Spark Core随笔
Spark Core随笔
第一章 SparkCore概述
1.1 概念
Spark是一种基于内存的快速、通用、可扩展的大数据的分析计算引擎。
1.2 Spark & Flink
Spark : 主要适用于离线计算业务中
Flink : 主要适用于实时计算业务中
1.3 Spark & Hadoop
出现的时机:Hadoop1.x ~ Hadoop2.x
| Hadoop | Spark | |
|---|---|---|
| 典型 | 基础平台,包含计算,存储调度 | 分布式计算工具 |
| 场景 | 大规模数据集的批处理 | 迭代计算,交互式计算,流计算 |
| 延迟 | 大 | 小 |
| 易用性 | API较为底层,算法适用性差 | API较为顶层,方便使用 |
| 价格 | 对机器要求低,便宜 | 堆内存有要求,相对较贵 |
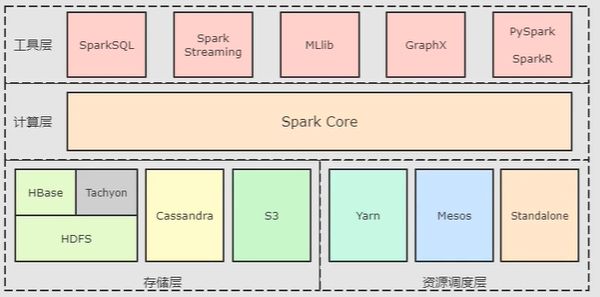
1.4 Spark 核心模块
第二章 快速入门
2.1 经典案例:WordCount
步骤1 :maven 环境搭建【配置spark】
org.apache.spark
spark-core_2.12
3.0.0
步骤2 :配置log4j.properties
在resources目录下创建log4j.properties文件
log4j.rootCategory=ERROR, console
log4j.appender.console=org.apache.log4j.ConsoleAppender
log4j.appender.console.target=System.err
log4j.appender.console.layout=org.apache.log4j.PatternLayout
log4j.appender.console.layout.ConversionPattern=%d{yy/MM/dd HH:mm:ss} %p %c{1}: %m%n
# Set the default spark-shell log level to ERROR. When running the spark-shell, the
# log level for this class is used to overwrite the root logger's log level, so that
# the user can have different defaults for the shell and regular Spark apps.
log4j.logger.org.apache.spark.repl.Main=ERROR
# Settings to quiet third party logs that are too verbose
log4j.logger.org.spark_project.jetty=ERROR
log4j.logger.org.spark_project.jetty.util.component.AbstractLifeCycle=ERROR
log4j.logger.org.apache.spark.repl.SparkIMain$exprTyper=ERROR
log4j.logger.org.apache.spark.repl.SparkILoop$SparkILoopInterpreter=ERROR
log4j.logger.org.apache.parquet=ERROR
log4j.logger.parquet=ERROR
# SPARK-9183: Settings to avoid annoying messages when looking up nonexistent UDFs in SparkSQL with Hive support
log4j.logger.org.apache.hadoop.hive.metastore.RetryingHMSHandler=FATAL
log4j.logger.org.apache.hadoop.hive.ql.exec.FunctionRegistry=ERROR
步骤3-1 : 代码【使用scala】
package com.heather.bigdata.spark.core.wc
import org.apache.spark.api.java.JavaSparkContext.fromSparkContext
import org.apache.spark.rdd.RDD
import org.apache.spark.{
SparkConf, SparkContext}
/**
* @Author Qi Shiwei
* @Date 2021-03-10 - 上午 10:08
* @Desc
*/
object Spark01_WordCount {
def main(args: Array[String]): Unit = {
// TODO 1. 建立Spark引擎的连接对象:SparkContext
// 创建Spark运行配置对象
val conf: SparkConf = new SparkConf().setMaster("local").setAppName("WordCount")
// val conf: SparkConf = new SparkConf().setMaster("local[*]").setAppName("WordCount")
val context:SparkContext = new SparkContext(conf)
// TODO 2. 数据的统计分析
// 2.1 读取数据源,获取原始数据【从文件中】 line , line , line , ...
val lines = context.textFile("data/word.txt")
lines.foreach(println)
// 2.2 将原始数据进行切分,形成一个一个单词 line => List(word,word,word...)
val words = lines.flatMap(line => line.split(" "))
words.foreach(println)
// 2.3 将数据根据单词进行分组
val groupWord: RDD[(String, Iterable[String])] = words.groupBy(word => word)
groupWord.foreach(println)
// 2.4 将分组后的单词进行分析 word => n
val wordCount: RDD[(String, Int)] = groupWord.map {
case (word, list) => {
(word, list.size)
}
}
// 2.5 将统计分析的结果输出到控制台
// wordCount.collect() : 将数据采集到内存中
println("最终结果:")
wordCount.collect().foreach(println)
// TODO 3. 释放Spark资源
context.stop()
}
}
步骤3-2 : 代码【使用spark】
package com.heather.bigdata.spark.core.wc
import org.apache.spark.rdd.RDD
import org.apache.spark.{
SparkConf, SparkContext}
/**
* @Author Qi Shiwei
* @Date 2021-03-10 - 上午 10:08
* @Desc
*/
object Spark03_WordCount {
def main(args: Array[String]): Unit = {
// TODO 1. 建立Spark引擎的连接
val conf: SparkConf = new SparkConf().setMaster("local").setAppName("WordCount")
val context = new SparkContext(conf)
// TODO 2. 数据的统计分析
// 2.1 读取数据源,获取原始数据【从文件中】 line , line , line , ...
val lines = context.textFile("data/word.txt")
// lines.foreach(println)
// 2.2 将原始数据进行切分,形成一个一个单词 line => List(word,word,word...)
val words = lines.flatMap(line => line.split(" "))
// words.foreach(println)
val wordToOne: RDD[(String, Int)] = words.map(
word => (word, 1)
)
// wordToOne.foreach(println)
// Spark提供了特殊的方法可以对分组聚合的操作进行操作 - reduceByKey
// reduceByKey : 数据处理中,如果有相同的Key,那么会对同样的Key的Value进行reduce聚合
// reduceByKey操作对数据有要求,要求数据必须是k-v的键值对。
val wordCount: RDD[(String, Int)] = wordToOne.reduceByKey(_ + _)
// 2.5 将统计分析的结果输出到控制台
wordCount.collect().foreach(println)
// TODO 3. 释放Spark资源
context.stop()
}
}
第三章 Spark运行环境
3.1 Local 模式
我们一般称Local模式为单机模式,就是不需要其他任何节点资源就可以在本地执行Spark代码的环境,一般用于教学,调试,演示等。
示意图:

3.1.1 上传资源
将spark-3.0.0-bin-hadoop3.2.tgz文件上传到Linux并解压缩,放置在指定位置,路径中不要包含中文或空格
tar -zxvf spark-3.0.0-bin-hadoop3.2.tgz -C /opt/module
cd /opt/module
mv spark-3.0.0-bin-hadoop3.2 spark-local
3.1.2 启动Local模式
-
进入解压后的Spark目录,执行bin/spark-shell命令,出现以下Spark欢迎界面表示登录启动成功

-
启动成功后可以使用浏览器输入网址进行Web UI监控页面进行访问
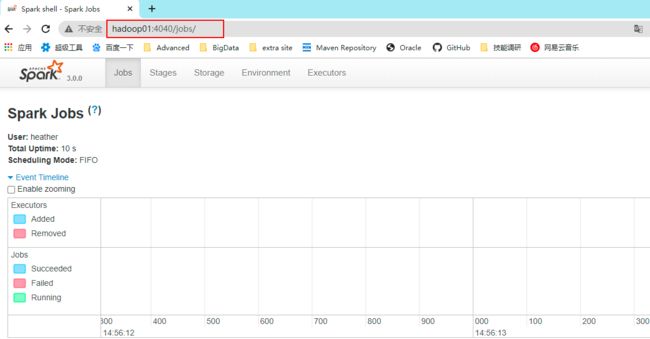
3.1.3 命令行工具
在解压缩文件夹下的data目录中,添加word.txt文件。在命令行工具中执行如下代码指令(和IDEA中代码简化版一致)
sc.textFile("data/word.txt").flatMap(_.split(" ")).map((_,1)).reduceByKey(_+_).collect
![]()
3.1.4 退出本地模式
按键Ctrl+C或输入Scala指令【:quit】
3.1.5 提交应用(***)
提交任务命令: Spark示例 - 计算圆周率
bin/spark-submit \
--class org.apache.spark.examples.SparkPi \
--master local[2] \
./examples/jars/spark-examples_2.12-3.0.0.jar \
10
命令详解:
1) --class表示要执行程序的主类,此处可以更换为咱们自己写的应用程序
2) --master local[2] 部署模式,默认为本地模式,数字表示分配的虚拟CPU核数量
3) spark-examples_2.12-3.0.0.jar 运行的应用类所在的jar包,实际使用时,可以设定为咱们自己打的jar包
4) 数字10表示程序的入口参数,用于设定当前应用的任务数量

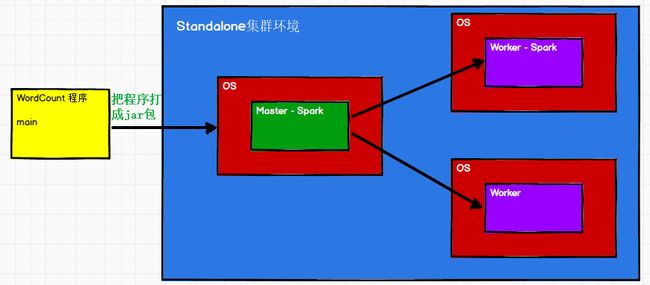
3.2 Standalone模式
local本地模式毕竟只是用来进行练习演示的,真实工作中还是要将应用提交到对应的集群中去执行,这里我们来看看只使用Spark自身节点运行的集群模式,也就是我们所谓的独立部署(Standalone)模式。Spark的Standalone模式体现了经典的master-slave模式。
示意图:
集群规划:
| hadoop01 | hadoop02 | hadoop03 | |
|---|---|---|---|
| Spark | Master [Worker] | Worker | Worker |
3.2.1 解压文件
重新解压文件在指定位置并修改文件名
tar -zxvf spark-3.0.0-bin-hadoop3.2.tgz -C /opt/module
cd /opt/module
mv spark-3.0.0-bin-hadoop3.2 spark-standalone
3.2.2 修改配置文件
- 进入解压缩后路径的conf目录,修改slaves.template文件名为slaves
[heather@hadoop01 conf]$ mv slaves.template slaves
- 修改slaves文件,添加worker节点
hadoop01
hadoop02
hadoop03
- 修改spark-env.sh.template文件名为spark-env.sh
[heather@hadoop01 conf]$ mv spark-env.sh.template spark-evn.sh
查看当前文件夹中文件:
[heather@hadoop01 conf]$ ll
总用量 36
-rw-r--r--. 1 heather heather 1105 6月 6 2020 fairscheduler.xml.template
-rw-r--r--. 1 heather heather 2023 6月 6 2020 log4j.properties.template
-rw-r--r--. 1 heather heather 9141 6月 6 2020 metrics.properties.template
-rw-r--r--. 1 heather heather 865 6月 6 2020 slaves
-rw-r--r--. 1 heather heather 1292 6月 6 2020 spark-defaults.conf.template
-rwxr-xr-x. 1 heather heather 4344 6月 6 2020 spark-evn.sh
-
修改spark-env.sh文件,添加JAVA_HOME环境变量和集群对应的master节点
注意:7077端口,相当于hadoop3内部通信的8020端口,此处的端口需要确认自己的Hadoop配置
# 在spark中配置Java的环境变量
export JAVA_HOME=/opt/module/jdk/jdk1.8.0_212
# 配置spark集群的主节点地址
SPARK_MASTER_HOST=hadoop01
# 配置spark集群的内部通信协议地址
SPARK_MASTER_PORT=7077
-
分发spark-standalone目录
注意:要在spark-standalone父目录下执行此命令
[heather@hadoop01 module]$ rsync.sh spark-standalone/
3.2.3 启动集群
- 执行脚本命令
[heather@hadoop01 spark-standalone]$ sbin/start-all.sh
- 查看三台服务器运行进程
[heather@hadoop01 spark-standalone]$ myjps.sh
==============hadoop01===============
1968 Worker
2048 Jps
1864 Master
==============hadoop02===============
1185 Worker
1262 Jps
==============hadoop03===============
1259 Jps
1180 Worker
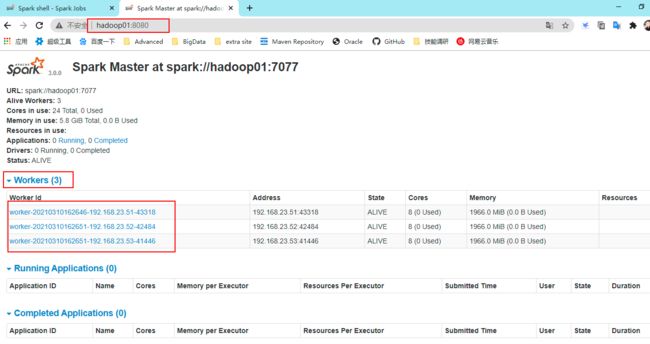
- 查看Master资源监控Web UI界面: http://hadoop01:8080
3.2.4 提交应用(***)
提交任务命令: Spark示例 - 计算圆周率
bin/spark-submit \
--class org.apache.spark.examples.SparkPi \
--master spark://hadoop01:7077 \
./examples/jars/spark-examples_2.12-3.0.0.jar \
10
命令详解:
1) --class表示要执行程序的主类
2) --master spark://linux1:7077 独立部署模式,连接到Spark集群
3) spark-examples_2.12-3.0.0.jar 运行类所在的jar包
4) 数字10表示程序的入口参数,用于设定当前应用的任务数量
[heather@hadoop01 spark-standalone]$ bin/spark-submit \
> --class org.apache.spark.examples.SparkPi \
> --master spark://hadoop01:7077 \
> ./examples/jars/spark-examples_2.12-3.0.0.jar \
> 10
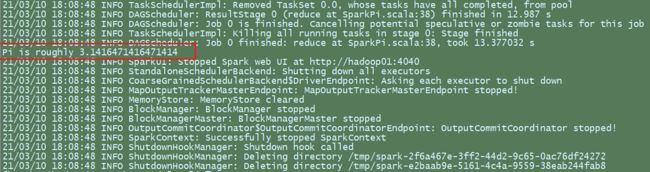
在执行命令时,会产生多个Java进程
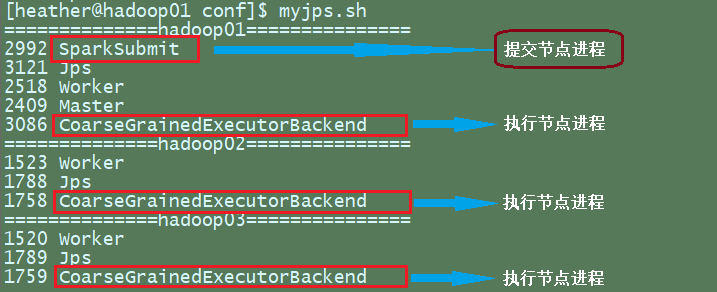
执行任务时,默认采用服务器集群节点的总核数。
3.2.5 提交参数的说明
在提交应用中,一般会同时一些提交参数
bin/spark-submit \
--class <main-class>
--master <master-url> \
... # other options
<application-jar> \
[application-arguments]
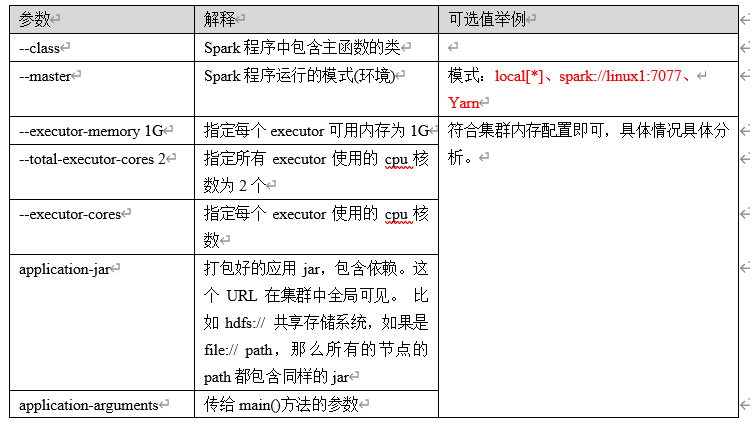
3.2.6 配置历史服务器
由于spark-shell停止掉后,集群监控hadoop01:4040页面就看不到历史任务的运行情况,所以开发时都配置历史服务器记录任务运行情况。
- 修改 spark-default.conf.template 文件名为spark-default.conf
mv spark-defaults.conf.template spark-defaults.conf
-
修改 spark-default.conf,配置日志存储路径
注意:需要启动hadoop集群,保证HDFS上的directory目录存在。【hadoop fs -mkdir /directory】
并且还要保证和hadoop的端口号一直
spark.eventLog.enabled true
spark.eventLog.dir hdfs://hadoop01:8020/directory
- 修改 spark-env.sh 文件,添加日志配置
export SPARK_HISTORY_OPTS="
# 历史服务器端口
-Dspark.history.ui.port=18080
-Dspark.history.fs.logDirectory=hdfs://hadoop01:8020/directory
-Dspark.history.retainedApplications=30"
- 参数1含义:WEB UI访问的端口号为18080
- 参数2含义:指定历史服务器日志存储路径
- 参数3含义:指定保存Application历史记录的个数,如果超过这个值,旧的应用程序信息将被删除,这个是内存
- 分发配置文件
[heather@hadoop01 module]$ rsync.sh spark-standalone/
- 重新启动集群
[heather@hadoop01 spark-standalone]$ sbin/start-all.sh
- 启动历史服务
[heather@hadoop01 spark-standalone]$ sbin/start-history-server.sh
- 重新执行任务
[heather@hadoop01 spark-standalone]$ bin/spark-submit \
--class org.apache.spark.examples.SparkPi \
--master spark://hadoop01:7077 \
./examples/jars/spark-examples_2.12-3.0.0.jar \
10

