物联网架构之HBase
**
物联网架构之HBase
技能目标
- 了解 HBase 体系结构
- 理解 HBase 数据模型
- 掌握 HBase 的安装
- 会使用 HBase Shell 操作 HBase
一、案例概述

**
二、案例前置知识点
**
HBase简介
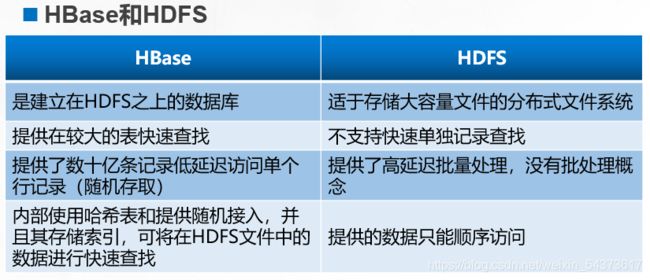
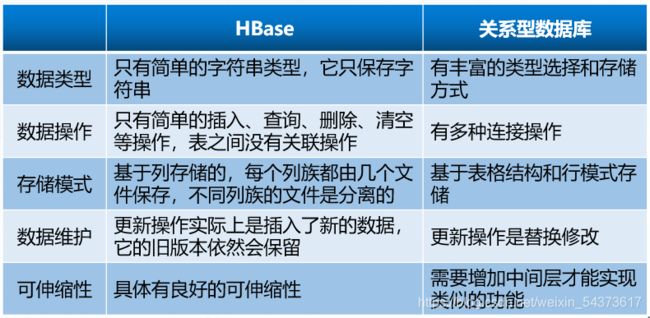
HBase 是数据库,但并不是传统的关系型数据库,HBase 不使用以行存储的关系型结构存储数据,而是以键值对方式按列存储,由此可以认为它是非关系型数据库 NoSQL(Not Only SQL)中的一个重要代表。

NoSQL目前并没有明确的范围和定义,主要特点是通常用于大规模数据的存储、没有预定义的模式(如表结构)、表和表之间没有复杂的关系。
总体上可将 NoSQL 数据库分为以下四类:
- 基于列存储的类型
- 基于文档存储的类型
- 基于键值对存储的类型
- 基于图形数据存储的类型
通常,人们将 HBase 归为基于列存储类型。在 NoSQL 领域,HBase 本身不是最优秀。但得益于与 Hadoop 的整合,给它带来了更广阔的发展空间。HBase 本质上只有插入操作,更新和删除都是使用插入方式完成,这是由底层 HDFS 流式访问特性(一次写入、多次读取)决定的。所以,在更新时总是插入一个带时间戳的新行,而删除时插入一个带有删除标记的新行。每一次的插入都有一个时间戳标记,每次都是一个新的版本HBase 会保留一定数量的版本(这个值是可以设定的)。如果在查询时提供时间戳,则返回距离该时间最近的版本;否则返回离现在最近的版本。
**
HBase和HDFS的关系
**
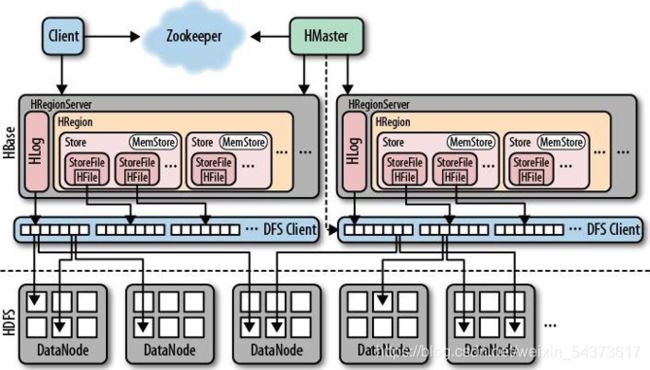
HBase体系结构

**
HRegion
HBase 使用表(Table)存储数据集,表由行和列组成,这与关系型数据库类似。但是,当表的大小超过设定值时,HBase 会自动将表划分为不同的区域(Region)。每个区域称为 HRegion,它是 HBase 集群上分布式存储和负载均衡的最小单位,在这点上表和 HRegion 类似于 HDFS 中文件与文件块的概念。一个 HRegion 中保存一个表中一段连续的数据,通过表名和主键范围(开始主键~结束主键)区分每一个HRegion。

一开始,一个表只有一个 Hregion。随着 HRegion 开始变大,直到超出设定的大小阈值,便会在某行的边界上把表分成两个大小基本相同的 HRegion,称为HRegion 分裂。如下图所示

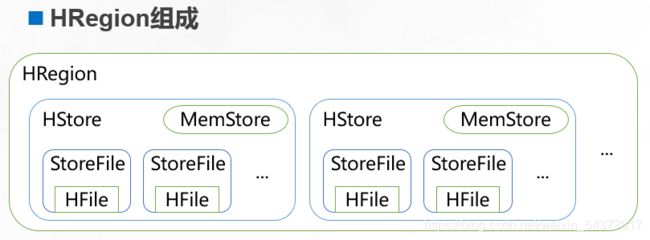
每个 HRegion 由多个 HStore 组成,每个 HStore 对应表中一个列族(ColumnFamily)的存储,列族在后面还会详细介绍。HStore 由两部分组成:MemStore 和StoreFile。用户写入的数据首先放入 MemStore,当 MemStore 满了以后再刷入(flush)StoreFile。StoreFile 是 HBase 中的最小存储单元,底层最终由 HFile 实现,而 HFile是键值对数据的存储格式,实质是 HDFS 的二进制格式文件。HBase 中不能直接更新和删除数据,所有的数据均通过追加的方式进行更新。当StoreFile 的 数 量 超 过 设 定 的 阈 值 将 触 发 合 并 操 作 , 将 多 个 StoreFile 合 并 为 一 个StoreFile,此时进行数据的更新和删除。
**
HRegionServer
HRegionServer 负责响应用户 I/O 请求,向 HDFS 中读写数据,一台机器上只运行一个 HRegionServer。HRegionServer 包含两部分:HLog 部分和 HRegion 部分。其中 HLog 用于存储数据日志,实质是 HDFS 的 Sequence File。到达 HRegion的写操作首先被追加到日志中,然后才被加入内存中的 MemStore。HLog 文件主要用于故障恢复。例如某台 HRegionServer 发生故障,那么它所维护的 HRegion 会被重新分配到新的机器上,新的 HRegionServer 在加载 HRegion 的时候可以通过 HLog对数据进行恢复。
HRegion 部分由多个 HRegion 组成,每个 HRegion 对应了表中的一个分块,并且每一个 HRegion 只会被一个 HRegionServer 管理。


