sqoop 基础
Sqoop
产生背景
1) RDBMS ==> Hadoop
file ==> load hive
shell ==> file ==> HDFS
MapReduce: DBInputFormat TextOutputFormat
2) Hadoop ==> RDBMS
MapReduce: TextInputFormat DBOutputFormat
存在的问题
1) MR 麻烦
2) 效率低: 新的业务线 写一个MR
==> 抽取一个框架
1) RDBMS层面的: driver/username/password/url/database/table/sql
2) Hadoop层面的:hdfs path/分隔符/mappers/reducers
3) 扩展一:当有一个新的业务线接入以后,那么我们只需要将新的业务线对应的参数传递给mapreduce即可
A) hadoop jar的方式来提交
B) 动态的根据业务线传入参数
4) 扩展二:OK了吗?爽了吗? ==> 工匠精神
思路是什么? ==> WebUI + DB Configuration ==> UIUE
使用Spring Boot微服务建构大数据平台
Sqoop是什么
Apache Sqoop(TM) is a tool designed for
efficiently transferring bulk data
between Apache Hadoop and structured datastores
such as relational databases(RDBMS 关系型数据库).
RDBMS <==> Hadoop(HDFS/Hive/HBase....)
Note that 1.99.7 is not compatible with 1.4.6 and not feature complete,
it is not intended for production deployment.
sqoop1和sqoop2是不兼容,就好比struts1和struts2
Sqoop: SQL-to-Hadoop
SQoops
连接传统数据库到Hadoop之间的一个桥梁
MapReduce:一定有Mapper和Reduce吗?
使用mapreduce来完成导入操作,是否需要reduce?
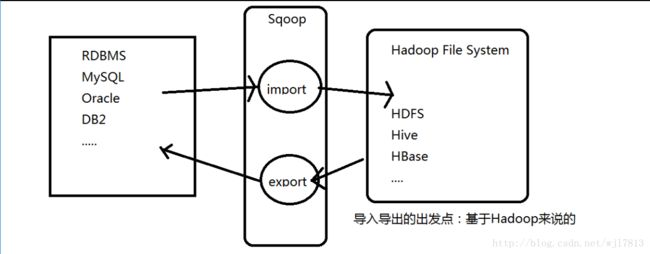
sqoop1架构
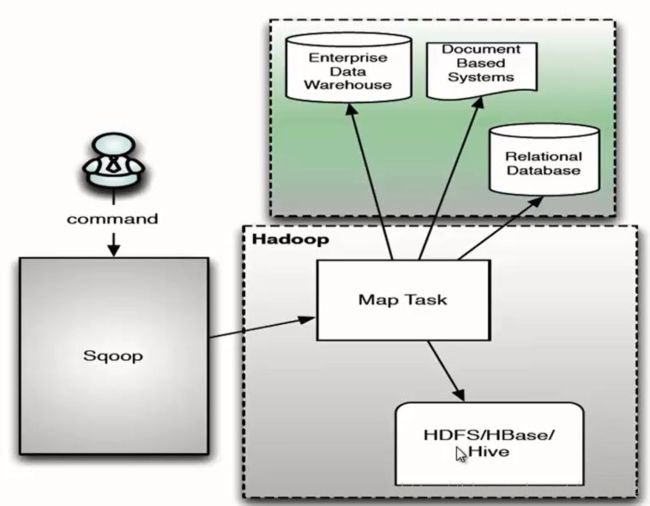
sqoop2 架构:

相关官方文档
http://archive.cloudera.com/cdh5/cdh/5/sqoop-1.4.6-cdh5.7.0/SqoopUserGuide.html
http://sqoop.apache.org/docs/1.4.7/SqoopUserGuide.html
测试环境相关:
[hadoop@node1 ~]$ echo $HIVE_HOME;echo $HADOOP_HOME
/home/hadoop/app/hive-1.1.0-cdh5.7.0
/home/hadoop/app/hadoop-2.6.0-cdh5.7.0
---- sqoop 安装 配置===
[hadoop@node1 software]$ tar xf sqoop-1.4.6-cdh5.7.0.tar.gz -C /home/hadoop/app/
添加 sqoop的环境变量
[hadoop@node1 ~]$ cat /home/hadoop/.bash_profile |grep SQOOP
export SQOOP_HOME=/home/hadoop/app/sqoop-1.4.6-cdh5.7.0
export PATH=$PATH:$SQOOP_HOME/bin
修改
[hadoop@node1 conf]$ pwd
/home/hadoop/app/sqoop-1.4.6-cdh5.7.0/conf
[hadoop@node1 conf]$ cp -rp sqoop-env-template.sh sqoop-env.sh
[hadoop@node1 conf]$ echo $HIVE_HOME ;echo $HADOOP_HOME
/home/hadoop/app/hive-1.1.0-cdh5.7.0
/home/hadoop/app/hadoop-2.6.0-cdh5.7.0
echo "export HADOOP_COMMON_HOME=$HADOOP_HOME" >> sqoop-env.sh
echo "export HADOOP_MAPRED_HOME=$HADOOP_HOME" >> sqoop-env.sh
echo "export HIVE_HOME=$HIVE_HOME" >> sqoop-env.sh
