Go语言设计与实现
文章目录
-
- 选读这本书的理由
- 内容
-
- 编译原理
- 基础知识
-
- 数据结构
- Go 语言的调用惯例
- 接口
- 反射
- for \ for range 数组、切片、哈希和字符串
- select
- defer
- panic and recover
- make new
- runtime
-
- context
- 同步原语
- 定时器( 10 种状态和 7 种操作)
- 调度
- 网络轮询器
- 系统监控
- 内存管理 --- 分配
思考一个问题:***是什么,为什么会有它,什么历史场景,它是怎么设计的,为什么这么决策
选读这本书的理由
- 我非常喜欢作者通过历史的演进和社区讨论理解设计背后的决策和原因
- 从编译层次理解Go语言设计
内容
- 理解编译器的 词法与语法解析、类型检查、中间代码生成以及机器码生成过程;
- 理解 数组、切片、哈希表和字符串等数据结构的内部表示以及常见操作的原理;
- 理解 Go 语言中的函数、方法以及反射等语言特性;
- 理解常见 并发原语 Mutex、WaitGroup 以及扩展原语的使用和原理;
- 理解 make、new、defer、select、for 和 range 等关键字的实现;
- 理解运行时中的调度器、网络轮询器、内存分配器、垃圾收集器的实现原理;
- 理解 HTTP、RPC、JSON 等标准库的设计与原理;
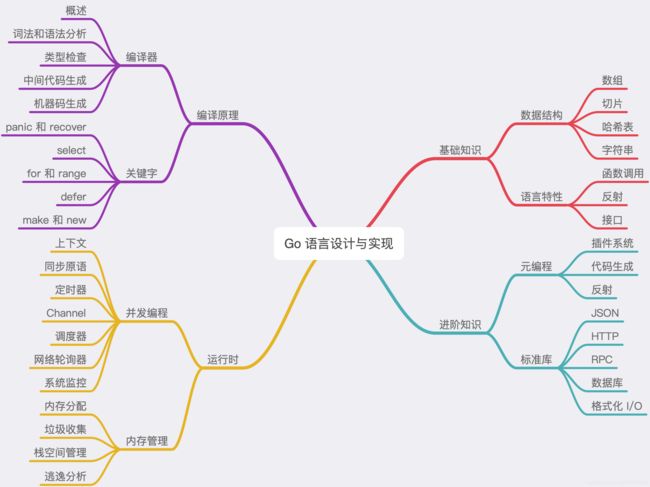
编译原理
- 源码 —> 词法与语法分析抽象 —> 类型检查和 AST 转换 —> 用 SSA 生成 —> 机器代码生成
- 词法分析 将字符串序列转换成 Token 序列
- 语法的解析 将 Token 转换成上述语法树
- 遍历AST,检查类型、展开和改写一些内建的函数
- SSA 的主要作用是对代码进行优化(中间代码)
- 根据目标的 CPU 架构生成机器码
1、检查常量、类型和函数的类型;
2、处理变量的赋值;
3、对函数的主体进行类型检查;
4、决定如何捕获变量;
5、检查内联函数的类型;
6、进行逃逸分析;
7、将闭包的主体转换成引用的捕获变量;
8、编译顶层函数;
9、检查外部依赖的声明;
基础知识
数据结构
-
数组大小、对数组中的元素的读写在编译期间就已经进行了简化,由于数组的内存固定且连续,很多操作都会变成对内存的直接读写
-
切片的很多功能都是在运行时实现的了,无论是初始化切片,还是对切片进行追加或扩容都需要运行时的支持,
注:需要注意的是在遇到大切片扩容或者复制时可能会发生大规模的内存拷贝,一定要在使用时减少这种情况的发生 避免对程序的性能造成影响。 -
字符串在做拼接和类型转换等操作时时一定要注意性能的损耗,遇到需要极致性能的场景一定要尽量减少类型转换的次数
-
字符串和 []byte 中的内容虽然一样,但是字符串的内容是只读的,我们不能通过下标或者其他形式改变其中的数据,而 []byte 中的内容是可以读写的,无论从哪种类型转换到另一种都需要对其中的内容进行拷贝,而内存拷贝的性能损耗会随着字符串和 []byte 长度的增长而增长。
Go 语言的调用惯例
go tool compile -S -N -l main.go
1、通过堆栈传递参数,入栈的顺序是从右到左;
2、函数返回值通过堆栈传递并由调用者预先分配内存空间;
3、调用函数时都是传值,接收方会对入参进行复制再计算;
注:在传递数组或者内存占用非常大的结构体时,我们在一些函数中应该尽量使用指针作为参数类型来避免发生大量数据的拷贝而影响性能。
接口
- 接口的本质就是引入一个新的中间层,调用方可以通过接口与具体实现分离,解除上下游的耦合,上层的模块不再需要依赖下层的具体模块,只需要依赖一个约定好的接口。
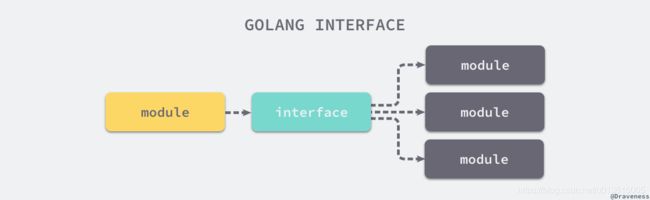
SQL 就是接口的一个例子,当我们使用 SQL 语句查询数据时,其实不需要关心底层数据库的具体实现,我们只在乎 SQL 返回的结果是否符合预期。
- 接口类型: iface、eface