**
HMaster
每台 HRegionServer 都会和 HMaster 服务器通信,HMaster 的主要任务就是告诉每个 HRegionServer 它要维护的 HRegion。
在 HBase 中可以启动多个 HMaster,通过 ZooKeeper 的 Master 选举机制来保证系统中总有一个 Master 在运行。HMaster 的具体功能包括:
- 管理用户对表的增、删、改、查操作;
- 管理 HRegionServer 的负载均衡,调整 HRegion 分布;
- 在 HRegion 分裂后,负责新的 HRegion 分配;
- 在 HRegionServer 停机后,负责失效 HRegionServer 上的 HRegion 迁移。

**
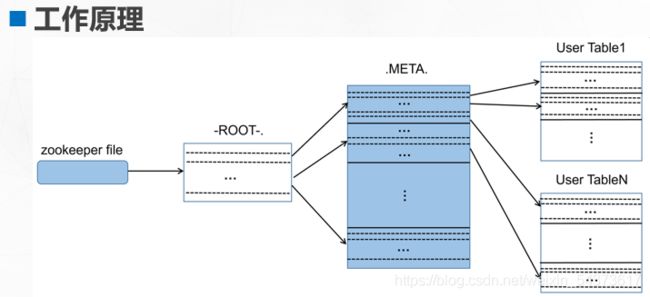
ZooKeeper
ZooKeeper 存储的是 HBase 中的 ROOT 表和 META 表的位置,这是 HBase 中两张特殊的表,称为根数据表(ROOT)和元数据表(META)。META 表记录普通用户表的 HRegion 标识符信息,每个 HRegion 的标识符为:表名+开始主键+唯一 ID。
随着用户表的 HRegion 分裂,META 表的信息也会增长,并且可能还会被分割为几个 HRegion。此时,可以用一个 ROOT 表来保存 META 的 HRegion 信息,而ROOT 表是不能被分割的,也就是 ROOT 表只有一个 HRegion。那么客户端(Client)在访问用户数据前需要首先访问 ZooKeeper,然后访问 ROOT 表,接着访问 META表,最后才能找到用户数据的位置进行访问,如图下所示。

**
HBase与关系型数据库的区别
**
HBase 数据模型
(1)数据模型
在 HBase 中,数据以表的方式存储。具体数据模型中涉及到的术语解释如下:
- 表(Table):是一个稀疏表(不存储值为 NULL 的数据),表的索引是行关键字、列关键字和时间戳。
- 行关键字(Row Key):行的主键,唯一标识一行数据,也称行键。表中的行根据行键进行字典排序,所有对表的访问都要通过表的行键。在创建表时,行键不用、也不能预先定义。而在对表数据进行操作时必须指定行键,行键在添加数据时首次被确定。
- 列族(Column Family):行中的列被分为“列族”。同一个列族的所有成员具有相同的列族前缀。例如“course:math”和“course:art”都是列族“course”的成员。一个表的列族必须在创建表时预先定义,列族名称不能包含 ASCII 控制字符(ASCII 码在 0~31 间外加 127)和冒号(:)。
- 列关键字(Column Key):也称列、列键。语法格式为:
:
其中: - family 是列族名,用于表示列族前缀;
- qualifier 是列族修饰符,表示列族中的一个成员。列族成员可以在随后
使用时按需加入,也就是只要列族预先存在,随时可以把列族成员添加
到列族中去。列族修饰符可以是任意字节。 - 存储单元格(Cell):在 HBase 中,值是作为一个单元保存在系统中。要定位一个单元,需要使用“行键+列键+时间戳”三个要素。
- 时间戳(Timestamp):插入单元格时的时间戳。默认作为单元格的版本号。
下面结合 HBase 的概念视图进一步体会这些术语。
(2)概念视图
在关系型数据库中,只能通过表的主键或唯一字段定位到某一条数据。例如使用典型的关系表的结构描述学生成绩表 scores,如下表所示。其中主要字段依次为姓名(name)、年级(grade)、数学成绩(math)、艺术成绩(art),主键为 name。
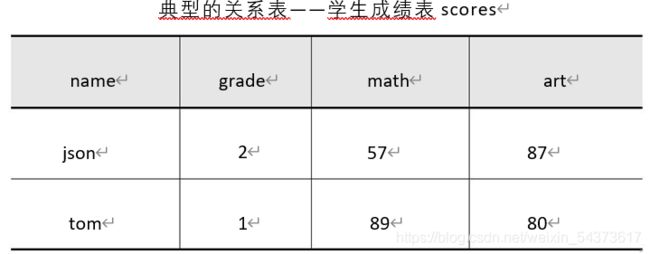
由于主键唯一标识了一行记录,所于很容易按姓名查询到某位同学的所有成绩。
但是,请思考如下问题:
(1)如果现在新加一门课程,能够在不修改表结构的情况下去保存新的课程成绩吗?
(2)如果某同学数学课程参加了补考,那么两次的考试成绩都能够保存下来吗?
(3)如果某同学只考试了一门课程而其它课程都没有成绩,是否可以只保存有成绩的课程而节省存储空间呢?
对于问题 1 和 2,在不修改表结构的情况下是不能够实现的,即使通过修改表结构实现,也不能保证后续的需求不会再发生变化。而在问题 3 中,按表结构的字段类型定义,一条记录的某个字段无论是否为 NULL 都会占用存储空间,那么将不能有选择的保存数据来节省存储空间。
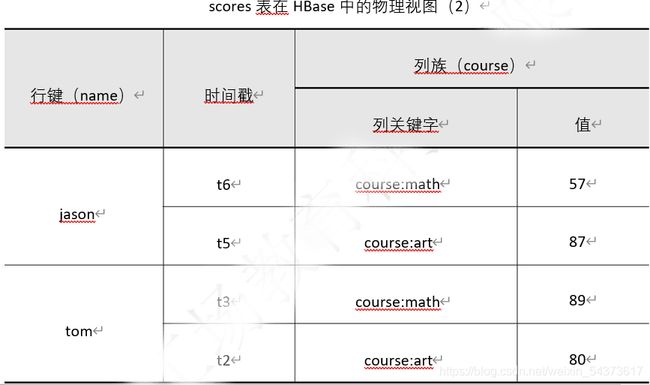
很明显,上面的需求在实际运用中经常出现,而 HBase 则可以完美的解决这些问题。将 scores 表转为在 HBase 中的概念视图,如下表所示。


