集成学习精讲之Stacking和Blending(附源代码)
Stacking/Blending这两种集成学习方法的特点,一句话概括,就是以预测结果作为新特征进行训练。
我们分为5篇文章介绍集成学习,分别是:
- 集成学习基础-偏差和方差 - 戳此阅读
- Bagging - 戳此阅读
- Boosting - 戳此阅读
- Stacking/Blending
- Voting/Averaging
本节课中,书中的人物小冰将一步一步的从老师咖哥身上学到Boosting的各种方法。
小冰开口问道:“集成学习,的确强大,从普通的决策树,到树的Bagging,到随机森林,到各种Boosting的手段,很长见识。然而这些大都是基于同一种机器学习算法的集成,而且基本都是在集成决策树。我的问题是,能不能集成不同类型的机器学习算法,比如随机森林啦、神经网络啦、逻辑回归啦,AdaBoost啦,然后优中选优,以进一步提升性能。”
咖哥点头微笑:“小冰,你的思路很对。集成学习,分为两大类。”
- 如果基模型都是通过一个基础算法生成的同类型的学习器,这叫同质集成。
- 有同质集成就有异质集成,就是把不同类型的算法集成在一起。那么为了集成后的结果有好的表现,异质集成中的基模型要有足够大的差异性。
下面就介绍一些不同类型的模型之间相互集成的方法。
Stacking
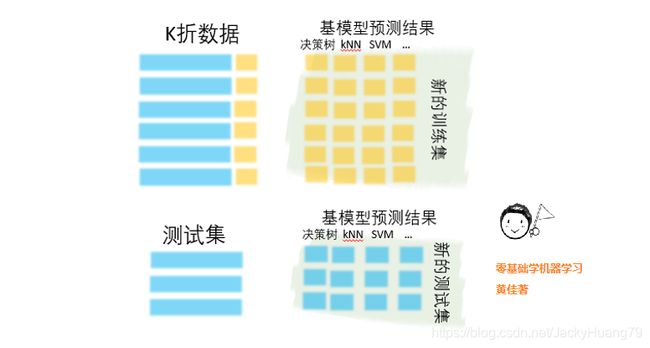
先说异质集成中的Stacking(可译为堆叠)。这种集成方法还是蛮诡异的,其思路是,使用初始训练数据集学习出若干个基模型之后,用这几个基模型的的预测结果作为新的训练集的特征,来训练出新的模型。Stacking集成的流程如下图所示。
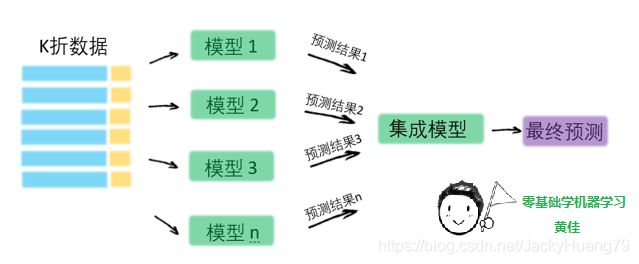
这些基模型在异质类型中进行选择,比如决策树、kNN、svm或神经网络等等,都可以组合在一起。
来看Stacking的具体步骤:
- 通常把训练集拆成k折(请大家回忆第一课中介绍过的k折验证);
- 利用k折验证的方法在k-1折上训练模型,在第k折上进行验证;
- 这样训练k次之后,把训练好了的模型对训练集整体进行最终训练,拿到一个基模型
- 使用基模型跑训练集,得到对训练集的预测结果;
- 使用基模型跑测试集,得到对测试集的预测结果;
- 重复步骤2-5,生成全部基模型和预测结果(比如CART、kNN 、SVM,或神经网络,4组预测结果);
- 好了,现在你可以忘记训练集和测试集这两个数据集样本了。你只拿训练集预测结果作为新训练集的特征,测试集预测结果作为新测试集的特征去训练新模型。新模型的类型不必与基模型有关联。
这方法是不是有点奇葩?
下面给大家一个Stacking的简单用例。
首先定义一个函数用来实现Stacking:
def Stacking(model,train,y,test,n_fold):
folds=StratifiedKFold(n_splits=n_fold,random_state=1)
test_pred=np.empty((test.shape[0],1),float)
train_pred=np.empty((0,1),float)
for train_indices,val_indices in folds.split(train,y.values):
X_train,x_val=train.iloc[train_indices],train.iloc[val_indices]
y_train,y_val=y.iloc[train_indices],y.iloc[val_indices]
model.fit(X=X_train,y=y_train)
train_pred=np.append(train_pred,model.predict(x_val))
test_pred=np.append(test_pred,model.predict(test))
return test_pred.reshape(-1,1),train_pred
然后用刚才定义的Stacking函数训练两个不同类型的模型,一个是决策树分类器模型,一个是kNN分类器模型,并用这两个模型分别生成预测结果:
model1 = tree.DecisionTreeClassifier(random_state=1)
test_pred1 ,train_pred1=Stacking(model=model1,n_fold=10,
train=X_train,test=X_test,y=y_train)
train_pred1=pd.DataFrame(train_pred1)
test_pred1=pd.DataFrame(test_pred1)
model2 = KNeighborsClassifier()
test_pred2 ,train_pred2=Stacking(model=model2,n_fold=10,
train=X_train,test=X_test,y=y_train)
train_pred2=pd.DataFrame(train_pred2)
test_pred2=pd.DataFrame(test_pred2)
把上面的预测结果连接成一个新的特征集,标签则保持不变,用回原始的标签集。最后使用逻辑回归算法对新的特征集进行分类预测。
df = pd.concat([train_pred1, train_pred2], axis=1)
df_test = pd.concat([test_pred1, test_pred2], axis=1)
model = LogisticRegression(random_state=1)
model.fit(df,y_train)
model.score(df_test, y_test)
Blending
再来说说Blending(可译为混合),它的思路和Stacking几乎是完全一样的,唯一的不同之处在哪里呢?就是Blending的过程中不进行k折验证,而是只将原始样本训练集分为训练集和验证集,然后只针对验证集进行预测,生成的新训练集就只是对于验证集的预测结果,而不是对全部训练集生成的预测结果。Blending集成的流程如下图所示。

上述这两种集成方案在机器学习实战中,虽然不是经常见到,但是也有可能会产生意想不到的好效果。

本文经作者授权,节选自机器学习小白入门书《零基础学机器学习》,这本书专门为希望轻松快乐学习机器学习和深度学习技术的您而量身定做。喜欢的读者可以直接去京东购买呦!:)作者谢谢您的支持与赞赏!
https://item.jd.com/12763913.html
http://product.dangdang.com/29159728.html
上一篇: 集成学习精讲之Boosting方法