6.1

6.2
(a)不能需要的其它信息可以是闭频繁项集,算法可以参照6.1
(b)项集X是闭项集,如果不存在真超项集Y,使得Y与X具有相同的支持度计数;而如果项集X是生成元,如果不存在其真子集Y,使得Y与X具有相同的支持度计数。可见,闭项集考察的是真超项集,生成元考察的是真子集;闭频繁项集包含了关于频繁项集的完整信息,而频繁生成元集并不包含对应的频繁项集的完整支持度信息。
6.3
(a)设s是一个频繁项集,min_sup是(相对)最小支持度阈值,任务相关的数据D是数据库事务的集合,|D|是D中的事务数量,则support_count(s)>=min_sup*|D|;再设s’是s的非空子集,则任何包含项集s的事务将同样包含项集s’,即support_count(s’)≥support_count(s) ≥min_sup*|D|,所以s’也是一个频繁项集。
(b)设任务相关的数据D是数据库事务的集合,|D|是D的事务量,由定义得:
support(s)=support_count(s)/|D|
设s’是s的非空子集,由定义得:support(s’)=support_count(s’)/|D|
由(a)可知:support(s’)≥support(s)
由此证明,项集s的任意非空子集s’的至少和s的支持度一样大。
(c)设s是l的子集,则confidence(s=>(l-s))=support(l)/support(s)
设s’是s的非空子集,则confidence(s’=>(l-s’))=support(l)/support(s’)
由(b)可知:support_count(s’)≥support_count(s),此外,confidence((s’)=>(l-s’))≤confidence((s)=>(l-s))
所以,规则”s’=>(l-s’)”的置信度不可能大于”s=>(l-s)”
(d)证明:假设频繁项集F在事务数据库D中的任何一个分区中都是非频繁的。令C表示D中的所有事务量;令A表示D中包含频繁模式F的事务量,令min_sup表示最小支持度阈值,令d1,d2,..,dn表示D的n个不重叠的分区,ci表示分区di中的事务总数,ai表示分区di中包含F的事务数。所以,C=c1+c2+..+cn,A=a1+a2+..+an。因为F是一个频繁项集,所以A>=C*min_sup,即(a1+a2+..+an)>=(c1+c2+...+cn)*min_sup。又因为F在每个分区中都是不频繁的,所以对于任意i,ai=(c1+c2+...+cn)*min_sup)矛盾。所以得到:D中频繁的项集至少在D的一个分区中是频繁的。
6.4

6.5

图5.1给出了一种从频繁项集产生强关联规则的算法,它比6.2.2节介绍的方法更加高效是因为它只生成且测试必要的子集。如果一个长度为k的子集x不满足最低可信度,那么就没有意义的生成它的非空子集,因为这些子集的置信度将永远不会大于x的置信度(参照习题6.3(b)6.3(c))。然而,如果x满足最低可信度,那么我们就生成且测试他的(k-1)子集,使用这个标准,我们从n项集的(n-1)子集逐渐到1子集。从另一方面讲,6.2.2中的方法是一个强力的方法,生成频繁项集L的所有非空子集,然后测试他们是否存在潜在的关联规则。这是不高效的,因为会产生很多不必要的子集。如果我们考虑最糟的情况,有k-项集b,k是个很大的数。假设没有b的(k-1)子集满足最小置信度,6.2.2中的方法仍然会不必要的生成所有非空子集且测试。新方法则不同,他会只生成b的(k-1)子集,确定没有规则满足最小置信度,会避免生成和测试更多的子集,从而节省大量不必要的计算。
6.6
(a)Apriori
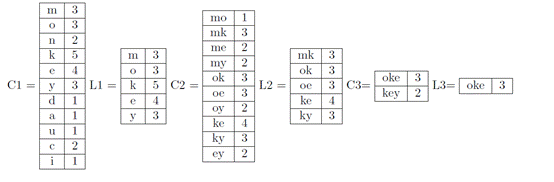
FP-growth:
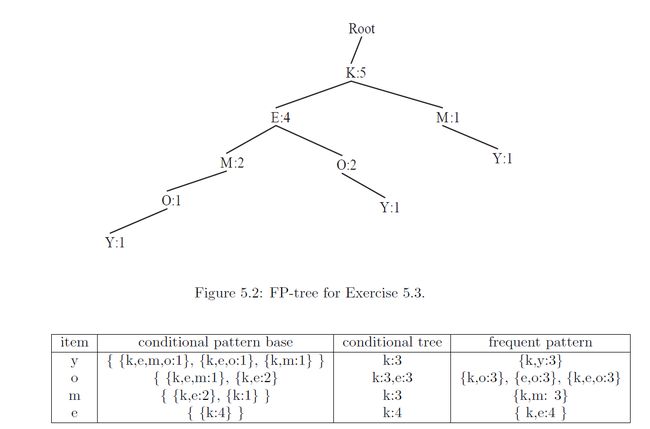
有效性比较:Apriori需要多次扫描数据库而FP增长建立FP树只需一次的扫描。在Apriori算法中产生候选是昂贵的(由于联接),而FP增长不产生任何候选。
(b)k,o→e[0.6,1]e,o→k[0.6,1]
6.8
(a)K=3,频繁3项集是{Bread,Milk,Cheese}。关联规则是:
K=3,频繁3-项集是{Bread,Milk,Cheese}
关联规则是:
Bread^Cheese=>Milk,[75%,100%]
Cheese^Milk=>Bread,[75%,100%]
Cheese=>Milk^Bread,[75%,100%]
(b)K=3,频繁3-项集是{(Wonder-Bread,Dairyland-Milk,Tasty-Pie),(Wonder-Bread,Sunset-Milk,Dairyland-Cheese)}
6.14
(a)根据规则,support=2000/5000=40%,confidence=2000/3000=66.7%
该规则是强规则。
(b)corr{hotdog,hamburger}=P({hotdog,hamburger})/(P{hotdog})P({hamburger})=0.4/(0.5*0.6)=1.33>1,所以,买hotdog不是独立于买hamburger。两者存在正相关关系。
(c)全置信度为:2/3
最大置信度为:0.8
Kulczynski为:11/15
余弦:(8/15)^(1/2)
提升度:4/3
相关度:833.33
比较:就此数据而言,全置信度,最大置信度,Kulczynski,余弦的值(均小于1)与提升度,相关度(均大于1)的值存在明显差异;四个新的度量显示两种产品存在正相关,与提升度和相关度的分析结果相同。