表中的列包含了行键、时间戳和两个列族(grade、course),行包含了“jason”和“tom”两行数据。每次对表操作都必须指定行键和列键,每次操作增加一条数据,每一条数据对应一个时间戳。从上往下按倒序排列,该时间戳自动生成,用户不必进行管理。每次只针对一个列键操作,例如在 t3 时刻,用户指定“tom”的“math”成绩为“89”,类似操作:先找到行键“tom”然后指定列键进行赋值:course:math=89。其中:“course:math”为列键,“course”为列族名而“math”为列族修饰符,最后将“89”作为列键值赋给列键,t3 时刻的时间自动插入到时间戳列中。
又如在 t4 时刻,用户指定“jason”的“grade”为“2”。按照前面分析应类似如下操作:先找到行键“jason”,然后指定列键并赋值:grade:=2。请注意:这里没有给出列键的列族修饰符,即列族修饰符为空字符串。这样是允许的,因为前面提过列族修饰符可以是任意字符组成。
现在在 HBase 中回答前面的三个问题:
(1)如果现在为学生 jason 新增英语成绩,那么指定行键:“jason”,列键:“cource:english”,以及列键值(英语成绩)。
( 2 ) 如 果 学 生 jason 参 加 了 数 学 补 考 , 那 么 指 定 行 键 : “jason” , 列 键 :“cource:math”,以及列键值(补考成绩)。
(3)前面提过 HBase 是基于稀疏存储设计,在概念视图中发现存在很多空白项,这些空白项并不会被实际存储。总之,有数据就存储,无数据则忽略,通过表的物理视图可以更好的体会这一点。
(3)物理视图
通过概念视图,有助于从逻辑上理解 HBase 的数据结构。但在实际存储时,是按照列族来存储的。一个新的列键可以随时加入到已存在的列族中,这也是为什么列族必须在创建表时预先定义的原因。由上表中的概念视图对应的物理视图如下表1和下表2所示。

 HBase 就是这样一个基于列模式的映射数据库,它只能表示简单的键-值的映射关系。与关系型数据库相比,它有如下特点:
HBase 就是这样一个基于列模式的映射数据库,它只能表示简单的键-值的映射关系。与关系型数据库相比,它有如下特点:
HBase与关系型数据库的区别
**
Hive 和 Spark
完整的大数据平台应该提供离线计算、实时计算、实时查询这几方面的功能。离线计算就是非实时计算。通常,这类计算要在开始前就知道问题的所有数据输入。MapReduce 就是典型的离线计算,用于对全部归档数据进行批量处理,然后将结果缓存起来提供查询(如 HBase),可以看出从数据输入到结果输出的整个阶段,MapReduce 在实时性上并不是非常理想。
(1)Hive
在实际运用中,通常采用 Hadoop+Spark+Hive(MapReduce)的解决方案。利用 Hadoop 的 HDFS 解决分布式存储问题;利用 MapReduce 或 Hive 解决离线计算问题;利用 Spark 解决实时计算;最后利用 HBase 来解决实时查询的问题。
Hive 是 Hadoop 中的一个重要子项目,它的优势在于可以利用 MapReduce 编程技术,提供了类似 SQL 的编程接口,实现部分 SQL(结构化查询语句)语句的功能。Hive 的出现极大地推进了 Hadoop 在数据仓库方面的发展。
Hive 定 义 了 类 SQL 的 语 言 ——HiveQL 。 使 用 HiveQL 意 味 着 , 不 需 要 编 写MapReduce 就可以方便地使用 Mapper 和 Reducer 操作,这对 MapReduce 框架是一个强有力的支持。
Hive 本身建立在 Hadoop 体系结构上,提供了一个 SQL 解析的过程,从外部接口中获取命令,并对用户指令进行解析。Hive 将外部命令解析成一个 MapReduce 作业,随后提交到 Hadoop 集群进行处理。
Hive 的出现,是要解决如何让用户从一个现有的数据基础架构转移到 Hadoop上,而这个基础架构是基于传统关系型数据库和 SQL 的。大多数的数据仓库应用程序是使用基于 SQL 的关系型数据库实现的,所以 Hive 降低了将这些应用移植到Hadoop 上的障碍。用户如果懂得 SQL,那么学习使用 Hive 将会很容易;否则只能重新学习 MapReduce 编程。

典型 Hive 命令如下:
hive> CREATE TABLE employees(name STRING,salary FLOAT);
hive> SELECT name ,salary FROM employees;
Hive 的默认文件格式为以行存储的文本格式,文件中每行表示一个记录,记录之间以不同分隔符来区别。如下所示:
Jason^A8000
Tom^A7000
…
其中“^A”表示字段间分隔符。
更多详细资料请参考 http://hive.apache.org。
(2)Spark
Apache Spark 是一个新出现的大数据处理引擎,和 Hadoop 都属于大数据解决方案,相同之处是 Spark 也提供了类似 MapReduce 的处理。但是 Spark 没有提供文件管理系统,所以它必须和其它的分布式文件系统进行集成才能运行。实际使用中,通常是选择 Hadoop 的 HDFS,并让 Spark 运行在 YARN 上。
MapReduce 存在的问题:
① MapReduce 框架局限性
a.仅支持 Map 和 Reduce 两种操作。
b.处理效率低。
- Map 中间结果写磁盘,Reduce 写 HDFS,多个 MR 之间通过 HDFS 交
换数据; 任务调度和启动开销大。 - 无法充分利用内存。
- Map 端和 Reduce 端均需要排序。
c.不适合迭代计算(如机器学习、图计算等),交互式处理(数据挖掘) 和流式处理(点击日志分析)。
② MapReduce 编程不够灵活
与之相比,Spark 的优势是:
① 高效(比 MapReduce 快 10~100 倍)
a.内存计算引擎,提供 Cache 机制来支持需要反复迭代计算或者多次数据共享,减少数据读取的 IO 开销。
b.DAG 引擎,减少多次计算之间中间结果写到 HDFS 的开销。
c.使用多线程池模型来减少 task 启动开稍,shuffle 过程中避免不必要的 sort操作以及减少磁盘 IO 操作。
② 易用
a.提供了丰富的 API,支持 Java、Scala、Python 和 R 四种语言。
b.代码量比 MapReduce 少 2~5 倍。
③ 与 Hadoop 集成:读写 HDFS/Hbase 与 YARN 集成。

