Python编程从入门到实践笔记(超详细的精华讲解+内有2021最新版本代码)
编程环境的安装请见我个人博客https://tianjuewudi.gitee.io/的另两篇文章《Pycharm安装方法》及《Pycharm配置和使用教程》,下面以你能正常使用pycharm为前提。
基础知识
变量及简单数据类型
变量名的使用
- 变量名只能包含字母,数字和下划线。可以以字母和下划线开头,但不能以数字开头。
- 变量名不能包含空格,可用下划线来分割单词,如:greeting_message。
- 不要将Python关键字和函数名用作变量名。
- 变量名应既简短又具有描述性。
- 慎用小写字母l和大写字母O,容易被看成1和0。
字符串
字符串是一串字符,引号括起的都是字符串,可以是单引号或双引号,如:
str = "ada lovelace"
str.title() #单词首字母大写
str.upper() #单词所有字母大写
str.lower() #单词所有字母小写
str = str1 + str2 #字符串相加
#字符串中出现\t是制表符,\n是换行符
str.rstrip() #删除空格,不改变原变量
整型(浮点型同理)
加减乘除不必多说
3 ** 2 #乘方,结果是9
3 % 2 #求模,返回余数
注意,整型相除也是整型,会自行砍掉小数。
强制类型转换
str(age) # 转变为字符串
int(age) # 转变为整型
列表
列表由一系列特定元素排列而成,如:
bicycles = ['trek','cannondale','redline','specialized']
list[0] #表示第一个元素
list[-1] #表示最后一个元素
#列表的增删改
list.append('honda') #在列表末尾添加字符串'honda'
list.insert(0,'ducati') #在第一位插入字符串'ducati',后面的元素后移一位
del list[0] #删除第一个元素
str = list.pop() #删除列表末尾的元素,同时可以把这个元素赋值给另一个变量
str = list.pop(0) #删除第一个元素,同时可以把这个元素赋值给另一个变量
list.remove('ducati') #不清楚元素位置,知道元素值的删除方法
#列表的排列(排列时列表数据类型要保持一致)
list.sort() #按字母顺序排列列表
list.sort(reverse = True)#按与字母顺序相反的顺序排列列表
sorted(list) #不影响原有列表的排列顺序,直接返回一个排列好的列表
sorted(list,reverse = True) #反向排列,不改变原有列表
list.reverse() #将列表元素反转排列
#使用列表一部分
list[0:3] #输出一个包含列表第1到3个元素的列表,没有list[3]
list[:4] #输出一个包含列表前四个元素的列表
list[2:] #输出一个包含列表第三个元素开始往后的元素的列表
list[-3:] #输出一个包含列表最后三个元素的列表
#复制一个列表
list2 = list1[:] #不能使用list2 = list1,因为这样它们的地址是一样的
len(list) #确定列表长度
for i in list: #打印整个列表
print(i)
range(1,5) #1到4的整数,是可迭代对象
range(2,11,2) #2到10的整数,步长为2(2,4,6,8,10)
list(range(1,5)) #转换为列表
min(list_digits) #找出数字列表的最小值
max(list_digits) #找出数字列表的最大值
list = [value**2 for value in range(1,11)] #一行代码生成列表
元组
不可修改的列表称为元组。
tuple = (200,50) #两个元素的元组
tuple[0] = 10 #不合法
tuple = (100,10) #可以给储存元组的变量重新赋值,合法
if语句
#检查单个条件
if car == 'bmw':
print(car.upper())
elif car == 'saf':
print(car.lower())
else:
print(car.title())
#检查多个条件
if age_0 >= 21 and age_1 >= 21
if age_0 >= 21 or age_1 >= 21
#检查特定值是否在列表中,特定值是否在字符串中同理
if 'value' in list
if 'value' not in list
#确定列表不是空的
if list
字典
字典是一系列的键值对:
dict = {
'color':'green','points':5}
dict['color'] #访问字典中'color'所对应的值
#字典是动态结构,可随时在其中添加键值对,键值对的排列顺序和添加顺序不同,Python不关心键值对顺序,只关心键与值的联系
dict['x_position'] = 0
#修改字典中的值
dict['x_position'] = 10
#删除键值对
del dict['points']
#遍历字典
for key,value in dict.items(): #item方法返回一个键值对列表,依次是键,值,键,值。。。
print(key/n)
print(value)
for key in dict.keys(): #遍历字典所有键
print(key);
for key in sorted(dict.keys()): #按顺序遍历字典所有键
print(key);
for value in dict.values():
print(value)
#嵌套,字典储存于列表或列表储存于字典
#字典储存于列表中可运用于游戏中产生的一群敌人(列表),每个敌人的数据都不相同(字典)
#列表储存于字典运用于一个特征由多个元素组成,如披萨的原料,顾客点的披萨:外壳:硬,原料:蘑菇,奶酪。
#字典中储存字典,运用于网站用户,用户名作为键,用户信息储存于一个字典中,字典作为值。
用户输入和while循环
- 函数input()让程序暂停运行,等待用户输入文本,获取用户输入后,Python将其储存在一个变量中,供你使用:
message = input("Tell me something,and I will repeat it back to you:") #获取输入,input中是提示信息
print(message)
- while循环不断执行,知道指定的条件不满足为止:
num = 1
while num <= 5:
print(num)
num++
if city == 'quit': #可以设定条件主动退出循环
break #continue为退出本次循
- 在for循环中不应修改列表,否则将导致Python难以跟踪其中的元素,可使用while进行修改:
unconfirmed_users = ['alice','brian','candace']
confirmed_users = []
while unconfirmed_users: #验证所有未验证用户,并从旧列表中删除,将已验证用户加入新列表中
current_user = unconfirmed_users.pop()
print(current_user.title())
confirmed_users.append(current_users)
- 删除包含特定值的所有列表元素
while 'cat' in pets:
pets.remove('cat')
函数
函数是带名字的代码块,用于完成具体的工作。需要程序多次执行同一项任务是,无需反复编写代码,只需反复调用执行改任务的函数即可。
def greet_user():
print('Hello!')
#向函数传递信息
def greet_user(username): #一个参数
print("Hello" + username.title())
def describe_pet(animal_type = ‘rabbit’,pet_name = 'snoby'): #两个参数,可以给形参设定默认值,这样就可以不用传入实参
print("I have a" + animal_type + '.The name is' + pet_name)
describe_pet('hamster','harry') #实际调用
describe_pet(animal_type = 'hamster',pet_name = 'harry')
#有返回值的函数
def git_fromatted_name(first_name,last_name):
full_name = first_name + last_name
return full_name.title() #return {'first':first_name,'last':last_name} 可返回字典
#把列表传给函数后,函数可以直接对其进行修改,注意这在简单数据类型行不通。如果不想修改列表本身可以用list[:]副本传入
def print_models(unprinted_designs,completed_models):
while unprinted_designs:
current_designs = unprinted_designs.pop()
print('Printing model:' + current_design)
completed_models.append(current_design)
#传递任意数量的实参
def make_pizza(*toppings): #这里toppings是一个元组,可以传入任意数量的元素
print(toppings)
make_pizza('mushrooms','green peppers','extra cheese') #调用函数,传入的参数自行组成元组
def make_pizza(size,*toppings): #结合使用
print("make a " + size + "pizza with the following toppings:")
for topping in toppings:
print("- " + topping)
#使用任意数量的关键字实参(传入任意数量元素的字典)
def build_profile(first,last,**user_info): #传入信息和键值对,合并成一个字典
profile = {
}
profile['first_name'] = first
profile['last_name'] = last
for key,value in user_info.items():
profile[key] = value
return profile
bild_profile('albert','einstein',location = 'princeton',field = 'physics') #调用
#将函数储存在模块中
#创建一个存储函数的独立文件,在其所在目录中的其他py文件都可以通过import+文件名导入模块
#pizza.py
def make_pizza(*toppings):
print(toppings)
#making_pizzas.py
import pizza #import pizza as p 可以给模块指定别名
pizza.make_pizza('mushroom','green peppers','extra cheese')
#导入特定函数
from pizza import make_pizza as mp #可以给函数指定别名
#导入模块中所有函数
from pizza import *
类
面向对象编程是最有效的软件编写方法之一。在面向对象编程是,你编写表示现实世界中的事物和场景的类,基于这些类来创造对象,每个对象都具备类的通用行为,也可根据需要赋予每个对象独特的个性。
#创建一个类
#self是一个指向实类本身的引用,让实例能访问类中的属性和方法。
#Python调用_init_()方法来创建实例时会自动传入实参self,我们自己不需要传递它。
class Dog():
def __init__(self,name,age): #注意init两边的横线的两条杠
self.name = name
self.age = age
self.model = 0 #可以在此处定义另外没传入的变量
def sit(self):
print(self.name.title() + ‘is now sitting.’)
def roll_over(self):
print(self.name.title() + 'rolled over!')
def update_model(self,model):
self.model = model
#创建实例
my_dog = Dog('willie',6)
my_dog.name #访问实例中的变量
my_dog.age #访问实例中的变量
my_dog.sit() #调用类中的方法
#修改属性的值
my_dog.model = 10 #大多数情况为了封装完整,应该使用方法对属性进行修改
my_dog.update_model(10) #这样修改
类的继承
编写类是,并非总是从空白开始。一个类继承另一个类时,自动获得另一个类所有的属性和方法,原有的类称为父类,新类称为子类,子类也可定义属于自己的属性和方法。
#假设前面已有一个Car类
class ElectricCar(Car):
def __init__(self,make,model,year):
super()._init_(make,model,year) #super是一个特殊函数,将父类和子类联系起来,代表了父类,此处父类和子类的_init_函数保持一致
#此处编写ElecticCar类的独特属性
#子类可以重写父类的方法
#可以将实例用作属性
class Battery():
--skip
class ElectricCar(car):
def _init_(self,make,model,year):
super()._init_(make,model,year)
self.battery = Battery(); #实例作属性
导入类
Python允许你将类储存在模块中,然后在主程序中导入所需的模块:
#car.py
Class Car():
--skip
Class Smartphone():
--skip
#my_car.py
from car import Car #导入整个模块用import car,运用是要在类前加mudule_name.。导入模块中所有类用from car import *
my_new_car = Car('audi','a4',2016)
文件和异常
自此,你已掌握了编写组织有序易于使用的程序所需的基本技巧,为了让程序用途更广,本章将学习处理文件,让程序快速分析大量数据;处理异常,用于管理程序运行时出现的错误,还将学习模块json,保存用户数据,以免程序停止运行后丢失。本章的学习可提高程序的实用性,可用性,稳定性。
从文件中读取数据
假设已创建了一个文件pi_digits.txt
#读取文件,显示内容,不需要主动调用close
with open('pi_digits.txt') as file_object: #文件命名为file_object。相对路径行不通可以用绝对路径
contents = file_object.read() #读取文件内容,传入字符串中
print(contents.rstrip()) #rstrip()方法删除字符串末尾的空白
#逐行读取
with open(filename) as file_object:
lines = file_object.readlines() #readlines()方法从文件中读取每一行,储存在一个列表中
for line in file_object:
print(line)
写入文件
#整体写入
with open(filename,'w') as file_object: #以写入模式打开文件,如果文件不存在会自动创建,已经存在会清空文件
file_object.write("I love programming.") #注意只能写入字符串,写入多行时可以加换行符
#附加内容
with open(filename,'a') as file_object: #以附加模式打开文件,不会清空原有文件,写入的行添加到文件末尾
file_object.write("I love programming.")
异常
发生程序异常时未对异常进行处理,程序会停止。使用try-except代码块时,即使出现异常,也会继续运行,显示你编写的友好的错误信息而不是traceback。
try:
print(5/0)
except ZeroDivisionError:
print('You can\'t divide by zero!')
else: #正常运行
print("answer")
#处理文件找不到的异常
try:
with open(filename) as f_obj:
contents = f_obj.read()
except FileNotFoundError:
msg = "Sorry,the file" + filename + "does not exist." #如果这里写pass,错误时可以不输出信息
print(msg)
分析文本
str.split() #以空格为分隔符将字符串拆分为多个部分,并储存到一个列表中
#计算文本单词数
def count_words(filename):
try:
with open(filename) as f_obj:
contents = f_obj.read()
except FileNotFoundError:
print('Sorry,the file does not exist')
else:
word = contents.split()
num_words = len(words)
print("The file " + filename + "has about " + str(num_words) + " words.")
存储数据
程序需要把用户提供的数据存储在列表和字典等数据结构中,用户关闭程序时,需要保存他们提供的信息,一种简单的办法是用模块json来储存信息
json.dump()和json.load()
import json
numbers = [2,3,5,7,11,13]
filename = 'numbers.json'
with open(filename,'w') as f_obj:
json.dump(numbers,f_obj) #传入要储存的数据和储存数据的文件对象
#文件中数据存储格式和Python中一样[2,3,5,7,11,13]
#再将列表读取到内存中
with open(filename) as f_obj:
numbers = json.load(f_obj) #列表被读取出来
测试代码
每个程序员都需要经常测试其代码,在用户发现问题前找到它,因此需要编写测试代码改进代码。
Python标准库中的模块unittest提供了测试工具,单元测试用于核实函数的某个方面没有问题。
import unittest
from name_function import get_formatted_name
#测试类,所有以test_开头的方法自动运行
class NamesTestCase(unittest.TestCase): #必须继承unittest.TestCase
def test_first_last_name(self): #核实名和姓能否被正确格式化
formatted_name = get_formatted_name('janis','joplin')
self.assertEqual(formatted_name,'Janis Joplin') #断言方法,核实得到的结果与期望是否一致
unittest.main()
#如果全部测试通过会输出OK,第一行的句点表明几个测试通过
#不通过第一行会有E,最后显示FALLED
#测试不通过时,意味新代码有错。不要修改测试,而应修改导致测试不通过的代码。
| 方法 | 用途 |
|---|---|
| assertEqual(a,b) | 核实a == b |
| assertNotEqual(a,b) | 核实a != b |
| assertTrue(x) | 核实x为True |
| assertFalse(x) | 核实x为False |
| assertIn(item,list) | 核实item在list中 |
| assertNotIn(item,list) | 核实item不在list中 |
类的测试和函数的测试类似:
#假设已经创建了一个匿名调查类AnonymousSurvey
from survey import AnonymousSurvey
import unittest
class TestAnonmyousSurvey(unittest.TestCase):
def test_store_single_response(self):
question = 'what language did you first learn to speak?'
my_survey = AnonymousSurvey(question) #问题
my_survey.store_response('English') #答案,会添加到答案列表中
my_survey.store_response('Chinese')
self.assertIn('English',my_survey.responses)
unittest.main()
方法setUp(),TestCase类包含方法,对测试函数初始化
from survey import AnonymousSurvey
import unittest
class TestAnonmyousSurvey(unittest.TestCase):
def setUp(self):
question = 'what language did you first learn to speak?'
my_survey = AnonymousSurvey(question) #输入问题
self.responses = ['English','Spanish','Mandarin']
def test_store_single_response(self): #测试一个答案
my_survey.store_response(self.responses[0])
self.assertIn(self.responses[0],my_survey.responses)
def test_store_three_responses(self): #测试三个答案
for response in self.responses:
self.my_survey.store_reponse(response)
for response in self.responses:
self.assertIn(response,self.my_survey.responses)
unittest.main()
项目
数据可视化
数据可视化是通过可视化来表示探索数据,与数据挖掘紧密相关,在基因研究,天气研究,政治经济分析等众多领域,大家都使用Python完成数据密集型工作,数据科学家编写了一系列令人印象深刻的可视化和分析工具,最流行的是matplotlib,它是一个数学绘图库,可以制作简单的图表。我们还将使用Pygal包,它专注于生成适合在数字设备上显示的图表。
pycharm安装matplotlib十分方便快捷,直接在File→setting→Project interpreter中一键导入即可,不再赘述。
绘制简单曲线图
#最简版
import matplotlib.pyplot as plt
squares = [1,4,9,16,25]
plt.plot(squres)
plt.show()