- 查看历史服务:http://hadoop01:18080
3.27 搭建高可用HA
所谓的高可用是因为当前集群中的Master节点只有一个,所以会存在单点故障问题。所以为了解决单点故障问题,需要在集群中配置多个Master节点,一旦处于活动状态的Master发生故障时,由备用Master提供服务,保证作业可以继续执行。这里的高可用一般采用Zookeeper设置
集群规划:
| hadoop01 | hadoop02 | hadoop03 | |
|---|---|---|---|
| Spark | zookeepr Master Worker |
zookeepr Master Worker |
zookeeper Worker |
- 停止当前集群 和 历史服务器
[heather@hadoop01 spark-standalone]$ sbin/stop-all.sh
[heather@hadoop01 spark-standalone]$ sbin/stop-history-server.sh
- 启动zookeeper
[heather@hadoop01 ~]$ zk.sh start
- 修改spark-env.sh文件添加如下配置
# 在spark中配置Java的环境变量
export JAVA_HOME=/opt/module/jdk/jdk1.8.0_212
# 注释如下内容
# 配置spark集群的主节点地址【HA高可用集群不需要】
# SPARK_MASTER_HOST=hadoop01
# 配置spark集群的内部通信协议地址【HA高可用集群不需要】
# SPARK_MASTER_PORT=7077
#Master监控页面默认访问端口为8080,但是可能会和Zookeeper冲突,所以改成8989,也可以自定义,访问UI监控页面时请注意
SPARK_MASTER_WEBUI_PORT=8989
export SPARK_DAEMON_JAVA_OPTS="
-Dspark.deploy.recoveryMode=ZOOKEEPER
-Dspark.deploy.zookeeper.url=hadoop01,hadoop02,hadoop03
-Dspark.deploy.zookeeper.dir=/spark"
# 配置历史服务器
export SPARK_HISTORY_OPTS="
-Dspark.history.ui.port=18080
-Dspark.history.fs.logDirectory=hdfs://hadoop01:8020/directory
-Dspark.history.retainedApplications=30"
- 分发配置文件
[heather@hadoop01 module]$ rsync.sh spark-standalone/
- 启动集群
[heather@hadoop01 spark-standalone]$ sbin/start-all.sh
查看进程:
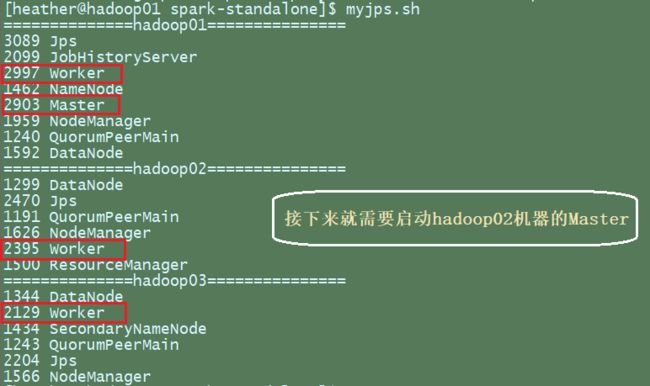
- 启动hadoop02的单独Master节点,此时hadoop02节点Master状态处于备用状态
[heather@hadoop02 spark-standalone]$ sbin/start-master.sh
查看进程:
- 提交应用到高可用集群
bin/spark-submit \
--class org.apache.spark.examples.SparkPi \
--master spark://hadoop01:7077,hadoop02:7077 \
./examples/jars/spark-examples_2.12-3.0.0.jar \
10
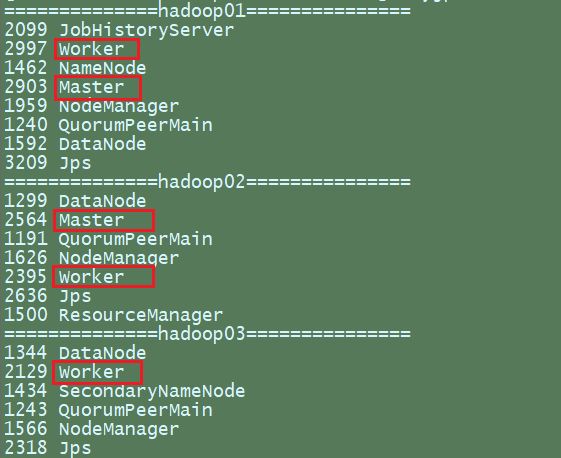
- 停止hadoop01 的Master资源监控进程
[heather@hadoop01 spark-standalone]$ kill -9 2997
- 查看hadoop02 的Master资源监控Web UI ,稍等一段时间后,hadoop02节点的Master状态提升为活动状态
3.3 Yarn模式
独立部署(Standalone)模式由Spark自身提供计算资源,无需其他框架提供资源。这种方式降低了和其他第三方资源框架的耦合性,独立性非常强。但是你也要记住,Spark主要是计算框架,而不是资源调度框架,所以本身提供的资源调度并不是它的强项,所以还是和其他专业的资源调度框架集成会更靠谱一些。所以接下来我们来认识一下在强大的Yarn环境下Spark是如何工作的(其实是因为在国内工作中,Yarn使用的非常多)。
示意图:
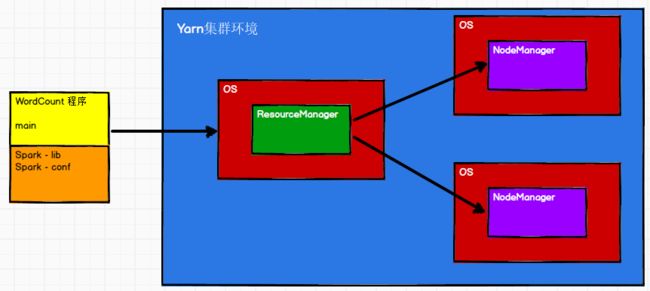
3.3.1 解压文件
重新解压文件在指定位置并修改文件名
tar -zxvf spark-3.0.0-bin-hadoop3.2.tgz -C /opt/module
cd /opt/module
mv spark-3.0.0-bin-hadoop3.2 spark-yarn
3.3.2 修改配置文件
- 修改hadoop配置文件/opt/module/hadoop/etc/hadoop/yarn-site.xml, 并分发
# 添加一下内容
<!--是否启动一个线程检查每个任务正使用的物理内存量,如果任务超出分配值,则直接将其杀掉,默认是true -->
<property>
<name>yarn.nodemanager.pmem-check-enabled</name>
<value>false</value>
</property>
<!--是否启动一个线程检查每个任务正使用的虚拟内存量,如果任务超出分配值,则直接将其杀掉,默认是true -->
<property>
<name>yarn.nodemanager.vmem-check-enabled</name>
<value>false</value>
</property>
- 修改conf/spark-env.sh,添加JAVA_HOME和YARN_CONF_DIR配置
#先修改文件名:
mv spark-env.sh.template spark-env.sh
#向文件中添加以下内容
export JAVA_HOME=/opt/module/jdk/jdk1.8.0_212
YARN_CONF_DIR=/opt/module/hadoop/hadoop-3.1.3/etc/hadoop
3.3.3 启动Hdfs 以及 Yarn集群
[heather@hadoop01 module]$ mycluster.sh start
3.3.4 提交应用
bin/spark-submit \
--class org.apache.spark.examples.SparkPi \
--master yarn \
--deploy-mode cluster \
./examples/jars/spark-examples_2.12-3.0.0.jar \
10

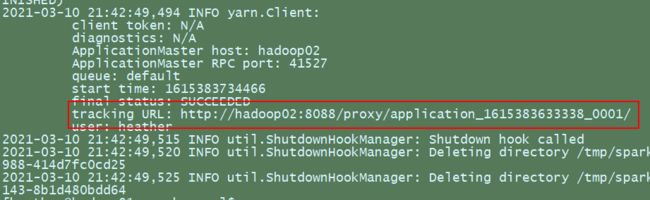
访问http://hadoop02:8088页面,点击History,查看历史页面。
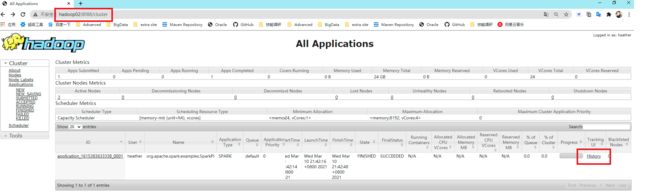
详细任务列表:

3.3.5 配置历史服务器
- 修改spark-defaults.conf.template 文件名为spark-defaults.conf
mv spark-defaults.conf.template spark-defaults.conf
- 修改spark-defaults.conf文件,配置日志存储路径
注意:需要启动hadoop集群,HDFS上的目录需要提前存在。
spark.eventLog.enabled true
spark.eventLog.dir hdfs://hadoop01:8020/directory
- 修改spark-env.sh文件, 添加日志配置
export SPARK_HISTORY_OPTS="
-Dspark.history.ui.port=18080
-Dspark.history.fs.logDirectory=hdfs://hadoop01:8020/directory
-Dspark.history.retainedApplications=30"
- 参数1含义:WEB UI访问的端口号为18080
- 参数2含义:指定历史服务器日志存储路径
- 参数3含义:指定保存Application历史记录的个数,如果超过这个值,旧的应用程序信息将被删除,这个是内存中的应用数,而不是页面上显示的应用数。
- 修改spark-defaults.conf,添加以下内容
# 把hadoop中的历史服务器和spark中的历史服务器相关联
spark.yarn.historyServer.address=hadoop01:18080
spark.history.ui.port=18080
- 启动spark 和历史服务
[heather@hadoop01 spark-yarn]$ sbin/start-all.sh
[heather@hadoop01 spark-yarn]$ sbin/start-history-server.sh
- 重新提交应用
bin/spark-submit \
--class org.apache.spark.examples.SparkPi \
--master yarn \
--deploy-mode client \
./examples/jars/spark-examples_2.12-3.0.0.jar \
10
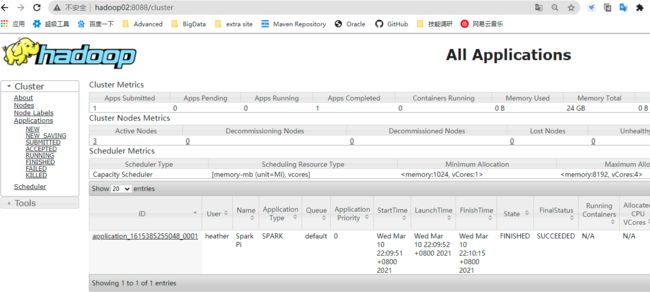
- Web页面查看日志:http://hadoop02:8088
3.4 部署模式对比
| 模式 | Spark安装机器数量 | 需启动的进程 | 所属者 | 应用场景 |
|---|---|---|---|---|
| Local | 1 | 无 | Spark | 测试 |
| Standalone | 3 | Master及Worker | Spark | 单独部署 |
| Yarn | 1 | Yarn及Hdfs | Hadoop | 混合部署 |
3.5 端口号
Ø Spark查看当前Spark-shell运行任务情况端口号:4040(计算)
Ø Spark Master内部通信服务端口号:7077
Ø Standalone模式下,Spark Master Web端口号:8080(资源)
Ø Spark历史服务器端口号:18080
Ø Hadoop YARN任务运行情况查看端口号:8088
第四章 Spark运行架构
4.1 Spark各组件之间的关系