**
案例环境
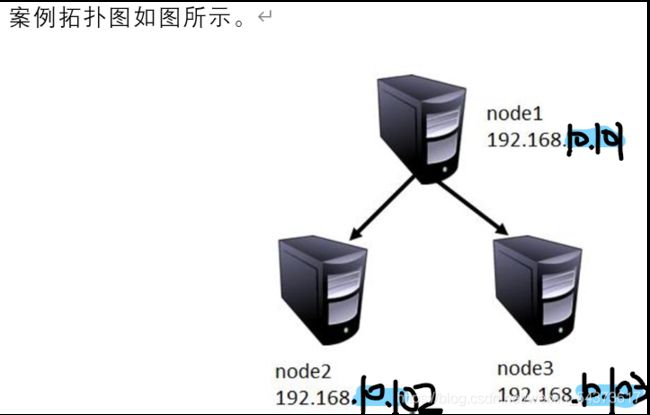
1. 本案例实验环境
本章是在Hadoop 环境基础上进行讲解。Hadoop 环境基础搭建可在CSDN网站主页请搜索用户:lxiaoyouyouj 就可选择博客就可以找到一篇名为:《物联网架构之Hadoop》文章,HBase 同样也有三种模式,
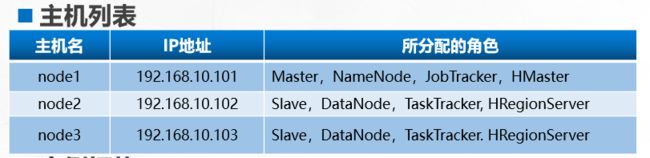
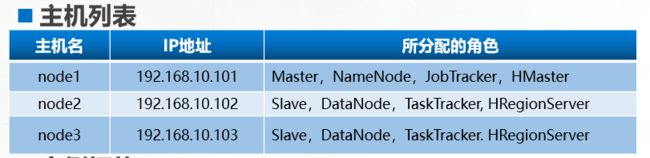
分为单机模式、伪分布式、完全分布式模式,前面两种不是本章学习的重点。只是简单的介绍,本章还是以 3 台主机介绍 HBase 完全分布式模式的安装。具体环境如下表
**
案例需求
下面是本案例的需求:
(1)安装部署 HBase。
(2)HBase 日常操作管理。




**
HBase 的安装部署
安装 HBase 与 HDFS、MapReduce 不同,HBase 需要单独安装。首先下载压缩包,注意需要选择和 Hadoop 相对应的 HBase 软件包,不然可能会有问题。本案例中提供的是 hbase-1.0.2 版本,然后将其解压到 NameNode 节点(node1)上:
首先先上传下载的Hbase的软件压缩包
 解压时必须要解压到Hadoop解压的目录下面
解压时必须要解压到Hadoop解压的目录下面
[root@node1 ~]# tar zxvf hbase-1.0.2-bin.tar.gz -C /home/hduser/
解压后查看 Hbase 的目录结构。
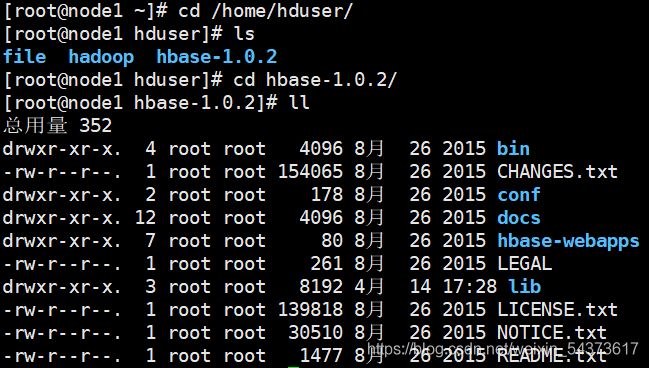 下面是其中各目录用途的说明:
下面是其中各目录用途的说明:
- bin:包含了所有可执行命令与脚本。
- conf:配置文件目录。
- docs: 配置文档
- hbase-webapps:存储 Web 应用的目录,里面应用主要用于查看 HBase 运行状态。默认访问地址 http://Master:16010,其中 Master 为 HBase Master服务器地址。
- lib:jar 文件目录,包括第三方依赖与 Hadoop 相关 jar 文件。其中 Hadoop相关 jar 文件版本最好能与实际运行的 Hadoop 版本一致,保证稳定运行。
按照惯例,HBase 的 conf 目录下也提供了 hbase-site.xml 文件进行自定义配置,用以覆盖默认配置文件 hbase-default.xml,其位于 lib/hbase-common-1.0.2.jar 中。按照 hbase-site.xml 不同的配置方式,使得 HBase 分别运行在单机、伪分布式和完全分布模式下,其中运行分布式 HBase 需要以下条件:
- JDK 环境
- SSH 免密码登录
- Hadoop 环境
这些条件的实现可请在CSDN网站主页搜索用户:lxiaoyouyouj 就可选择博客就可以找到一篇名为:《物联网架构之Hadoop》文章
**
单机模式
解 压 后 即 可 在 单 机 模 式 下 运 行 , 在 此 模 式 下 只 需 要 在hbase-1.0.2/conf/hbase-site.xml 中指定 HBase 的文件存储目录即可
[root@node1 hduser]# vim /home/hduser/hbase-1.0.2/conf/hbase-site.xml
末尾添加
 其中 hbase.rootdir 指定了 HBase 的数据存储目录。注意:这是 Linux 系统的文件目录。运行下面命令即可启动 Hbase。
其中 hbase.rootdir 指定了 HBase 的数据存储目录。注意:这是 Linux 系统的文件目录。运行下面命令即可启动 Hbase。
启动hbase
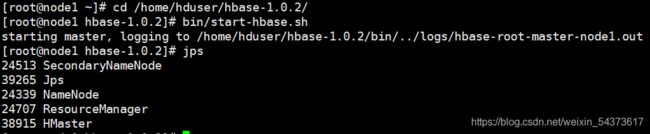 在单机模式下的 HBase 运行进程仅有 HMaster 进程。
在单机模式下的 HBase 运行进程仅有 HMaster 进程。
启动后 HBase 自动创建 hbase.rootdir 目录,其中的文件数据如下所示。