iface 结构体表示第一种接口
_type 是 Go 语言类型的运行时表示。下面是运行时包中的结构体,结构体包含了很多元信息,例如:类型的大小、哈希、对齐以及种类等。
type _type struct {
size uintptr // 存储了类型占用的内存空间,为内存空间的分配提供信息;
ptrdata uintptr // 能够帮助我们快速确定类型是否相等;
hash uint32
tflag tflag
align uint8
fieldAlign uint8
kind uint8
equal func(unsafe.Pointer, unsafe.Pointer) bool //用于判断当前类型的多个对象是否相等,该字段是为了减少 Go 语言二进制包大小从 typeAlg 结构体中迁移过来的
gcdata *byte
str nameOff
ptrToThis typeOff
}
eface 结构体表示第二种空接口
在类型断言中介绍 hash 字段的使用,在动态派发一节中介绍 fun 数组中存储的函数指针是如何被使用的
type itab struct {
// 32 bytes
inter *interfacetype
_type *_type
hash uint32 // 对 _type.hash 的拷贝,当我们想将 interface 类型转换成具体类型时,可以使用该字段快速判断目标类型和具体类型 _type 是否一致
_ [4]byte
fun [1]uintptr // 用于动态派发的虚函数表,存储了一组函数指针。虽然该变量被声明成大小固定的数组,但是在使用时会通过原始指针获取其中的数据,所以 fun 数组中保存的元素数量是不确定的;
}
两种接口虽然都使用 interface 声明,但是由于后者在 Go 语言中非常常见,所以在实现时使用了特殊的类型。
需要注意的是,与 C 语言中的 void * 不同,interface{} 类型不是任意类型,如果我们将类型转换成了 interface{} 类型,这边变量在运行期间的类型也发生了变化,获取变量类型时就会得到 interface{}
- 指针和接口
| *** | 结构体实现接口 | 结构体指针实现接口 |
|---|---|---|
| 结构体初始化变量 | 通过 | 不通过 |
| 结构体指针初始化变量 | 通过 | 通过 |
- 接口类型是如何初始化和传递的(把具体类型转换成接口类型)
- 将一个接口类型转换成具体类型
【罕见深入分析,从源码和编译角度解释我们遇到的问题】
Go 语言的接口类型不是任意类型;
在 Go 中:实现接口的所有方法就隐式的实现了接口;
除了向方法传入参数之外,变量的赋值也会触发隐式类型转换; - 动态派发
动态派发(Dynamic dispatch)是在运行期间选择具体多态操作(方法或者函数)执行的过程
func main() {
var c Duck = &Cat{
Name: "grooming"}
c.Quack()
c.(*Cat).Quack()
}
两次方法调用对应的汇编指令差异就是动态派发带来的额外开销,这些额外开销在有低延时、高吞吐量需求的服务中是不能被忽视的
我们来详细分析一下产生的额外汇编指令对性能造成的影响
| *** | 直接调用 | 动态派发 |
|---|---|---|
| 指针 | ~3.03ns | ~3.58ns |
| 结构体 | ~3.09ns | ~6.98ns |
所以,使用结构体来实现接口带来的开销会大于使用指针实现,而动态派发在结构体上的表现非常差,这也提醒我们应当尽量避免使用结构体类型实现接口;
反射
使用反射来 动态修改变量、判断类型是否实现了某些接口以及动态调用方法;
运行时的反射能力,能够让程序操作不同类型的对象
-
Type 是反射包定义的一个接口,我们可以使用 reflect.TypeOf 函数获取任意变量的的类型
-
Value 被声明成了结构体,提供了获取或者写入数据的方法