4.2 运行架构
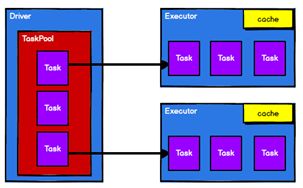
Spark框架的核心是一个计算引擎,整体来说,它采用了标准 master-slave 的结构。
如下图所示,它展示了一个 Spark执行时的基本结构。
图形中的Driver表示master,负责管理整个集群中的作业任务调度。
图形中的Executor表示slave,负责实际执行任务。
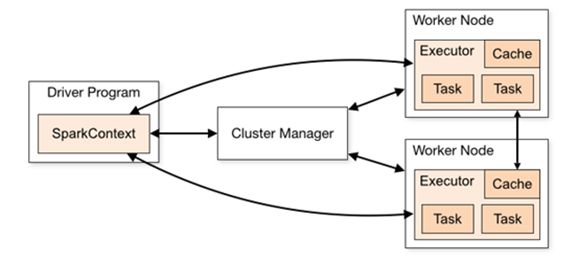
4.3 核心组件
由上图可以看出,对于Spark框架有两个核心组件:
Driver = Master
Executor = Salve
4.3.1 Driver
Spark驱动器节点,用于执行Spark任务中的main方法,负责实际代码的执行工作。Driver在Spark作业执行时主要负责:
- 将用户程序转化为作业(job)
- 在Executor之间调度任务(task)
- 跟踪Executor的执行情况
- 通过UI展示查询运行情况
实际上,我们无法准确地描述Driver的定义,因为在整个的编程过程中没有看到任何有关Driver的字眼。所以简单理解,所谓的Driver就是驱使整个应用运行起来的程序,也称之为Driver类。
4.3.2 Executor
Spark Executor是集群中工作节点(Worker)中的一个JVM进程,负责在 Spark 作业中运行具体任务(Task),任务彼此之间相互独立。Spark 应用启动时,Executor节点被同时启动,并且始终伴随着整个 Spark 应用的生命周期而存在。如果有Executor节点发生了故障或崩溃,Spark 应用也可以继续执行,会将出错节点上的任务调度到其他Executor节点上继续运行。
Executor有两个核心功能:
- 负责运行组成Spark应用的任务,并将结果返回给驱动器进程
- 它们通过自身的块管理器(Block Manager)为用户程序中要求缓存的 RDD 提供内存式存储。RDD 是直接缓存在Executor进程内的,因此任务可以在运行时充分利用缓存数据加速运算。
4.4 核心概念
4.4.1 Executor与Core(核)
Spark Executor是集群中运行在工作节点(Worker)中的一个JVM进程,是整个集群中的专门用于计算的节点。在提交应用中,可以提供参数指定计算节点的个数,以及对应的资源。这里的资源一般指的是工作节点Executor的内存大小和使用的虚拟CPU核(Core)数量。
应用程序相关启动参数如下:
| 名称 | 说明 |
|---|---|
| –num-executors | 配置Executor的数量 |
| –executor-memory | 配置每个Executor的内存大小 |
| –executor-cores | 配置每个Executor的虚拟CPU core数量 |
4.4.2 并行度(Parallelism)
在分布式计算框架中一般都是多个任务同时执行,由于任务分布在不同的计算节点进行计算,所以能够真正地实现多任务并行执行,记住,这里是并行,而不是并发。这里我们将整个集群并行执行任务的数量称之为并行度。那么一个作业到底并行度是多少呢?这个取决于框架的默认配置。应用程序也可以在运行过程中动态修改。
4.4.3 有向无环图(DAG)
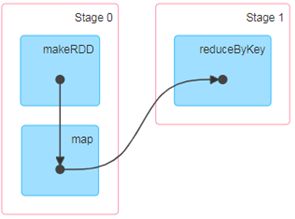
有向无环图详解:
有向:有方向
无环:没有形成环状【有环就是死循环,在实际中是不允许出现有环的,有环就没有出口】
典型应用:Maven不运行循环依赖,会报错
大数据计算引擎框架我们根据使用方式的不同一般会分为四类,其中第一类就是Hadoop所承载的MapReduce,它将计算分为两个阶段,分别为 Map阶段 和 Reduce阶段。对于上层应用来说,就不得不想方设法去拆分算法,甚至于不得不在上层应用实现多个 Job 的串联,以完成一个完整的算法,例如迭代计算。 由于这样的弊端,催生了支持 DAG 框架的产生。因此,支持 DAG 的框架被划分为第二代计算引擎。如 Tez 以及更上层的 Oozie。这里我们不去细究各种 DAG 实现之间的区别,不过对于当时的 Tez 和 Oozie 来说,大多还是批处理的任务。接下来就是以 Spark 为代表的第三代的计算引擎。第三代计算引擎的特点主要是 Job 内部的 DAG 支持(不跨越 Job),以及实时计算。
这里所谓的有向无环图,并不是真正意义的图形,而是由Spark程序直接映射成的数据流的高级抽象模型。简单理解就是将整个程序计算的执行过程用图形表示出来,这样更直观,更便于理解,可以用于表示程序的拓扑结构。
DAG(Directed Acyclic Graph)有向无环图是由点和线组成的拓扑图形,该图形具有方向,不会闭环。
4.4.4 提交流程
所谓的提交流程,其实就是我们开发人员根据需求写的应用程序通过Spark客户端提交给Spark运行环境执行计算的流程。在不同的部署环境中,这个提交过程基本相同,但是又有细微的区别,我们这里不进行详细的比较,但是因为国内工作中,将Spark引用部署到Yarn环境中会更多一些,所以本课程中的提交流程是基于Yarn环境的。
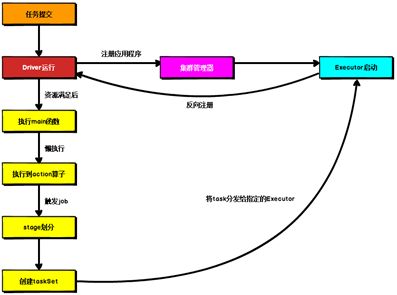
Spark应用程序提交到Yarn环境中执行的时候,一般会有两种部署执行的方式:Client和Cluster。两种模式主要区别在于:Driver程序的运行节点位置。
第五章 Spark核心编程
Spark计算框架为了能够进行高并发和高吞吐的数据处理,封装了三大数据结构,用于处理不同的应用场景。三大数据结构分别是:
Ø RDD : 弹性分布式数据集
Ø 累加器:分布式共享只写变量
Ø 广播变量:分布式共享只读变量
5.0 数据结构
数据结构 : 组织和关联数据的一种结构
比如:数组、链表、栈 . . .
5.1 隐式转换 & 模式匹配
隐式转换 和 模式匹配本是Scala中的技能点,在这儿属于旧事重提,就是因为重要!!!
5.1.1 隐式转换
两种方式:
- 编译器进行自动类型转换
- 由精度小的数据自动转换为精度大的数据
- 特殊的方式 String —> StringOps
- Scala在程序编译错误时,可以通过隐式转换中类型转换机制尝试进行二次编译,将本身错误无法编译通过的代码通过类型转换后编译通过。慢慢地,这也形成了一种扩展功能的转换机制。
下面对这两种方式分别进行演示。
自动类型转换
第一种方式 - 1:
def main(args: Array[String]): Unit = {
var b : Byte = 3
var a : Int = b
var d : Double = a
println(a)
println(d)
}
第一种方式 - 2:
Scala 中没有字符串类,字符串来自java,但是java的字符串并没有apply()方法,那么下面的代码就有问题!
val str = "abc"
val res = s.apply(0) // s.apply(0)通常写成 : s(0)
println(res)
// 输出结果:a
代码解析:
编译器在编译的过程中,将字符串转换成了Scala语言的StringOps类,所以就有了apply()方法,这个转换的过程也是隐式转换,需要特别注意!!!
二次编译
当程序出现编译错误的时候,编译器会尝试在整个的作用域范围内,查找能够让当前的错误编译通过的转换逻辑,这种方式就是二次编译,通常用于功能的增强,避免违反程序开发中的OCP原则 。
使用方式,在转换逻辑前使用关键字implicit让编译器识别 !
第二种方式 - 1 :
def main(args: Array[String]): Unit = {
// 重新写的转换逻辑【把Double 转换为 Int】
// 但是当我们定义后,以前报错的代码仍然无法解决,此时,我们只需要在转换逻辑前增加关键implicit即可
implicit def transform(n : Double) : Int = {
n.toInt
}
// 使用第三方的业务
// 当第三方业务修改后,本地受到影响,出现编译报错,但是我们又不能修改代码,那样就违反了开发的OCP原则
// 因此我们最好的做法就是再重新写一套转换逻辑,让本地编译报错的现象通过转换进行解决
// 解析:本地代码编译报错后,自动会从环境的上下文中寻找可以进行转换的逻辑,只需要implict,编译器可以自动识别
val age: Int = thirdPar_Age()
println(age)
}
// 第三方的业务
// 后期第三方的业务进行修改,把返回值类型由Int修改为Double
def thirdPar_Age() : Double ={
//Int = {
//30
30.5
}
第二种方式 - 2 :
def main(args: Array[String]): Unit = {
// TODO User类中只有一个新增功能,但是后期想增加一个修改的功能
/*
处于OCP原则的约束,我们不可以直接在User类中定义“修改”的方法
所以,我们可以新定义一个类,在类中定义“修改”的方法
但是,此时本类不能够直接调用“修改”的方法,需要新创建对象
此时,我们就可以在本类新增加一段逻辑转换代码,把User类转换为UserExt类,并且使用关键字imlicit定义
*/
implicit def transform1(user: User): UserExt = {
new UserExt
}
implicit def transform2(user: String): UserExt = {
new UserExt
}
// TODO 隐式转换 => 二次编译
// 隐式转换是在编译出现错误时执行的。
// 同一个作用域中,有相同的转换规则,那么编译器不知道用哪一个,所以会报错
// 隐式转换其实就是类型的转换,所以转换时,隐式函数中参数只有一个,就是需要被转换的类型
val user = thirdPart_User();
user.updateUser() //
user.insertUser()
}
class UserExt {
def updateUser(): Unit = {
println("update user...")
}
}
class User {
def insertUser(): Unit = {
println("insert user...")
}
}
def thirdPart_User() = {
new User()
}
5.1.2 模式匹配
5.2 RDD
5.1.1 什么是RDD
RDD(Resilient Distributed Dataset)叫做弹性分布式数据集,是Spark中最基本的数据处理模型。代码中是一个抽象类,它代表一个弹性的、不可变【计算逻辑不可变】、可分区、里面的元素可并行计算的集合。
- 弹性
-
存储的弹性:内存与磁盘的自动切换;
-
容错的弹性:数据丢失可以自动恢复;
-
计算的弹性:计算出错重试机制;
-
分片的弹性:可根据需要重新分片。
【 存在数据分区的概念,处理的数据会根据规则放置在不同过的分区中,然后发给不同节点进行计算】
-
- 分布式:数据存储在大数据集群不同节点上
- 数据集:RDD封装了计算逻辑,并不保存数据
- 数据抽象:RDD是一个抽象类,需要子类具体实现
- 不可变:RDD封装了计算逻辑,是不可以改变的,想要改变,只能产生新的RDD,在新的RDD里面封装计算逻辑【程序中的最小执行单元,可重复使用】
- 可分区、并行计算【makeRDD这个方法可以设置分区数量】
5.1.2 核心属性
在内部,每个RDD有五个主要属性:
- 分区列表
RDD数据结构中存在分区列表,用于执行任务时并行计算,是实现分布式计算的重要属性。
- 计算每个分割的函数
Spark在计算时,是使用分区函数对每一个分区进行计算
- 对其他rdd的依赖列表
RDD是计算模型的封装,当需求中需要将多个计算模型进行组合时,就需要将多个RDD建立依赖关系
- 可选,一个key-value RDD的分区程序(例如,说这个RDD是哈希分区的)
当数据为KV类型数据时,可以通过设定分区器自定义数据的分区
- 可选,计算每个拆分的首选位置列表(例如,HDFS文件的块位置)
计算数据时,可以根据计算节点的状态选择不同的节点位置进行计算
5.1.3 执行原理
和IO的执行原理一样,都是使用了“装饰者设计模式”进行设计,把功能组合在一起,进行功能的扩展。两者都是属于延迟加载数据。
通过简单的WordCout的代码和示例图了解RDD的执行原理
val wordCount: RDD[(String, Int)] = context.textFile("data/word.txt") .flatMap(line => line.split(" ")) .map( word => (word, 1) ).reduceByKey(_ + _) wordCount.collect().foreach(println)

从计算的角度来讲,数据处理过程中需要计算资源(内存 & CPU)和计算模型(逻辑)。执行时,需要将计算资源和计算模型进行协调和整合。
Spark框架在执行时,先申请资源,然后将应用程序的数据处理逻辑分解成一个一个的计算任务。然后将任务发到已经分配资源的计算节点上, 按照指定的计算模型进行数据计算。最后得到计算结果。
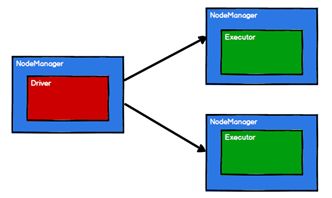
RDD是Spark框架中用于数据处理的核心模型,接下来我们看看,在Yarn环境中,RDD的工作原理:
- 启动Yarn集群环境