# 如果需要把RDBMS导入到HBASE的时候,需要设置 export HBASE_HOME=...
# 因为环境中没有安装zookeeper,也不需要设置export ZOOCFGDIR=...
[hadoop@node1 ~]$ sqoop help
Warning: /home/hadoop/app/sqoop-1.4.6-cdh5.7.0/../hcatalog does not exist! HCatalog jobs will fail.
Please set $HCAT_HOME to the root of your HCatalog installation.
Warning: /home/hadoop/app/sqoop-1.4.6-cdh5.7.0/../accumulo does not exist! Accumulo imports will fail.
Please set $ACCUMULO_HOME to the root of your Accumulo installation.
18/02/21 17:30:53 INFO sqoop.Sqoop: Running Sqoop version: 1.4.6-cdh5.7.0
usage: sqoop COMMAND [ARGS]
Available commands:
codegen Generate code to interact with database records
create-hive-table Import a table definition into Hive
eval Evaluate a SQL statement and display the results
export Export an HDFS directory to a database table
help List available commands
import Import a table from a database to HDFS
import-all-tables Import tables from a database to HDFS
import-mainframe Import datasets from a mainframe server to HDFS
job Work with saved jobs
list-databases List available databases on a server
list-tables List available tables in a database
merge Merge results of incremental imports
metastore Run a standalone Sqoop metastore
version Display version information
See 'sqoop help COMMAND' for information on a specific command.
上面的报错信息 ,可以不用在意 。
如果在意的话, 可以修改$ZOOKEEPER_HOME/bin/configure-sqoop 注释掉HCatalog,Accumulo检查
$ZOOKEEPER_HOME
$ACCUMULO_HOME
这些warn如果用到了可以加到环境变量,没有用到也没关系
[hadoop@node1 software]$ cp -rp mysql-connector-java-5.1.40-bin.jar /home/hadoop/app/sqoop-1.4.6-cdh5.7.0/lib/
[hadoop@node1 software]$ unzip java-json.jar.zip
[hadoop@node1 software]$ cp -rp java-json.jar /home/hadoop/app/sqoop-1.4.6-cdh5.7.0/lib/
unzip /tmp/java-json.jar.zip
# 将mysql库中的表导入到hdfs中时,报错缺包java-json.jar
# 该包的下载地址:http://www.java2s.com/Code/Jar/j/Downloadjavajsonjar.htm
# 存在BUG,需要复制包,否则sqoop import到hive的时候报错
[hadoop@node1 ~]$ cp -rp /home/hadoop/app/hive-1.1.0-cdh5.7.0/lib/hive-common-1.1.0-cdh5.7.0.jar /home/hadoop/app/sqoop-1.4.6-cdh5.7.0/lib/
[hadoop@node1 ~]$ cp -rp /home/hadoop/app/hive-1.1.0-cdh5.7.0/lib/hive-shims-* /home/hadoop/app/sqoop-1.4.6-cdh5.7.0/lib/
