者,集群中各个角色(producer、broker、consumer等)都需要定时想nameserver上报自己的状态,以便互相发现彼此,超时不上报的话,nameserver会把它从列表中剔除
nameserver可以部署多个,当多个nameserver存在的时候,其他角色同时向他们上报信息,以保证高可用,
NameServer集群间互不通信,没有主备的概念
nameserver内存式存储,nameserver中的broker、topic等信息默认不会持久化
为什么不用zookeeper?:rocketmq希望为了提高性能,CAP定理,客户端负载均衡
对比JSM中的Topic和Queue
Topic是一个逻辑上的概念,实际上Message是在每个Broker上以Queue的形式记录。
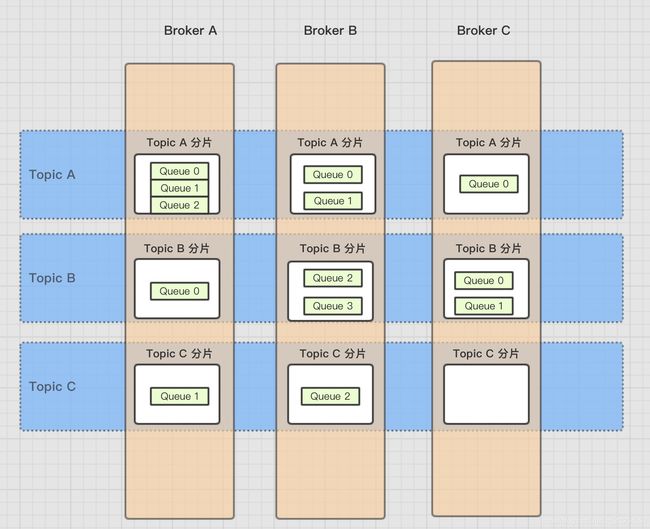
对应到JMS中的topic实现是由客户端来完成的
consumer.setMessageModel(MessageModel.BROADCASTING);
RocketMQ 03
消息
消息消费模式
消息消费模式由消费者来决定,可以由消费者设置MessageModel来决定消息模式。
消息模式默认为集群消费模式
consumer.setMessageModel(MessageModel.BROADCASTING);
consumer.setMessageModel(MessageModel.CLUSTERING);
集群消息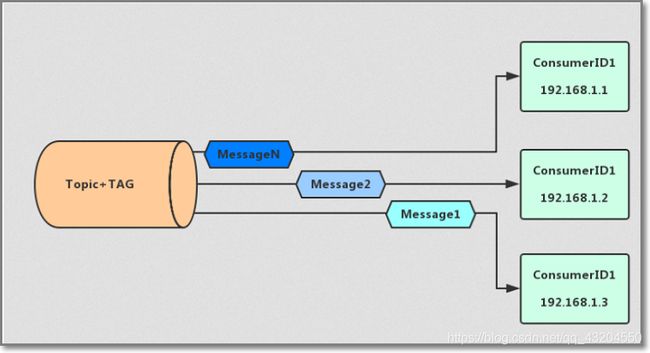
集群消息是指集群化部署消费者
当使用集群消费模式时,MQ 认为任意一条消息只需要被集群内的任意一个消费者处理即可。
特点
- 每条消息只需要被处理一次,broker只会把消息发送给消费集群中的一个消费者
- 在消息重投时,不能保证路由到同一台机器上
- 消费状态由broker维护
广播消息
当使用广播消费模式时,MQ 会将每条消息推送给集群内所有注册过的客户端,保证消息至少被每台机器消费一次。
特点
-
消费进度由consumer维护
-
保证每个消费者消费一次消息
-
消费失败的消息不会重投
发送方式
同步消息
消息发送中进入同步等待状态,可以保证消息投递一定到达
异步消息
想要快速发送消息,又不想丢失的时候可以使用异步消息
producer.send(message,new SendCallback() {
public void onSuccess(SendResult sendResult) {
// TODO Auto-generated method stub
System.out.println("ok");
}
public void onException(Throwable e) {
// TODO Auto-generated method stub
e.printStackTrace();
System.out.println("err");
}
});
单向消息
只发送消息,不等待服务器响应,只发送请求不等待应答。此方式发送消息的过程耗时非常短,一般在微秒级别。
producer.sendOneway(message);
批量消息发送
可以多条消息打包一起发送,减少网络传输次数提高效率。
producer.send(Collection c)方法可以接受一个集合 实现批量发送
public SendResult send(
Collection msgs) throws MQClientException, RemotingException, MQBrokerException, InterruptedException {
return this.defaultMQProducerImpl.send(batch(msgs));
}
- 批量消息要求必要具有同一topic、相同消息配置
- 不支持延时消息
- 建议一个批量消息最好不要超过1MB大小
- 如果不确定是否超过限制,可以手动计算大小分批发送
TAG
可以使用tag来过滤消费
在Producer中使用Tag:
Message msg = new Message("TopicTest","TagA" ,("Hello RocketMQ " ).getBytes(RemotingHelper.DEFAULT_CHARSET));
在Consumer中订阅Tag:
consumer.subscribe("TopicTest", "TagA||TagB");// * 代表订阅Topic下的所有消息
SQL表达式过滤
消费者将收到包含TAGA或TAGB或TAGB的消息. 但限制是一条消息只能有一个标签,而这对于复杂的情况可能无效。 在这种情况下,您可以使用SQL表达式筛选出消息.
