TensorFlow-Keras 14.共享层 or 模型
一.引言
函数式 API 的重要特性是能够多次重复使用一个层实例,如果对一个层实例调用两次,而不是每次调用都实例化一个新层,那么每次调用就可以重复使用相同的权重。这样可以构建具有共享分支的模型。
二.共享层权重
1.模型结构
假设模型判断两个句子的相似度,模型有两个输入,分别为句子A,句子B,并输出一个 0-1 的分数代表相似度。在这种前提下,句子AB是具备交换性的,即A与B的相似性应该与B与A的相似性是一致的,所以只需要用一个 LSTM 处理即可,其权重是根据两个输入共同学习的,模型也成为连体 LSTM 或者 共享 LSTM 模型。
2.模型构建
类似于之前初始化一个 Flatten 层一直用一样,这里初始化一个 LSTM 一直用,区别是后者会根据多个输入同时学习。
# 只实例化LSTM层一次
lstm = layers.LSTM(32)
left_input = Input(shape=(None, 128))
left_output = lstm(left_input)
right_input = Input(shape=(None, 128))
right_output = lstm(right_input)
merged = layers.concatenate([left_output, right_output], axis=-1)
prediction = layers.Dense(1, activation='sigmoid')(merged)
model = Model([left_input, right_input], prediction)两个输入层都接入了 LSTM :

3.模型训练
正常情况下语料是 None x 128 即不定长的句子,这里偷个懒都打成 128x128,训练目标是 0-1 的浮点数:
vocabulary_size = 10000
num_samples = 10000
max_length = 128
left_data = np.random.randint(1, vocabulary_size, size=(num_samples, max_length, max_length))
right_data = np.random.randint(1, vocabulary_size, size=(num_samples, max_length, max_length))
targets = np.random.rand(num_samples)
print(targets[0:100])
model.compile(optimizer='rmsprop',
loss='binary_crossentropy')
model.fit([left_data, right_data], targets, batch_size=128, epochs=10)Epoch 1/10
79/79 [==============================] - 4s 43ms/step - loss: 0.7331
......
Epoch 9/10
79/79 [==============================] - 3s 40ms/step - loss: 0.6935
Epoch 10/10
79/79 [==============================] - 3s 38ms/step - loss: 0.6927
三.共享模型权重
1.模型结构
除了共享层,理论上一个☝️ 模型也可以看做是一个抽象的大层,所以也可以通过输入张量给模型得到新张量,这和层的用法看起来差不多,共享层重复使用层的权重,共享模型(大层)重复使用很多的权重。 假设临近的两个摄像头一前一后采集图像,可以通过共享层将两个摄像头的图像进行提取,最后连接在一起进行后续操作。
2.模型构建
这里从 keras.application 加载了训练好的模型,include_top 选择 Flase 只留下卷积基,最后拼接出结果。
xception_base = applications.Xception(weights=None, include_top=False)
left_input = Input(shape=(250, 250, 3))
right_input = Input(shape=(250, 250, 3))
left_features = xception_base(left_input)
right_features = xception_base(right_input)
merged_features = layers.concatenate([left_features, right_features], axis=-1)
merged_features = Flatten()(merged_features)
output = layers.Dense(10, activation='softmax')(merged_features)
model = Model([left_input, right_input], output)
model.summary()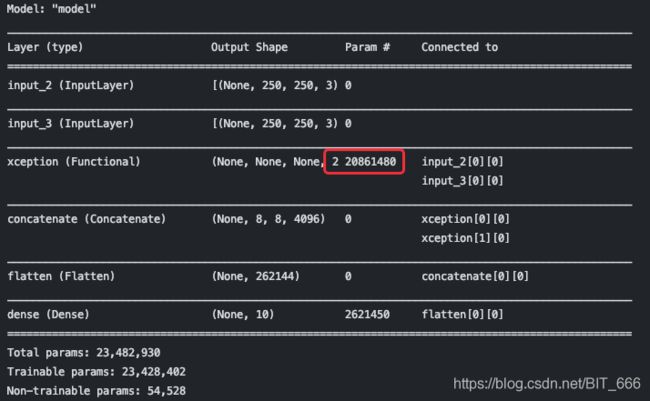
3.模型训练
这里 Xception 模型的参数太多了,本地实在跑步起来,这一步就忽略了。。。 总之我们可以多次调用相同的层或模型实例,在不同的处理分支之间重复使用层或者模型的权重,同时配合多输入或者多输出。