sqoop list-databases --help 查看 帮助
sqoop list-databases \
--connect jdbc:mysql://node1.oracle.com:3306 \
--username root \
--password oracle
Caused by: java.sql.SQLException: Access denied for user 'root'@'node1.oracle.com' (using password: YES)
grant all privileges on *.* to 'root'@'node1.oracle.com 'identified by 'oracle' with grant option;
flush privileges;
sqoop list-tables \
--connect jdbc:mysql://node1.oracle.com:3306/employees \
--username root \
--password oracle
sqoop list-tables \
--connect jdbc:oracle:thin:@192.168.137.251:1521:devdb \
--username hr \
--password hr
[hadoop@node1 ~]$ sqoop list-tables --connect jdbc:oracle:thin:@192.168.137.251:1521:devdb --username hr --password hr
MySQL数据导入到HDFS
sqoop import \
--connect jdbc:mysql://node1.oracle.com:3306/use_hive \
--username root \
--password oracle \
--table emp
Oracle数据导入到HDFS 中
sqoop 默认导入的分片数量是4
sqoop import \
--connect jdbc:oracle:thin:@192.168.137.251:1521:devdb \
--username hr \
--password hr \
--table EMPLOYEES
[hadoop@node1 ~]$ hadoop fs -ls
Found 2 items
drwxr-xr-x - hadoop supergroup 0 2018-02-23 15:52 EMPLOYEES
drwxr-xr-x - hadoop supergroup 0 2018-02-23 15:44 emp
[hadoop@node1 ~]$ hadoop fs -ls /user/hadoop/
Found 2 items
drwxr-xr-x - hadoop supergroup 0 2018-02-23 15:52 /user/hadoop/EMPLOYEES
drwxr-xr-x - hadoop supergroup 0 2018-02-23 15:44 /user/hadoop/emp
[hadoop@node1 ~]$ hadoop fs -ls emp
Found 5 items
-rw-r--r-- 1 hadoop supergroup 0 2018-02-23 15:44 emp/_SUCCESS
-rw-r--r-- 1 hadoop supergroup 93 2018-02-23 15:44 emp/part-m-00000
-rw-r--r-- 1 hadoop supergroup 95 2018-02-23 15:44 emp/part-m-00001
-rw-r--r-- 1 hadoop supergroup 194 2018-02-23 15:44 emp/part-m-00002
-rw-r--r-- 1 hadoop supergroup 281 2018-02-23 15:44 emp/part-m-00003
[hadoop@node1 ~]$ hadoop fs -text emp/part-m-00003
7839,KING,PRESIDENT,null,1981-11-17,5000,null,10
7844,TURNER,SALESMAN,7698,1981-09-08,1500,0,30
7876,ADAMS,CLERK,7788,1987-07-13,1100,null,20
7900,JAMES,CLERK,7698,1981-12-03,950,null,30
7902,FORD,ANALYST,7566,1981-12-03,3000,null,20
7934,MILLER,CLERK,7782,1982-01-23,1300,null,10
作业:hadoop fs -ls和hadoop fs -ls / 的区别?