配置
在broker.conf中添加配置
enablePropertyFilter=true
启动broker 加载指定配置文件
../bin/mqbroker -n 192.168.150.113:9876 -c broker.conf
随后在集群配置中可以看到
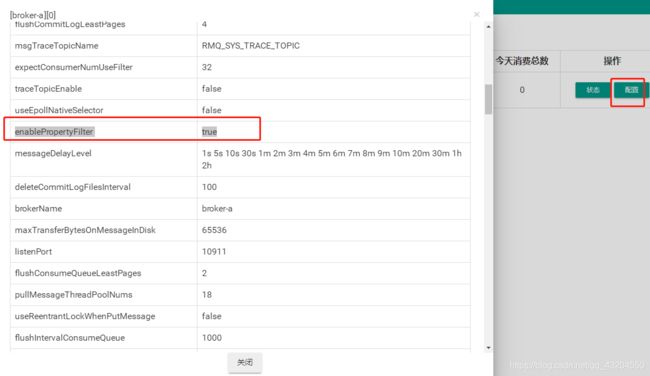
实例
MessageSelector selector = MessageSelector.bySql("order > 5");
consumer.subscribe("xxoo3", selector);
语法
RocketMQ只定义了一些基本的语法来支持这个功能。 你也可以很容易地扩展它.
- 数字比较, 像
>,>=,<,<=,BETWEEN,=; - 字符比较, 像
=,<>,IN; IS NULL或者IS NOT NULL;- 逻辑运算
AND,OR,NOT;
常量类型是:
- 数字, 像123, 3.1415;
- 字符串, 像‘abc’,必须使用单引号;
NULL, 特殊常数;- 布尔常量,
TRUE或FALSE;
延迟消息
RocketMQ使用messageDelayLevel可以设置延迟投递
默认配置为
messageDelayLevel 1s 5s 10s 30s 1m 2m 3m 4m 5m 6m 7m 8m 9m 10m 20m 30m 1h 2h
配置
在broker.conf中添加配置
messageDelayLevel=1s 5s 10s 30s 1m 2m 3m 4m 5m 6m 7m 8m 9m 10m 20m 30m 1h 2h
这个配置项配置了从1级开始,各级延时的时间,可以修改这个指定级别的延时时间;
时间单位支持:s、m、h、d,分别表示秒、分、时、天;
使用
发送消息时设置
message.setDelayTimeLevel(1);
顺序消费
队列先天支持FIFO模型,单一生产和消费者下只要保证使用MessageListenerOrderly监听器即可
顺序消费表示消息消费的顺序同生产者为每个消息队列发送的顺序一致,所以如果正在处理全局顺序是强制性的场景,需要确保使用的主题只有一个消息队列。
并行消费不再保证消息顺序,消费的最大并行数量受每个消费者客户端指定的线程池限制。
那么只要顺序的发送,再保证一个线程只去消费一个队列上的消息,那么他就是有序的。
跟普通消息相比,顺序消息的使用需要在producer的send()方法中添加MessageQueueSelector接口的实现类,并重写select选择使用的队列,因为顺序消息局部顺序,需要将所有消息指定发送到同一队列中。
保证有序参与因素
- FIFO
- 队列内保证有序
- 消费线程
重试机制
producer
默认超时时间
/**
* Timeout for sending messages.
*/
private int sendMsgTimeout = 3000;
// 异步发送时 重试次数,默认 2
producer.setRetryTimesWhenSendAsyncFailed(1);
// 同步发送时 重试次数,默认 2
producer.setRetryTimesWhenSendFailed(1);
// 是否向其他broker发送请求 默认false
producer.setRetryAnotherBrokerWhenNotStoreOK(true);
Consumer
消费超时,单位分钟
consumer.setConsumeTimeout()
发送ack,消费失败
RECONSUME_LATER
broker投递
只有在消息模式为MessageModel.CLUSTERING集群模式时,Broker才会自动进行重试,广播消息不重试
重投使用messageDelayLevel
默认值
messageDelayLevel 1s 5s 10s 30s 1m 2m 3m 4m 5m 6m 7m 8m 9m 10m 20m 30m 1h 2h
事务消息
分布式系统中的事务可以使用TCC(Try、Confirm、Cancel)、2pc来解决分布式系统中的消息原子性
RocketMQ 4.3+提供分布事务功能,通过 RocketMQ 事务消息能达到分布式事务的最终一致
RocketMQ实现方式
**Half Message:**预处理消息,当broker收到此类消息后,会存储到RMQ_SYS_TRANS_HALF_TOPIC的消息消费队列中
**检查事务状态:**Broker会开启一个定时任务,消费RMQ_SYS_TRANS_HALF_TOPIC队列中的消息,每次执行任务会向消息发送者确认事务执行状态(提交、回滚、未知),如果是未知,等待下一次回调。
**超时:**如果超过回查次数,默认回滚消息
TransactionListener的两个方法
executeLocalTransaction
半消息发送成功触发此方法来执行本地事务
checkLocalTransaction
broker将发送检查消息来检查事务状态,并将调用此方法来获取本地事务状态
本地事务执行状态
LocalTransactionState.COMMIT_MESSAGE
执行事务成功,确认提交
LocalTransactionState.ROLLBACK_MESSAGE
回滚消息,broker端会删除半消息
LocalTransactionState.UNKNOW
暂时为未知状态,等待broker回查
RocketMQ 04
MQAdmin
创建Topic updateTopic
./mqadmin updateTopic -b localhost:10911 -t TopicCmd
删除Topic deleteTopic
./mqadmin deleteTopic -n localhost:9876 -c localhost:10911 -t TopicCmd
Topic列表 topicList
./mqadmin topicList -n localhost:9876
Topic信息 topicStatus
./mqadmin topicStatus -n localhost:9876 -t xxoo3
Topic 路由信息 topicRoute
./mqadmin topicRoute -n localhost:9876 -t xxoo3
Broker状态信息 brokerStatus
./mqadmin brokerStatus -n localhost:9876 -b localhost:10911
Broker配置信息 brokerStatus
./mqadmin getBrokerConfig -n localhost:9876 -b localhost:10911
性能测试
./mqadmin sendMsgStatus -n localhost:9876 -b broker-a -c 10
后台启动服务
nohup ./mqnamesrv >./log.txt 2>&1 &
nohup
ssh连接中,运行这条指令,你会发现进程中有了demo.jar 这条进程,但它并不在后台运行这时你无法在当前ssh连接中进行其他命令,因为它不是后台运行,你ctrl+c,这条进程会消失。
nohup 并不会后台运行,它是忽略内部的挂断信号,不挂断运行
&
程序会在后台运行,如果直接关闭窗口,进程任然会被关闭
>./log.txt
表示把控制台的日志输出到指定文件中
2>&1
0表示标准输入
1表示标准输出
2表示标准错误输出
> 默认为标准输出重定向,与 1> 相同
2>&1 意思是把 标准错误输出 重定向到 标准输出.