#改善可读性
import matplotlib.pyplot as plt
input_values = [1,2,3,4,5] #x轴的值
squares = [1,4,9,16,25] #y轴的值
plt.plot(input_values,squares,linewidth = 5) #线段宽度
plt.title("Square Numbers",fontsize = 24) #标题及其大小
plt.xlabel("Value",fontsize = 14) #x轴标签及其大小
plt.ylabel("Square of Value",fontsize = 14) #y轴标签及其大小
plt.tick_params(axis = 'both',labelsize = 14) #设置刻度标记的大小
plt.show()

绘制散点图
import matplotlib.pyplot as plt
x_values = [1,2,3,4,5]
y_values = [1,4,9,16,25]
#scatter方法绘制散点图,可删除数据点黑色轮廓,可设置颜色,默认为蓝色。cmap = plt.cm.Blues为设置渐变蓝色
plt.scatter(x_values,y_values,s = 100,edgecolor = 'none',c = 'red')
plt.title("Square Numbers",fontsize = 24) #配置四连,不再赘述
plt.xlabel("Value",fontsize = 14)
plt.ylabel("Square of Value",fontsize = 14)
plt.tick_params(axis = 'both',labelsize = 14)
plt.show()
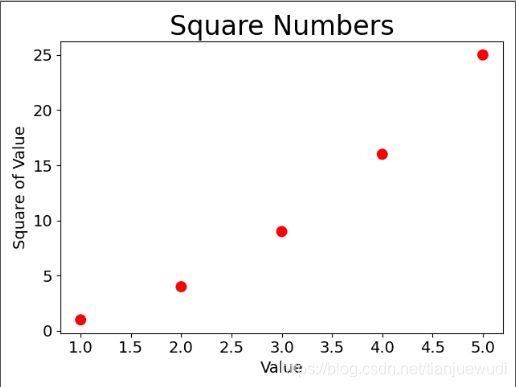
保存图表
#第一个实参是文件名,第二个指定将图表多余的空白裁剪掉
plt.savefig('squares_plot.png',bbox_inches = 'tight')
随机漫步
from random import choice
import matplotlib.pyplot as plt
class RandomWalk():
def __init__(self,num_points = 5000):
self.num_points = num_points
self.x_values = [0]
self.y_values = [0]
def fill_walk(self):
while len(self.x_values) < self.num_points:
x_direction = choice([1,-1]) #这里采用choice方法选取随机数
x_distance = choice([0,1,2,3,4])
x_step = x_direction * x_distance
y_direction = choice([1, -1])
y_distance = choice([0, 1, 2, 3, 4])
y_step = y_direction * y_distance
if x_step == 0 and y_step == 0:
continue
next_x = self.x_values[-1] + x_step
next_y = self.y_values[-1] + y_step
self.x_values.append(next_x)
self.y_values.append(next_y)
rw = RandomWalk()
rw.fill_walk()
point_numbers = list(range(rw.num_points))
plt.scatter(0,0,s = 100,c = 'green',edgecolor = 'none') #绘制起点
plt.scatter(rw.x_values[-1],rw.y_values[-1],s = 100,c = 'red',edgecolor = 'none') #绘制终点
plt.scatter(rw.x_values,rw.y_values,s = 15,c = point_numbers, #根据绘制的先后决定点颜色的深浅
cmap=plt.cm.Blues,edgecolor = 'none')
#plt.figure(dpi=128,figsize=(10,6)) 调整绘图窗口尺寸
plt.show()