控制并行分片数量 和
sqoop import \
--connect jdbc:mysql://node1.oracle.com:3306/use_hive \
--username root \
--password oracle \
--table emp \
--delete-target-dir \
--num-mappers 4
[hadoop@node1 ~]$ hadoop fs -text emp/part-m-00000
7369,SMITH,CLERK,7902,1980-12-17,800,null,20
7499,ALLEN,SALESMAN,7698,1981-02-20,1600,300,30
7521,WARD,SALESMAN,7698,1981-02-22,1250,500,30
7566,JONES,MANAGER,7839,1981-04-02,2975,null,20
7654,MARTIN,SALESMAN,7698,1981-09-28,1250,1400,30
7698,BLAKE,MANAGER,7839,1981-05-01,2850,null,30
7782,CLARK,MANAGER,7839,1981-06-09,2450,null,10
7788,SCOTT,ANALYST,7566,1987-07-13,3000,null,20
7839,KING,PRESIDENT,null,1981-11-17,5000,null,10
7844,TURNER,SALESMAN,7698,1981-09-08,1500,0,30
7876,ADAMS,CLERK,7788,1987-07-13,1100,null,20
7900,JAMES,CLERK,7698,1981-12-03,950,null,30
7902,FORD,ANALYST,7566,1981-12-03,3000,null,20
7934,MILLER,CLERK,7782,1982-01-23,1300,null,10
--控制 mapreduce-job-name 名字
sqoop import \
--connect jdbc:mysql://node1.oracle.com:3306/use_hive \
--username root \
--password oracle \
--table emp \
--delete-target-dir \
--num-mappers 4 \
--mapreduce-job-name emp-all \
--fields-terminated-by '\t' \
--null-non-string '0' \
--null-string ''
---控制选择那些列 需要导入HDFS 中
sqoop import \
--connect jdbc:mysql://node1.oracle.com:3306/use_hive \
--username root \
--password oracle \
--table emp \
--delete-target-dir \
--num-mappers 4 \
--mapreduce-job-name emp-all \
--columns "EMPNO,ENAME,JOB,SAL,COMM"
[hadoop@node1 ~]$ hadoop fs -text emp/part-m-00000
7369,SMITH,CLERK,800,null
7499,ALLEN,SALESMAN,1600,300
---控制 导入指定HDFS中路径
sqoop import \
--connect jdbc:mysql://node1.oracle.com:3306/use_hive \
--username root \
--password oracle \
--table emp \
--delete-target-dir \
--num-mappers 4 \
--mapreduce-job-name emp-all \
--columns "EMPNO,ENAME,JOB,SAL,COMM" \
--target-dir EMP_COLUMN
---指定过滤条件导入到HDFS 中
需要注意单双引号的使用(双引号需要转义)
使用 --e或是 --query 都可以
sqoop import \
--connect jdbc:mysql://node1.oracle.com:3306/use_hive \
--username root \
--password oracle \
--delete-target-dir \
--num-mappers 1 \
--mapreduce-job-name emp-query \
--columns "EMPNO,ENAME,JOB,SAL,COMM" \
--target-dir EMP_COLUMN \
--query "select * from emp where sal > 2000"
Cannot specify --query and --table together. 注意该错误
sqoop import \
--connect jdbc:mysql://node1.oracle.com:3306/use_hive \
--username root \
--password oracle \
--delete-target-dir \
--num-mappers 1 \
--mapreduce-job-name emp-query \
--columns "EMPNO,ENAME,JOB,SAL,COMM" \
--target-dir EMP_COLUMN \
--query "select * from emp where sal > 2000 and \$CONDITIONS"
sqoop import \
--connect jdbc:mysql://node1.oracle.com:3306/use_hive \
--username root \
--password oracle \
--num-mappers 1 \
--delete-target-dir \
--mapreduce-job-name emp-query1 \
--columns "EMPNO,ENAME,JOB,SAL,COMM" \
--target-dir EMP_QUERY1 \
--query 'select * from emp where sal>2000 and $CONDITIONS'
sqoop import \
--connect jdbc:mysql://node1.oracle.com:3306/use_hive \
--username root \
--password oracle \
--num-mappers 1 \
--delete-target-dir \
--mapreduce-job-name emp-query2 \
--columns "EMPNO,ENAME,JOB,SAL,COMM" \
--target-dir EMP_QUERY2 \
--e 'select * from emp where sal>2000 and $CONDITIONS'
作业:
1) 将输出文件设置为parquet或者sequencefile格式
2) 对输出文件进行压缩