- Spark通过申请资源创建调度节点和计算节点
- Spark框架根据需求将计算逻辑根据分区划分成不同的任务
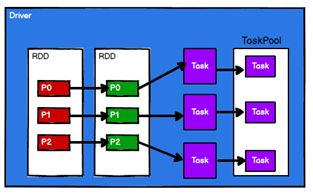
- 调度节点将任务根据计算节点状态发送到对应的计算节点进行计算
5.1.4 基础编程
5.1.4.1 RDD创建
在Spark中创建RDD的创建方式可以分为四种:
从集合(内存)中创建RDD
从外部存储(文件)创建RDD
从其他RDD创建
直接创建RDD(new)
1. 从内存中创建RDD
从集合中创建RDD,Spark主要提供了两个方法:parallelize和makeRDD
object Scala01_Instance_Memory {
def main(args: Array[String]): Unit = {
// TODO 建立Spark引擎的连接对象
val conf: SparkConf = new SparkConf().setMaster("local").setAppName("Instance")
val sc = new SparkContext(conf)
// TODO RDD创建 - 从内存中
val seq = Seq(1, 2, 3, 4)
// parallelize : 并行执行
val rdd: RDD[Int] = sc.parallelize(seq)
// 推荐此用法,底层同样调用parallelize()方法
val rdd1: RDD[Int] = sc.makeRDD(seq)
rdd.collect().foreach(println)
println("*" * 15)
rdd1.collect().foreach(println)
sc.stop()
}
}
从底层代码实现来讲,makeRDD方法其实就是parallelize方法
def makeRDD[T: ClassTag](
seq: Seq[T],
numSlices: Int = defaultParallelism): RDD[T] = withScope {
parallelize(seq, numSlices)
}
2. 从文件中创建RDD
从磁盘创建对象,Spark主要提供了一个方法:textFile()
由外部存储系统的数据集创建RDD包括:本地的文件系统,所有Hadoop支持的数据集,比如HDFS、HBase
object Scala01_Instance_Disk {
def main(args: Array[String]): Unit = {
// TODO 建立Spark引擎的连接对象
val conf: SparkConf = new SparkConf().setMaster("local").setAppName("Instance")
val sc = new SparkContext(conf)
// TODO RDD创建 - 从磁盘文件中 - 此种方式在读取文件时,以“行”为单位进行读取
// 文件路径可以是具体的文件路径,也可以是目录的路径
// val rdd1: RDD[String] = sc.textFile("data/word.txt")
val rdd2: RDD[String] = sc.textFile("data")
// 也可以使用通配符进行读取
// val rdd3: RDD[String] = sc.textFile("data/test*.txt")
// 如果想要读取数据所在的文件相关属性,需要使用wholeTextFiles()方法
// 此方法的返回值结果是 K-V键值对【key是文件的路径,value是文件的内容】
val rdd4: RDD[(String, String)] = sc.wholeTextFiles("data/word.txt")
rdd4.collect().foreach(println)
sc.stop()
}
}
5.1.4.2 RDD并行度与分区
默认情况下,Spark可以将一个作业切分多个任务后,发送给Executor节点并行计算,而能够并行计算的任务数量我们称之为并行度。这个数量可以在构建RDD时指定。记住,这里的并行执行的任务数量,并不是指的切分任务的数量,不要混淆了。
1. 基于内存的创建的RDD的分区数设定
package com.heather.spark.core.rdd.instance
import org.apache.spark.rdd.RDD
import org.apache.spark.{
SparkConf, SparkContext}
/**
* @Author Qi Shiwei
* @Date 2021-03-12 - 上午 09:56
* @Desc
*/
object Spark01_Instance_Memory_Par {
def main(args: Array[String]): Unit = {
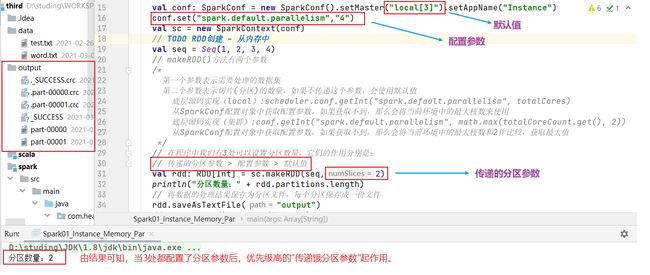
val conf: SparkConf = new SparkConf().setMaster("local[3]").setAppName("Instance")
conf.set("spark.default.parallelism","4")
val sc = new SparkContext(conf)
// TODO RDD创建 - 从内存中
val seq = Seq(1, 2, 3, 4)
// makeRDD()方法有两个参数
/*
第一个参数表示需要处理的数据集
第二个参数表示切片(分区)的数量,如果不传递这个参数,会使用默认值
底层源码实现(local):scheduler.conf.getInt("spark.default.parallelism", totalCores)
从SparkConf配置对象中获取配置参数,如果获取不到,那么会将当前环境中的最大核数来使用
底层源码实现(集群):conf.getInt("spark.default.parallelism", math.max(totalCoreCount.get(), 2))
从SparkConf配置对象中获取配置参数,如果获取不到,那么会将当前环境中的最大核数和2作比较,获取最大值
*/
// 在程序中我们有3处可以设置分区数量,它们的作用分别是:
// 传递的分区参数 > 配置参数 > 默认值
val rdd: RDD[Int] = sc.makeRDD(seq,2)
println("分区数量:" + rdd.partitions.length)
// 将数据的处理结果保存为分区文件,每个分区保存成一份文件
rdd.saveAsTextFile("output")
//rdd.collect().foreach(println)
sc.stop()
}
}
2. 基于磁盘的创建的RDD的分区数设定
package com.heather.spark.core.rdd.instance
import org.apache.spark.rdd.RDD
import org.apache.spark.{
SparkConf, SparkContext}
/**
* @Author Qi Shiwei
* @Date 2021-03-12 - 上午 09:56
* @Desc
*/
object Spark01_Instance_Disk_Par {
def main(args: Array[String]): Unit = {
// TODO 建立Spark引擎的连接对象
val conf: SparkConf = new SparkConf().setMaster("local").setAppName("Par")
val sc = new SparkContext(conf)
// TODO RDD创建 - 从磁盘文件中
// textFile()方法提供了2个参数
/*
第一个参数为文件(目录路径)
第二个参数为最小分区数量【预期分区数量】(分区数 >= 参数),这个参数如果不传,使用默认值
默认值:math.min(defaultParallelism, 2)
分区数量的设定:
传参的分区参数 > 配置参数 > 默认值
*/
// TODO Spark从磁盘中读取文件,分区数量确定原则:
/*
1. Spark读取文件采用的是Hadoop的读取方式
TextInputFormat ——> FileInputFormat ——> getSplits()方法 ——> totalSize属性
long goalSize = totalSize / (long)(numSplits == 0 ? 1 : numSplits);
2. 底层实现:
totalSize : 总的文件字节数 104
goalSize : 每个分区存放的字节数量(集群128M) 10【总字节数 / 预期分区数量 = 10】
goalSize = 总字节数 / 分区数 = “求商”
计算分区数:
104 / 10 = 10.4 ; 4 / 10 = 40% > 10%
则分区数为:10 + 1 = 11(个分区)
如果余数 < 10% ,则不创建新的分区。【假如一共101个字节,则最后一个10个分区】
*/
val rdd: RDD[String] = sc.textFile("data/word.txt",10)
println("分区数 :" + rdd.partitions.length)
rdd.saveAsTextFile("output")
sc.stop()
}
}
5.1.4.3 RDD 转换算子
转换算子:把一个RDD转换为一个新的RDD。
算子(operator ):其实就是方法。
RDD.flatMap() : Spark中RDD的方法称之为算子。
List.flatMap() : Scala中集合的方法称之为方法。
执行原理:
默认原理下:旧的RDD转换为新的RDD,分区数量不变,数据所在的分区也不变。
RDD的分区之间是并行计算的。
RDD的分区内部是串行计算的。
RDD根据数据处理方式的不同将算子整体上分为Value类型、双Value类型和Key-Value类型。
在shuffle过程中,如果落盘的数据量越少,性能提升越明显。
具有shuffle操作的算子:
groupBy 、groupByKey 、reduceByKey 、distinct(借助于reduceByKey) 、 coalesce 、repartition 、sortBy 、aggregateByKey 、 join 、cogroup
具有预聚合功能的算子:【在落盘之前提前在RDD中进行聚合操作,较少落盘数量】
reduceByKey 、 aggregateByKey 、 foldBykey 、combineByKey
可以实现WordCount操作的算子:
groupBy 、 groupByKey 、reduceByKey 、aggregateByKey 、foldByKey 、combineByKey 、countByKey 、countByValue 、
具有行动算子能力的转换算子
sortBy 、sortByKey
aggregateByKey
val wordCount = rdd.aggregateByKey(0)(_+_,_+_)
wordCount.collect().foreach(println)
**foldByKey **
val wordCount = rdd.foldByKey(0)(_+_)
wordCount.collect().foreach(println)
combineByKey
val result: RDD[(String, Int)] = rdd.combineByKey(
num => num,
(x: Int, y: Int) => x + y,
(x: Int, y: Int) => x + y,
)
result.collect().foreach(println)
单Value类型
1)map
函数说明
将处理的数据逐条进行映射转换,这里的转换可以是类型的转换,也可以是值的转换。
代码示例1:
object Spark01_Oper_Map {
def main(args: Array[String]): Unit = {
val conf = new SparkConf().setMaster("local[*]").setAppName("TransformOperator")
val sc = new SparkContext(conf)
// TODO 算子 - 转换
// 所谓的算子,其实就是RDD的方法,将有一个RDD转换成另外一个RDD的方法,就称之为转换算子
// TODO map
val rdd : RDD[Int] = sc.makeRDD(List(1,2,3,4))
// map算子将数据集中的每一条数据按照指定的规则进行转换,这里的转换可能是数值,也可能是类型
// map算子需要传递一个参数,这个参数是函数类型:Int => U
def mapFunction( num:Int ): Int = {
num * 2
}
//val rdd1: RDD[Int] = rdd.map(mapFunction)
//val rdd1: RDD[Int] = rdd.map((num:Int)=>{num * 2})
//val rdd1: RDD[Int] = rdd.map((num:Int)=>num * 2)
//val rdd1: RDD[Int] = rdd.map((num)=>num * 2)
//val rdd1: RDD[Int] = rdd.map(num=>num * 2)
val rdd1: RDD[Int] = rdd.map(_ * 2)
rdd1.collect().foreach(println)
sc.stop()
}
}
代码示例2【执行原理介绍】:
object Spark01_Oper_Map_2 {
def main(args: Array[String]): Unit = {
val conf = new SparkConf().setMaster("local[*]").setAppName("TransformOperator")
val sc = new SparkContext(conf)
val rdd : RDD[Int] = sc.makeRDD(List(1,2,3,4),2)
val rdd1: RDD[Int] = rdd.map(
num => {
println("num = " + num)
num
}
)
// TODO 多个map功能进行叠加
val rdd2: RDD[Int] = rdd1.map(
num => {
println(">>>>>>>> = " + num)
num
}
)
//println(rdd1.partitions.length)
rdd2.collect()//.foreach(println)
sc.stop()
}
}
2)mapPartitions
函数说明
优点:此算子是将数据集中的数据以分区为单位进行转换,类似于批处理,效率高
缺点:将待处理的数据以分区为单位发送到计算节点进行处理,这里的处理是指可以进行任意的处理,哪怕是过滤数据。在处理中数据会有丢失的可能。
代码示例1:
object Spark01_Oper_mapPartitions {
def main(args: Array[String]): Unit = {
val conf: SparkConf = new SparkConf().setMaster("local[*]").setAppName("mapPartitions")
val sc = new SparkContext(conf)
val rdd: RDD[Int] = sc.makeRDD(List(1, 2, 3, 4), 2)
/*
TODO
map : 此算子是将数据集中的每一条数据进行转换,效率低
mapPartitions : 此算子是将数据集中的数据以分区为单位进行转换,类似于批处理,效率高
下面还是以每个数 乘以 2 为案例进行演示
*/
val rdd1: RDD[Int] = rdd.map(
num => {
println("******************") // 程序运行了4遍
num * 2
}
)
val rdd2: RDD[Int] = rdd.mapPartitions(
list => {
println("&&&&&&&&&&&&&&&&&&&") // 程序运行了2遍
list.map(_*2)
}
)
rdd1.collect().foreach(println)
rdd2.collect().foreach(println)
}
}
代码示例2:
object Spark01_Oper_mapPartitions_2 {
def main(args: Array[String]): Unit = {
val conf: SparkConf = new SparkConf().setMaster("local[*]").setAppName("mapPartitions")
val sc = new SparkContext(conf)
// TODO 获取每个数据分区的最大值
val rdd: RDD[Int] = sc.makeRDD(List(1,3,2,6), 2)
/*
mapPartitions 参数的要求:
参数类型:可迭代的类型
返回值类型:可迭代的类型
*/
val rdd1: RDD[Int] = rdd.mapPartitions(
list => {
// 因为求最大值,最大值只有一个不是一个集合,不可迭代,所以我们可以把最大值单独存储到集合中,并获取迭代器
List(list.max).iterator
}
)
rdd1.collect().foreach(println)
}
}
打印结果:
3
6
map和mapPartitions的区别
- 数据处理角度
Map算子是分区内一个数据一个数据的执行,类似于串行操作。而mapPartitions算子是以分区为单位进行批处理操作。
- 功能的角度
Map算子主要目的将数据源中的数据进行转换和改变。但是不会减少或增多数据。MapPartitions算子需要传递一个迭代器,返回一个迭代器,没有要求的元素的个数保持不变,所以可以增加或减少数据
- 性能的角度
Map算子因为类似于串行操作,所以性能比较低,而是mapPartitions算子类似于批处理,所以性能较高。但是mapPartitions算子会长时间占用内存,那么这样会导致内存可能不够用,出现内存溢出的错误。所以在内存有限的情况下,不推荐使用。使用map操作。【完成优于完美!!!】
3)mapPartitionsWithIndex
函数说明
将待处理的数据以分区为单位发送到计算节点进行处理,这里的处理是指可以进行任意的处理,哪怕是过滤数据,在处理时同时可以获取当前分区索引。
代码示例1【 需求:只获取第二个分区中的数据,也就是分区索引的下标为1】:
def main(args: Array[String]): Unit = {
// TODO 算子 —— mapPartitionsWithIndex
// Spark中的分区数的索引是从0号开始的。
val conf: SparkConf = new SparkConf().setMaster("local[*]").setAppName("transform")
val sc = new SparkContext(conf)
val rdd = sc.makeRDD(List(1,2,3,4),2)
// 需求:只获取第二个分区中的数据,也就是分区索引的下标为1
val rdd1: RDD[Int] = rdd.mapPartitionsWithIndex(
/*
参数中的函数有2个参数
第一个参数:分区数下标
第二个参数:每个分区中的数据的迭代器对象
返回值结果:分区中数据的迭代器对象
*/
(index, iter) => {
if (index == 1) {
//直接返回值迭代器对象
iter
} else {
// 当第二个分区中没有数据时,是一个空集合,则没有返回值结果,
// 与此算子要求的返回值结果不符,所以我们返回空集合的一个迭代器
Nil.iterator
}
}
)
rdd1.collect().foreach(println)
}
打印结果:
3
4
代码示例2【 需求: 获取每个分区中的数据所在的分区号】:
def main(args: Array[String]): Unit = {
// TODO 算子 —— mapPartitionsWithIndex
val conf: SparkConf = new SparkConf().setMaster("local[*]").setAppName("transform")
val sc = new SparkContext(conf)
// 需求: 获取每个分区中的数据所在的分区号
// 当前没有指定分区数,则采用默认的分区数,当前系统的最大核数:8个
val rdd = sc.makeRDD(List(1,2,3,4))
val rdd1: RDD[(Int, Int)] = rdd.mapPartitionsWithIndex(
(index, iter) => {
// 遍历转换迭代器中的每个元素
iter.map(
num => {
// index 是分区号
// num 是每一个数值
(index, num)
}
)
}
)
rdd1.collect().foreach(println)
}
4)flatMap
函数说明
将处理的数据进行扁平化后再进行映射处理,所以算子也称之为扁平映射
扁平化:将一个整体拆分成一个一个的个体进行使用的方式。
代码示例1:【遍历集合】
def main(args: Array[String]): Unit = {
// TODO 算子 —— flatMap
val conf: SparkConf = new SparkConf().setMaster("local[*]").setAppName("transform")
val sc = new SparkContext(conf)
val rdd: RDD[List[Int]] = sc.makeRDD(
List(
List(1, 2), List(3, 4)
)
)
// 元素是List集合,表示一个整体
// 希望获取的结果是集合中每一个元素,1,2,3,4
// 函数类型中第一个参数类型list代表的是数据集中的元素类型
// 函数类型中第二个参数类型list代表的是扁平化后的数据容器
val rdd1: RDD[Int] = rdd.flatMap(
list => {
list
}
)
rdd1.collect().foreach(println)
}
代码示例2:【获取每一个单词】
def main(args: Array[String]): Unit = {
// TODO 算子 —— flatMap
val conf: SparkConf = new SparkConf().setMaster("local[*]").setAppName("transform")
val sc = new SparkContext(conf)
val rdd: RDD[String] = sc.makeRDD(
List("Hello Spark", "Hello Scala")
)
val rdd1: RDD[String] = rdd.flatMap(
str => {
str.split(",")
}
)
rdd1.collect().foreach(println)
}
5)glom
函数说明
将同一个分区的一个个的个体数据直接转换为相同类型的内存数组进行处理,分区不变,类似于reduce聚合
def main(args: Array[String]): Unit = {
// TODO 算子 —— glom
val conf: SparkConf = new SparkConf().setMaster("local[*]").setAppName("transform")
val sc = new SparkContext(conf)
// TODO golm : 把一个一个的个体组合成一个整体,结果类型是一个数组,类似于reduce
val rdd = sc.makeRDD(List(1,2,3,4),2)
val golm: RDD[Array[Int]] = rdd.glom()
val rdd1: RDD[Int] = golm.map(_.max)
golm.foreach(println)
println("最大值:" + rdd1.collect())
}
6)groupBy
函数说明
将数据根据指定的规则进行分组, 分区默认不变,但是数据会被打乱重新组合,我们将这样的操作称之为shuffle。极限情况下,数据可能被分在同一个分区中
一个组的数据在一个分区中,但是并不是说一个分区中只有一个组
代码示例1:
def main(args: Array[String]): Unit = {
// TODO 算子 —— groupBy
val conf: SparkConf = new SparkConf().setMaster("local[*]").setAppName("transform")
val sc = new SparkContext(conf)
val rdd = sc.makeRDD(List(1,2,3,4),2)
// 参数 ——> (f: T => K)
// T(元素) => 规则 => K(组名)
val rdd1: RDD[(Int, Iterable[Int])] = rdd.groupBy(
num => {
/*
在分组操作中,一般我们不会关心分组后的组名,所以,代码可以简化
if (num % 2 == 0) {
"偶数"
} else {
"奇数"
}
打印结果:
(偶数,CompactBuffer(2, 4))
(奇数,CompactBuffer(1, 3))
*/
num % 2
/*
打印结果:
(0,CompactBuffer(2, 4))
(1,CompactBuffer(1, 3))
*/
}
)
rdd1.collect().foreach(println)
sc.stop()
}
}
7)filter
函数说明
将数据根据指定的规则进行判断然后进行筛选过滤,符合规则的数据保留,不符合规则的数据丢弃。
符合规则的返回true,数据保留,不符合规则的返回false,数据丢弃。
当数据进行筛选过滤后,分区不变,但是分区内的数据可能不均衡,生产环境下,可能会出现数据倾斜。
代码示例1:
def main(args: Array[String]): Unit = {
// TODO 算子 —— filter
val conf: SparkConf = new SparkConf().setMaster("local[*]").setAppName("transform")
val sc = new SparkContext(conf)
val rdd: RDD[Int] = sc.makeRDD(List(1, 2, 3, 4))
// 保留奇数的数据
val rdd1: RDD[Int] = rdd.filter(
num => {
num % 2 == 1 // 结果如果为true,则数据保留
}
)
rdd1.collect().foreach(println)
sc.stop()
}
代码示例2:
def main(args: Array[String]): Unit = {
val conf = new SparkConf().setMaster("local[*]").setAppName("TransformOperator")
val sc = new SparkContext(conf)
// TODO 算子 - 转换 - filter
// 从服务器日志数据apache.log中获取2015年5月17日的请求路径
// 数据样本 ==> 83.149.9.216 - - 17/05/2015:10:05:03 +0000 GET /presentations/logstash-monitorama-2013/images/kibana-search.png
val rdd = sc.textFile("data/apache.log")
val rdd1: RDD[String] = rdd.filter(
line => {
val datas = line.split(" ")
val time = datas(3)
time.contains("17/05/2015")
//time.substring(0, 10)
//time.startsWith("17/05/2015")
}
).map(
line => {
val datas: Array[String] = line.split(" ")
datas(6)
}
)
rdd1.collect().foreach(println)
sc.stop()
}
8)sample
函数说明
根据指定的规则从数据集中随机抽取数据
- 抽取数据后,这个数据放回,重新抽取
- 抽取数据后,这个数据不放回,不会重新抽取
def main(args: Array[String]): Unit = {
val conf = new SparkConf().setMaster("local[*]").setAppName("TransformOperator")
val sc = new SparkContext(conf)
// TODO 算子 - 转换 - sample
// TODO sample用于在数据集中随机抽取数据
// 1. 抽取数据后,这个数据放回,重新抽取
// 2. 抽取数据后,这个数据不放回,不会重新抽取
val rdd = sc.makeRDD(List(1,2,3,4,5,6,7,8,9,10))
// DB => 10000 Data
// Memory => 10000 User Object
// 1 Data => 1 User => 1K * 10000
// 100 Data => 100 User => 1M * 40
// sample方法第一个参数表示数据抽取后是否放回
// true:放回,false : 不放回
// sample方法第二个参数依赖于第一个参数
// 如果第一个参数为false,第二个参数表示每个数据被抽取的几率, 取值为0 ~ 1之间
// 如果第一个参数为true,第二个参数表示每个数据预期被抽取的数据, 取值大于1
// sample方法第三个参数seed : 随机数种子
// 随机数不随机 : 1 => 随机算法 => a => 随机算法 => 7
// 1 => Hash算法 => X
// 1 => Hash算法 => X
//val rdd1: RDD[Int] = rdd.sample(false, .5)
//val rdd1: RDD[Int] = rdd.sample(true, 2)
val rdd1: RDD[Int] = rdd.sample(true, 2, 1)
rdd1.collect().foreach(println)
sc.stop()
}
9)distinct
函数说明
将数据集中重复的数据去重
def main(args: Array[String]): Unit = {
val conf = new SparkConf().setMaster("local[*]").setAppName("TransformOperator")
val sc = new SparkContext(conf)
// TODO 算子 - 转换 - distinct
val rdd = sc.makeRDD(List(1,1,2,3,4,5,6,7,4,5,3,2,7))
// shuffle
// map(x => (x, null)).reduceByKey((x, _) => x).map(_._1)
// 1, 1
// (1, null), (1, null)
// (1, (null, null))
// (1, null)
// 1
// List(1,2,1,2).distinct (单点)
val rdd1: RDD[Int] = rdd.distinct()
// 参数的作用: 把去重后的数据存放到多少个分区中
val rdd2: RDD[Int] = rdd.distinct(5)
rdd2.saveAsTextFile("output")
rdd2.collect().foreach(println)
sc.stop()
}
10)coalesce
函数说明
根据数据量缩减分区,用于大数据集过滤后,提高小数据集的执行效率
当spark程序中,存在过多的小任务的时候,可以通过coalesce方法,收缩合并分区,减少分区的个数,减小任务调度成本
适用场景:缩小分区数量,并且进行shuffle操作,与repartition算子区分使用。
代码示例:
def main(args: Array[String]): Unit = {
val conf = new SparkConf().setMaster("local[*]").setAppName("TransformOperator")
val sc = new SparkContext(conf)
// TODO 算子 - 转换 - coalesce
// 此算子更多的适用场景:缩小分区数量,并且进行shuffle操作。
val rdd: RDD[Int] = sc.makeRDD(List(1, 2, 3, 4, 5,6),3)
/*
此算子有两个参数
第一个参数:改变后的分区的数量
第二个参数:是否进行shuffle操作,默认值为false。
①:如果为false,则新的分区的数量不能比以前的分区数量多。因为不会进行shuffle操作,数据不会打乱重新组合。
②:如果不进行shuffle操作,则数据不会打乱,有可能会导致数据倾斜现象。推荐参数设置为true。
*/
val rdd1: RDD[Int] = rdd.coalesce(2, true)
rdd1.saveAsTextFile("output")
rdd1.collect().foreach(println)
sc.stop()
}
11)repartition
函数说明
该操作内部其实执行的是coalesce操作,参数shuffle的默认值为true。无论是将分区数多的RDD转换为分区数少的RDD,还是将分区数少的RDD转换为分区数多的RDD,repartition操作都可以完成,因为无论如何都会经shuffle过程。
适用场景:缩小分区数量,并且进行shuffle操作,与coalesce算子区分使用。
代码示例:
def main(args: Array[String]): Unit = {
val conf = new SparkConf().setMaster("local[*]").setAppName("TransformOperator")
val sc = new SparkContext(conf)
// TODO 算子 - 转换 - repartition
val rdd: RDD[Int] = sc.makeRDD(List(1, 2, 3, 4, 5,6),2)
/*
源码:
def repartition(numPartitions: Int)(implicit ord: Ordering[T] = null): RDD[T] = withScope {
coalesce(numPartitions, shuffle = true)
}
*/
val rdd1: RDD[Int] = rdd.repartition(4)
rdd1.saveAsTextFile("output")
rdd1.collect().foreach(println)
sc.stop()
}
12)sortBy
函数说明
该操作用于排序数据。在排序之前,可以将数据通过f函数进行处理,之后按照f函数处理的结果进行排序,默认为升序排列。排序后新产生的RDD的分区数与原RDD的分区数一致。中间存在shuffle的过程
def main(args: Array[String]): Unit = {
val conf = new SparkConf().setMaster("local[*]").setAppName("TransformOperator")
val sc = new SparkContext(conf)
// TODO 算子 - 转换 - repartition
val rdd: RDD[Int] = sc.makeRDD(List(2, 6, 4, 1, 5,3))
/*
Int => K
rdd.groupBy()
Int(数据值) => K(排序的值)
1 => "1"
2 => "2"
11 => "11"
*/
// 此算子的倒叙和Scala不同,可以直接使用true和fasle即可操作
val rdd1: RDD[Int] = rdd.sortBy(num => num,false)
rdd1.collect().foreach(println)
sc.stop()
}
双Value类型
13)intersection
函数说明
对源RDD和参数RDD求交集后返回一个新的RDD
14)union
函数说明
对源RDD和参数RDD求并集后返回一个新的RDD
15)subtract
函数说明
以一个RDD元素为主,去除两个RDD中重复元素,将其他元素保留下来。求差集
16)zip
函数说明
将两个RDD中的元素,以键值对的形式进行合并。其中,键值对中的Key为第1个RDD中的元素,Value为第2个RDD中的相同位置的元素。
**重点:**在Spark中,如果想要进行拉链操作,那么两个集合的分区数量要一致,分区内的数据要一致,数据类型没要求。
思考一个问题:如果两个RDD数据类型不一致怎么办?
可以进行拉链操作
思考一个问题:如果两个RDD数据分区不一致怎么办?
不可以进行拉链操作
思考一个问题:如果两个RDD分区数据数量不一致怎么办?
