数组
数组和以往的认知有很大的不同。
- 数组是值类型,赋值和传参会复制整个数组,而不是指针。
- 数组长度必须是常量,且是类型的组成部分。[2]int和[3]int是不同类型。
- 支持 "=="、"!="操作符,因为内存总是被初始化过的。
- 指针数组[n]*T,数组指针 *[n]T
可用复合语句初始化。支持多维数组
a := [3]int{1, 2}// 未初始化元素值为 0。
b := [...]int{1, 2, 3, 4} // 通过初始化值确定数组⻓长度。
c := [5]int{2: 100, 4:200} // 使用用索引号初始化元素。
d := [...]struct {
name string
age
uint8
}{
{"user1", 10}, // 可省略元素类型。
{"user2", 20}, // 别忘了最后一一行行的逗号。
}
a := [2][3]int{{1, 2, 3}, {4, 5, 6}}
b := [...][2]int{{1, 1}, {2, 2}, {3, 3}}// 第 2 纬度不能用用 "..."。
值拷贝行为会造成性能问题,通常会建议使用 slice,或数组指针。
Slice
需要说明,Slice并不是数组或数组指针。它通过内部指针和相关属性引用数组片段,以实现变长方案。
runtime.h
struct Slice
{// must not move anything
byte* array; // actual data
uintgo len; // number of elements
uintgo cap; // allocated number of elements
};
- 引用类型。但自身是结构体,值拷贝传递。
- 属性len表示可用元素数量,读写操作不能超过该限制。
- 属性cap表示最大扩张容量,不能超出数组限制。
- 如果slice == nill,那么len、cap结果都为0。
data := [...]int{0, 1, 2, 3, 4, 5, 6}
slice := data[1:4:5] //[low : heigh : max]

可直接创建 slice 对象,自动分配底层数组。
s1 := []int{0, 1, 2, 3, 8: 100}// 通过初始化表达式构造,可使用用索引号。
fmt.Println(s1, len(s1), cap(s1))
s2 := make([]int, 6, 8)// 使用用 make 创建,指定 len 和 cap 值。
fmt.Println(s2, len(s2), cap(s2))
s3 := make([]int, 6)// 省略 cap,相当于 cap = len。
fmt.Println(s3, len(s3), cap(s3))
//输出:
[0 1 2 3 0 0 0 0 100] 9 9
[0 0 0 0 0 0] 6 8
[0 0 0 0 0 0] 6 6
使用 make 动态创建 slice,避免了数组必须用常量做长度的麻烦。还可用用指针直接访问底层数组,退化成普通数组操作。
append操作
向slice尾部添加数据,返回新的slice对象。
s := make([]int, 0, 5)
fmt.Printf("%p\n", &s)
s2 := append(s, 1)
fmt.Printf("%p\n", &s2)
fmt.Println(s, s2)
//输出:
0x210230000
0x210230040
[] [1]
copy
函数 copy 在两个 slice 间复制数据,复制长度以 len 小的为准。两个 slice 可指向同一底层数组,允许元素区间重叠。应及时将所需数据 copy 到较小的 slice,以便释放超大号底层数组内存。
Map
引用类型,哈希表。键必须是支持相等运算符 (==、!=) 类型,比如 number、string、pointer、array、struct,以及对应的 interface。值可以是任意类型,没有限制。
m := map[int]struct {
name string
age int
}{
1: {"user01",10}
2: {"user02",20}
}
println(m[1].name)
预先给 make 函数一个合理元素数量参数,有助于提升性能。因为事先申请一大块内存,可避免后续操作时频繁扩张。
m := make(map[string]int, 1024)
Map常用操作:
m := map[string]int{
"a": 1,
}
if v, ok := m["a"]; ok {// 判断 key 是否存在。
println(v)
}
println(m["c"]) // 对于不存在的 key,直接返回 \0,不会出错。
m["b"] = 2 // 新增或修改。
delete(m, "c") // 删除。如果 key 不存在,不会出错。
println(len(m)) // 获取键值对数量。cap 无无效。
for k, v := range m { // 迭代,可仅返回 key。随机顺序返回,每次都不相同。
println(k, v)
}
Struct
值类型,赋值和传参会复制全部内容。可用 "_" 定义补位字段,支持指向自身类型的指针成员。顺序初始化必须包含全部字段,否则会出错。支持匿名结构,可用作结构成员或定义变量。支持 "=="、"!=" 相等操作符,可用作 map 键类型。可定义字段标签,用反射读取。标签是类型的组成部分。
type File struct {
name string
size int
attr struct {
perm int
owner int
}
}
f := File{
name: "test.txt",
size: 1025,
// attr: {0755, 1},// Error: missing type in composite literal
}
f.attr.owner = 1
f.attr.perm = 0755
var attr = struct {
perm int
owner int
}{2, 0755}
f.attr = attr
空结构 "节省" 内存,比如用来实现 set 数据结构,或者实现没有 "状态" 只有方法的 "静态类"。
var null struct{}
set := make(map[string]struct{})
set["a"] = null
匿名字段
匿名字段不过是一种语法糖,从根本上说,就是一个与成员类型同名 (不含包名) 的字段。被匿名嵌入的可以是任何类型,当然也包括指针。
type User struct {
name string
}
type Manager struct {
User
title string
}
m := Manager {
User:User{"Tonny"}, //匿名字段的显式字段名,和类型名相同。
title:"Administrator",
}
可以像普通字段那样访问匿名字段成员,编译器从外向内逐级查找所有层次的匿名字段,直到发现目标或出错。外层同名字段会遮蔽嵌入字段成员,相同层次的同名字段也会让编译器无所适从。解决方法是使用显式字段名。不能同时嵌入一类型和其指针类型,因为它们名字相同。
面向对象
面向对象三大特征里,Go 仅支持封装,尽管匿名字段的内存布局和行为类似继承。没有class 关键字,没有继承、多态等等。
type User struct {
id
int
name string
}
type Manager struct {
User
title string
}
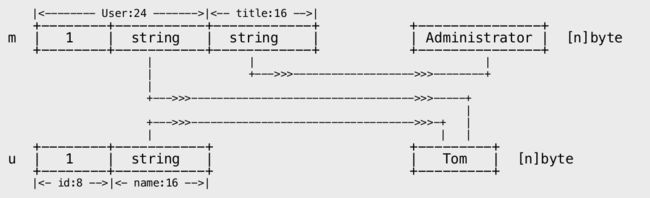
m := Manager{User{1, "Tom"}, "Administrator"}
// var u User = m // Error: cannot use m (type Manager) as type User in assignment
// 没有继承,自自然也不会有多态。
var u User = m.User// 同类型拷⻉贝。
内存布局和 C struct 相同,没有任何附加的 object 信息。