3) 将多个表的统计结果导出到HDFS
4) 导出没有主键的表,并且要使用多个mapper
===将输出文件设置为parquet或者sequencefile格式==
sqoop 默认导出的文件格式是 textfile
--as-avrodatafile
--as-parquetfile
--as-sequencefile
sqoop import \
--connect jdbc:mysql://node1.oracle.com:3306/use_hive \
--username root \
--password oracle \
--table emp \
--num-mappers 4 \
--delete-target-dir \
--mapreduce-job-name emp_import_parquet \
--target-dir emp_import_parquet \
--as-parquetfile
===对输出文件进行压缩==
sqoop import \
--connect jdbc:mysql://node1.oracle.com:3306/use_hive \
--username root \
--password oracle \
--table emp \
--num-mappers 4 \
--delete-target-dir \
--mapreduce-job-name emp_import_parquet_compress \
--target-dir emp_import_parquet_compress \
--as-parquetfile \
--compression-codec org.apache.hadoop.io.compress.SnappyCodec \
--fields-terminated-by '\t'
导入到HDFS中的如果文件格式是parquet的话,是不支持 BZip 压缩的
sqoop import \
--connect jdbc:mysql://node1.oracle.com:3306/use_hive \
--username root \
--password oracle \
--table emp \
--num-mappers 4 \
--delete-target-dir \
--mapreduce-job-name emp_import_bzip2_compress \
--target-dir emp_import_bizip2_compress \
--compression-codec org.apache.hadoop.io.compress.BZip2Codec \
--fields-terminated-by '\t'
=====多个表的统计结果导出到HDFS====
sqoop import \
--connect jdbc:mysql://node1.oracle.com:3306/use_hive \
--username root \
--password oracle \
--num-mappers 1 \
--delete-target-dir \
--mapreduce-job-name emp-query3 \
--columns "EMPNO,ENAME,JOB,SAL,COMM" \
--target-dir EMP_QUERY3 \
--e 'select * from emp e,dept d where e.deptno=d.deptno and e.sal > 2000 and $CONDITIONS'
sqoop import \
--connect jdbc:mysql://node1.oracle.com:3306/use_hive \
--username root \
--password oracle \
--num-mappers 1 \
--delete-target-dir \
--mapreduce-job-name emp--dept-join1 \
--columns "EMPNO,ENAME,JOB,SAL,COMM" \
--target-dir emp_dept_join1 \
--fields-terminated-by '\t' \
--null-non-string '0' \
--null-string '' \
--e 'select * from emp e join dept d on e.deptno = d.deptno and e.sal > 2000 and $CONDITIONS'
and $CONDITIONS
====导入没有主键的表 到 HDFS 中===
sqoop import \
--connect jdbc:mysql://node1.oracle.com:3306/use_hive \
--username root \
--password oracle \
--table salgrage
ERROR tool.ImportTool: Error during import: No primary key could be found for table salgrage. Please specify one with --split-by or perform a sequential import with '-m 1'.
1) map = 4
2) 没主键,如何切分数据?
sqoop import \
--connect jdbc:mysql://node1.oracle.com:3306/use_hive \
--username root \
--password oracle \
--table salgrage \
--split-by GRADE \
--delete-target-dir \
--num-mappers 2
作业:hadoop fs -ls和hadoop fs -ls / 的区别
测试:
-m的用法
删除目标文件
设置mr作业的名称
只抽取指定字段
设置指定路径
sqoop import \
--connect jdbc:mysql://hadoop000:3306/sqoop \
--username root \
--password root \
--table emp \
-m 1 \
--delete-target-dir \
--mapreduce-job-name emp-all \
--columns "EMPNO,ENAME,JOB,SAL,COMM" \
--target-dir EMP_COLUMN \
--where "SAL>2000"
sqoop import --connect jdbc:mysql://hadoop000:3306/sqoop --username root --password root -m 1 --delete-target-dir --mapreduce-job-name emp-all --columns "EMPNO,ENAME,JOB,SAL,COMM" --target-dir EMP_COLUMN --query 'select * from emp where sal>2000 and $CONDITIONS'
作业:
1) 将输出文件设置为parquet或者sequencefile格式
2) 对输出文件进行压缩