不可以进行拉链操作
Key - Value类型
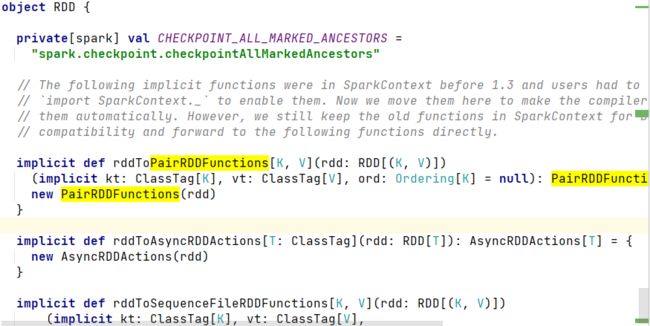
K - V 类型的算子说明:
所有的K-V类型的算子都是使用了隐式转换,都是先把当前的RDD转换成了PairRDDFunctions类型。我们可以从源码中找到。如果RDD不是K-V类型,此类算子无法使用。
17)partitionBy
函数说明
将数据按照指定Partitioner(分区器)重新进行分区。Spark默认的分区器是HashPartitioner
使用注意:
1.如果当前的rdd不是对欧元组【map结构】,那么此rdd不能调用partitionBy()方法 所以在使用前,我们需要先把当前的RDD转换为map结构,这一点我们在前面介绍的RDD的"五大核心属性"中已经提到过。 2.其实partitionBy()方法不是RDD的算子,而是在编译时因式转换为PairRddFunctions类型 3.partitionBy()方法需要传递一个参数,这个参数是Partitioner分区器,通过源码可知,这个分区器 是抽象类,所以我们需要使用其子类,一共有3个 : 【RangePartitioner(范围分区器)、HashPartitioner(哈希算法分区器)、PythonPartitioner(python专属,被private修饰)】, 其中HashPartitioner分区器是默认分区器, 源码为:class HashPartitioner(partitions: Int) extends Partitioner,所以我们使用HashPartitioner分区器时, 需要传递一个Int类型的参数,这个参数就是重新分区的分区数量。
代码示例:
def main(args: Array[String]): Unit = {
val conf = new SparkConf().setMaster("local[*]").setAppName("TransformOperator")
val sc = new SparkContext(conf)
// TODO 算子 - 转换 - KV格式 - partitionBy
val rdd: RDD[Int] = sc.makeRDD(List(1, 2, 3, 4), 2)
rdd.saveAsTextFile("output-1")
/*
使用注意:
1.如果当前的rdd不是对欧元组【map结构】,那么此rdd不能调用partitionBy()方法
所以在使用前,我们需要先把当前的RDD转换为map结构,这一点我们在前面介绍的RDD的"五大核心属性"中已经提到过。
2.其实partitionBy()方法不是RDD的算子,而是在编译时因式转换为PairRddFunctions类型
3.partitionBy()方法需要传递一个参数,这个参数是Partitioner分区器,通过源码可知,这个分区器
是抽象类,所以我们需要使用其子类,一共有3个 :
【RangePartitioner(范围分区器)、HashPartitioner(哈希算法分区器)、PythonPartitioner(python专属,被private修饰)】,
其中HashPartitioner分区器是默认分区器,
源码:class HashPartitioner(partitions: Int) extends Partitioner,所以我们使用HashPartitioner分区器时,
需要传递一个Int类型的参数,这个参数就是重新分区的分区数量。
*/
val rdd1: RDD[(Int, Int)] = rdd.map((_, 1))
val newRdd: RDD[(Int, Int)] = rdd1.partitionBy(new HashPartitioner(2))
// 通过结果可看出效果
newRdd.saveAsTextFile("output-2")
// 释放资源
sc.stop()
}
18)reduceByKey
函数说明
可以将数据按照相同的Key对Value进行聚合,我们可以认为此算子有两个步骤,先根据Key分组,再聚合。
def main(args: Array[String]): Unit = {
val conf = new SparkConf().setMaster("local[*]").setAppName("TransformOperator")
val sc = new SparkContext(conf)
// TODO 算子 - 转换 - KV格式 - reduceByKey
val rdd: RDD[(String, Int)] = sc.makeRDD(
List(("a", 1), ("b", 2), ("a", 3), ("c", 4), ("b", 4),("c", 2)),
2
)
// reduceByKey算子将相同的Key的数据的value值进行聚合。
val rdd1: RDD[(String, Int)] = rdd.reduceByKey(_ + _)
rdd1.collect().foreach(println)
// 释放资源
sc.stop()
}
19)groupByKey
函数说明
将数据源的数据根据key对value进行分组
特别注意:
groupByKey 和 groupBy() 的区别 。
groupByKey 仅仅是根据key对value值进行聚合操作 。
但是groupBy 是借助于key对 (key和value)整体进行聚合操作 。
groupByKey 和 reduceByKey() 的区别 。
groupByKey 和 groupBy() 的区别
代码示例:
def main(args: Array[String]): Unit = {
val conf = new SparkConf().setMaster("local[*]").setAppName("TransformOperator")
val sc = new SparkContext(conf)
// TODO 算子 - 转换 - KV格式 - groupByKey
val rdd: RDD[(String, Int)] = sc.makeRDD(
List(
("a", 1), ("b", 2), ("a", 2), ("b", 3),("c", 2),
("c", 1), ("a", 3), ("b", 2), ("c", 4)
),
2
)
/*
首先,groupBy 和 groupByKey都可以做分组,先分析两者之间的区别:
- groupBy 的返回值中是元组的嵌套 => (key,((key,value),(key,value)...))
- groupByKey 的返回值中只是一个元组 => (key,(value,value...))
*/
// 因为源数据中的值是一个tuple,如果我们要根据key分组,则就是tuple的第一个元素。
val rdd1: RDD[(String, Iterable[(String, Int)])] = rdd.groupBy(_._1)
rdd1.collect().foreach(println)
println("*" * 15)
val rdd2: RDD[(String, Iterable[Int])] = rdd.groupByKey()
rdd2.collect().foreach(println)
// 释放资源
sc.stop()
}
输出结果:
(b,CompactBuffer((b,2), (b,3), (b,2)))
(a,CompactBuffer((a,1), (a,2), (a,3)))
(c,CompactBuffer((c,2), (c,1), (c,4)))
***************
(b,CompactBuffer(2, 3, 2))
(a,CompactBuffer(1, 2, 3))
(c,CompactBuffer(2, 1, 4))
groupByKey 和 reduceByKey() 的区别
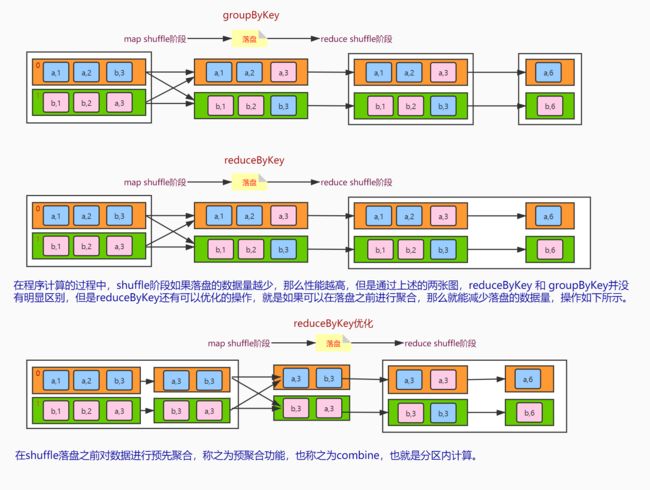
在程序计算的过程中,shuffle阶段如果落盘的数据量越少,那么性能越高,但是通过上述的两张图,reduceByKey 和 groupByKey并没有明显区别,但是reduceByKey还有可以优化的操作,就是如果可以在落盘之前进行聚合,那么就能减少落盘的数据量。总结如下:
从shuffle的角度:reduceByKey和groupByKey都存在shuffle的操作,但是reduceByKey可以在shuffle前对分区内相同key的数据进行预聚合(combine)功能,这样会减少落盘的数据量,而groupByKey只是进行分组,不存在数据量减少的问题,reduceByKey性能比较高。
从功能的角度:reduceByKey其实包含分组和聚合的功能。groupByKey只能分组,不能聚合,所以在分组聚合的场合下,推荐使用reduceByKey,如果仅仅是分组而不需要聚合。那么还是只能使用groupByKey
**扩展:**在shuffle落盘之前对数据进行预先聚合,称之为预聚合,也称之为combine,也就是分区内计算。
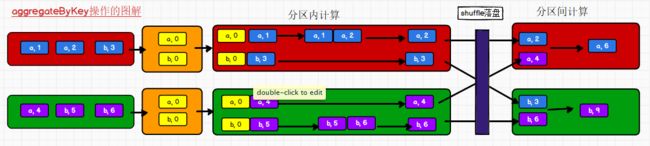
20)aggregateByKey
函数说明
将数据根据不同的规则进行分区内计算和分区间计算
特别注意:aggregateByKey 和 reduceByKey 的区别:
- reduceByKey 算子的分区内和分区间的计算逻辑是一样的 。
- aggregateByKey 算子的分区内和分区间的计算逻辑可以不同 ,功能更强大 。
aggregateByKey 的参数
aggregateByKey 算子有柯里化操作,存在多个参数列表
第一个参数列表有一个参数,这个参数表示计算的初始值【根据业务自定义】
第二个参数列表有两个参数
1. 第一个参数表示分区内的计算规则的逻辑
2. 第二个参数表示分区间的计算规则的逻辑
def main(args: Array[String]): Unit = {
val conf = new SparkConf().setMaster("local[*]").setAppName("TransformOperator")
val sc = new SparkContext(conf)
// TODO 算子 - 转换 - KV格式 - aggregateByKey
// 需求 : 数据集中相同的key 分区内求最大值,分区间求和
val rdd: RDD[(String, Int)] = sc.makeRDD(
List(
("a", 1), ("a", 2), ("b", 3),
("b", 4), ("b", 5), ("a", 6)
),
2
)
val rdd1: RDD[(String, Int)] = rdd.aggregateByKey(0)(
(x, y) => math.max(x, y), //分区内求最大值
(x, y) => x + y // 分区间求和
)
rdd1.collect().foreach(println)
// 释放资源
sc.stop()
}
对上述代码的图解:
21)foldByKey
函数说明
当分区内计算规则和分区间计算规则相同时,aggregateByKey就可以简化为foldByKey
特别注意:
foldByKey 和 reduceByKey的区别:foldByKey 的参数具有柯里化的,具有初始值。
代码示例:
def main(args: Array[String]): Unit = {
val conf = new SparkConf().setMaster("local[*]").setAppName("TransformOperator")
val sc = new SparkContext(conf)
// TODO 算子 - 转换 - KV格式 - foldByKey
// WordCount
val rdd: RDD[(String, Int)] = sc.makeRDD(
List(
("a", 1), ("a", 2), ("b", 3),
("b", 4), ("b", 5), ("a", 6)
),
2
)
val wordCount = rdd.foldByKey(0)(_+_)
wordCount.collect().foreach(println)
// 释放资源
sc.stop()
}
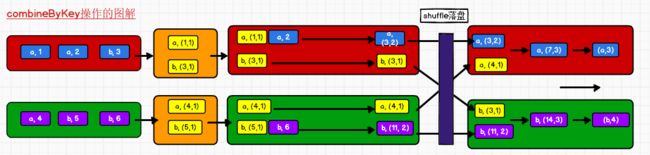
22)combineByKey
函数说明
最通用的对key-value型rdd进行聚集操作的聚集函数(aggregation function)。类似于aggregate(),combineByKey()允许用户返回值的类型与输入不一致。
代码示例 :
def main(args: Array[String]): Unit = {
val conf = new SparkConf().setMaster("local[*]").setAppName("TransformOperator")
val sc = new SparkContext(conf)
// TODO 算子 - 转换 - KV格式 - combineByKey
// 需求 :求相同的key的平均值
val rdd: RDD[(String, Int)] = sc.makeRDD(
List(
("a", 1), ("a", 2), ("b", 3),
("b", 4), ("b", 5), ("a", 6)
),
2
)
/*
combineByKey 算子有3个参数
第一个参数表示初始值的转换
第二个参数表示分区内的计算逻辑
第三个参数表示分区间的计算逻辑
*/
val rdd1: RDD[(String, (Int, Int))] = rdd.combineByKey(
// 第一个参数表示初始值的转换
(num: Int) => (num, 1),
// 第二个参数表示分区内的计算逻辑
(t: (Int, Int), num: Int) => (t._1 + num, t._2 + 1),
// 第三个参数表示分区间的计算逻辑
(t1: (Int, Int), t2: (Int, Int)) => {
(t1._1 + t2._1, t1._2 + t2._2)
}
)
val result: RDD[(String, Int)] = rdd1.map {
case (key, (total, size)) => {
(key, total / size)
}
}
result.collect().foreach(println)
// 释放资源
sc.stop()
}s
对上述代码的图解:
重点:combineByKey 、aggregateByKey、foldByKey、reduceByKey的区别
总结:
CombineByKey : 当计算时,发现数据结构不满足要求时,可以让第一个数据转换结构。分区内和分区间计算规则不相同。
AggregateByKey :相同key的第一个数据和初始值进行分区内计算,分区内和分区间计算规则可以不相同
foldByKey : 相同key的第一个数据和初始值进行分区内计算,分区内和分区间计算规则相同
reduceByKey : 相同key的第一个数据不进行任何计算,分区内和分区间计算规则相同
详情看源代码:
- combineByKey
def combineByKey[C]( createCombiner: V => C, mergeValue: (C, V) => C, mergeCombiners: (C, C) => C, partitioner: Partitioner, mapSideCombine: Boolean = true, // 支持预聚合 serializer: Serializer = null): RDD[(K, C)] = self.withScope { combineByKeyWithClassTag( createCombiner, // 相同Key的第一个值的转换逻辑 mergeValue, // 分区内的计算逻辑 mergeCombiners, // 分区间的计算逻辑 partitioner, // 分区器,默认HashPartitioner mapSideCombine, // 默认值true【属性中定义过】 serializer) (null) }
- aggregateByKey
combineByKeyWithClassTag[U]( (v: V) => cleanedSeqOp(createZero(), v), // 将初始值和相同key的第一个值进行分区内的计算 cleanedSeqOp, // 分区内的计算逻辑 combOp, // 分区间的计算逻辑 partitioner // 分区器,默认HashPartitioner )
- foldByKey
combineByKeyWithClassTag[V]( (v: V) => cleanedFunc(createZero(), v), // 将初始值和相同key的第一个值进行分区内的计算 cleanedFunc, // 分区内的计算逻辑 cleanedFunc, // 分区间的计算逻辑,和分区内的计算逻辑相同 partitioner // 分区器,默认HashPartitioner )
- reduceByKey
combineByKeyWithClassTag[V]( (v: V) => v, // 相同Key的第一个值的转换逻辑 func, // 分区内的计算逻辑 func, // 分区间的计算逻辑,和分区内的计算逻辑相同 partitioner // 分区器,默认HashPartitioner )
23)sortByKey
函数说明
仅仅根据key进行排序,不对value进行比较排序。
在一个(K,V)的RDD上调用,如果key是对象类型,则K必须实现Ordered接口(特质),重写compare()方法,在方法内定义排序规则,返回一个按照key进行排序的RDD。
代码示例1 :
def main(args: Array[String]): Unit = {
val conf = new SparkConf().setMaster("local[*]").setAppName("TransformOperator")
val sc = new SparkContext(conf)
// TODO 算子 - 转换 - KV格式 - sortByKey
val rdd = sc.makeRDD(
List(
(2,3),(3,2),(1,3),(1,1),(2,1)
)
)
// 参数:如果设置为true,则升序排序,如果为false,则倒叙排序【默认是升序】
val rdd1: RDD[(Int, Int)] = rdd.sortByKey(true)
rdd1.collect().foreach(println)
// 释放资源
sc.stop()
}
代码示例2:
def main(args: Array[String]): Unit = {
val conf = new SparkConf().setMaster("local[*]").setAppName("TransformOperator")
val sc = new SparkContext(conf)
// TODO 算子 - 转换 - KV格式 - sortByKey
val rdd = sc.makeRDD(
List(
(new User(),1),(new User(),3),(new User(),2)
)
)
rdd.sortByKey().collect().foreach(println)
// 释放资源
sc.stop()
}
class User extends Ordered[User] with Serializable {
override def compare(that: User): Int = {
// 排序规则,如果为正数1,则升序
// 如果为负数-1,则倒叙
-1
}
override def toString = s"User()"
}
24)join
函数说明
在类型为(K,V)和(K,W)的RDD上调用,返回一个相同key对应的所有元素连接在一起的(K,(V,V))的RDD。
此操作易引起笛卡尔积,不推荐使用。
代码示例:
def main(args: Array[String]): Unit = {
val conf = new SparkConf().setMaster("local[*]").setAppName("TransformOperator")
val sc = new SparkContext(conf)
// TODO 算子 - 转换 - KV格式 - join
val rdd1: RDD[(String, Int)] = sc.makeRDD(List(
("a", 1), ("b", 2), ("c", 3)
))
val rdd2 : RDD[(String,Int)] = sc.makeRDD(List(
("a",4),("b",5),("c",6)
))
// 两个集合,按照相同的key进行组合
val newRdd: RDD[(String, (Int, Int))] = rdd1.join(rdd2)
newRdd.collect().foreach(println)
/*
输出结果:
(a,(1,4))
(b,(2,5))
(c,(3,6))
*/
// 释放资源
sc.stop()
}
25)leftOuterJoin
函数说明
类似于SQL语句的左外连接
26)RightOuterJoin
函数说明
类似于SQL语句的右外连接
27)cogroup
函数说明
类似于SQL语句中的全连接。
作用:
在一个RDD的内部按照key进行分组,另外的RDD的内部也按照key进行分组按照,最后两个RDD按照相同的Key进行聚合。
在类型为(K,V)和(K,W)的RDD上调用,返回一个(K,(Iterable,Iterable))类型的RDD
综合练习 - Top3
示例代码
def main(args: Array[String]): Unit = {
val conf = new SparkConf().setMaster("local[*]").setAppName("req")
val sc = new SparkContext(conf)
//统计出每一个省份每个广告被点击数量排行的Top3
// 时间戳, 省份, 城市, 用户, 广告,
// 1516609143867 6 7 64 16
// 先聚合 再分组
// 1. 加载文件,获取数据
// line => 1516609143867 6 7 64 16
val rdd: RDD[String] = sc.textFile("data/agent.log")
// 2. 对原始数据进行切分,进行格式的转换
// line => ((省份-广告),1)
val mapRdd: RDD[(String, Int)] = rdd.map(
line => {
val splitRdd: Array[String] = line.split(" ")
((splitRdd(1) + "-" + splitRdd(4)), 1)
}
)
// 3. 对数据进行聚合
// line => (省份1-广告1,sum1),(省份2-广告2,sum2),(省份3-广告3,sum3)
val reduceRdd: RDD[(String, Int)] = mapRdd.reduceByKey(_ + _)
// 4. 进行结构的转换
val rdd1: RDD[(String, (String, Int))] = reduceRdd.map {
case (key, num) => {
val keys: Array[String] = key.split("-")
(keys(0), (keys(1), num))
}
}
// 5. 按照省份进行分组
val groupRdd: RDD[(String, Iterable[(String, Int)])] = rdd1.groupByKey()
// 6.排序获取前3名
val res: RDD[(String, List[(String, Int)])] = groupRdd.mapValues(
it => {
it.toList.sortBy(_._2)(Ordering.Int.reverse).take(3)
}
)
res.collect().foreach(println)
sc.stop()
}
代码优化
def main(args: Array[String]): Unit = {
val conf = new SparkConf().setMaster("local[*]").setAppName("req")
val sc = new SparkContext(conf)
val rdd: RDD[String] = sc.textFile("data/agent.log")
val mapRdd: RDD[(String, Int)] = rdd.map(
line => {
val splitRdd: Array[String] = line.split(" ")
((splitRdd(1) + "-" + splitRdd(4)), 1)
}
)
val reduceRdd: RDD[(String, Int)] = mapRdd.reduceByKey(_ + _)
val rdd1: RDD[(String, (String, Int))] = reduceRdd.map {
case (key, num) => {
val keys: Array[String] = key.split("-")
(keys(0), (keys(1), num))
}
}
// 问题1:groupByKey只是单纯的进行分组操作,并不能较少数据,
// val groupRdd: RDD[(String, Iterable[(String, Int)])] = rdd1.groupByKey()
//
// val res: RDD[(String, List[(String, Int)])] = groupRdd.mapValues(
// it => {
// // 问题2:将分布式数据进行单点排序,有可能程序跑不通
// it.toList.sortBy(_._2)(Ordering.Int.reverse).take(3)
// }
// )
// 代码优化
// (ArrayBuffer[(String,Int)]()) : 设置初始值是一个数组
val res = rdd1.aggregateByKey(ArrayBuffer[(String,Int)]())(
// 分区内的计算逻辑
(buffer,t) => {
buffer.append(t)
buffer.sortBy(_._2)(Ordering.Int.reverse).take(3)
},
// 分区间的计算逻辑
(buffer1,buffer2) => {
buffer1.appendAll(buffer2)
buffer1.sortBy(_._2)(Ordering.Int.reverse).take(3)
}
)
res.collect().foreach(println)
sc.stop()
}
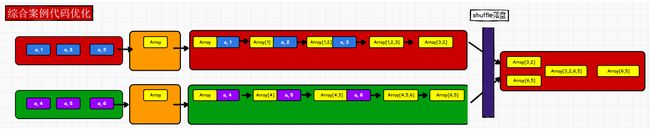
5.1.4.4 RDD 行动算子
行动算子:触发RDD算子开始执行
1)reduce
函数说明
聚集RDD中的所有元素,先聚合分区内数据,再聚合分区间数据
2)collect
函数说明
在驱动程序(Driver)中,以数组Array的形式返回数据集的所有元素
3)count
函数说明
返回RDD中元素的个数
4) first
函数说明
返回RDD中的第一个元素
5) take
函数说明
返回一个由RDD的前n个元素组成的数组
6) takeOrdered
函数说明
返回该RDD排序后的前n个元素组成的数组
7) aggregate
函数说明
分区的数据通过初始值和分区内的数据进行聚合,然后再和初始值进行分区间的数据聚合
8) fold
函数说明
折叠操作,aggregate的简化版操作
9)countByKey
函数说明
统计每种key的个数
10)sava 类算子
函数说明
将数据保存到不同格式的文件中
11) foreache
函数说明
分布式遍历RDD中的每一个元素,调用指定函数
5.1.4.5 RDD 序列化
1. 闭包
**概念:**在嵌套函数调用时,函数调用了外部的变量(参数),将外部的变量包含到函数的内部并且形成了一个闭合的环境,而且此变量其余地方无法再使用,改变了此变量的生命周期,这就是闭包,其实就是“偷” 。
场景:
- 所有的嵌套函数的使用都有闭包 。
- 所有的匿名函数都有闭包 。
- Spark中算子内调用算子外的变量 。
**新老版本的区别:**早期——>匿名内部类 。新版——>变更函数声明方式 。
def main(args: Array[String]): Unit = { def outer(x : Int) = { def inner(y : Int) = { x + y } inner _ } val fun = outer(10) val res = fun(20) println(res) // 30 }
2. 闭包检查
从计算的角度, 算子以外的代码都是在Driver端执行, 算子里面的代码都是在Executor端执行。那么在scala的函数式编程中,就会导致算子内经常会用到算子外的数据,这样就形成了闭包的效果,如果使用的算子外的数据无法序列化,就意味着无法传值给Executor端执行,就会发生错误,所以需要在执行任务计算前,检测闭包内的对象是否可以进行序列化,这个操作我们称之为闭包检测。Scala2.12版本后闭包编译方式发生了改变
3. 序列化方法和属性
从计算的角度, 算子以外的代码都是在Driver端执行, 算子里面的代码都是在Executor端执行,看如下代码:
object serializable02_function {
def main(args: Array[String]): Unit = {
//1.创建SparkConf并设置App名称
val conf: SparkConf = new SparkConf().setAppName("SparkCoreTest").setMaster("local[*]")
//2.创建SparkContext,该对象是提交Spark App的入口
val sc: SparkContext = new SparkContext(conf)
//3.创建一个RDD
val rdd: RDD[String] = sc.makeRDD(Array("hello world", "hello spark", "hive", "atguigu"))
//3.1创建一个Search对象
val search = new Search("hello")
//3.2 函数传递,打印:ERROR Task not serializable
search.getMatch1(rdd).collect().foreach(println)
//3.3 属性传递,打印:ERROR Task not serializable
search.getMatch2(rdd).collect().foreach(println)
//4.关闭连接
sc.stop()
}
}
// 样例类默认实现可序列化接口
class Search(query:String) extends Serializable {
def isMatch(s: String): Boolean = {
s.contains(query)
}
// 函数序列化案例
def getMatch1 (rdd: RDD[String]): RDD[String] = {
//rdd.filter(this.isMatch)
rdd.filter(isMatch)
}
// 属性序列化案例
def getMatch2(rdd: RDD[String]): RDD[String] = {
//rdd.filter(x => x.contains(this.query))
rdd.filter(x => x.contains(query))
//val q = query
//rdd.filter(x => x.contains(q))
}
}
4. Kryo序列化框架
Java的序列化能够序列化任何的类。但是比较重(字节多),序列化后,对象的提交也比较大。Spark出于性能的考虑,Spark2.0开始支持另外一种Kryo序列化机制。Kryo速度是Serializable的10倍。当RDD在Shuffle数据的时候,简单数据类型、数组和字符串类型已经在Spark内部使用Kryo来序列化。
注意:即使使用Kryo序列化,也要继承Serializable接口。
使用前提:在maven中配置kryo
<dependency> <groupId>com.esotericsoftwaregroupId> <artifactId>kryoartifactId> <version>5.0.3version> dependency>
代码示例
object serializable_Kryo {
def main(args: Array[String]): Unit = {
val conf: SparkConf = new SparkConf()
.setAppName("SerDemo")
.setMaster("local[*]")
// 替换默认的序列化机制
.set("spark.serializer", "org.apache.spark.serializer.KryoSerializer")
// 注册需要使用 kryo 序列化的自定义类
.registerKryoClasses(Array(classOf[Searcher]))
val sc = new SparkContext(conf)
val rdd: RDD[String] = sc.makeRDD(Array("hello world", "hello atguigu", "atguigu", "hahah"), 2)
val searcher = new Searcher("hello")
val result: RDD[String] = searcher.getMatchedRDD1(rdd)
result.collect.foreach(println)
}
}
case class Searcher(val query: String) {
def isMatch(s: String) = {
s.contains(query)
}
def getMatchedRDD1(rdd: RDD[String]) = {
rdd.filter(isMatch)
}
def getMatchedRDD2(rdd: RDD[String]) = {
val q = query
rdd.filter(_.contains(q))
}
}
5.1.4.6 RDD 依赖关系
1. RDD 血缘关系
RDD只支持粗粒度转换,即在大量记录上执行的单个操作。将创建RDD的一系列Lineage(血统)记录下来,以便恢复丢失的分区。RDD的Lineage会记录RDD的元数据信息和转换行为,当该RDD的部分分区数据丢失时,它可以根据这些信息来重新运算和恢复丢失的数据分区。
val fileRDD: RDD[String] = sc.textFile("input/1.txt")
println(fileRDD.toDebugString)
println("----------------------")
val wordRDD: RDD[String] = fileRDD.flatMap(_.split(" "))
println(wordRDD.toDebugString)
println("----------------------")
val mapRDD: RDD[(String, Int)] = wordRDD.map((_,1))
println(mapRDD.toDebugString)
println("----------------------")
val resultRDD: RDD[(String, Int)] = mapRDD.reduceByKey(_+_)
println(resultRDD.toDebugString)
resultRDD.collect()
2. 依赖关系
这里所谓的依赖关系,其实就是两个相邻RDD之间的关系
val sc: SparkContext = new SparkContext(conf)
val fileRDD: RDD[String] = sc.textFile("input/1.txt")
println(fileRDD.dependencies)
println("----------------------")
val wordRDD: RDD[String] = fileRDD.flatMap(_.split(" "))
println(wordRDD.dependencies)
println("----------------------")
val mapRDD: RDD[(String, Int)] = wordRDD.map((_,1))
println(mapRDD.dependencies)
println("----------------------")
val resultRDD: RDD[(String, Int)] = mapRDD.reduceByKey(_+_)
println(resultRDD.dependencies)
resultRDD.collect()
3. RDD 窄依赖
窄依赖表示每一个父(上游)RDD的Partition最多被子(下游)RDD的一个Partition使用,窄依赖我们形象的比喻为独生子女。