&>file 意思是把 标准输出 和 标准错误输出 都重定向到文件file中
终止进程中的kill命令
1 SIGHUP 挂起进程
2 SIGINT 终止进程
3 SIGGQUIT 停止进程
9 SIGKILL 无条件终止进程
15 SIGTERM 尽可能终止进程
17 SIGSTOP 无条件停止进程,但不是终止
18 SIGTSTP 停止或者暂停进程,但不终止进程
19 SIGCONT 继续运行停止的进程
RocketMQ 05
Offset
每个broker中的queue在收到消息时会记录offset,初始值为0,每记录一条消息offset会递增+1
minOffset
最小值
maxOffset
最大值
consumerOffset
消费者消费进度/位置
diffTotal
消费积压/未被消费的消息数量
消费者
DefaultMQPushConsumer 与 DefaultMQPullConsumer
在消费端,我们可以视情况来控制消费过程
DefaultMQPushConsumer 由系统自动控制过程,
DefaultMQPullConsumer 大部分功能需要手动控制
集群消息的消费负载均衡
在集群消费模式下(clustering)
相同的group中的每个消费者只消费topic中的一部分内容
group中的所有消费者都参与消费过程,每个消费者消费的内容不重复,从而达到负载均衡的效果。
使用DefaultMQPushConsumer,新启动的消费者自动参与负载均衡。
ProcessQueue
消息处理类 源码解析
长轮询
Consumer -> Broker RocketMQ采用的长轮询建立连接
- consumer的处理能力Broker不知道
- 直接推送消息 broker端压力较大
- 采用长连接有可能consumer不能及时处理推送过来的数据
- pull主动权在consumer手里
短轮询
client不断发送请求到server,每次都需要重新连接
长轮询
client发送请求到server,server有数据返回,没有数据请求挂起不断开连接
长连接
连接一旦建立,永远不断开,push方式推送
RocketMQ 06 消息存储机制
消息存储
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-w0URFiWw-1609973626100)(…/…/…/…/images-02/image-20200228140910086.png)]
磁盘存储速度问题
省去DB层提高性能
RocketMQ 使用文件系统持久化消息。性能要比使用DB产品要高。
M.2 NVME协议磁盘存储
文件写入速度 顺序读写:3G左右 随机读写2G
数据零拷贝技术
很多使用文件系统存储的高性能中间件都是用了零拷贝技术来发送文件数据,比如Nginx
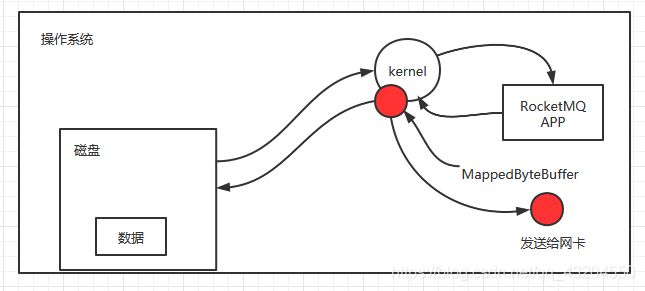
内存映射MappedByteBuffer API
- MappedByteBuffer使用虚拟内存,因此分配(map)的内存大小不受JVM的-Xmx参数限制,但是也是有大小限制的。
- 如果当文件超出1.5G限制时,可以通过position参数重新map文件后面的内容。
- MappedByteBuffer在处理大文件时的确性能很高,但也存在一些问题,如内存占用、文件关闭不确定,被其打开的文件只有在垃圾回收的才会被关闭,而且这个时间点是不确定的。
javadoc中也提到:A mapped byte buffer and the file mapping that it represents remain* valid until the buffer itself is garbage-collected.
所以为了使用零拷贝技术,RocketMQ的文件存储大小默认每个1G,超过1G会重新建立一个新文件
存储结构
CommitLog
存储消息的详细内容,按照消息收到的顺序,所有消息都存储在一起。每个消息存储后都会有一个offset,代表在commitLog中的偏移量。
默认配置 MessageStoreConfig
核心方法
- putMessage 写入消息
CommitLog内部结构
- MappedFileQueue -> MappedFile
MappedFile
默认大小 1G
// CommitLog file size,default is 1G
private int mappedFileSizeCommitLog = 1024 * 1024 * 1024;
ConsumerQueue
通过消息偏移量建立的消息索引
针对每个Topic创建,消费逻辑队列,存储位置信息,用来快速定位CommitLog中的数据位置
启动后会被加载到内存中,加快查找消息速度
以Topic作为文件名称,每个Topic下又以queue id作为文件夹分组
默认大小
// ConsumeQueue extend file size, 48M
private int mappedFileSizeConsumeQueueExt = 48 * 1024 * 1024;
indexFile
消息的Key和时间戳索引
存储路径配置
默认文件会存储在家目录下/root/store/
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-IrlYBTqx-1609973626100)(…/…/…/…/images-02/image-20200228150807152.png)]
config
以json格式存储消费信息
consumerFilter.json
消息过滤器
consumerOffset.json
客户端的消费进度
delayOffset.json
延迟消息进度
subscriptionGroup.json
group的订阅数据
topics.json
Topic的配置信息
刷盘机制
在CommitLog初始化时,判断配置文件 加载相应的service
if (FlushDiskType.SYNC_FLUSH == defaultMessageStore.getMessageStoreConfig().getFlushDiskType()) {
this.flushCommitLogService = new GroupCommitService();
} else {
this.flushCommitLogService = new FlushRealTimeService();
}
写入时消息会不会分割到两个MapedFile中?