所有方法基本都是围绕着 Type 和 Value 这两个类型设计的。 我们通过 reflect.TypeOf、reflect.ValueOf 可以将一个普通的变量转换成『反射』包中提供的 Type 和 Value,随后就可以使用反射包中的方法对它们进行复杂的操作。 reflect.TypeOf 函数将传入的变量隐式转换成 emptyInterface 类型并获取其中存储的类型信息 rtype reflect.ValueOf 在该函数中我们先调用了 reflect.escapes 函数保证当前值逃逸到堆上,然后通过 reflect.unpackEface 方法从接口中获取 Value 结构体;reflect.unpackEface 函数会将传入的接口转换成 emptyInterface 结构体,然后将具体类型和指针包装成 Value 结构体并返回。 -
三大法则
1、从 interface{
} 变量可以反射出反射对象;
reflect.TypeOf 和 reflect.ValueOf 函数能转换成 interface{
} 类型
2、从反射对象可以获取 interface{
} 变量;
既然能够将接口类型的变量转换成反射对象,那么一定需要其他方法将反射对象还原成接口类型的变量
3、要修改反射对象,其值必须可设置;
由于 Go 语言的函数调用都是值传递的,所以我们只能先获取指针对应的 reflect.Value,
再通过 reflect.Value.Elem 方法迂回的方式得到可以被设置的变量
func main() {
i := 1
v := reflect.ValueOf(&i) // 函数获取变量指针
v.Elem().SetInt(10) // reflect.Value.Elem方法获取指针指向的变量 reflect.Value.SetInt方法更新变量的值
fmt.Println(i)
}
$ go run reflect.go
10
从反射对象到接口值的过程就是从接口值到反射对象的镜面过程:
- 更新变量
- 实现协议
可以用于判断某些类型是否遵循特定的接口 - 方法调用
利用反射在运行期间执行方法不是一件容易的事情
参数检查 — 准备参数 — 调用函数 — 处理返回值
for \ for range 数组、切片、哈希和字符串
Go 语言遍历数组和切片时会复用变量:
- 遇到这种同时遍历 索引和元素 的 range 循环时,Go 语言会额外创建一个新的 v2 变量存储切片中的元素,循环中使用的这个变量 v2 会在每一次迭代被 重新赋值而覆盖 ,在赋值时也发生了 拷贝
数组:因为在循环中获取返回变量的地址都完全相同,所以会发生神奇的指针一节中的现象。
所以如果我们想要访问数组中元素所在的地址,不应该直接获取 range 返回的变量地址 &v2,
而应该使用 &a[index] 这种形式。
func main() {
arr := []int{
1, 2, 3}
newArr := []*int{
}
for i, _ := range arr {
newArr = append(newArr, &arr[i])
}
for _, v := range newArr {
fmt.Println(*v)
}
}
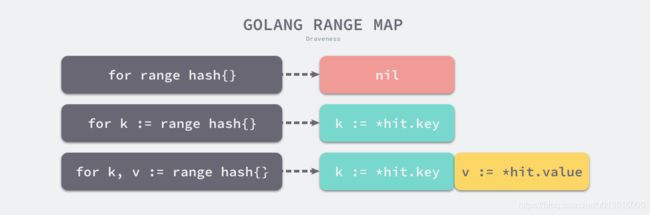
- 字符串:只是在遍历时会获取字符串中索引对应的字节并将字节转换成 rune。我们在遍历字符串时拿到的值都是 rune 类型的变量
- 字符串是一个只读的字节数组切片,所以范围循环在编译期间生成的框架与切片非常类似,只是细节有一些不同。
select
C 语言中的 select 关键字可以同时监听多个文件描述符的可读或者可写的状态
Go 语言中的 select 关键字也能够让 Goroutine 同时等待多个 Channel 的可读或者可写
在多个文件或者 Channel 发生状态改变之前,select 会一直阻塞当前线程或者 Goroutine
- select 能在 Channel 上进行非阻塞的收发操作
非阻塞的 Channel 发送和接收操作还是很有必要的,在很多场景下我们不希望向 Channel 发送消息或者从 Channel 中接收消息会阻塞当前 Goroutine,我们只是想看看 Channel 的可读或者可写状态。 - select 在遇到多个 Channel 同时响应时会随机挑选 case 执行