class OneToOneDependency[T](rdd: RDD[T]) extends NarrowDependency[T](rdd)
4. RDD 宽依赖
宽依赖表示同一个父(上游)RDD的Partition被多个子(下游)RDD的Partition依赖,会引起Shuffle,总结:宽依赖我们形象的比喻为多生育。

class ShuffleDependency[K: ClassTag, V: ClassTag, C: ClassTag](
@transient private val _rdd: RDD[_ <: Product2[K, V]],
val partitioner: Partitioner,
val serializer: Serializer = SparkEnv.get.serializer,
val keyOrdering: Option[Ordering[K]] = None,
val aggregator: Option[Aggregator[K, V, C]] = None,
val mapSideCombine: Boolean = false)
extends Dependency[Product2[K, V]]
5. RDD 阶段划分
DAG(Directed Acyclic Graph)有向无环图是由点和线组成的拓扑图形,该图形具有方向,不会闭环。例如,DAG记录了RDD的转换过程和任务的阶段。
Spark中一个Job的阶段的数量等同于shuffle依赖的数量 + 1
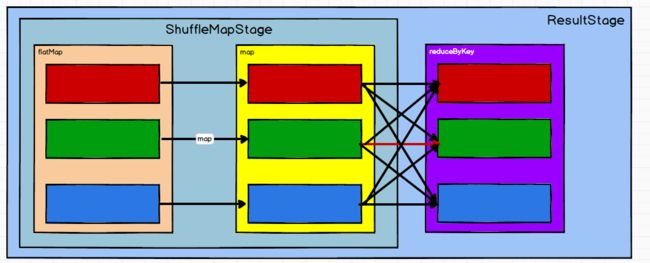
6. RDD 任务划分
RDD任务切分中间分为:Application、Job、Stage和Task
Application:初始化一个SparkContext即生成一个Application;
Job:一个Action算子就会生成一个Job;
Stage:Stage等于宽依赖(ShuffleDependency)的个数加1;
Task:一个Stage阶段中,最后一个RDD的分区个数就是Task的个数。
注意:Application->Job->Stage->Task每一层都是1对n的关系。
1. Spark执行Job时,上一个阶段没有提交完成,无法执行下一个阶段
2. 一个阶段中的任务数量等同于它最后的那个RDD的分区的数量
5.1.4.7 RDD 持久化
缓存
检查点
5.1.4.8 RDD分区器
Spark目前支持Hash分区和Range分区,和用户自定义分区。Hash分区为当前的默认分区。分区器直接决定了RDD中分区的个数、RDD中每条数据经过Shuffle后进入哪个分区,进而决定了Reduce的个数。
Hash分区 、Range分区 、自定义分区器
- 只有Key-Value类型的RDD才有分区器,非Key-Value类型的RDD分区的值是None
- 每个RDD的分区ID范围:0 ~ (numPartitions - 1),决定这个值是属于那个分区的。
**Hash分区:**对于给定的key,计算其hashCode,并除以分区个数取余
class HashPartitioner(partitions: Int) extends Partitioner {
require(partitions >= 0, s"Number of partitions ($partitions) cannot be negative.")
def numPartitions: Int = partitions
def getPartition(key: Any): Int = key match {
case null => 0
case _ => Utils.nonNegativeMod(key.hashCode, numPartitions)
}
override def equals(other: Any): Boolean = other match {
case h: HashPartitioner =>
h.numPartitions == numPartitions
case _ =>
false
}
override def hashCode: Int = numPartitions
}
**Range分区:**将一定范围内的数据映射到一个分区中,尽量保证每个分区数据均匀,而且分区间有序
class RangePartitioner[K : Ordering : ClassTag, V](
partitions: Int,
rdd: RDD[_ <: Product2[K, V]],
private var ascending: Boolean = true)
extends Partitioner {
// We allow partitions = 0, which happens when sorting an empty RDD under the default settings.
require(partitions >= 0, s"Number of partitions cannot be negative but found $partitions.")
private var ordering = implicitly[Ordering[K]]
// An array of upper bounds for the first (partitions - 1) partitions
private var rangeBounds: Array[K] = {
...
}
def numPartitions: Int = rangeBounds.length + 1
private var binarySearch: ((Array[K], K) => Int) = CollectionsUtils.makeBinarySearch[K]
def getPartition(key: Any): Int = {
val k = key.asInstanceOf[K]
var partition = 0
if (rangeBounds.length <= 128) {
// If we have less than 128 partitions naive search
while (partition < rangeBounds.length && ordering.gt(k, rangeBounds(partition))) {
partition += 1
}
} else {
// Determine which binary search method to use only once.
partition = binarySearch(rangeBounds, k)
// binarySearch either returns the match location or -[insertion point]-1
if (partition < 0) {
partition = -partition-1
}
if (partition > rangeBounds.length) {
partition = rangeBounds.length
}
}
if (ascending) {
partition
} else {
rangeBounds.length - partition
}
}
override def equals(other: Any): Boolean = other match {
...
}
override def hashCode(): Int = {
...
}
@throws(classOf[IOException])
private def writeObject(out: ObjectOutputStream): Unit = Utils.tryOrIOException {
...
}
@throws(classOf[IOException])
private def readObject(in: ObjectInputStream): Unit = Utils.tryOrIOException {
...
}
}
自定义分区器
def main(args: Array[String]): Unit = {
val conf = new SparkConf().setMaster("local").setAppName("Partitioner")
val sc = new SparkContext(conf)
// 自定义分区器
// 自行决定数据存储的分区位置
val rdd = sc.makeRDD(
List(
("nba", "xxxx"),
("cba", "xxxx"),
("cba", "xxxx"),
("cba", "xxxx"),
("nba", "xxxx"),
("wnba", "xxxx"),
),3
)
// 0 - nba, 1 - cba, 2 - wnba
val rdd1 = rdd.partitionBy( new MyPartitioner() )
rdd1.saveAsTextFile("output")
sc.stop()
}
// 自定义分区器类
// 1. 继承抽象类:Partitioner
class MyPartitioner extends Partitioner {
override def numPartitions: Int = 3
// 根据数据的k获取所在分区的编号(从0开始)
override def getPartition(key: Any): Int = {
key match {
case "nba" => 0
case "cba" => 1
case "wnba" => 2
}
}
}
5.1.4.9 RDD文件读取与保存
Spark的数据读取及数据保存可以从两个维度来作区分:文件格式以及文件系统。
文件格式分为:text文件、csv文件、sequence文件以及Object文件;
文件系统分为:本地文件系统、HDFS、HBASE以及数据库。
text文件
sequence文件
SequenceFile文件是Hadoop用来存储二进制形式的key-value对而设计的一种平面文件(Flat File)。在SparkContext中,可以调用sequenceFilekeyClass, valueClass。
object对象文件
对象文件是将对象序列化后保存的文件,采用Java的序列化机制。可以通过objectFileT: ClassTag函数接收一个路径,读取对象文件,返回对应的RDD,也可以通过调用saveAsObjectFile()实现对对象文件的输出。因为是序列化所以要指定类型。
三种文件存取方式代码示例
保存
def main(args: Array[String]): Unit = {
val conf = new SparkConf().setMaster("local").setAppName("Partitioner")
val sc = new SparkContext(conf)
// 自定义分区器
// 自行决定数据存储的分区位置
val rdd = sc.makeRDD(
List(
("nba", "xxxx"),
("cba", "xxxx"),
("cba", "xxxx"),
("cba", "xxxx"),
("nba", "xxxx"),
("wnba", "xxxx"),
),3
)
rdd.saveAsTextFile("output1")
rdd.saveAsObjectFile("output2")
rdd.saveAsSequenceFile("output3")
sc.stop()
}
读取
def main(args: Array[String]): Unit = {
val conf = new SparkConf().setMaster("local").setAppName("Partitioner")
val sc = new SparkContext(conf)
// 自定义分区器
// 自行决定数据存储的分区位置
val rdd = sc.makeRDD(
List(
("nba", "xxxx"),
("cba", "xxxx"),
("cba", "xxxx"),
("cba", "xxxx"),
("nba", "xxxx"),
("wnba", "xxxx"),
),3
)
println(sc.textFile("output1").collect().mkString(","))
println(sc.objectFile[(String, String)]("output2").collect().mkString(","))
println(sc.sequenceFile[String, String]("output3").collect().mkString(","))
sc.stop()
}sc
5.3 累加器
累加器用来把Executor端变量信息聚合到Driver端。在Driver程序中定义的变量,在Executor端的每个Task都会得到这个变量的一份新的副本,每个task更新这些副本的值后,传回Driver端进行merge。
为什么使用累加器
def main(args: Array[String]): Unit = {
val conf: SparkConf = new SparkConf().setMaster("local[*]").setAppName("Acc")
val sc = new SparkContext(conf)
val rdd: RDD[Int] = sc.makeRDD(List(1, 2, 3, 4), 2)
var sum = 0
rdd.foreach(
num => {
sum = sum+num
}
)
println(sum)
// 释放资源
sc.stop()
}