停止 HBase 使用如下命令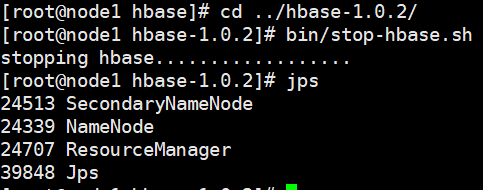
停止后就没有 HMaster 进程了
**
伪分布式模式
在伪分布式模式下,HBase 只在单个节点上运行,这和单机模式一样。但是其数据 文 件 可 以 存 储 在 HDFS 分 布 式 存 储 系 统 中 。 配 置 伪 分 布 模 式 , 只 需 要 在hbase-site.xml 中将 hbase.rootdir 的值更换为 HDFS 文件系统,修改如下配置。
上传下载的Hbase压缩包,解压操作
解压时必须要解压到Hadoop解压的目录下面
[root@node1 ~]# tar zxvf hbase-1.0.2-bin.tar.gz -C /home/hduser/
- 修改配置文件
[root@node1 ~]# vim /home/hduser/hbase-1.0.2/conf/hbase-site.xml
末尾添加

使用 HDFS 替换本地文件系统后,必须首先启动 HDFS,然后再启动 HBase,已经启动的就不需要在启动了,没有启动的
执行下面命令启动HDFS

启动HBase

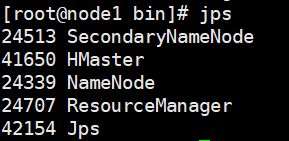
进程列表主要包含 Hadoop 的相关进程和 HBase 的 HMaster 进程,对 HBase来说还是只有一个进程,这和单机模式并无差异。但在此模式下 HBase 数据存储目录位于 HDFS 中,如下所示。
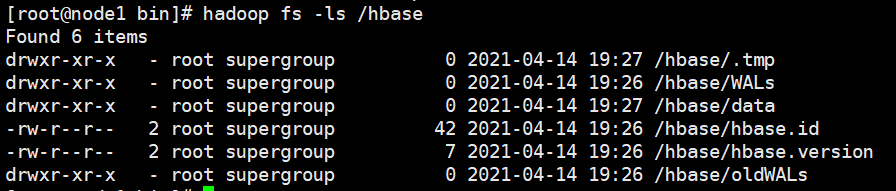
在执行完伪分布操作后,会在 HDFS 生成 hbase 目录,此时要删除 hbase 目录,才能进行下面的完全分布式配置模式,执行前先关闭 HBase 服务。
- 格式化文件系统
- 关闭HBase服务
[root@node1 bin]# hdfs namenode -format //格式化文件系统
**
完全分布式部署
完 全 分 布 式 与 伪 分 布 式 的 差 别 在 于 HBase 会 运 行 在 多 个 节 点 上 。 通 常 是 将HBase 的 HMaster 运行在 HDFS 的 NameNode 上 ,而 HRegionServer 运行在 HDFS DataNode 上。
在后续的实验中 HBase 均采用完全分布式模式运行,在此模式下需要在 conf 目录下配置三个文件 hbase-site.xml、hbase-env.sh 和 regionservers。首先在 node1上进行配置,随后将整个 HBase 安装目录复制到其它节点上。
在配置前先做一些必要的清理工作:
- 将 HDFS 中已经存在的“hdfs://node1:9000/hbase”目录删除(按前面配置示例,配置过伪分布式模式运行,已使用过该目录),如果没有请跳过。
- 检查并同步所有节点机(node1、node2、node3)的时钟,并且各节点与HBase 的 HMaster 节点(node1)时钟误差不能大于 30 秒。
删除vim /home/hduser/hbase-1.0.2/conf/hbase-site.xml 下添加的配置文件
[root@node1 ~]# vim /home/hduser/hbase-1.0.2/conf/hbase-site.xml

检查hbase目录是否存在:

显示已不存在
检查时间同步:
[root@node1 ~]# date
2021年 04月 14日 星期三 20:01:17 CST
[root@node2 ~]# date
2021年 04月 14日 星期三 20:01:17 CST
[root@node3 ~]# date
2021年 04月 14日 星期三 20:01:17 CST
三台主机时间都一致
上传下载的Hbase压缩包,解压操作
解压时必须要解压到Hadoop解压的目录下面
[root@node1 ~]# tar zxvf hbase-1.0.2-bin.tar.gz -C /home/hduser/
- 修改配置文件
[root@node1 ~]# vim /home/hduser/hbase-1.0.2/conf/hbase-site.xml
文件末尾添加
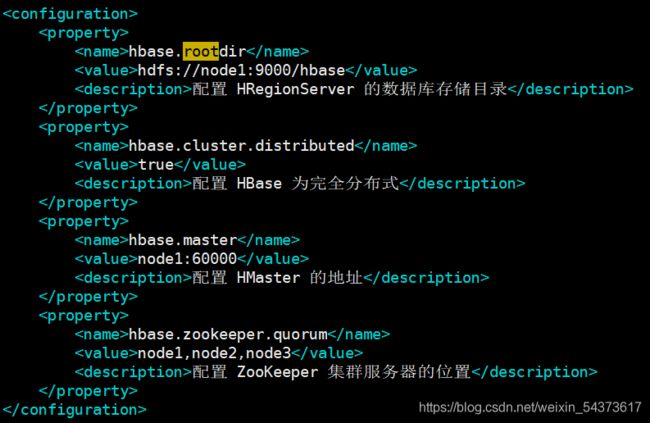 带有汉字的地方是注释信息
带有汉字的地方是注释信息
其中主要参数说明如下:
- hbase.cluster.distributed:默认为 false,即单机或伪分布式运行。这里设置为 true,表示在完全分布式模式运行。
- hbase.master:指定 HBase 的 HMaster 服务器地址、端口。
- hbase.zookeeper.quorum:指出了 ZooKeeper 集群中各服务器位置。也就是将哪些节点加入到 ZooKeeper 进行协调管理,推荐为奇数个服务器。
hbase-env.sh 文件
此文件用来配置全局的 HBase 集群系统的特性,每一台机器都可以通过该文件来了解全局的 HBase 的某些特性。需要在文件末尾增加以下环境变量
[root@node1 ~]# vim /home/hduser/hbase-1.0.2/conf/hbase-env.sh
文件末尾添加