随机的引入就是为了避免饥饿问题的发生 - runtime.scase 的种类,总共包含以下四种
const (
caseNil = iota
caseRecv
caseSend
caseDefault
)
- 实现原理
select 不存在任何的 case; // 空的 select 语句会直接阻塞当前的 Goroutine
select 只存在一个 case; // 将 select 改写成 if 条件语句
select 存在两个 case,其中一个 case 是 default; // 编译器就会认为这是一次非阻塞的收发操作
select 存在多个 case;// 该函数会将 case 中的所有 Channel 都转换成指向 Channel 的地址。我们会分别介绍非阻塞发送和非阻塞接收时,编译器进行的不同优化
OSEND 时,编译器会使用 if/else 语句和 runtime.selectnbsend 函数改写代码
- 一般步骤:
1、将所有的 case 转换成包含 Channel 以及类型等信息的 runtime.scase 结构体;
2、调用运行时函数 runtime.selectgo 从多个准备就绪的 Channel 中选择一个可执行的 runtime.scase 结构体;
3、通过 for 循环生成一组 if 语句,在语句中判断自己是不是被选中的 case
最重要的就是用于选择待执行 case 的运行时函数 **runtime.selectgo**
1、随机生成一个遍历的轮询顺序 pollOrder 并根据 Channel 地址生成锁定顺序 lockOrder;
2、根据 pollOrder 遍历所有的 case 查看是否有可以立刻处理的 Channel;
- 如果存在就直接获取 case 对应的索引并返回;
- 如果不存在就会创建 runtime.sudog 结构体,将当前 Goroutine 加入到所有相关 Channel 的收发队列
3、并调用 runtime.gopark 挂起当前 Goroutine 等待调度器的唤醒;
4、当调度器唤醒当前 Goroutine 时就会再次按照 lockOrder 遍历所有的 case,从中查找需要被处理的 runtime.sudog 结构对应的索引;
defer
用于关闭文件描述符、关闭数据库连接以及解锁资源
常用中碰到的现象:
- defer 关键字的调用时机以及多次调用 defer 时执行顺序是如何确定的;
- defer 关键字使用传值的方式传递参数时会进行预计算,导致不符合预期的结果;
调用 defer 关键字会立刻对函数中引用的外部参数进行拷贝
func main() {
startedAt := time.Now()
defer fmt.Println(time.Since(startedAt))
time.Sleep(time.Second)
}
$ go run main.go
0s
func main() {
startedAt := time.Now()
defer func() {
fmt.Println(time.Since(startedAt)) }()
time.Sleep(time.Second)
}
$ go run main.go
1s
上面两种常见现象的背后原理:
-
编译期;
- 将 defer 关键字被转换 runtime.deferproc;
- 在调用 defer 关键字的函数返回之前插入 runtime.deferreturn;
-
运行时:
- runtime.deferproc 会将一个新的 runtime._defer 结构体追加到当前 Goroutine 的链表头;
- runtime.deferreturn 会从 Goroutine 的链表中取出 runtime._defer 结构并依次执行;
-
后调用的 defer 函数会先执行:
- 后调用的 defer 函数会被追加到 Goroutine _defer 链表的最前面;
- 运行 runtime._defer 时是从前到后依次执行;
-
函数的参数会被预先计算;
- 调用 runtime.deferproc 函数创建新的延迟调用时就会立刻拷贝函数的参数,函数的参数不会等到真正执行时计算;
panic and recover
-
panic 能够改变程序的控制流,函数调用panic 时会立刻停止执行函数的其他代码,并在执行结束后在当前 Goroutine 中递归执行调用方的延迟函数调用 defer;
- 一个 Goroutine 在 panic 时也不应该执行其他 Goroutine 的延迟函数
- panic 是可以多次嵌套调用
调用 panic 都会创建一个如下所示的数据结构存储相关信息
type _panic struct {
argp unsafe.Pointer //指向 defer 调用时参数的指针
arg interface{
} //调用 panic 时传入的参数
link *_panic //指向了更早调用的 runtime._panic 结构
// panic 函数可以被连续多次调用,它们之间通过 link 的关联形成一个链表
recovered bool //当前 runtime._panic 是否被 recover 恢复
aborted bool //当前的 panic 是否被强行终止
pc uintptr
sp unsafe.Pointer
goexit bool
}
编译器会将关键字 panic 转换成 runtime.gopanic:
1、创建新的 runtime._panic 结构并添加到所在 Goroutine _panic 链表的最前面;
2、在循环中不断从当前 Goroutine 的 _defer 中链表获取 runtime._defer 并调用 runtime.reflectcall 运行延迟调用函数;
3、调用 runtime.fatalpanic 中止整个程序;
- recover 可以中止 panic 造成的程序崩溃。它是一个只能在 defer 中发挥作用的函数,在其他作用域中调用不会发挥任何作用;
- 编译器会将关键字 recover 转换成 runtime.gorecover
- 程序的恢复也是由 runtime.gopanic 函数负责的
崩溃和恢复流程:详细的需要结合编译源码和运行时查看,大神看待问题的角度
- 1、编译器会负责做转换关键字的工作:
- 将 panic 和 recover 分别转换成 runtime.gopanic 和 runtime.gorecover;
- 将 defer 转换成 deferproc 函数;
- 在调用 defer 的函数末尾调用 deferreturn 函数;
- 2、在运行过程中遇到 gopanic 方法时,会从 Goroutine 的链表依次取出 _defer 结构体并执行;
- 3、如果调用延迟执行函数时遇到了 gorecover 就会将 _panic.recovered 标记成 true 并返回 panic 的参数:
- 在这次调用结束之后,gopanic 会从 _defer 结构体中取出程序计数器 pc 和栈指针 sp 并调用 recovery 函数进行恢复程序;
- recovery 会根据传入的 pc 和 sp 跳转回 deferproc;
- 编译器自动生成的代码会发现 deferproc 的返回值不为 0,这时会跳回 deferreturn 并恢复到正常的执行流程;
- 4、如果没有遇到 gorecover 就会依次遍历所有的 _defer 结构,并在最后调用 fatalpanic 中止程序、打印 panic 的参数并返回错误码 2;
make new
- 在编译期间的类型检查阶段,Go 语言就将代表 make 关键字的 OMAKE 节点根据参数类型的不同转换成了 OMAKESLICE、OMAKEMAP 和 OMAKECHAN 三种不同类型的节点,这些节点会调用不同的运行时函数来初始化相应的数据结构
- 编译器会在中间代码生成阶段