如何使用累加器
通过上述的代码和图示我们已经了解了累加器使用的必要性,就是变量操作在算子外和算子内,导致结果不符合实际,那么接下来看看如何使用累加器,首先认识系统自带的累加器
- longAccumulator
- doubleAccumulator
- collectionAccumulator
使用累加器一共有3个步骤:
1.声明累加器 、2.使用累加器(add方法) 、3.收集累加器并获取值
def main(args: Array[String]): Unit = {
val conf: SparkConf = new SparkConf().setMaster("local[*]").setAppName("Acc")
val sc = new SparkContext(conf)
val rdd: RDD[Int] = sc.makeRDD(List(1, 2, 3, 4), 2)
// 声明累加器
val sum: LongAccumulator = sc.longAccumulator("sum")
rdd.foreach(
num => {
// 使用累加器
sum.add(num)
}
)
// 收集累加器并获取值
val res: lang.Long = sum.value
println(res)
// 释放资源
sc.stop()
}
自定义累加器
自定义累加器实现WordCount
自定义WordCount累加器
- 继承AccumulatorV2
- 确定泛型
IN : 向累加器中增加的值的类型
OUT : 累加器的结果就是输出- 重写方法
object Spark03_Acc_WordCount {
def main(args: Array[String]): Unit = {
val conf: SparkConf = new SparkConf().setMaster("local[*]").setAppName("WordCountAcc")
val sc = new SparkContext(conf)
val rdd = sc.makeRDD( List(
("Hello",1),("Spark",2),("Scala",5),("Hello",3)
),2
)
// 声明累加器
val wordCount = new WordCountAcc()
// 注册累加器
sc.register(wordCount,"wordCount")
rdd.foreach(
// 使用累加器
t => {
wordCount.add(t)
}
)
// 收集累加器并获取结果
val result: mutable.Map[String, Int] = wordCount.value
println(result)
// 释放资源
sc.stop()
}
// 自定义累加器
// IN : 向累加器中增加的值的类型
// OUT: 累加器的结果就是输出
class WordCountAcc extends AccumulatorV2[(String,Int),mutable.Map[String,Int]]{
val wordCountMap = mutable.Map[String,Int]()
override def isZero: Boolean = wordCountMap.isEmpty
override def copy(): AccumulatorV2[(String, Int), mutable.Map[String, Int]] = {
new WordCountAcc()
}
override def reset(): Unit = wordCountMap.clear()
// 将数据向累加器中增加
override def add(v: (String, Int)): Unit = {
val (word,cnt) = v
val oldCnt: Int = wordCountMap.getOrElse(word, 0)
wordCountMap.update(word,cnt + oldCnt)
}
// 合并累加器
override def merge(other: AccumulatorV2[(String, Int), mutable.Map[String, Int]]): Unit = {
val otherMap: mutable.Map[String, Int] = other.value
otherMap.foreach {
// 模式匹配
case (word, count) => {
val oldCnt: Int = this.wordCountMap.getOrElse(word, 0)
this.wordCountMap.update(word,count + oldCnt)
}
}
}
// 获取累加器的结果
override def value: mutable.Map[String, Int] = wordCountMap
}
}
5.4 广播变量
实现原理
广播变量用来高效分发较大的对象。向所有工作节点发送一个较大的只读值,以供一个或多个Spark操作使用。比如,如果你的应用需要向所有节点发送一个较大的只读查询表,广播变量用起来都很顺手。在多个并行操作中使用同一个变量,但是 Spark会为每个任务分别发送。
分布式共享只读变量。
为什么使用广播变量?
我们知道所有程序的执行都是在Executor端执行的,但是数据的传输都是从Driver端直接把数据发送到Executor端的Task中的。在解释这一问题前,我们还是需要先回顾一个旧的知识点:闭包!!!
Spark中的闭包:Driver中的数据是在算子之外,但是数据的执行是在算子之内,这就是闭包。
然而Spark中的闭包的数据的传输虽然是从Driver端到Executor端,其实,数据是从Driver端封装到Task中进行传输的,所以,闭包数据的传输,都是以Task为单位进行数据的传输的,RDD没有能力将数据直接传输到Execoutor端,如果一个Executor中有多个Task任务,我们既要保证每一个Task任务可以操作数据,但是还不能对数据进行影响,因为这样会导致其它的Task任务中的数据不准确,所以就有了广播变量,广播变量可以把数据从Driver端传输到Executor端,而不是Task,这样就可以做到数据的共享,但是为了每个Task端不受其他Task任务对数据的影响,我们的广播变量只允许读操作。详情请看图:
如何使用广播变量
- 在Driver端【算子外】声明广播变量
- 在Executor端【算子内】获取广播变量