使用Pygal模拟掷骰子(柱状图)
from random import randint
import pygal
class Die():
def __init__(self,numsides = 6):
self.num_sides = numsides
def roll(self):
return randint(1,self.num_sides)
#投掷1000次,结果储存在列表中
die = Die()
results = []
for roll_num in range(10000):
result = die.roll()
results.append(result)
#处理数据
frequencies = []
for value in range(1,die.num_sides+1):
frequency = results.count(value) #count函数,计算列表中一个值出现的次数
frequencies.append(frequency)
print(frequencies)
#构建柱状图
hist = pygal.Bar()
hist.title = 'Results of rolling one D6 1000 times.'
hist.x_labels = ['1','2','3','4','5','6']
hist.x_title = "Result"
hist.y_title = "Frequency of Result"
hist.add('D6',frequencies)
hist.render_to_file('die_visual.svg') #保存文件
{% asset_img 5.png %}
从网上下载数据并处理和绘图
本章中,你将从网上下载数据,并对数据进行可视化。我们将使用Python模块csv来处理以CSV(逗号分隔的值)格式存储的天气数据,使用模块json来访问以JSON存储的人口数据。
绘制天气情况图表
import csv
from matplotlib import pyplot as plt
from datetime import datetime
filename = 'death_valley_2014.csv'
with open(filename) as f:
reader = csv.reader(f) #创建一个与该文件向关联的阅读器
header_row = next(reader) #返回文件中的下一行,这里是第一行,返回一个列表,以逗号分隔开的内容为一个元素
# for index,conlumn_header in enumerate(header_row): #enumerate()方法获取列表每个元素的索引和值
# print(index,conlumn_header)
dates,highs,lows = [],[],[]
# 遍历文件余下的各行,阅读器对象从其停留的地方继续往下读取csv文件,每次返回下一行,第一行已经读取,这里从第二行开始
# 返回的都是第二列每一天最高温度的值
for row in reader:
try: #对缺失的数据进行检查
current_date = datetime.strptime(row[0],"%Y-%m-%d") #这里获取日期,第二个参数指定如何解读日期
high = int(row[1]) #转化为整形,matplotlib才能读取它们
low = int(row[3])
except ValueError:
print(current_date,'missing data')
else:
dates.append(current_date)
highs.append(high)
lows.append(low)
#绘图代码
fig = plt.figure(dpi = 128,figsize=(10,6)) #调节图的大小,第一个参数是窗口分辨率,第二个是长和宽
plt.plot(dates,highs,c='red',alpha=0.5) #画折线图,alpha为透明度
plt.plot(dates,lows,c='blue',alpha=0.5)
plt.fill_between(dates,highs,lows,facecolor = 'blue',alpha=0.1) #中间填充颜色
fig.autofmt_xdate() #绘制倾斜的x轴标签
plt.title('Daily high and low temperatures - 2014',fontsize=24)
plt.xlabel('',fontsize=16)
plt.ylabel('Temperature(F)',fontsize=16)
plt.tick_params(axis='both',which = 'major',labelsize = 16)
plt.show()
datetime.strptime方法第一个参数是传入的字符串,第二个参数规定字符串的格式,下表列出了一些这样的实参:
| 实参 | 含义 |
|---|---|
| %A | 星期的名称,如Monday |
| %B | 月份名称,如January |
| %m | 用数字表示的月份(01-12) |
| %d | 用数字表示的月份中的一天(01-31) |
| %Y | 四位的年份,如2021 |
| %y | 两位的年份,如21 |
| %H | 24小时的小时数(00-23) |
| %I | 12小时的小时数(01-12) |
| %p | am或pm |
| %M | 分钟数(00-59) |
| %S | 秒数(00-61) |
制作世界人口地图
JSON文件其实是一个很长的列表,每个元素都是字典。
书本提供的链接已经不能下载数据,但感谢CSDN的兄弟,让我下载到了这份数据,链接附上:
https://pan.baidu.com/s/1FlwB2SQzn_z06SR3eM9mJg,提取码:q6vy
注意:原来的pygal.i18n的包已经弃用,改为pygal.maps.world,请自行下载pygal_maps_world模块。
代码如下:
import json
from pygal.maps.world import COUNTRIES #注意原来的包已经弃用,COUNTIES是一个字典,两位国别码是键,国家名是值
import pygal
from pygal.style import RotateStyle as RS,LightColorizedStyle as LCS
def get_country_code(country_name): #获取两位国别码的函数
for code,name in COUNTRIES.items():
if name == country_name:
return code
return None
filename = "population_data.json"
with open(filename) as f:
pop_data = json.load(f) #生成一个列表,每个元素是字典
cc_populations = {
}
for pop_dict in pop_data:
if pop_dict['Year'] == '2010': #只用2010年的信息
country_name = pop_dict['Country Name']
population = int(float(pop_dict['Value']))
code = get_country_code(country_name) #获取两位国别码
if code: #过滤掉不是国家的信息
cc_populations[code] = population
cc_pops_1,cc_pops_2,cc_pops_3 = {
},{
},{
} #分成三类可以用不同颜色的深浅表示,区分度更明显
for cc,pop in cc_populations.items():
if pop < 10000000:
cc_pops_1[cc] = pop
elif pop < 1000000000:
cc_pops_2[cc] = pop
else:
cc_pops_3[cc] = pop
wm_style = RS('#336699',base_style=LCS) #让地图颜色更一致,更明亮,更容易区分不同的编组
wm = pygal.maps.world.World(style = wm_style)
wm.title = ('World Population in 2010, by Country')
wm.add('0-10m',cc_pops_1)
wm.add('10m-1bn',cc_pops_2)
wm.add('>1bn',cc_pops_3)
wm.render_to_file('americas.svg')

使用API
在本章,程序将使用Web应用编程接口(API)自动请求网站的特定信息而不是整个网站,再对信息进行可视化,这样信息是最新的。
使用API调用请求数据,在浏览器地址栏输入:
https://api.github.com/search/repositories?q=language:python&sort=stars
这个调用返回GitHub当前托管了多少个项目,还有最受欢迎的Python仓库的信息。
import requests
url = 'https://api.github.com/search/repositories?q=language:python&sort=stars'
r = requests.get(url)
print('Status code:',r.status_code) #状态码为200则响应成功
response_dict = r.json() #这个API返回的是JSON格式信息,因此转换为字典
print(response_dict.keys())
print("Total repositories:",response_dict['total_count']) #看仓库总数
#看获取了多少仓库的信息
repo_dicts = response_dict['items']
print("Repositories returned:",len(repo_dicts))
#查看获取到的每个仓库的信息
print("\nSelected information about each repository:")
for repo_dict in repo_dicts:
print("\nName:",repo_dict['name'])
print("Owner:", repo_dict['owner']['login'])
print('Stars:',repo_dict['stargazers_count'])
print('Repository:',repo_dict['html_url'])
print('Description:',repo_dict['description'])
监视API速率限制,在浏览器输入:https://api.github.com/rate_limit,内容如下:
{"resources":
{"core":
{"limit":60,"remaining":60,"reset":1610899050,"used":0},
"graphql":{"limit":0,"remaining":0,"reset":1610899050,"used":0},
"integration_manifest":{"limit":5000,"remaining":5000,"reset":1610899050,"used":0},
"search":{"limit":10,"remaining":10,"reset":1610895510,"used":0}
},
"rate":{"limit":60,"remaining":60,"reset":1610899050,"used":0}
}
我们关心的是搜索API的速率限制,可知极限为每分钟10个请求,用完配额后会受到一条简单的响应,必须等待配额重置。很多API都要求你注册获得API秘钥后才能执行API调用。
使用API可视化仓库:
import requests
import pygal
from pygal.style import LightColorizedStyle as LCS,LightenStyle as LS
url = 'https://api.github.com/search/repositories?q=language:python&sort=stars'
r = requests.get(url)
print('Status code:',r.status_code) #状态码为200则响应成功
response_dict = r.json() #这个API返回的是JSON格式信息,因此转换为字典
print(response_dict.keys())
print("Total repositories:",response_dict['total_count']) #看仓库总数
repo_dicts = response_dict['items']
#收集每个仓库的名字和星数信息
names,plot_dicts,stars = [],[],[]
for repo_dict in repo_dicts:
names.append(repo_dict['name'])
plot_dict = {
'value': repo_dict['stargazers_count'], #数据
'label': str(repo_dict['description']), #描述
'xlink': repo_dict['html_url'], #链接
}
plot_dicts.append(plot_dict)
stars.append(repo_dict['stargazers_count'])
my_style = LS('#333366',base_style=LCS) #定义样式,基色为深蓝色
my_config = pygal.Config() #创建设定,下面是一系列设定
my_config.x_label_rotation = 45
my_config.show_legend = False
my_config.title_font_size = 24
my_config.label_font_size = 14
my_config.major_label_font_size = 18 #主要标签大小
my_config.truncate_label = 15 #较长的项目名缩短为15个字符
my_config.show_y_guides = False #隐藏图表中的水平线
my_config.width = 1000 #图表宽度
chart = pygal.Bar(my_config,style = my_style)
chart.title = "Most_Starred Python Projects on Github"
chart.x_labels = names #x轴标签
chart.add('',plot_dicts) #导入数据
chart.render_to_file('python_repos.svg')
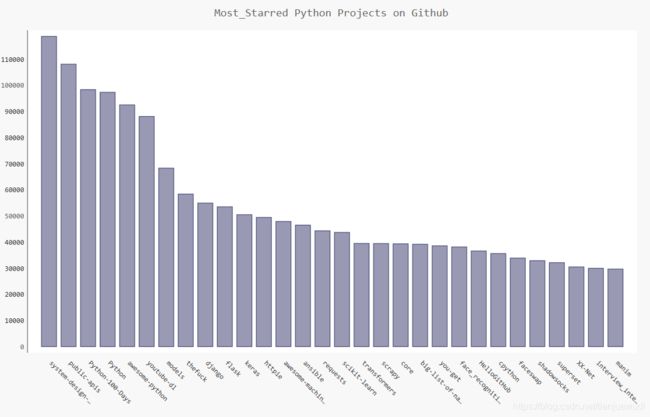
探索如何使用其他网站的API调用,可以自己去查API接口,这部分内容我会在以后更新放在其他博文里。
Django入门
建立项目
Python提供了一组开发Web开发的卓越工具,这时一个Web框架,一套用于帮助开发交互式网站的工具。
建立虚拟环境,新建一个目录,将终端切换到这个目录,使用如下命令建立虚拟环境:
python -m venv 11_env
建立虚拟环境后,需要使用如下命令激活它:
source 11_env/Scripts/activate
环境处于激活状态时环境名包含在括号里,这时可以在环境中安装包,使用已安装的包,在11_env中安装的包在环境处于活动状态时才能使用。
如果要停止虚拟环境,执行命令:
deactivate
安装Django:
pip3 install Django
在Django中创建项目:
django-admin.py startproject learning_log
这时在根目录下就会出现learning_log文件夹,内含几个.py文件。manage.py接受命令交给Django的相关部分执行,管理诸如使用数据库和运行服务器等任务。文件settings.py指定Django如何与你的系统交互,如何管理项目。urls.py告诉Django应该创建哪些网页来响应浏览器的请求。文件wsgi.py帮助Django提供它创建的文件。
创建数据库:
Django将大部分与项目相关的信息都储存在数据库中,因此我们需要创建一个供Django使用的数据库,活跃状态下进入manage.py的目录执行如下命令:
python manage.py migrate
我们将修改数据库成为迁移数据库,在使用SQLite的新项目中首次执行这个命令时,Django将新建一个数据库。在这里Django创建必要的数据库表,用于储存我们将在这个项目中使用的信息,确保数据库结构与当前代码匹配。
核实Django是否正确创建了项目:
python manage.py runserver
Django启动服务器,让你能够查看系统中的项目,当你在浏览器中输入URL请求网页时,Django服务器将进行响应。打开浏览器输入:http://localhost:8000/即可查看网页,控制台按Ctrl+C可以关闭服务器。