通过 cmd/compile/internal/gc.callnew 函数会将关键字转换成 ONEWOBJ 类型的节点
通过 cmd/compile/internal/gc.state.expr 函数会根据申请空间的大小分两种情况处理
runtime
context
- 上下文 context.Context 是用来设置截止日期、同步信号,传递请求相关值的结构体
- 在 Goroutine 构成的树形结构中对信号进行同步以减少计算资源的浪费是 context.Context 的最大作用
- context.Background、context.TODO、context.WithDeadline 和 context.WithValue 函数会返回实现该接口的私有结构体
设计原理:多个 Goroutine 同时订阅 ctx.Done() 管道中的消息,一旦接收到取消信号就立刻停止当前正在执行的工作
func main() {
ctx, cancel := context.WithTimeout(context.Background(), 1*time.Second)
defer cancel()
go handle(ctx, 500*time.Millisecond)
select {
case <-ctx.Done():
fmt.Println("main", ctx.Err())
}
}
func handle(ctx context.Context, duration time.Duration) {
select {
case <-ctx.Done():
fmt.Println("handle", ctx.Err())
case <-time.After(duration):
fmt.Println("process request with", duration)
}
}
同步原语
- 锁是一种并发编程中的同步原语(Synchronization Primitives)
- 基本原语提高了较为基础的同步功能,但是它们是一种相对原始的同步机制,在多数情况下,我们都应该使用抽象层级的更高的 Channel 实现同步
定时器( 10 种状态和 7 种操作)
运行时会根据状态的不同而做出不同的反应,所以我们在分析计时器时会从状态的维度去分析其实现原理
调度
- 基于协作的抢占式调度器 - 1.2 ~ 1.13
- 通过编译器在函数调用时插入抢占检查指令,在函数调用时检查当前 Goroutine 是否发起了抢占请求,实现基于协作的抢占式调度;
- Goroutine 可能会因为垃圾回收和循环长时间占用资源导致程序暂停;
- 基于信号的抢占式调度器 - 1.14 ~ 至今
- 实现基于信号的真抢占式调度;
- 垃圾回收在扫描栈时会触发抢占调度;
- 抢占的时间点不够多,还不能覆盖全部的边缘情况;
网络轮询器
- 网络轮询器就是 Go 语言运行时用来处理 I/O 操作的关键组件,它使用了操作系统提供的 I/O 多路复用机制增强程序的并发处理能力
- 运行时中的调度和系统调用会通过 runtime.netpoll 与网络轮询器交换消息,获取待执行的 Goroutine 列表,并将待执行的 Goroutine 加入运行队列等待处理。
所有的文件 I/O、网络 I/O 和计时器都是由网络轮询器管理的
系统监控
- 运行计时器 — 获取下一个需要被触发的计时器;
- 轮询网络 — 获取需要处理的到期文件描述符;
非阻塞地调用 runtime.netpoll 检查待执行的文件描述符并通过 runtime.injectglist 将所有处于就绪状态的 Goroutine 加入全局运行队列中 - 抢占处理器 — 抢占运行时间较长的或者处于系统调用的 Goroutine;
- 垃圾回收 — 在满足条件时触发垃圾收集回收内存;
运行时通过系统监控来触发线程的抢占、网络的轮询和垃圾回收,保证 Go 语言运行时的可用性。系统监控能够很好地解决尾延迟的问题,减少调度器调度 Goroutine 的饥饿问题并保证计时器在尽可能准确的时间触发。
内存管理 — 分配
堆中的对象由内存分配器分配并由垃圾收集器回收