3) 将多个表的统计结果导出到HDFS
4) 导出没有主键的表,并且要使用多个mapper
====== sqoop 导入 处理 分隔符 和 null 值问题 ==
sqoop import \
--connect jdbc:mysql://node1.oracle.com:3306/use_hive \
--username root \
--password oracle \
--table emp \
--num-mappers 1 \
--delete-target-dir \
--mapreduce-job-name emp-split \
--columns "EMPNO,ENAME,JOB,SAL,COMM" \
--target-dir EMP_SPLIT \
--fields-terminated-by '\t'
sqoop import \
--connect jdbc:mysql://node1.oracle.com:3306/use_hive \
--username root \
--password oracle \
--table emp \
--num-mappers 1 \
--delete-target-dir \
--mapreduce-job-name emp-split1 \
--columns "EMPNO,ENAME,JOB,SAL,COMM" \
--target-dir EMP_SPLIT1 \
--fields-terminated-by '\t' \
--null-non-string '0' \
--null-string ''
===sqoop 导入时HDFS时direct方式 ===
sqoop import \
--connect jdbc:mysql://node1.oracle.com:3306/use_hive \
--username root \
--password oracle \
--table emp \
--num-mappers 1 \
--delete-target-dir \
--mapreduce-job-name emp-split1 \
--columns "EMPNO,ENAME,JOB,SAL,COMM" \
--target-dir EMP_SPLIT1 \
--fields-terminated-by '\t' \
--null-non-string '0' \
--null-string '' \
--direct
INFO tool.ImportTool: Destination directory EMP_SPLIT1 deleted.
WARN manager.DirectMySQLManager: Direct-mode import from MySQL does not support column
direct 不支持列模式
sqoop import \
--connect jdbc:mysql://node1.oracle.com:3306/use_hive \
--username root \
--password oracle \
--table emp \
--num-mappers 1 \
--delete-target-dir \
--mapreduce-job-name emp-split2 \
--target-dir EMP_SPLIT2 \
--fields-terminated-by '\t' \
--null-non-string '0' \
--null-string '' \
--direct
INFO manager.DirectMySQLManager: Beginning mysqldump fast path import
INFO mapreduce.ImportJobBase: Beginning import of emp
==== eval的使用===
sqoop eval \
--connect jdbc:mysql://node1.oracle.com:3306/use_hive \
--username root \
--password oracle \
--query "select * from emp where deptno=10"
# 使用eval指定一个SQL查询,将查询的结果直接显示到控制台上
# 不再需要参数$CONDITIONS了
======= options-file的使用:工作中推荐使用==
import
--connect
jdbc:mysql://node1.oracle.com:3306/mysql
--username
root
--password
oracle
--mapreduce-job-name
FromMySQL2HDFS
--delete-target-dir
--fields-terminated-by
\t
--num-mappers
2
--null-non-string
0
--target-dir
/user/hadoop/USER_COLUMN_SPLIT
--query
select Host,User from mysql.user where host='localhost' and $CONDITIONS
--split-by
'host'
--direct
sqoop --options-file /home/hadoop/sqoop_import.txt
# 写一个命令参数文件,文件格式是一行命令一行参数
# 需要将SQL语句两边引起来的单引号和双引号去掉,一些需要引号引起来的参数也不在需要引号了
# 因为是写入文件之中的,脱离了shell直接执行的情况,$符号不需要转义了
====sqoop export ==
sqoop export --help 查看帮助
# 使用export导出HDFS中的表到mysql中,用法和import相类似
# 区别是 需要提前在mysql中创建能够存放导出数据的表,字段数量类型要一致
mysql> create table emp_demo as select * from emp where 1=2;
ERROR 1786 (HY000): CREATE TABLE ... SELECT is forbidden when @@GLOBAL.ENFORCE_GTID_CONSISTENCY = 1.
需要 在MySQL 5.6 gtid 环境中的一些限制
mysql> create table emp_demo like emp;
Query OK, 0 rows affected (0.14 sec)
mysql> select * from emp_demo;
Empty set (0.00 sec)
sqoop export \
--connect jdbc:mysql://node1.oracle.com:3306/use_hive \
--username root \
--password oracle \
--table emp_demo \
--export-dir /user/hadoop/emp \
--num-mappers 1
mysql> select count(*) from emp_demo;
+----------+
| count(*) |
+----------+
| 14 |
+----------+
1 row in set (0.02 sec)