创建应用程序
在激活状态下,切换到manage.py的目录下执行命令:
python manage.py startapp learning_logs
Django创建程序应用learning_logs,项目文件新增一个文件夹learning_logs,里面有一些.py文件,其中models.py定义我们要在应用程序中管理的数据。
models.py:
from django.db import models
class Topic(models.Model): #Model是Django中定义了模型基本功能的类,只有text和date_added两个属性
text = models.CharField(max_length=200) #CharField储存少量文本,在数据库中预留200个字符的位置
date_added = models.DateTimeField(auto_now_add=True) #记录日期和时间,当用户创建新主题,自动设置成当前日期和时间
def __str__(self): #显示模型的简单表示
return self.text
然后打开learning_log目录下的setting.py,把修改一段代码:
INSTALLED_APPS = [ #安装在项目中的应用程序
'django.contrib.admin',
'django.contrib.auth',
'django.contrib.contenttypes',
'django.contrib.sessions',
'django.contrib.messages',
'django.contrib.staticfiles',
#我的应用程序
'learning_logs',
]
接下来需要Django修改数据库,使其能够储存于模型Topic相关的信息,在终端执行:
python manage.py makemigrations learning_logs
命令makemigrations让Django确定如何修改数据库,使其储存与我们定义的新模型相关的数据,Django创建了一个名为0001——initial.py的迁移文件,这个文件在数据库中为模型Topic创建一个表。
应用这种迁移:
python manage.py migrate
当需要修改数据时,都需要采取如下三个步骤:修改models.py,对learning_logs调用makemigrations,让Django迁移项目。
Django管理网站:
为应用程序定义模型时,Django提供的管理网站(admin site)让你能轻松处理模型。
Django允许创建具备所有权限的用户——超级用户,命令如下(要在cmd执行否则不成功):
python manage.py createsuperuser
向管理网站注册模型:
Django自动在网站中添加了一些模型,如User和Group,但对于我们自己创建的模型,必须进行手工注册。
models.py所在的目录中有admin.py文件,为向管理网站注册Topic,输入下面代码:
from django.contrib import admin
from learning_logs.models import Topic #导入要注册的模型
admin.site.register(Topic) #可以通过管理网站管理模型了
访问http://localhost:8000/admin/,输入用户名和密码,可以进入超级用户账户访问管理网站,可以让你添加修改用户和用户组,管理刚才定义的模型Topic相关的数据。
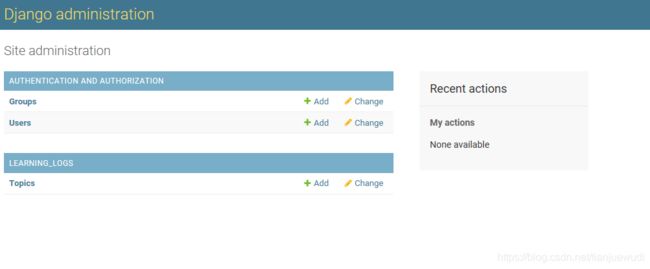
添加主题
单击Topics进入主题网页,单击Add,看到一个用于添加新主题的菜单,输入Chess单击Save。在Add一个Rock Climbing。这样就有两个主题了。
定义模型Entry:
要记录学到的国际象棋和攀岩知识,需要为用户可在学习笔记中添加的条目定义模型,每个条目都与特定主题相关联,这种关系被称为多对一关系,即多个条目可关联到同一个主题:
models.py
from django.db import models
class Topic(models.Model): #Model是Django中定义了模型基本功能的类,只有text和date_added两个属性
text = models.CharField(max_length=200) #CharField储存少量文本,在数据库中预留200个字符的位置
date_added = models.DateTimeField(auto_now_add=True) #记录日期和时间,当用户创建新主题,自动设置成当前日期和时间
def __str__(self): #显示模型的简单表示
return self.text
class Entry(models.Model):
#外键是数据库术语,引用数据库中另一条记录将条目关联到特定的主题
#在django2.0后,定义外键和一对一关系的时候需要加on_delete选项,此参数为了避免两个表里的数据不一致问题,不然会报错
topic = models.ForeignKey(Topic,on_delete=models.CASCADE)
text = models.TextField() #不需要长度限制的字段
date_added = models.DateTimeField(auto_now_add=True) #按创建顺序呈现条目,条目旁边放置时间戳
class Meta: #储存用于管理模型的额外信息,可以使用entries表示多个条目
verbose_name_plural = 'entries'
def __str__(self):
return self.text[:50] + "..." #呈现条目时只显示前50个字符
修改完models.py后记得迁移模型:
python manage.py makemigrations learning_logs
python manage.py migrate
这时会生成一个新的迁移文件0002——entry.py,使数据库能储存于模型Entry相关的信息。
然后向管理网站注册Entry:
admin.py:
from django.contrib import admin
from .models import Topic,Entry
admin.site.register(Topic)
admin.site.register(Entry)
这时登录超级用户管理网站,就可以在主题下添加条目了:

输入一些数据后,就可以通过交互式终端会话以编程方式查看这些数据了,这种交互式环境被称为Django Shell,是测试项目和排除故障的理想之地。下面是交互式Shell示例:
$ python manage.py shell
>>> from learning_logs.models import Topic
>>> Topic.objects.all()
, ]>
>>> topics = Topic.objects.all()
>>> for topic in topics:
... print(topic.id,topic)
...
1 Chess
2 Rock Climbing
知道对象的ID后,就可获取该对象并查看其任何属性,其中内容展示由于中文原因造成乱码:
>>> t = Topic.objects.get(id=1)
>>> t.text
'Chess'
>>> t.date_added
datetime.datetime(2021, 1, 18, 15, 29, 47, 62586, tzinfo=)
>>> t.entry_set.all()
]>
退出shell会话输入exit()按回车即可。
创建网页:学习笔记主页
使用Django创建网页的过程分为三个阶段:定义URL、编写视图、编写模板。
首先必须定义URL模式,URL模式描述了URL是如何设计的,让Django知道如何将浏览器请求与网站URL匹配,以确定返回哪个网页。
每个URL都被映射到特定的视图——视图函数获取并处理网页所需的信息。视图函数通常调用一个模板,后者生成浏览器能够理解的网页。
映射URL:
用户通过在浏览器中点击链接或输入URL来请求网页,因此我们需要确定项目需要哪些URL。主页的URL最重要,是用户访问项目的基础URLhttp://localhost:8000/。我们将这个基础URL映射到“学习笔记”的主页。
**在这里书本上的代码是Django1.0时期的,而后来新出的Django2.0使代码有了很大变化,此处是书本的大坑。**此处请参照下面代码:
urls.py:
#注意2.0的代码的变化
from django.contrib import admin
from django.urls import path, include
urlpatterns = [
path('admin/', admin.site.urls),
path('', include('learning_logs.urls', namespace='learning_logs')),
]
此时我们需要在文件夹learning_logs中创建另一个urls.py文件,代码修改如下:
urls.py:
from django.urls import path
from . import views #从此文件所在的目录中导入wiews
app_name='learning_logs' #巨坑,书中没有,不写runserver时会报错
#URL模式是一个对函数path的调用,第一个参数是正则表达式,第二个参数指定了调用的视图函数第三个参数指定名称
#当需要提供到这个主页的链接时,都将使用这个名称而不是编写URL
urlpatterns = [ #包含可在learning_logs中请求的网页
path('', views.index, name='index'), # 主页
]
视图函数接受请求中的信息,准备好生成网页所需要的数据,再将这些数据发送给浏览器,这通常定义了网页是什么样的模板实现的。
views.py:
from django.shortcuts import render
def index(request):
return render(request,'learning_logs/index.html') #参数是原始请求对象以及一个可用于创建网页的模板
URL请求与我们刚才定义的模式匹配时,Django将在views.py文件中查找函数,再将请求对象传递给这个视图函数,在这里我们不需要处理任何数据。
编写模板:
模板定义了网页的结构,指定了网页是什么样的,每当网页被请求时,Django将填入相关的数据,模板能让你访问视图提供的任何数据,我们的主页视图没有提供任何的数据,因此相应的模板非常简单。
在文件夹learning_logs中新建一个文件夹,命名templates,在里面新建一个文件夹名为learning_logs,在learning_logs中新建文件命名index.html。
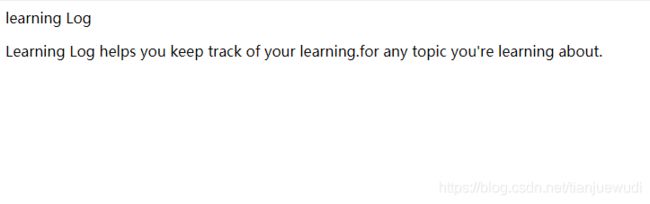
index.html:
<p>learning Logp>
<p>Learning Log helps you keep track of your learning.for any topic you're learning about.p>
此时运行服务器,进入首页,看到的不是默认的Django网页,而是调用函数view.index()后使用index.html模板来渲染的网页。
创建网页的过程看起来很复杂,但将URL、视图、模板分离的效果实际上很好,这让我们能够分别考虑到项目的不同方面,在项目很大时,每个参与者可专注于其擅长的方面。数据库专家专注于模型,程序员专注于视图代码,Web设计人员专注于模板。
创建其他网页
我们将创建两个显示数据的网页,一个列出所有主题,一个显示特定主题下的所有条目,每个网页都将指定URL模式,编写一个视图函数,并编写一个模板,但这样做之前,要先创建一个父模板,项目中的其他模板都继承它。
模板继承:
在创建网站时,有一些所有网页都包含的元素,可编写一个包含通用元素的模板,让所有网页继承这个模板。
首先创建一个名为base.html的模板,储存在index.html所在的目录中,所有页面都包含顶端的标题,这个标题设置为到主页的链接:
base.html:
<p>
<a href="{% url 'learning_logs:index' %}">learning Loga>
p>
{% block content %}{% endblock content %}
第一部分创建了包含项目名的段落,该段落也是一个到主页的链接。为创建链接,我们使用了一个模板标签,它生成了一个URL,该URL与learning_logs/urls.py中定义的名为index的URL模式匹配。此时,learning_logs是一个命名空间,index是该命名空间中一个名称独特的URL模式,在简单的HTML页面中,链接是使用锚标签定义的:
<a href="link_url">link texta>
使用模板标签生成URL可让链接保持最新容易得多,修改项目中的URL只需修改urls.py的URL模式。
第二部分插入了一对块标签,名为content,是一个占位符,其中的内容由子模板指定。在父模板中,可使用任意多的块来预留空间,而子模板可根据需要定义相应数量的块。
重新编写index.html:
{% extends "learning_logs/base.html" %}
{% block content %}
<p>Learning Log helps you keep track of your learning.for any topic you're learning about.p>
{% endblock content %}
与原来的代码相比,我们将标题替换为了从父模板继承的代码。在子模板中只需包含当前网页特有的内容,简化了模板,让网站修改容易得多。
显示所有主题的页面:
首先定义显示所有主题页面的URL,我们将使用单词topics,因此http://localhost:8000/topics/将返回这个页面,learning_logs/urls.py修改如下:
from django.urls import path
from . import views #从此文件所在的目录中导入wiews
app_name='learning_logs' #巨坑,书中没有,不写runserver时会报错
#URL模式是一个对函数path的调用,第一个参数是正则表达式,第二个参数指定了调用的视图函数第三个参数指定名称
#当需要提供到这个主页的链接时,都将使用这个名称而不是编写URL
urlpatterns = [ #包含可在learning_logs中请求的网页
path('', views.index, name='index'), # 主页
path('topics/', views.topics, name='topics'), # 显示所有的主题
]
views.py:
from django.shortcuts import render
from .models import Topic #导入所需数据相关的模型
def index(request):
return render(request,'learning_logs/index.html')
def topics(request): #形参是Django从服务器收到的request对象
#显示所有主题
topics = Topic.objects.order_by('date_added') #查询数据库,请求提供Topic对象,按属性date_added进行排序
context = {
'topics':topics} #定义一个要发送给模板的上下文字典,键是模板中访问数据的名称,值是我们发送给模板的数据
return render(request,'learning_logs/topics.html',context)#这里多传递一个数据
同样在index.html所在目录中,创建topics.html:
{% extends "learning_logs/base.html" %}
{% block content %}
<p>Topicsp>
<ul>
{% for topic in topics %}
<li>{
{ topic }}li>
{% empty %}
<li>No topics have been added yet.li>
{% endfor %}
ul>
{% endblock content %}
在content块中,首先显示一个主题名称的文本。然后使用了一个for循环的模板标签,遍历字典context中的列表topics,这里for循环必须使用 endfor 标签来显式指出其结束位置。在循环中,需要将变量名用双花括号括起来,告诉Django使用了一个模板变量,这样{ { topic }}每次循环都会被替换成topic当前值。在标签对
此时修改父模板,将其包含到显示所有主题的页面的链接:
base.html:
<p>
<a href="{% url 'learning_logs:index' %}">learning Loga> -
<a href="{% url 'learning_logs:topics' %}">Topicsa>
p>
{% block content %}{% endblock content %}
主页链接后面添加了一个连字符。后面新加一行让Django生成一个链接,与learning_logs/urls.py中名为topics的URL模式匹配。
现在可以在浏览器看到效果了:

显示特定主题的页面
显示特定主题的URL模式与前面所有的URL模式有所不同,它将使用主题的id属性来指出请求的是哪个主题,例如用户查看主题Chess(id为1)的详细页面,URL将为http://localhost:8000/topics/1/。
urls.py:
from django.urls import path,re_path
from . import views #从此文件所在的目录中导入wiews
app_name='learning_logs' #巨坑,书中没有,不写runserver时会报错
#URL模式是一个对函数path的调用,第一个参数是正则表达式,第二个参数指定了调用的视图函数第三个参数指定名称
#当需要提供到这个主页的链接时,都将使用这个名称而不是编写URL
urlpatterns = [ #包含可在learning_logs中请求的网页
path('', views.index, name='index'), # 主页
path('topics/', views.topics, name='topics'), # 显示所有的主题
re_path('topics/(?P\d+)/' , views.topic, name='topic'), # 特定主题的详细页面
#使用正则表达式要用re_path否则控制台报警告
]
这里采用了正则表达式?P
views.py:
from django.shortcuts import render
from .models import Topic #导入所需数据相关的模型
def index(request):
return render(request,'learning_logs/index.html')
def topics(request): #形参是Django从服务器收到的request对象
#显示所有主题
topics = Topic.objects.order_by('date_added') #查询数据库,请求提供Topic对象,按属性date_added进行排序
# 定义一个要发送给模板的上下文字典,键是模板中访问数据的名称,值是我们发送给模板的数据
context = {
'topics':topics}
return render(request,'learning_logs/topics.html',context)#这里多传递一个数据
def topic(request,topic_id):
#显示单个主题及其所有条目
topic = Topic.objects.get(id=topic_id) #获取指定的主题
entries = topic.entry_set.order_by('-date_added') #获取与该主题相关联的条目,按date_added降序排序
context = {
"topic":topic,'entries':entries} #数据储存在字典中发送给模板topic.html
return render(request,'learning_logs/topic.html',context)
topic.html:
{% extends "learning_logs/base.html" %}
{% block content %}
<p>Topic:{
{ topic }}p>
<ul>
{% for entry in entries %}
<li>
<p>{
{ entry.date_added|date:'M d, Y H:i }}p>
<p>{
{ entry.text|linebreaks }}p>
li>
{% empty %}
<li>
There are no entries for this topic yet.
li>
{% endfor %}
ul>
{% endblock content %}
首先使用了包含在字典context里的topic作为主题。然后遍历entries条目,显示出属性date_added的值,竖线|表示模板过滤器,对模板变量的值修改的函数,过滤器date:'M d, Y H:i以这样的格式显示时间戳:January 1,2021 23:00。接下来的一行享受text的完整值,过滤器linebreaks将包含换行符的长条目转换为浏览器能够理解的格式,以免显示一个不间断的文本块。
将所有主题页面中的每个主题都设置为链接:
topics.html:
{% extends "learning_logs/base.html" %}
{% block content %}
<p>Topicsp>
<ul>
{% for topic in topics %}
<li>
<a href="{% url 'learning_logs:topic' topic.id %}">{
{ topic }}a>
li>
{% empty %}
<li>No topics have been added yet.li>
{% endfor %}
ul>
{% endblock content %}
再次访问网页发现功能已经实现:

用户账户
Web应用程序的核心是让任何用户都能够注册账户并能够使用它。本章中,你将创建一些表单让用户能够添加主题和条目,以及编辑现有条目。你还将学习Django如何防范对基于表单的网页发起的常见攻击。然后,我们将实现一个用户身份验证系统,创建一个注册页面,供用户注册,并让有些页面只让已登录的用户访问。接下来,修改一些视图参数,使用户只能看到自己的数据。
让用户能输入数据
首先让用户能添加新主题,与前面的方法几乎一样,主要差别是需要导入包含表单的模块form.py。
用户输入并提交的信息都是表单,我们需要验证提供的信息是正确的数据类型且不是恶意信息,再对有效的信息进行处理。创建表单最简单的方式是使用ModelForm,它根据我们之前定义的模型中的信息自动创建表单。接下来在models.py的目录下创建forms.py文件:
form.py:
from django import forms
from .models import Topic
class TopicForm(forms.ModelForm):
class Meta:
model = Topic #根据模型Topic创建一个表单
fields = ['text'] #该表单只包含字段text
labels = {
'text':''} #不用为text生成标签
URL模式new_topic:
当用户要添加新主题时,我们将切换到http://localhost:8000/new_topic/。
learning_logs/urls.py:
--snip--
urlpatterns = [ #包含可在learning_logs中请求的网页
--snip--
path('new_topic/', views.new_topic, name='new_topic'), # 同于添加新主题的网页
]
views.py:
from django.shortcuts import render
from .models import Topic #导入所需数据相关的模型
from django.http import HttpResponseRedirect
from django.urls import reverse #注意这里在django2.0的包名有所变化
from .forms import TopicForm
--snip--
def new_topic(request):
if request.method != 'POST': #判断请求是GET还是POST,如未提交数据(点击进入页面链接),创建一个新表单
form = TopicForm()
else: #POST请求,对提交的表单数据进行处理(点击了提交按钮)
form = TopicForm(request.POST) #使用用户输入的数据创建一个TopicForm实例,储存在form中
if form.is_valid(): #检查填写了所有必不可少的字段(默认所有),且输入的数据与要求的类型一致
form.save() #表单中的数据写入数据库
return HttpResponseRedirect(reverse('learning_logs:topics'))#获取topics的URL,重新定位到页面topics
context = {
'form': form}
return render(request,'learning_logs/new_topic.html',context)
创建Web应用程序时,用到的两种主要请求类型是GET请求和POST请求。只是从服务器读取数据的页面使用GET请求,用户需要通过表单提交信息使用POST请求,处理所有表单时,我们都将使用POST方法。
新建new_topic.html:
{% extends "learning_logs/base.html" %}
{% block content %}
<p>Add a new topic:p>
<form action="{% url 'learning_logs:new_topic' %}" method="post">
{% csrf_token %}
{
{ form.as_p }}
<button name="submit">add topicbutton>
form>
{% endblock content %}
从form标签哪一行开始,定义了一个HTML表单,实参action告诉服务器提交的表单数据发送到视图函数new_topic(),以POST请求的方式。 csrf_token 标签防止攻击者利用表单获得对服务器未经授权的访问。{ { form.as_p }}显示表单,自动创建表单需要的全部字段,修饰符as_p以段落格式渲染所有表单元素。下边设置一个提交按钮。
topics.html添加一个到new_topic的链接:
{% extends "learning_logs/base.html" %}
{% block content %}
<p>Topicsp>
<ul>
--snip--
ul>
<a href="{% url 'learning_logs:new_topic' %}">Add a new topic:a>
{% endblock content %}
现在打开服务器,打开网页,可以看到效果了:
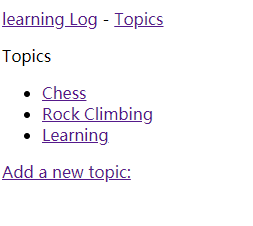
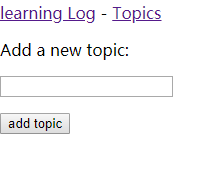
添加新条目:
forms.py:
from django import forms
from .models import Topic,Entry
--snip--
class EntryForm(forms.ModelForm):
class Meta:
model = Entry
field = {
'text'}
labels = {
'text':''}
#设置widgets可覆盖Django选择的默认小部件。forms.Textarea定制字段'text'的输入小部件,并设置文本宽度80列
widgets = {
'text': forms.Textarea(attrs={
'cols':80})}
learning_logs/urls.py:
urlpatterns = [ #包含可在learning_logs中请求的网页
--snip--
re_path('new_entry/(?P\d+)/' , views.new_entry, name='new_entry'), # 添加新条目的网页
]
views.py:
--snip--
from .forms import TopicForm,EntryForm
--snip--
def new_entry(request,topic_id):
topic = Topic.objects.get(id=topic_id)
if request.method != 'POST':
form = EntryForm()
else:
form = EntryForm(data=request.POST) #填充数据
if form.is_valid():
new_entry = form.save(commit=False) #保存到new_entry中,但不保存到数据库中
new_entry.topic = topic #获取主题
new_entry.save() #保存到数据库,与主题关联
#列表args包含在URL中的所有实参,在这里只有一个
return HttpResponseRedirect(reverse('learning_logs:topic',args=[topic_id]))
context = {
'topic': topic,'form': form}
return render(request,'learning_logs/new_entry.html',context)
new_entry.html:
{% extends "learning_logs/base.html" %}
{% block content %}
<p><a href="{% url 'learning_logs:topic' topic.id %}">{
{ topic }}a>p>
<p>Add a new entry:p>
<form action="{% url 'learning_logs:new_entry' topic.id %}" method="post">
{% csrf_token %}
{
{ form.as_p}}
<button name="submit">add entrybutton>
form>
{% endblock content %}
页面的顶端是主题名,同时也是一个链接。表单的实参action包含topic_id值,让视图函数能将新条目关联到正确的主题。
更改topic.html,添加链接:
{% extends "learning_logs/base.html" %}
{% block content %}
<p>Topic:{
{ topic }}p>
<p>Entriesp>
<p>
<a href="{% url 'learning_logs:new_entry' topic.id %}">add new entrya>
p>
<ul>
--snip--
ul>
{% endblock content %}
这时网页就可以看到效果了:


编辑条目
创建一个页面,让用户能编辑现有的条目。
urls.py:
--snip--
urlpatterns = [ #包含可在learning_logs中请求的网页
--snip--
re_path('edit_entry/(?P\d+)/' , views.edit_entry, name='edit_entry'), # 编辑条目页面
]
views.py:
from django.shortcuts import render
from .models import Topic,Entry #导入所需数据相关的模型
from django.http import HttpResponseRedirect
from django.urls import reverse #注意这里在django2.0的包名有所变化
from .forms import TopicForm,EntryForm
--snip--
def edit_entry(request,entry_id):
entry = Entry.objects.get(id-entry_id)
topic = entry.topic
if request.method != 'POST':
form = EntryForm(instance=entry) #根据现有条目创建表单
else:
form = EntryForm(instance=entry,data=request.POST) #根据现有条目创建表单,根据POST内容对其进行修改
if form.is_valid():
form.save()
return HttpResponseRedirect(reverse('learning_logs:topic',args=[topic.id]))
context = {
'entry':entry,'topic':topic,'form':form}
return render(request,'learning_logs/edit_entry.html',context)
新建edit_entry.html:
{% extends "learning_logs/base.html" %}
{% block content %}
<p><a href="{% url 'learning_logs:topic' topic.id %}">{
{ topic }}a>p>
<p>Edit entry:p>
<form action="{% url 'learning_logs:edit_entry' entry.id %}" method="post">
{% csrf_token %}
{
{ form.as_p}}
<button name="submit">save changesbutton>
form>
{% endblock content %}
修改topic.html:
--snip--
{% for entry in entries %}
<li>
<p>{
{ entry.date_added|date:'M d, Y H:i' }}p>
<p>{
{ entry.text|linebreaks }}p>
<a href="{% url 'learning_logs:edit_entry' entry.id %}">edit entrya>
li>
--snip--
这时打开网页可以看到效果:


创建用户账户
下面将建立用户注册和身份验证系统,我们将创建一个新的应用程序,包含与处理用户账户相关的所有功能。
首先使用命令创建名为users的应用程序,结构与learning_logs相同:
python manage.py startapp users
settings.py
--snip--
INSTALLED_APPS = [ #安装在项目中的应用程序
--snip--
#我的应用程序
'learning_logs',
'users',
]
learning_log/urls.py:
from django.contrib import admin
from django.urls import path,include
urlpatterns = [
path('admin/', admin.site.urls),
path('', include('learning_logs.urls', namespace='learning_logs')),
path('users/', include('users.urls', namespace='users')),
]
登录页面:
在users文件夹中新建urls.py:
from django.urls import path,re_path
from . import views
from django.contrib.auth.views import LoginView #导入默认视图LoginView
app_name='users'
#URL模式是一个对函数path的调用,第一个参数是正则表达式,第二个参数指定了调用的视图函数第三个参数指定名称
#当需要提供到这个主页的链接时,都将使用这个名称而不是编写URL
urlpatterns = [
#鉴于没有编写视图函数而是使用默认的LoginView,后面的as_view告诉Django去哪里寻找模板
path('login/', LoginView.as_view(template_name='users/login.html'), name='login')
]
接下来在users中创建一个templates目录,在templates中创建一个users目录,又在这个users目录中创建login.html:
{% extends "learning_logs/base.html" %}
{% block content %}
{% if form.errors %}
<p>>Your username and password didn't match.Please try again.p>
{% endif %}
<form method="post" action=" {% 'users:login' %}">
{% csrf_token %}
{
{ form.as_p }}
<button name="submit">log inbutton>
<input type="hidden" name="next" value="{% url 'learning_logs:index' %}" />
form>
{% endblock content %}
首先如果表单的errors属性被设置,就显示错误信息,表示用户名密码不匹配。要让登录视图处理表单,因此将action设置为登录页面的URL,登录视图发送一个表单给模板,模板中显示这个表单并添加一个提交按钮。最后包含了一个隐藏表单元素next,其中的参数value告诉Django在用户登录成功后定位到主页。
下面在base.html添加到登录页面的链接:
<p>
<a href="{% url 'learning_logs:index' %}">learning Loga> -
<a href="{% url 'learning_logs:topics' %}">Topicsa> -
{% if user.is_authenticated %}
Hello,{
{ user.username }}.
{% else %}
<a href="{% url 'users:login' %}">log ina>
{% endif %}
p>
{% block content %}{% endblock content %}
在Django身份验证系统中,每个模板都可使用变量user,这个变量的is_authenticated属性在登录时为True,否则为False。
此时在admin页面退出管理员账户,就可以在网页中看到log in按钮,点击它:

注销:
让用户点击一个按钮就可注销并返回主页:
users/urls.py:
--snip--
urlpatterns = [
path('login/', LoginView.as_view(template_name='users/login.html'), name='login')
path('logout/', views.logout_view, name='logout')
]
users/views.py(注意新版的包名有所变化):
from django.urls import reverse
from django.contrib.auth import logout
from django.http import HttpResponseRedirect
def logout_view(request):
logout(request)
return HttpResponseRedirect(reverse('learning_logs:index'))
建立链接,修改base.html,给登录后的用户名旁边加上log out按钮:
<p>
<a href="{% url 'learning_logs:index' %}">learning Loga> -
<a href="{% url 'learning_logs:topics' %}">Topicsa> -
{% if user.is_authenticated %}
Hello,{
{ user.username }}.
<a href="{% url 'users:logout' %}">log outa>
{% else %}
<a href="{% url 'users:login' %}">log ina>
{% endif %}
p>
{% block content %}{% endblock content %}
注册页面:
users/urls.py:
--snip--
urlpatterns = [
path('login/', LoginView.as_view(template_name='users/login.html'), name='login'),
path('logout/', views.logout_view, name='logout'),
path('register/', views.register, name='register'),
]
users/views.py:
from django.urls import reverse
from django.contrib.auth import logout,login,authenticate
from django.http import HttpResponseRedirect
from django.shortcuts import render
from django.contrib.auth.forms import UserCreationForm
def logout_view(request):
logout(request)
return HttpResponseRedirect(reverse('learning_logs:index'))
def register(request):
if request.method != 'POST': #点击注册,创建一个表单
form = UserCreationForm()
else: #点击提交,录入信息,切换登录状态,转到主页
form = UserCreationForm(data=request.POST)
if form.is_valid():
new_user = form.save()
authenticated_user = authenticate(username=new_user.username,password=request.POST['password1'])
login(request,authenticated_user)
return HttpResponseRedirect(reverse('learning_logs:index'))
context = {
'form':form}
return render(request,'users/register.html',context)
保存用户信息后,我们调用authenticate(),将实参用户名和密码传递给它,返回一个通过了 身份验证的用户对象,然后调用login登录。用户注册时被要求输入密码两次,输入两次相同表单才可能有效。
在login.html目录下新建register.html:
{% extends "learning_logs/base.html" %}
{% block content %}
<form action="{% url 'users:register' %}" method="post">
{% csrf_token %}
{
{ form.as_p}}
<button name="submit">registerbutton>
<input type="hidden" name="next" value="{% url 'learning_logs:index' %}" />
form>
{% endblock content %}
在base.html添加用户在没有登录时显示到注册页面的链接:
--snip--
{% else %}
<a href="{% url 'users:register' %}">registera> -
<a href="{% url 'users:login' %}">log ina>
{% endif %}
--snip--
现在可以看到效果了:

让用户拥有自己的数据
这里将创建一个系统,确定各项数据所属用户,再限制对页面的访问,让用户只能使用自己的数据。
Django提供了修饰器@login_required,可以实现某些页面只允许已登录的用户访问。
修改learning_logs/views.py:
--snip--
from django.contrib.auth.decorators import login_required
--snip--
@login_required
def topics(request):
--snip--
@login_required
def topic(request,topic_id):
@login_required
def new_topic(request):
--snip--
@login_required
def new_entry(request,topic_id):
--snip--
@login_required
def edit_entry(request,entry_id):
--snip--
login_required()检查用户是否已登录,当用户已登录时,才运行topics的代码,否则重定向到登录页面。
修改settings.py,让Django知道到哪里查找登录页面,在末尾添加:
LOGIN_URL = '/users/login/'
现在未登录状态下点击topics或输入编辑添加主题条目的链接,就会跳转到登录页面。
将数据关联到用户:
我们只需将最高层的数据关联到用户,这样更底层的数据自动管理到用户。下面修改模型Topic,添加一个关联到用户的外键,完成后必须对数据库进行迁移。最后必须对一些视图进行修改,使其只显示与当前登录的用户相关联的数据。
models.py
from django.db import models
from django.contrib.auth.models import User
class Topic(models.Model):
text = models.CharField(max_length=200)
date_added = models.DateTimeField(auto_now_add=True)
owner = models.ForeignKey(User,on_delete=models.CASCADE)
def __str__(self): #显示模型的简单表示
return self.text
--snip--
确定当前数据库有哪些用户,输入命令启动Django shell会话:
$ python manage.py shell
Python 3.9.1 (tags/v3.9.1:1e5d33e, Dec 7 2020, 17:08:21) [MSC v.1927 64 bit (AMD64)] on win32
Type "help", "copyright", "credits" or "license" for more information.
(InteractiveConsole)
>>> from django.contrib.auth.models import User
>>> User.objects.all()
, ]>
>>> for user in User.objects.all():
... print(user.username,user.id)
...
tianjue 1
测试账户 2
>>>
迁移数据库:
$ python manage.py makemigrations learning_logs
You are trying to add a non-nullable field 'owner' to topic without a default; we can't do that (the database needs something to populate existing rows).
Please select a fix:
1) Provide a one-off default now (will be set on all existing rows with a null value for this column)
2) Quit, and let me add a default in models.py
Select an option: 1
Please enter the default value now, as valid Python
The datetime and django.utils.timezone modules are available, so you can do e.g. timezone.now
Type 'exit' to exit this prompt
>>> 1
Migrations for 'learning_logs':
learning_logs\migrations\0003_topic_owner.py
- Add field owner to topic
执行迁移:
$ python manage.py migrate
现在可以在shell中验证是否符合预期:
>>> from learning_logs.models import Topic
>>> for topic in Topic.objects.all():
... print(topic,topic.owner)
...
Chess tianjue
Rock Climbing tianjue
Learning tianjue
可以看到每个主题都属于用户tianjue了。
只允许访问自己的主题:
learning_logs/views.py:
--snip--
from django.http import HttpResponseRedirect,Http404
--snip--
@login_required
def topics(request):
# 查询数据库,请求提供Topic对象,只让所有者访问,按属性date_added进行排序
topics = Topic.objects.filter(owner=request.user).order_by('date_added')
context = {
'topics':topics}
return render(request,'learning_logs/topics.html',context)
@login_required
def topic(request,topic_id):
topic = Topic.objects.get(id=topic_id)
if topic.owner != request.user: #如果主题不归用户所有,返回404响应
raise Http404
entries = topic.entry_set.order_by('-date_added')
context = {
'topic':topic,'entries':entries}
return render(request,'learning_logs/topic.html',context)
@login_required
def new_topic(request):
if request.method != 'POST':
form = TopicForm()
else:
form = TopicForm(request.POST)
if form.is_valid():
new_topic = form.save(commit=False)
new_topic.owner = request.user #把新建立的主题和用户关联上
new_topic.save()
return HttpResponseRedirect(reverse('learning_logs:topics'))
context = {
'form': form}
return render(request,'learning_logs/new_topic.html',context)
@login_required
def new_entry(request,topic_id):
topic = Topic.objects.get(id=topic_id)
if topic.owner != request.user: #如果主题不归用户所有,返回404响应
raise Http404
--snip--
@login_required
def edit_entry(request,entry_id):
entry = Entry.objects.get(id=entry_id)
topic = entry.topic
if topic.owner != request.user: #如果主题不归用户所有,返回404响应
raise Http404
--snip--
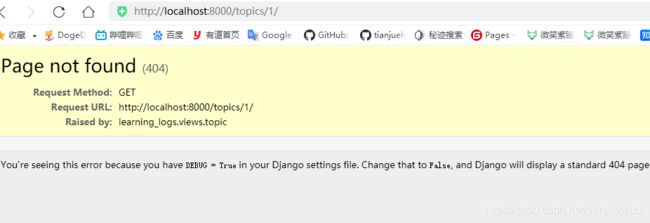