前三个环境变量分别代表 Java、Hadoop、HBase 安装目录。完全分布式的 HBase集群需要 ZooKeeper 实例的运行,那么最后一个环境变量 HBASE_MANAGES_ZK表示 HBase 是否使用内置的 ZooKeeper 实例,默认为 true。
当在 hbase-site.xml 文件中配置了 hbase.zookeeper.quorum 属性后,系统会使用 该属 性所 指定 的 ZooKeeper 集 群服 务器 列表 。 在启 动 HBase 时 ,HBase 将 把ZooKeeper 作为自身的一部分运行,其对应进程为“HQuorumPeer”,关闭 HBase 时其内置 ZooKeeper 实例也一起关闭。如果 HBASE_MANAGES_ZK 为 false,表示不会使用内置 ZooKeeper 实例,也就是内置 ZooKeeper 不会随 HBase 启动,而需要用 户 在 指 定 机 器 上 独 立 安 装 配 置 ZooKeeper 实 例 , 同 样 使 用hbase.zookeeper.quorum 属性指定这些机器,并且在启动 HBase 之前必须手动启动这些机器的ZooKeeper。
说明:为了方便讲解,使用 HBase 内置 ZooKeeper 实例。关于 ZooKeeper 的单独安装与配置不在本课程讨论范围。如果需要,大家可以自行查阅相关资料。
regionservers 文件
该文件列出了所有 HRegionServer 节点,配置方式与 Hadoop 的 slaves 文件类似,每一行指定一台机器。当 HBase 启动、关闭时会把此文件中列出的所有机器同时启动、关闭。按下表的各机器角色分配,将 node2、node3 作为 HRegionServer。故regionservers 文件中内容如下:
- regionservers 文件中内容修改为如下:
[root@node1 ~]# vim /home/hduser/hbase-1.0.2/conf/regionservers
node2
node3
注意:regionservers 文件不包含 node1,因为 node1 已在 hbase-site.xml 中被指定为 HMaster 服务器,通常不会将 HMaster 和 HRegionServer 服务器运行在一个节点上。
在机器 node1 上配置完成上面三个文件后,HBase 基本的完全分布式模式配置便 已 完 成 。 同 Hadoop 分 布 式 安 装 类 似 , 还 需 要 将 HBase 所 在 目 录 如“/home/hduser/hbase-1.0.2”分别复制到 node2、node3,使得各个节点上都能运行HBase 来构建 HBase 集群。
- 在 node1 上运行下面命令:
[root@node1 ~]# scp -r /home/hduser/hbase-1.0.2/ node2:/home/hduser/
[root@node1 ~]# scp -r /home/hduser/hbase-1.0.2/ node3:/home/hduser/
在启动 HBase 的过程中,HBase 会先启动 ZooKeeper,再启动所有 HMaster和 HRegionServer , 启 动 成 功 后 注 意 node1 上 的 java 进 程 增 加 了 两 个 :“HQuorumPeer”和“HMaster”,分别为 ZooKeeper 进程和 HBase 进程。

查看 node2 的 java 进程,多了两个进程“HQuorumPeer”和“HRegionServer”,同样分别为 ZooKeeper 进程和 HBase 进程。另外在 node3 中的 java 进程和 node2 一样。
[root@node2 ~]# jps
23667 DataNode
23811 NodeManager
42419 Jps
42068 HRegionServer
41967 HQuorumPeer
[root@node3 ~]# jps
42212 HRegionServer
42582 Jps
23630 DataNode
23774 NodeManager
42111 HQuorumPeer
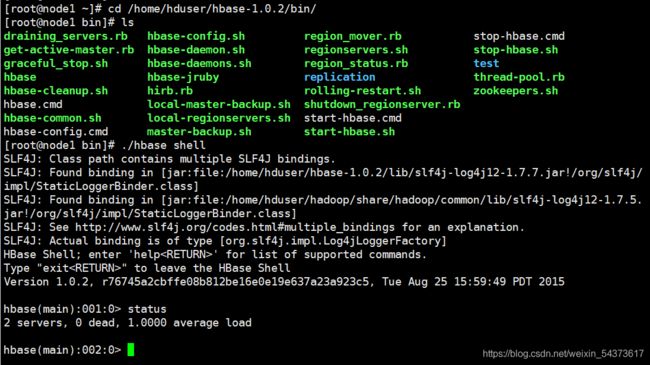
在启动 HBase 后,通过命令“hbase shell”进入 HBase Shell,然后使用 HBaseShell 命令“status”可在 HBase Shell 中查看 HBase 运行状态。如下所示,表示当前共有 2 个 HRegionServer 正在正常运行。
提示:如输入命令“hbase shell”提示“bash: hbase: command not found”,此时将HBase 的 bin 目录加入到系统环境变量 PATH 中即可。方法如下:
(1)打开文件:vim /etc/profile
(2)在文件中增加一行,随后保存退出。
export PATH=/home/hduser/hbase-1.0.2/bin:$PATH”
(3)使配置生效:source /etc/profile
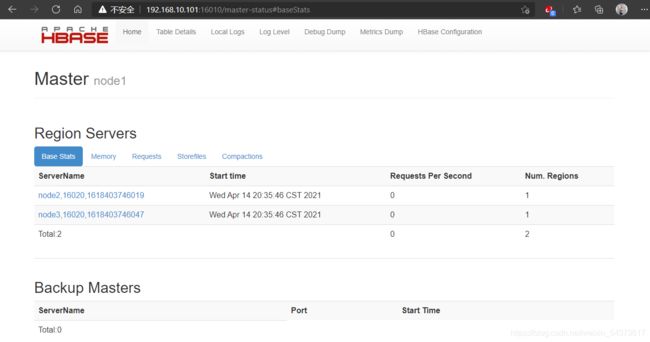
还 可 以 通 过 HMaster 节 点 的 16010 端 口 查 看 HBase 运 行 状 态 , 如
http://192.168.10.101:16010,页面输出如下图所示。
最后,使用命令“exit”即可退出 HBase Shell。
**
Hbase Shell 操作
前面已经接触了两个 HBase Shell 命令:status 和 exit。HBase 命令很多,其中又分为几个组,输入:help “cmd”可查看所有分组及其所包含的命令。如果需要了解具体命令的用法,可以将参数”cmd”换成具体命令,如:help “status”。下表提供了HBase Shell 的常用命令。