// Determines whether there is sufficient free space
if ((msgLen + END_FILE_MIN_BLANK_LENGTH) > maxBlank) {
this.resetByteBuffer(this.msgStoreItemMemory, maxBlank);
// 1 TOTALSIZE
this.msgStoreItemMemory.putInt(maxBlank);
// 2 MAGICCODE
不够放下一个消息的时候,用魔术字符代替
this.msgStoreItemMemory.putInt(CommitLog.BLANK_MAGIC_CODE);
// 3 The remaining space may be any value
// Here the length of the specially set maxBlank
final long beginTimeMills = CommitLog.this.defaultMessageStore.now();
byteBuffer.put(this.msgStoreItemMemory.array(), 0, maxBlank);
return new AppendMessageResult(AppendMessageStatus.END_OF_FILE, wroteOffset, maxBlank, msgId, msgInner.getStoreTimestamp(),
queueOffset, CommitLog.this.defaultMessageStore.now() - beginTimeMills);
}
同步刷盘
消息被Broker写入磁盘后再给producer响应
异步刷盘
消息被Broker写入内存后立即给producer响应,当内存中消息堆积到一定程度的时候写入磁盘持久化。
配置选项
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-9XhSvs7I-1609973626101)(…/…/…/…/images-02/image-20200228150746731.png)]
RocketMQ 07 NameServer详解
NameServer是一个非常简单的Topic路由注册中心,其角色类似Dubbo中的zookeeper,支持Broker的动态注册与发现。主要包括两个功能
Broker管理,NameServer接受Broker集群的注册信息并且保存下来作为路由信息的基本数据。然后提供心跳检测机制,检查Broker是否还存活;
路由信息管理,每个NameServer将保存关于Broker集群的整个路由信息和用于客户端查询的队列信息。然后Producer和Conumser通过NameServer就可以知道整个Broker集群的路由信息,从而进行消息的投递和消费
NameServer通常也是集群的方式部署,各实例间相互不进行信息通讯。Broker是向每一台NameServer注册自己的路由信息,所以每一个NameServer实例上面都保存一份完整的路由信息。当某个NameServer因某种原因下线了,Broker仍然可以向其它NameServer同步其路由信息,Producer,Consumer仍然可以动态感知Broker的路由的信息
NameServer实例时间互不通信,这本身也是其设计亮点之一,即允许不同NameServer之间数据不同步(像Zookeeper那样保证各节点数据强一致性会带来额外的性能消耗)
为什么没有使用zookeeper?
RocketMQ 08 集群
单Master模式
只有一个 Master节点
优点:配置简单,方便部署
缺点:这种方式风险较大,一旦Broker重启或者宕机时,会导致整个服务不可用,不建议线上环境使用
多Master模式
一个集群无 Slave,全是 Master,例如 2 个 Master 或者 3 个 Master
优点:配置简单,单个Master 宕机或重启维护对应用无影响,在磁盘配置为RAID10 时,即使机器宕机不可恢复情况下,由与 RAID10磁盘非常可靠,消息也不会丢(异步刷盘丢失少量消息,同步刷盘一条不丢)。性能最高。多 Master 多 Slave 模式,异步复制
缺点:单台机器宕机期间,这台机器上未被消费的消息在机器恢复之前不可订阅,消息实时性会受到受到影响
多Master多Slave模式(异步复制)
每个 Master 配置一个 Slave,有多对Master-Slave, HA,采用异步复制方式,主备有短暂消息延迟,毫秒级。
优点:即使磁盘损坏,消息丢失的非常少,且消息实时性不会受影响,因为Master 宕机后,消费者仍然可以从 Slave消费,此过程对应用透明。不需要人工干预。性能同多 Master 模式几乎一样。
缺点: Master 宕机,磁盘损坏情况,会丢失少量消息。
多Master多Slave模式(同步双写)
每个 Master 配置一个 Slave,有多对Master-Slave, HA采用同步双写方式,主备都写成功,向应用返回成功。
优点:数据与服务都无单点, Master宕机情况下,消息无延迟,服务可用性与数据可用性都非常高
缺点:性能比异步复制模式略低,大约低 10%左右,发送单个消息的 RT会略高。目前主宕机后,备机不能自动切换为主机,后续会支持自动切换功能

双主双从集群搭建
准备
- 4台虚拟机
rm -rf /etc/udev/rules.d/70-persistent-net.rulesvi /etc/sysconfig/network-scripts/ifcfg-eth0
- 配置好网络
- 准备好RocketMQ服务端程序
启动NameServer
4台机器分别启动
Broker配置
Broker configuration
| Property Name | Default value | Details |
|---|---|---|
| listenPort | 10911 | listen port for client |
| namesrvAddr | null | name server address |
| brokerIP1 | InetAddress for network interface | Should be configured if having multiple addresses |
| brokerName | null | broker name |
| brokerClusterName | DefaultCluster | this broker belongs to which cluster |
| brokerId | 0 | broker id, 0 means master, positive integers mean slave |
| storePathCommitLog | $HOME/store/commitlog/ | file path for commit log |
| storePathConsumerQueue | $HOME/store/consumequeue/ | file path for consume queue |
| mapedFileSizeCommitLog | 1024 * 1024 * 1024(1G) | mapped file size for commit log |
| deleteWhen | 04 | When to delete the commitlog which is out of the reserve time |
| fileReserverdTime | 72 | The number of hours to keep a commitlog before deleting it |
| brokerRole | ASYNC_MASTER | SYNC_MASTER/ASYNC_MASTER/SLAVE |
| flushDiskType | ASYNC_FLUSH | {SYNC_FLUSH/ASYNC_FLUSH}. Broker of SYNC_FLUSH mode flushes each message onto disk before acknowledging producer. Broker of ASYNC_FLUSH mode, on the other hand, takes advantage of group-committing, achieving better performance |