现在这个项目运行任何用户注册,每个用户可以随意添加主题和条目,并且只能访问自己的数据。
设置应用程序的样式并对其进行部署
设置项目的样式
当前,学习笔记的功能基本完成,但未设置样式。我们将使用Bootstrap库,这是一种工具,用于为Web应用程序设置样式,最后把这个项目部署到服务器端。
执行命令,安装django-bootstrap3:
$ pip3 install django-bootstrap3
在settings.py中添加代码:
--snip--
INSTALLED_APPS = [
--snip--
#第三方应用程序
'bootstrap3',
#我的应用程序
'learning_logs',
'users',
]
--snip--
BOOTSTRAP3 ={
'include_jquery': True,
}
需要让django-bootstrap3包含jQuery,这是一个JavaScript库,能够让你使用Bootstrap模板的一些交互性元素,这样无需手工下载jQuery。
Bootstarp是一个大型样式设置工具集,提供了大量的模板,具体可访问https://getbootstrap.com/。
首先需要修改base.html,在这个文件定义HTML头部,添加一些在模板中使用Bootstrap所需的信息,删除base.html全部代码,改为:
{% load bootstrap3 %}
<html lang="en">
<head>
<meta charset="utf-8">
<meta http-equiv="X-UA-Compatible" content="IE=edge">
<meta name="viewport" content="width=device-width, initial-scale=1">
<title>Learning Logtitle>
{% bootstrap_css %}
{% bootstrap_javascript %}
head>
<body>
<nav class="navbar navbar-default navbar-static-top">
<div class="container">
<div class="navbar-header">
<button type="button" class="navbar-toggle collapsed"
data-toggle="collapse" data-target="#navbar"
aria-expanded="false" aria-controls="navbar">button>
<a class="navbar-brand" href="{% url 'learning_logs:index' %}">
Learning Log
a>
div>
<div id="navbar" class="navbar-collapse collapse">
<ul class="nav navbar-nav">
<li><a href="{% url 'learning_logs:topics' %}">Topicsa>li>
ul>
<ul class="nav navbar-nav navbar-right">
{% if user.is_authenticated %}
<li><a>Hello, {
{ user.username }}.a>li>
<li><a href="{% url 'users:logout' %}">log outa>li>
{% else %}
<li><a href="{% url 'users:register' %}">registera>li>
<li><a href="{% url 'users:login' %}">log ina>li>
{% endif %}
ul>
div>
div>
nav>
<div class="container">
<div class="page-header">
{% block header %}{% endblock %}
div>
<div>
{% block content %}{% endblock %}
div>
div>
body>
html>
首先,HTML分为两个主要部分:头部(head)和主体(body),头部不包含任何内容,只是将正确显示页面所需的信息告诉浏览器。
主体包含用户在页面上看到的内容
在class="navbar-header"的地方,定义了一个按钮
- 开头的列表,其中的每个链接都是列表项
- ,要添加更多的链接,可插入下述结构的行:
<li><a href="{% url 'learning_logs:title' %}">Titlea>li>后面的部分是一个容器,包含一个名为header的块和content块,header块决定页面包含哪些消息以及用户可在页面上执行哪些操作,其属性page-header将一系列的样式应用于这个块。
现在打开浏览器可以看到网页发生了很大改变:

设置登录页面的样式:
login.html:
{% extends "learning_logs/base.html" %} {% load bootstrap3 %} {% block header %} <h2>Log in to your account.h2> {% endblock header %} {% block content %} <form method="post" action="{% url 'users:login' %}" class="form"> {% csrf_token %} {% bootstrap_form form %} {% buttons %} <button name="submit" class="btn btn-primary">log inbutton> {% endbuttons %} <input type="hidden" name="next" value="{% url 'learning_logs:index' %}" /> form> {% endblock content %}首先是加载bootstrap3模板,然后定义header块,原来的if form.error代码块删除了,因为bootstrap3会自动管理表单错误。
后面用bootstrap_form form显示表单,替换了原来的form.as_p。后面的按钮用了bootstrap3模板标签。
现在 访问login页面,样式已经改变:
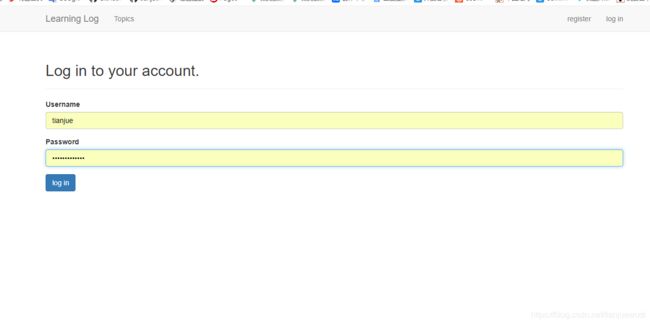
设置new_topic页面的样式:
修改new_topic.html:
{% extends "learning_logs/base.html" %} {% load bootstrap3 %} {% block header %} <h2>Add a new topic:h2> {% endblock header %} {% block content %} <form action="{% url 'learning_logs:new_topic' %}" method="post" class="form"> {% csrf_token %} {% bootstrap_form form %} {% buttons %} <button name="submit" class="btn btn-primary">add topicbutton> {% endbuttons %} form> {% endblock content %}可以看到效果:

设置topics页面的样式:
topics.html:
{% extends "learning_logs/base.html" %} {% block header %} <h1>Add a new topic:h1> {% endblock header %} {% block content %} <ul> {% for topic in topics %} <li> <h3> <a href="{% url 'learning_logs:topic' topic.id %}">{ { topic }}a> h3> li> {% empty %} <li>No topics have been added yet.li> {% endfor %} ul> <h3><a href="{% url 'learning_logs:new_topic' %}">Add a new topic:a>h3> {% endblock content %}这里没有使用bootstrap3自定义标签,只是加了header块,改了字体大小。
设置topic页面中的条目样式:
topic.html:
{% extends "learning_logs/base.html" %} {% block header %} <h2>{ { topic }}h2> {% endblock header %} {% block content %} <p> <a href="{% url 'learning_logs:new_entry' topic.id %}">add new entrya> p> {% for entry in entries %} <div class="panel panel-default"> <div class="panel-heading"> <h3> { { entry.date_added|date:'M d, Y H:i' }} <small> <a href="{% url 'learning_logs:edit_entry' entry.id %}">edit entrya> small> h3> div> <div class="panel-body"> { { entry.text|linebreaks }} div> div> {% empty %} There are no entries for this topic yet. {% endfor %} {% endblock content %}删除了以前使用的无序列表结构,创建了面板式div元素,而不是将每一个条目作为一个列表项,其中有两个嵌套div:面板标题(panel-heading)div和面板主体(panel-body)div。面板标题div包含条目的创建日期以及用于编辑条目的链接,还使用了标签small使其比时间戳小一些。面板主体包含实际文本。
效果如下:

同样,给其他页面设置:
new_entry.html:
{% extends "learning_logs/base.html" %} {% load bootstrap3 %} {% block header %} <h2><a href="{% url 'learning_logs:topic' topic.id %}">{ { topic }}a>h2> <h3>Add a new entry:h3> {% endblock header %} {% block content %} <form action="{% url 'learning_logs:new_entry' topic.id %}" method="post" class="form"> {% csrf_token %} {% bootstrap_form form %} {% buttons %} <button name="submit" class="btn btn-primary">add entrybutton> {% endbuttons %} form> {% endblock content %}edit_entry.html:
{% extends "learning_logs/base.html" %} {% load bootstrap3 %} {% block header %} <h2><a href="{% url 'learning_logs:topic' topic.id %}">{ { topic }}a>h2> <h3>Edit entry:h3> {% endblock header %} {% block content %} <form action="{% url 'learning_logs:edit_entry' entry.id %}" method="post" class="form"> {% csrf_token %} {% bootstrap_form form %} {% buttons %} <button name="submit" class="btn btn-primary">save changesbutton> {% endbuttons %} form> {% endblock content %}部署学习笔记
由于在墙内是注册不了书本上要求的网站的,没办法还原书本的操作。我们需要按自己的方法部署。这部分需要话费的精力较多,还需要购买云服务器,需要一定的时间成本和金钱成本,具体可参考视频python3 django项目部署方案和Nginx + uWsgi 部署 Django + Mezzanine 生产服务器。等我以后有需求时会写一篇新博文来完善此处内容。
最后的话
至此,pyhon的基本知识学习完毕了,我们掌握了python的基本语法,能够自己下载和处理一些数据了,还能用Django搭建自己的网站,现在已经具备了开发各种项目所需的python基本技能。在学习的过程中,肯定会遇到自己不能解决的问题,这时候,查阅资料的能力尤为关键,其中给我最大帮助的是CSDN,遇到的大多数问题都能在其中找到答案,最后郑重提醒:每学完一项技术时,一定要写博客,写博客,写博客,很重要!这对知识的巩固有至关重要的作用,博客的搭建可以参考我的另一篇博文《个人建立hexo博客Matery主题的过程心得》。
祝贺你在学习Python的道路上走出了坚实的一步,愿你在以后的学习中好运相伴!