现在,使用命令将下表所示的概念视图 scores 表保存到 HBase 中。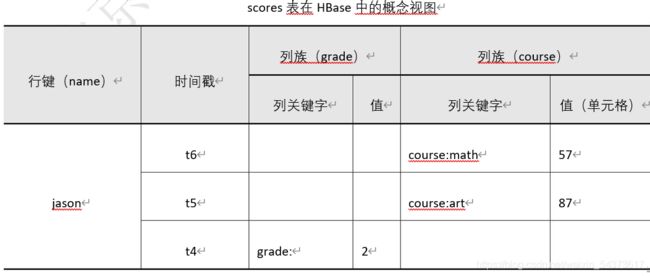

创建表:create
由于将 scores 表的“name”作为行键,所以在创建表时不用预指定行键这一列。并 且 “时 间 戳 ”这 一 列 也 是 由 HBase 自 动 生 成 , 所 以 只 需 指 定 两 个 列 族 “grade”和“course”。
create 命令的语法格式:
语法:
create ‘表名称’,’列名称 1’,’列名称 2’,…,’列名称 N’
其中:表名、列名必须用单引号括起来并以逗号分隔。
按照 create 语法操作如下:
hbase(main):002:0> create ‘scores’,‘grade’,‘course’
0 row(s) in 0.6580 seconds
=> Hbase::Table - scores
查看所有表:list
语法:
list
使用 list 命令可以查看当前 HBase 数据库中所有表,具体操作如下。
hbase(main):003:0> list
TABLE
scores
1 row(s) in 0.0190 seconds
=> [“scores”]
可以看到当前数据库中已经存在“scores”表。如果要查看该表所有列族的详细描述信息可使用 describe 命令。
语法:
describe ‘表名’
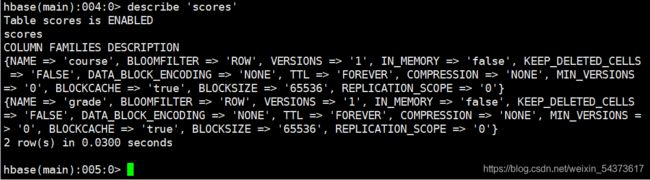
其中关于列族描述信息具体含义如下表所示。

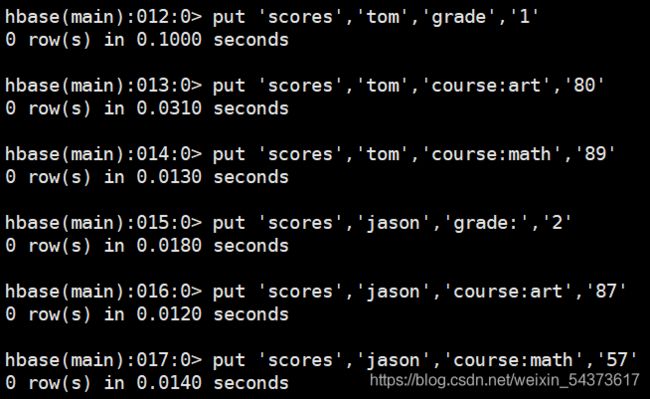
添加数据:put
向 scores 中增加一些数据,使用 put 命令可向表中插入数据。
语法:
put ‘表名称’,’行键’,’列键’,’值’
具体操作如下:
扫描表:scan
scan 用于进行全表单元扫描。
语法:
scan ‘表名称’,{COLUMNS=>[‘列族名 1’,’列族名 2’…],参数名=>参数值…}
大括号内的内容为扫描条件。如果不指定扫描条件,则查询所有数据。
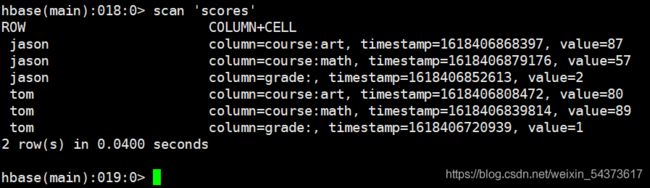
输出结果显示共 2 行数据,因为在 scan 的结果中,相同行键的所有单元视为一行。如果对有些列族不关心,便可指定查询某个列族。

能不能指定列键来扫描呢?肯定是可以的,语法如下。
语法:
scan ‘表名称’,{COLUMN=>[‘列键 1’,’列键 2’…],参数名=>参数值…}
将 COLUMNS 替换成 COLUMN,表示当前扫描的目标是列键,注意区分大小写。如下所示,扫描所有行的列键为“course:math”的单元,并使用 LIMIT 参数限制为输出一个单元。

获取数据:get
get 用于获取行的所有单元或者某个指定的单元。
语法:
get ‘表名称’,’行键’,{COLUMNS=>[‘列族名 1’,’列族名 2’…],参数名=>参数值…}
get ‘表名称’,’行键’,{COLUMN=>[‘列键 1’,’列键 2’…],参数名=>参数值…}
与 scan 相比多一个参数即行键。scan 查找的目标是全表的某个列族、列键,而get 查找的目标是某行的某个列族、列健。
查找行键为“jason”的所有单元:
 从上面输出结果可见,不指定列族或列键,会输出行键的所有列键单元。
从上面输出结果可见,不指定列族或列键,会输出行键的所有列键单元。
精确查找行键为“jason”,列键为“course:math”的单元:

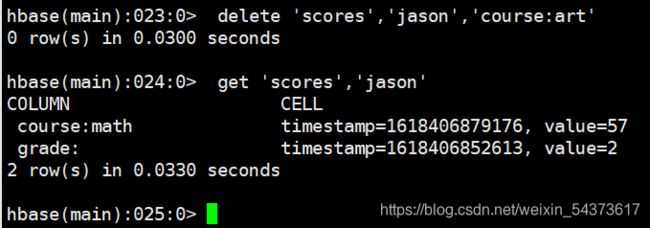
删除数据:delete
语法:
delete ‘表名称’,’行键’,’列键’
deleteall ‘表名称’,’行键’
delete 只能删除一个单元,而 deleteall 为删除一行。下面删除 scores 表中,行键为“jason”,列键为“course:art”的单元:
修改表:alter
使用 alter 可为表增加或修改列族。
语法:
alter ‘表名称’,参数名=>参数值,…
其中列族名参数 NAME 必须提供,如果已存在则修改,否则增加一个列族。下面示例将 scores 表的列族“course”的“VERSIONS”参数修改为“5”:

同时修改或增加多个列族时以逗号分开,并且每个列族用“{}”括起来。
语法:
alter ‘表名称’,{参数名=>参数值,…},{参数名=>参数值,…}…
下面示例将同时修改 scores 表的两个列族:

删除表:drop
在 前 面 的 describe 命 令 操 作 过 程 中 就 可 以 发 现 , HBase 表 分 两 种 状 态 :
DISABLED 和 ENABLED,分别表示是否可用状态。
使用 disable 将表置为不可用状态:
hbase(main):027:0> disable ‘scores’
0 row(s) in 1.1970 seconds
使用 enable 将表置为可用状态:
hbase(main):028:0> enable ‘scores’
0 row(s) in 0.2200 seconds
当表为 ENABLED 状态时,表会禁止被删除。所以必须先将表置为 DISABLED状态。操作如下:

**
MapReduce 与 Hbase
为什么要集成 MapReduce 和 HBase?
HBase 可以使用本地文件系统和 HDFS 文件系统作为数据存储介质,当在伪分布式和完全分布式下运行时,其使用的是 HDFS 文件系统。不用关心 HBase 中的表是如何在 HDFS 上存储的,但是数据最终会被写入某些文件中,并且可以通过 HBase将数据从这些文件中读取出来。
再来看,一个 MapReduce 应用要被定义为一个作业才能在 MapReduce 框架中运行,这些定义包括两个基本要素:MapReduce 的输入和输出,包括数据输入/输出的文件和处理这些文件所采用的输入/输出格式。
综上两点,可以让 MapReduce 作业需要输入数据时从 HBase 中读取,而在输出数据时,又可以输出到 HBase 完成存储,达到 HBase 与 MapReduce 协同工作,为 MapReduce 提 供 数 据 的 输 入 输 出 的 目 的 。 这 样 带 来 的 好 处 是 , 既 利 用 了MapReduce 分布式计算的优势,也利用了 HDFS 海量存储的特点,特别是利用了HBase 对 海 量 数 据 的 实 时 访 问 的 特 点 。 通 过 MapReduce 和 HBase 的 集 成 ,MapReduce、HBase、HDFS 之间关系如下图所示。

除了将 HBase 作为 MapReduce 作业的输入和输出,集成 MapReduce 与 HBase还可以做什么呢?
(1)可以对 HBase 中的数据进行非实时性的统计分析。HBase 适合做 Key-Value查询,默认不带聚合函数(sum、avg 等),对于这种需求非常适合集成 MapReduce来完成,但也应该注意到 MapReduce 局限性,MapReduce 的本身高延迟使得它不能满足实时交互式的计算。
(2)可以对 HBase 的表数据进行分布式计算。HBase 的目标是在海量数据中快速定位所需要的数据并访问它,可以发现 HBase 只能按照行键查询并不支持其他条件查询,所以只依靠 HBase 来解决存储的扩展,而不是业务逻辑,那么此时将业务逻辑放到 MapReduce 计算框架中是合适的。
(3)可以在多个 MapReduce 间使用 HBase 作为中间存储介质。
HBase Java API 对 MapReduce API 进 行 了 扩 展 , 这 里 将 其 称 为 HBaseMapReduce API。显然这是由 HBase 提供,主要是为了方便 MapReduce 应用对HTable 的操作。
前面提过,MapReduce 的输入和输出包括数据输入/输出的文件和处理这些文件所采用的输入/输出格式,与 HBase 集成后,“输入/输出的文件”变为“表(HTable)”,那 么 针 对 表 的 输 入 / 输 出 格 式 也 得 提 供 相 应 实 现 , 分 别 是 TableInputFormat 和TableOutputFormat,其所在 jar 文件为“hbase-server-1.0.2.jar”。同时,HBase 还提供了 TableMapper 和 TableReducer 类使得编写 MapReduce 程序更加方便。


表中左侧的类均继承于右侧的类,关于 HBase MapReduce API 的具体使用
在稍后再详细讲解。默认情况下,MapReduce 作业发布到集群中后,不能访问 HBase的配置文件和相关类,所以首先需要对集群中的各节点的 Hadoop 环境做如下调整:
-
(1)将 hbase-site.xml 复制到$HADOOP_HOME/etc/hadoop 下;
[root@node1 ~]# cp /home/hduser/hbase-1.0.2/conf/hbase-site.xml $HADOOP_HOME/etc/hadoop -
(2)编辑$HADOOP_HOME/etc/hadoop/hadoop-env.sh,增加一行:
[root@node1 ~]# vim $HADOOP_HOME/etc/hadoop/hadoop-env.sh
末尾添加

其中,HBase 的路径视其安装目录而不同。第一步可使 MapReduce 作业在运行时可以连接到 ZooKeeper 集群;第二步将 HBase 安装目录 lib 下的所有 jar 文件添加到环境变量$HADOOP_CLASSPATH 中,使得 MapReduce 作业可以访问所依赖的HBase 相关类,从而不用每次将 HBase 相关类打包到 MapReduce 应用的 jar 文件中。
最后注意将上述操作的两个文件,复制到 Hadoop 集群中其它节点上。

使用如下命令可测试环境是否已正确配置:
music是hbase里面的表,可以统计出这个表的行数
 省略部分内容…
省略部分内容…

该命令将运行“hbase-server-1.0.2.jar”中的 MapReduce 应用“rowcounter”,参数为表名“music”。其功能是使用 MapReduce 框架统计 HBase 数据库表 music 中的行数。