**brokerClusterName:**同一个集群中,brokerClusterName需一致
**brokerId:**0 表示 Master,>0 表示 Slave
**namesrvAddr:**配置多个用分号分隔
brokerIP1:默认系统自动识别,但是某些多网卡机器会存在识别错误的情况,建议都手工指定
**brokerRole:**选择Broker的角色
**flushDiskType:**选择刷盘方式
deleteWhen: 过期文件真正删除时间
**fileReservedTime:**Commitlog、ConsumeQueue文件,如果非当前写文件在一定时间间隔内没有再次被更新,则认为是过期文件,可以被删除,RocketMQ不会管这个这个文件上的消息是否被全部消费
主备切换 故障转移模式
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-TADtze03-1609973650760)(image-rocketMQ/watermark,type_ZmFuZ3poZW5naGVpdGk,shadow_10,text_aHR0cHM6Ly9ibG9nLmNzZG4ubmV0L3l1bnFpaW5zaWdodA==,size_16,color_FFFFFF,t_70)]
在 RocketMQ 4.5 版本之前,RocketMQ 只有 Master/Slave 一种部署方式,一组 broker 中有一个 Master ,有零到多个
Slave,Slave 通过同步复制或异步复制的方式去同步 Master 数据。Master/Slave 部署模式,提供了一定的高可用性。
但这样的部署模式,有一定缺陷。比如故障转移方面,如果主节点挂了,还需要人为手动进行重启或者切换,无法自动将一个从节点转换为主节点。因此,我们希望能有一个新的多副本架构,去解决这个问题。
新的多副本架构首先需要解决自动故障转移的问题,本质上来说是自动选主的问题。这个问题的解决方案基本可以分为两种:
利用第三方协调服务集群完成选主,比如 zookeeper 或者 etcd(raft)。这种方案会引入了重量级外部组件,加重部署,运维和故障诊断成本,比如在维护 RocketMQ 集群还需要维护 zookeeper 集群,并且 zookeeper 集群故障会影响到 RocketMQ 集群。
利用 raft 协议来完成一个自动选主,raft 协议相比前者的优点是不需要引入外部组件,自动选主逻辑集成到各个节点的进程中,节点之间通过通信就可以完成选主。
DLedger
至少要组件3台服务器集群,不然无法提供选举
broker配置
# dleger
enableDLegerCommitLog = true
dLegerGroup = broker-a
dLegerPeers = n0-192.168.150.210:40911;n1-192.168.150.211:40911
dLegerSelfId = n0
sendMessageThreadPoolNums = 4
Topic中的Queue分布
手动创建topic
topic可以在producer发送消息时自动创建或使用console手动创建,但还有很多细节参数无法指定 ,在生成环境中,通常我们会使用MQAdmin工具指定具体参数,
命令
[root@node-01 bin]# ./mqadmin updateTopic
usage: mqadmin updateTopic -b | -c [-h] [-n ] [-o ] [-p ] [-r ] [-s ] -t
[-u ] [-w ]
-b,--brokerAddr create topic to which broker
-c,--clusterName create topic to which cluster
-h,--help Print help
-n,--namesrvAddr Name server address list, eg: 192.168.0.1:9876;192.168.0.2:9876
-o,--order set topic's order(true|false)
-p,--perm set topic's permission(2|4|6), intro[2:W 4:R; 6:RW]
-r,--readQueueNums set read queue nums
-s,--hasUnitSub has unit sub (true|false)
-t,--topic topic name
-u,--unit is unit topic (true|false)
-w,--writeQueueNums set write queue nums
RocketMQ 09 SpringBoot 整合
目前还没有官方的starter
pom.xml
org.apache.rocketmq
rocketmq-common
4.6.1
org.apache.rocketmq
rocketmq-client
4.6.1
Producer配置
Config配置类
用于在系统启动时初始化producer参数并启动
package com.mashibing.rmq.controller;
import org.apache.rocketmq.client.exception.MQClientException;
import org.apache.rocketmq.client.producer.DefaultMQProducer;
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
import org.springframework.beans.factory.annotation.Value;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
@Configuration
public class MQConfig {
public static final Logger LOGGER = LoggerFactory.getLogger(MQConfig.class);
@Value("${rocketmq.producer.groupName}")
private String groupName;
@Value("${rocketmq.producer.namesrvAddr}")
private String namesrvAddr;
@Bean
public DefaultMQProducer getRocketMQProducer() {
DefaultMQProducer producer;
producer = new DefaultMQProducer(this.groupName);
producer.setNamesrvAddr(this.namesrvAddr);
try {
producer.start();
System.out.println("start....");
LOGGER.info(String.format("producer is start ! groupName:[%s],namesrvAddr:[%s]", this.groupName,
this.namesrvAddr));
} catch (MQClientException e) {
LOGGER.error(String.format("producer is error {}", e.getMessage(), e));
}
return producer;
}
}
Service消息发送类
package com.mashibing.rmq.service;
import org.apache.rocketmq.client.producer.DefaultMQProducer;
import org.apache.rocketmq.common.message.Message;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.stereotype.Service;
@Service
public class MQService {
@Autowired
DefaultMQProducer producer;