代码示例:【不使用广播变量】
def main(args: Array[String]): Unit = {
val conf = new SparkConf().setMaster("local").setAppName("Bro")
val sc = new SparkContext(conf)
val rdd = sc.makeRDD(List(
("a", 1), ("b", 2), ("c", 3)
), 2)
val map: mutable.Map[String, Int] = mutable.Map(("a", 4), ("b", 5), ("c", 6))
// A => B
// ("a", 1) => (a, (1,4))
// ("b", 2) => (b, (2,5))
// ("c", 3) => (c, (3,6))
val rdd1: RDD[(String, (Int, Int))] = rdd.map {
case (k, v) => {
(k, (v, map.getOrElse(k, 0)))
}
}
rdd1.collect().foreach(println)
/*
输出结果:
(b,(2,5))
(a,(1,4))
(c,(3,6))
*/
sc.stop()
}
代码示例:【使用广播变量】
def main(args: Array[String]): Unit = {
val conf = new SparkConf().setMaster("local").setAppName("Acc")
val sc = new SparkContext(conf)
val rdd1 = sc.makeRDD(List(
("a", 1), ("b", 2), ("c", 3)
),2)
val map = mutable.Map(("a", 4), ("b", 5), ("c", 6))
// 在Driver端【算子外】声明广播变量
val bro: Broadcast[mutable.Map[String, Int]] = sc.broadcast(map)
val rdd2 = rdd1.map {
case ( k, v ) => {
// 在Executor端【算子内】获取广播变量
(k, ( v, bro.value.getOrElse(k,0) ))
}
}
rdd2.collect().foreach(println)
/*
输出结果:
(b,(2,5))
(a,(1,4))
(c,(3,6))
*/
sc.stop()
}
第六章 综合练习

上面的数据图是从数据文件中截取的一部分内容,表示为电商网站的用户行为数据,主要包含用户的4种行为:搜索,点击,下单,支付。数据规则如下:
Ø 数据文件中每行数据采用下划线分隔数据
Ø 每一行数据表示用户的一次行为,这个行为只能是4种行为的一种
Ø 如果搜索关键字为null,表示数据不是搜索数据
Ø 如果点击的品类ID和产品ID为-1,表示数据不是点击数据
Ø 针对于下单行为,一次可以下单多个商品,所以品类ID和产品ID可以是多个,id之间采用逗号分隔,如果本次不是下单行为,则数据采用null表示
Ø 支付行为和下单行为类似
详细字段说明:
| 编号 | 字段名称 | 字段类型 | 字段含义 |
|---|---|---|---|
| 1 | date | String | 用户点击行为的日期 |
| 2 | user_id | Long | 用户的ID |
| 3 | session_id | String | Session的ID |
| 4 | page_id | Long | 某个页面的ID |
| 5 | action_time | String | 动作的时间点 |
| 6 | search_keyword | String | 用户搜索的关键词 |
| 7 | click_category_id | Long | 某一个商品品类的ID |
| 8 | click_product_id | Long | 某一个商品的ID |
| 9 | order_category_ids | String | 一次订单中所有品类的ID集合 |
| 10 | order_product_ids | String | 一次订单中所有商品的ID集合 |
| 11 | pay_category_ids | String | 一次支付中所有品类的ID集合 |
| 12 | pay_product_ids | String | 一次支付中所有商品的ID集合 |
| 13 | city_id | Long | 城市 id |
样例类:
//用户访问动作表
case class UserVisitAction(
date: String,//用户点击行为的日期
user_id: Long,//用户的ID
session_id: String,//Session的ID
page_id: Long,//某个页面的ID
action_time: String,//动作的时间点
search_keyword: String,//用户搜索的关键词
click_category_id: Long,//某一个商品品类的ID
click_product_id: Long,//某一个商品的ID
order_category_ids: String,//一次订单中所有品类的ID集合
order_product_ids: String,//一次订单中所有商品的ID集合
pay_category_ids: String,//一次支付中所有品类的ID集合
pay_product_ids: String,//一次支付中所有商品的ID集合
city_id: Long
)//城市 id
6.1 需求1:Top10热门品类
6.1.1 需求说明
品类是指产品的分类,大型电商网站品类分多级,咱们的项目中品类只有一级,不同的公司可能对热门的定义不一样。我们按照每个品类的点击、下单、支付的量来统计热门品类。
鞋 点击数 下单数 支付数
衣服 点击数 下单数 支付数
电脑 点击数 下单数 支付数
例如,综合排名 = 点击数20%+下单数30%+支付数*50%
本项目需求优化为:先按照点击数排名,靠前的就排名高;如果点击数相同,再比较下单数;下单数再相同,就比较支付数。
6.1.2 实现方案一
6.1.2.1 需求分析
分别统计每个品类点击的次数,下单的次数和支付的次数:
(品类,点击总数)(品类,下单总数)(品类,支付总数)
6.1.2.2 需求实现
6.1.3 实现方案二
6.1.3.1 需求分析
一次性统计每个品类点击的次数,下单的次数和支付的次数:
(品类,(点击总数,下单总数,支付总数))
6.1.3.2 需求实现
6.1.4 实现方案三
6.1.4.1 需求分析
使用累加器的方式聚合数据
6.1.4.2 需求实现
6.1.5 实现方案四
6.1.5.1 需求分析
使用累加器的方式聚合数据
6.1.5.2 需求实现
6.2 需求2:Top10热门品类中每个品类的Top10活跃Session统计
6.2.1 需求说明
在需求一的基础上,增加每个品类用户session的点击统计
6.2.2 需求分析
6.2.3 功能实现
6.3 需求3:页面单跳转换率统计
6.3.1 需求说明
1)页面单跳转化率
计算页面单跳转化率,什么是页面单跳转换率,比如一个用户在一次 Session 过程中访问的页面路径 3,5,7,9,10,21,那么页面 3 跳到页面 5 叫一次单跳,7-9 也叫一次单跳,那么单跳转化率就是要统计页面点击的概率。
比如:计算 3-5 的单跳转化率,先获取符合条件的 Session 对于页面 3 的访问次数(PV)为 A,然后获取符合条件的 Session 中访问了页面 3 又紧接着访问了页面 5 的次数为 B,那么 B/A 就是 3-5 的页面单跳转化率。

2)统计页面单跳转化率意义
产品经理和运营总监,可以根据这个指标,去尝试分析,整个网站,产品,各个页面的表现怎么样,是不是需要去优化产品的布局;吸引用户最终可以进入最后的支付页面。
数据分析师,可以此数据做更深一步的计算和分析。
企业管理层,可以看到整个公司的网站,各个页面的之间的跳转的表现如何,可以适当调整公司的经营战略或策略。
6.3.2 需求分析
.value.getOrElse(k,0) ))
}
}
rdd2.collect().foreach(println)
/*
输出结果:
(b,(2,5))
(a,(1,4))
(c,(3,6))
*/
sc.stop()
}
## 第六章 综合练习
[外链图片转存中...(img-KcVcYkgd-1618326239544)]
上面的数据图是从数据文件中截取的一部分内容,表示为电商网站的用户行为数据,主要包含用户的4种行为:搜索,点击,下单,支付。数据规则如下:
Ø 数据文件中每行数据采用下划线分隔数据
Ø 每一行数据表示用户的一次行为,这个行为只能是4种行为的一种
Ø 如果搜索关键字为null,表示数据不是搜索数据
Ø 如果点击的品类ID和产品ID为-1,表示数据不是点击数据
Ø 针对于下单行为,一次可以下单多个商品,所以品类ID和产品ID可以是多个,id之间采用逗号分隔,如果本次不是下单行为,则数据采用null表示
Ø 支付行为和下单行为类似
**详细字段说明:**
| 编号 | 字段名称 | 字段类型 | 字段含义 |
| ---- | ------------------ | -------- | -------------------------- |
| 1 | date | String | 用户点击行为的日期 |
| 2 | user_id | Long | 用户的ID |
| 3 | session_id | String | Session的ID |
| 4 | page_id | Long | 某个页面的ID |
| 5 | action_time | String | 动作的时间点 |
| 6 | search_keyword | String | 用户搜索的关键词 |
| 7 | click_category_id | Long | 某一个商品品类的ID |
| 8 | click_product_id | Long | 某一个商品的ID |
| 9 | order_category_ids | String | 一次订单中所有品类的ID集合 |
| 10 | order_product_ids | String | 一次订单中所有商品的ID集合 |
| 11 | pay_category_ids | String | 一次支付中所有品类的ID集合 |
| 12 | pay_product_ids | String | 一次支付中所有商品的ID集合 |
| 13 | city_id | Long | 城市 id |
**样例类:**
//用户访问动作表
case class UserVisitAction(
date: String,//用户点击行为的日期
user_id: Long,//用户的ID
session_id: String,//Session的ID
page_id: Long,//某个页面的ID
action_time: String,//动作的时间点
search_keyword: String,//用户搜索的关键词
click_category_id: Long,//某一个商品品类的ID
click_product_id: Long,//某一个商品的ID
order_category_ids: String,//一次订单中所有品类的ID集合
order_product_ids: String,//一次订单中所有商品的ID集合
pay_category_ids: String,//一次支付中所有品类的ID集合
pay_product_ids: String,//一次支付中所有商品的ID集合
city_id: Long
)//城市 id
### 6.1 需求1:Top10热门品类
#### 6.1.1 需求说明
品类是指产品的分类,大型电商网站品类分多级,咱们的项目中品类只有一级,不同的公司可能对热门的定义不一样。我们按照每个品类的点击、下单、支付的量来统计热门品类。
鞋 点击数 下单数 支付数
衣服 点击数 下单数 支付数
电脑 点击数 下单数 支付数
例如,综合排名 = 点击数*20%+下单数*30%+支付数*50%
本项目需求优化为:**先按照点击数排名,靠前的就排名高;如果点击数相同,再比较下单数;下单数再相同,就比较支付数。**
#### 6.1.2 实现方案一
##### 6.1.2.1 需求分析
分别统计每个品类点击的次数,下单的次数和支付的次数:
(品类,点击总数)(品类,下单总数)(品类,支付总数)
##### 6.1.2.2 需求实现
#### 6.1.3 实现方案二
##### 6.1.3.1 需求分析
一次性统计每个品类点击的次数,下单的次数和支付的次数:
(品类,(点击总数,下单总数,支付总数))
##### 6.1.3.2 需求实现
#### 6.1.4 实现方案三
##### 6.1.4.1 需求分析
使用累加器的方式聚合数据
##### 6.1.4.2 需求实现
#### 6.1.5 实现方案四
##### 6.1.5.1 需求分析
使用累加器的方式聚合数据
##### 6.1.5.2 需求实现
### 6.2 需求2:Top10热门品类中每个品类的Top10活跃Session统计
#### 6.2.1 需求说明
在需求一的基础上,增加每个品类用户session的点击统计
#### 6.2.2 需求分析
#### 6.2.3 功能实现
### 6.3 需求3:页面单跳转换率统计
#### 6.3.1 需求说明
1)页面单跳转化率
计算页面单跳转化率,什么是页面单跳转换率,比如一个用户在一次 Session 过程中访问的页面路径 3,5,7,9,10,21,那么页面 3 跳到页面 5 叫一次单跳,7-9 也叫一次单跳,那么单跳转化率就是要统计页面点击的概率。
比如:计算 3-5 的单跳转化率,先获取符合条件的 Session 对于页面 3 的访问次数(PV)为 A,然后获取符合条件的 Session 中访问了页面 3 又紧接着访问了页面 5 的次数为 B,那么 B/A 就是 3-5 的页面单跳转化率。
[外链图片转存中...(img-bal8s-1618326239545)]
2)统计页面单跳转化率意义
产品经理和运营总监,可以根据这个指标,去尝试分析,整个网站,产品,各个页面的表现怎么样,是不是需要去优化产品的布局;吸引用户最终可以进入最后的支付页面。
数据分析师,可以此数据做更深一步的计算和分析。
企业管理层,可以看到整个公司的网站,各个页面的之间的跳转的表现如何,可以适当调整公司的经营战略或策略。
#### 6.3.2 需求分析
#### 6.3.3 功能实现