public Object sendMsg(String string) {
for (int i = 0; i < 1; i++) {
Message message = new Message("tpk02", "xx".getBytes());
try {
return producer.send(message);
} catch (Exception e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
}
return null;
}
}
配置文件
spring.application.name=mq01
rocketmq.producer.namesrvAddr=192.168.150.131:9876
rocketmq.producer.groupName=${spring.application.name}
server.port=8081
Consumer配置
Config配置类
package com.mashibing.rmq.controller;
import org.apache.rocketmq.client.consumer.DefaultMQPushConsumer;
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
import org.springframework.beans.factory.annotation.Value;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
@Configuration
public class MQConfig {
public static final Logger logger = LoggerFactory.getLogger(MQConfig.class);
@Value("${rocketmq.consumer.namesrvAddr}")
private String namesrvAddr;
@Value("${rocketmq.consumer.groupName}")
private String groupName;
@Value("${rocketmq.consumer.topics}")
private String topics;
@Bean
public DefaultMQPushConsumer getRocketMQConsumer() throws Exception {
DefaultMQPushConsumer consumer = new DefaultMQPushConsumer(groupName);
consumer.setNamesrvAddr(namesrvAddr);
consumer.subscribe(topics, "*");
consumer.registerMessageListener(new MyMessageListener() );
consumer.start();
return consumer;
}
}
消息处理类
package com.mashibing.rmq.controller;
import java.util.List;
import org.apache.rocketmq.client.consumer.listener.ConsumeConcurrentlyContext;
import org.apache.rocketmq.client.consumer.listener.ConsumeConcurrentlyStatus;
import org.apache.rocketmq.client.consumer.listener.MessageListenerConcurrently;
import org.apache.rocketmq.common.message.MessageExt;
public class MyMessageListener implements MessageListenerConcurrently {
@Override
public ConsumeConcurrentlyStatus consumeMessage(List<MessageExt> msgs, ConsumeConcurrentlyContext context) {
System.out.println("来啦!!22!");
for (MessageExt msg : msgs) {
System.out.println(new String(msg.getBody()));;
}
return ConsumeConcurrentlyStatus.CONSUME_SUCCESS;
}
}
配置文件
spring.application.name=mq02
rocketmq.producer.namesrvAddr=192.168.150.131:9876
rocketmq.producer.groupName=${spring.application.name}
rocketmq.consumer.topics=tpk02
RocketMQ 面试FAQ
说说你们公司线上生产环境用的是什么消息中间件?
为什么要使用MQ?
因为项目比较大,做了分布式系统,所有远程服务调用请求都是同步执行经常出问题,所以引入了mq
解耦
系统耦合度降低,没有强依赖关系
异步
不需要同步执行的远程调用可以有效提高响应时间
削峰
请求达到峰值后,后端service还可以保持固定消费速率消费,不会被压垮
多个mq如何选型?
RabbitMQ
erlang开发,延迟比较低
RocketMQ
java开发,面向互联网集群化功能丰富
kafka
Scala开发,面向日志功能丰富
ActiveMQ
java开发,简单,稳定
小项目:ActiveMQ
大项目:RocketMQ或kafka、RabbitMq
RocketMQ由哪些角色组成,每个角色作用和特点是什么?
nameserver 无状态 动态列表
producer
broker
consumer
RocketMQ中的Topic和ActiveMQ有什么区别?
ActiveMQ
有destination的概念,即消息目的地
destination分为两类:
- topic
- 广播消息
- queue
- 队列消息
RocketMQ
RocketMQ的Topic是一组Message Queue的集合 ConsumeQueue
一条消息是广播消息还是队列消息由客户端消费决定
RocketMQ Broker中的消息被消费后会立即删除吗?
不会,每条消息都会持久化到CommitLog中,每个consumer连接到broker后会维持消费进度信息,当有消息消费后只是当前consumer的消费进度(CommitLog的offset)更新了。
那么消息会堆积吗?什么时候清理过期消息?
4.6版本默认48小时后会删除不再使用的CommitLog文件
- 检查这个文件最后访问时间
- 判断是否大于过期时间
- 指定时间删除,默认凌晨4点
RocketMQ消费模式有几种?
消费模型由consumer决定,消费维度为Topic
集群消费
一组consumer同时消费一个topic,可以分配消费负载均衡策略分配consumer对应消费topic下的哪些queue
多个group同时消费一个topic时,每个group都会消费到数据
一条消息只会被一个group中的consumer消费,
广播消费
消息将对一 个Consumer Group 下的各个 Consumer 实例都消费一遍。即即使这些 Consumer 属于同一个Consumer Group ,消息也会被 Consumer Group 中的每个 Consumer 都消费一次。
消费消息时使用的是push还是pull?
在刚开始的时候就要决定使用哪种方式消费
两种:
DefaultLitePullConsumerImpl 拉
DefaultMQPushConsumerImpl推
两个实现 DefaultLitePullConsumerImpl DefaultMQPushConsumerImpl都实现了MQConsumerInner接口接口
名称上看起来是一个推,一个拉,但实际底层实现都是采用的长轮询机制,即拉取方式
broker端属性 longPollingEnable 标记是否开启长轮询。默认开启
为什么要主动拉取消息而不使用事件监听方式?
事件驱动方式是建立好长连接,由事件(发送数据)的方式来实时推送。
如果broker主动推送消息的话有可能push速度快,消费速度慢的情况,那么就会造成消息在consumer端堆积过多,同时又不能被其他consumer消费的情况
说一说几种常见的消息同步机制?
push:
如果broker主动推送消息的话有可能push速度快,消费速度慢的情况,那么就会造成消息在consumer端堆积过多,同时又不能被其他consumer消费的情况
pull:
轮训时间间隔,固定值的话会造成资源浪费
长轮询:
上连接 短连接(每秒) 长轮询
broker如何处理拉取请求的?
consumer首次请求broker
- broker中是否有符合条件的消息
- 有 ->
- 响应consumer
- 等待下次consumer的请求
- 没有
- 挂起consumer的请求,即不断开连接,也不返回数据
- 挂起时间长短,写死在代码里的吗?长轮询写死,短轮询可以配
- 使用consumer的offset,
- DefaultMessageStore#ReputMessageService#run方法
- 每隔1ms检查commitLog中是否有新消息,有的话写入到pullRequestTable
- 当有新消息的时候返回请求
- PullRequestHoldService 来Hold连接,每个5s执行一次检查pullRequestTable有没有消息,有的话立即推送
- DefaultMessageStore#ReputMessageService#run方法
RocketMQ如何做负载均衡?
通过Topic在多broker种分布式存储实现
producer端
发送端指定Target message queue发送消息到相应的broker,来达到写入时的负载均衡
- 提升写入吞吐量,当多个producer同时向一个broker写入数据的时候,性能会下降
- 消息分布在多broker种,为负载消费做准备
每 30 秒从 nameserver获取 Topic 跟 Broker 的映射关系,近实时获取最新数据存储单元,queue落地在哪个broker中
在使用api中send方法的时候,可以指定Target message queue写入或者使用MessageQueueSelector
默认策略是随机选择:
- producer维护一个index
- 每次取节点会自增
- index向所有broker个数取余
- 自带容错策略
其他实现
- SelectMessageQueueByHash
- hash的是传入的args
- SelectMessageQueueByRandom
- SelectMessageQueueByMachineRoom 没有实现
也可以自定义实现MessageQueueSelector接口中的select方法
MessageQueue select(final List mqs, final Message msg, final Object arg);
可以自定义规则来选择mqs
如何知道mqs的,mqs的数据从哪儿来?
producer.start()方法
参考源码
- 启动producer的时候会向nameserver发送心跳包
- 获取nameserver中的topic列表
- 使用topic向nameserver获取topicRouteData
TopicRouteData对象表示与某一个topic有关系的broker节点信息,内部包含多个QueueData对象(可以有多个broker集群支持该topic)和多个BrokerData信息(多个集群的多个节点信息都在该列表中)
producer加工TopicRouteData,对应的多节点信息后返回mqs。
consumer端
客户端完成负载均衡
- 获取集群其他节点
- 当前节点消费哪些queue
- 负载粒度直到Message Queue
- consumer的数量最好和Message Queue的数量对等或者是倍数,不然可能会有消费倾斜
- 每个consumer通过balanced维护processQueueTable
- processQueueTable为当前consumer的消费queue
- processQueueTable中有
- ProcessQueue :维护消费进度,从broker中拉取回来的消息缓冲
- MessageQueue : 用来定位查找queue
DefaultMQPushConsumer默认 使用AllocateMessageQueueAveragely(平均分配)
当消费负载均衡consumer和queue不对等的时候会发生什么?
平均分配
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-nXy8CWQC-1609973670711)(image-rocketMQ/image-20200313171617553.png)]
环形分配
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-4arPggzE-1609973670713)(image-rocketMQ/image-20200313171645109.png)]
负载均衡算法
平均分配策略(默认)(AllocateMessageQueueAveragely)
环形分配策略(AllocateMessageQueueAveragelyByCircle)
手动配置分配策略(AllocateMessageQueueByConfig)
机房分配策略(AllocateMessageQueueByMachineRoom)
一致性哈希分配策略(AllocateMessageQueueConsistentHash)
靠近机房策略(AllocateMachineRoomNearby)
consumer启动流程参考源码
消息丢失
SendResult
producer在发送同步/异步可靠消息后,会接收到SendResult,表示消息发送成功
SendResult其中属性sendStatus表示了broker是否真正完成了消息存储
当sendStatus!="ok"的时候,应该重新发送消息,避免丢失
当producer.setRetryAnotherBrokerWhenNotStoreOK
消息重复消费
影响消息正常发送和消费的重要原因是网络的不确定性。
可能是因为consumer首次启动引起重复消费
需要设置consumer.setConsumeFromWhere
只对一个新的consumeGroup第一次启动时有效,设置从头消费还是从维护开始消费
你们怎么保证投递出去的消息只有一条且仅仅一条,不会出现重复的数据?
绑定业务key
如果消费了重复的消息怎么保证数据的准确性?
引起重复消费的原因
ACK
正常情况下在consumer真正消费完消息后应该发送ack,通知broker该消息已正常消费,从queue中剔除
当ack因为网络原因无法发送到broker,broker会认为词条消息没有被消费,此后会开启消息重投机制把消息再次投递到consumer
group
在CLUSTERING模式下,消息在broker中会保证相同group的consumer消费一次,但是针对不同group的consumer会推送多次
解决方案
数据库表
处理消息前,使用消息主键在表中带有约束的字段中insert
Map
单机时可以使用map ConcurrentHashMap -> putIfAbsent guava cache
Redis
使用主键或set操作
如何让RocketMQ保证消息的顺序消费
你们线上业务用消息中间件的时候,是否需要保证消息的顺序性?
如果不需要保证消息顺序,为什么不需要?假如我有一个场景要保证消息的顺序,你们应该如何保证?
-
同一topic
-
同一个QUEUE
-
发消息的时候一个线程去发送消息
-
消费的时候 一个线程 消费一个queue里的消息或者使用MessageListenerOrderly
-
多个queue 只能保证单个queue里的顺序
应用场景是啥?
应用系统和现实的生产业务绑定,避免在分布式系统中多端消费业务消息造成顺序混乱
比如需要严格按照顺序处理的数据或业务
数据包装/清洗
数据:
import java.nio.ByteBuffer;
import java.nio.charset.Charset;
import java.util.HashMap;
import java.util.Iterator;
import java.util.Map;
- 去掉import
- 统计某个字符出现次数
业务流程处理
返修过程
- 收件录入信息
- 信息核对
- 送入检修系统处理
电商订单
- 创建订单
- 检查库存预扣库存
- 支付
- 真扣库存
binlog同步
RocketMQ如何保证消息不丢失
- 生产端如何保证投递出去的消息不丢失:消息在半路丢失,或者在MQ内存中宕机导致丢失,此时你如何基于MQ的功能保证消息不要丢失?
- MQ自身如何保证消息不丢失?
- 消费端如何保证消费到的消息不丢失:如果你处理到一半消费端宕机,导致消息丢失,此时怎么办?
解耦的思路
发送方
发送消息时做消息备份(记日志或同步到数据库),判断sendResult是否正常返回
broker
节点保证
- master接受到消息后同步刷盘,保证了数据持久化到了本机磁盘中
- 同步写入slave
- 写入完成后返回SendResult
consumer
- 记日志
- 同步执行业务逻辑,最后返回ack
- 异常控制
磁盘保证
使用Raid磁盘阵列保证数据磁盘安全
网络数据篡改
内置TLS可以开启,默认使用crc32校验数据
消息刷盘机制底层实现
每间隔10ms,执行一次数据持久化操作
两种, 同步刷、异步刷
public void run() {
CommitLog.log.info(this.getServiceName() + " service started");
while (!this.isStopped()) {
try {
this.waitForRunning(10);
this.doCommit();
} catch (Exception e) {
CommitLog.log.warn(this.getServiceName() + " service has exception. ", e);
}
}
rocketMq的消息堆积如何处理
下游消费系统如果宕机了,导致几百万条消息在消息中间件里积压,此时怎么处理?
你们线上是否遇到过消息积压的生产故障?如果没遇到过,你考虑一下如何应对?
具体表现为 ui中转圈圈
对于大规模消息发送接收可以使用pull模式,手动处理消息拉取速度,消费的时候统计消费时间以供参考
保证消息消费速度固定,即可通过上线更多consumer临时解决消息堆积问题
如果consumer和queue不对等,上线了多台也在短时间内无法消费完堆积的消息怎么办?
-
准备一个临时的topic
-
queue的数量是堆积的几倍
-
queue分不到多broker种
-
上线一台consumer做消息的搬运工,把原来topic中的消息挪到新的topic里,不做业务逻辑处理,只是挪过去
-
上线N台consumer同时消费临时topic中的数据
-
改bug
-
恢复原来的consumer,继续消费之前的topic
堆积时间过长消息超时了?
RocketMQ中的消息只会在commitLog被删除的时候才会消失,不会超时
堆积的消息会不会进死信队列?
不会,消息在消费失败后会进入重试队列(%RETRY%+consumergroup),多次(默认16)才会进入死信队列(%DLQ%+consumergroup)
你们用的是RocketMQ?那你说说RocketMQ的底层架构原理,磁盘上数据如何存储的,整体分布式架构是如何实现的?
零拷贝等技术是如何运用的?
使用nio的MappedByteBuffer调起数据输出
你们用的是RocketMQ?RocketMQ很大的一个特点是对分布式事务的支持,你说说他在分布式事务支持这块机制的底层原理?
分布式系统中的事务可以使用TCC(Try、Confirm、Cancel)、2pc来解决分布式系统中的消息原子性
RocketMQ 4.3+提供分布事务功能,通过 RocketMQ 事务消息能达到分布式事务的最终一致
RocketMQ实现方式
**Half Message:**预处理消息,当broker收到此类消息后,会存储到RMQ_SYS_TRANS_HALF_TOPIC的消息消费队列中
**检查事务状态:**Broker会开启一个定时任务,消费RMQ_SYS_TRANS_HALF_TOPIC队列中的消息,每次执行任务会向消息发送者确认事务执行状态(提交、回滚、未知),如果是未知,等待下一次回调。
**超时:**如果超过回查次数,默认回滚消息
TransactionListener的两个方法
executeLocalTransaction
半消息发送成功触发此方法来执行本地事务
checkLocalTransaction
broker将发送检查消息来检查事务状态,并将调用此方法来获取本地事务状态
本地事务执行状态
LocalTransactionState.COMMIT_MESSAGE
执行事务成功,确认提交
LocalTransactionState.ROLLBACK_MESSAGE
回滚消息,broker端会删除半消息
LocalTransactionState.UNKNOW
暂时为未知状态,等待broker回查
如果让你来动手实现一个分布式消息中间件,整体架构你会如何设计实现?
看过RocketMQ 的源码没有。如果看过,说说你对RocketMQ 源码的理解?
高吞吐量下如何优化生产者和消费者的性能?
消费
-
同一group下,多机部署,并行消费
-
单个consumer提高消费线程个数
-
批量消费
- 消息批量拉取
- 业务逻辑批量处理
运维
- 网卡调优
- jvm调优
- 多线程与cpu调优
- Page Cache
再说说RocketMQ 是如何保证数据的高容错性的?
- 在不开启容错的情况下,轮询队列进行发送,如果失败了,重试的时候过滤失败的Broker
- 如果开启了容错策略,会通过RocketMQ的预测机制来预测一个Broker是否可用
- 如果上次失败的Broker可用那么还是会选择该Broker的队列
- 如果上述情况失败,则随机选择一个进行发送
- 在发送消息的时候会记录一下调用的时间与是否报错,根据该时间去预测broker的可用时间