DeepHuman:从单一图像中3D人体重建
摘要:我们提出DeepHuman,一种图像引导的体到体转换CNN,用于从单一的RGB图像进行3D人体重建。为了减少与表面几何重建相关的模糊性,甚至对于不可见区域的重建,我们提出并利用从SMPL模型生成的密集语义表示作为额外的输入。我们的网络的一个关键特征是通过体积特征变换将不同尺度的图像特征融合到三维空间中,这有助于恢复精确的表面几何。可见表面细节通过常规精细网络进一步细化,该网络可以使用我们提出的体积法向投影层与体积生成网络连接。我们还提供了一个包含约7000个模型的三维真实人类模型数据集——THuman。使用数据集生成的训练数据对网络进行训练。总的来说,由于我们网络的具体设计和我们数据集的多样性,我们的方法能够在仅给出一张图像的情况下进行3D人体模型估计,并优于最先进的方法。
1 引言
基于图像的人体重建是VR/AR内容创建[7]、图像视频编辑和re-enactment[19,43]、holoportation[40]和虚拟着装[42]的重要研究课题。为了进行全身三维重建,目前可用的方法需要融合目标的多视图图像[8,25,20]或多个时间图像[3,2,1]。从单一的RGB图像中恢复人体模型仍然是一项挑战性的任务,迄今为止还没有引起多少关注。仅使用单一图像,现有的人类解析研究涵盖了从2D姿态检测[41,6,39],到3D姿态检测[33,44,64],最后使用人体统计模板(如assmpl[32])扩展到人体形状捕获[27]的热门话题。然而,该统计模板只能捕捉到最低限度穿着衣服的身体的形状和姿势,无法表现出普通衣服层下的3D人体模型。尽管最近的研究,如BodyNet,它是这一目标的先驱研究,它只产生几乎脱光的身体重建结果,偶尔会有破碎的身体部分。我们相信,在正常着装下,从单一图像进行三维人体重建,这一需要进一步研究的课题将很快成为下一个热门研究课题。
从技术上讲,人类从单一的RGB图像重建是极具挑战性的,不仅因为需要预测不可见部分的形状,也由于需要对可见表面的几何恢复。因此,一种能够完成这一任务的方法需要满足两个要求:一是要约束输出空间的自由度,避免不可见区域内不合理的工件(如破碎的身体部位);其次,该方法应该能够有效地从输入图像中提取出服装款式、褶皱等几何信息,并将其融合到三维空间中。
在本文中,我们提出了DeepHuman,一个基于深度学习的框架,旨在解决这些挑战。具体地说,为网络提供一个合理的初始化和约束的自由度输出空间,我们建议利用参数化人体模型通过生成3 d语义容量和相应的2 d语义地图后密度表示估计参数的身体的形状和姿态参数模板(例如,SMPL[32])的输入图像。注意,推断映像对应的SMPL模型的要求并不严格;相反,有几种精确的方法可以用于单个图像的SMPL预测。输入图像和语义体&地图被输入到一个图像引导的体对体转换CNN进行表面重建。为了尽可能准确地恢复发型或衣服轮廓等表面几何,我们提出了一种多尺度的体积特征变换,以便将这些不同尺度的图像引导信息融合到三维体积中。最后,根据输入图像引入体积法向投影层,进一步细化和丰富可见表面细节。这一层被设计来连接体积生成网络和正常的细化网络,并支持端到端的训练。综上所述,我们将该任务分为三个子任务:a)从输入图像进行参数化身体估计;b)从图像和估计的身体进行表面重建;c)根据图像对可见表面细节进行细化。
可用的用于BodyNet[52]网络训练的3D人体数据集[53]本质上是一组合成的基于SMPL模型[32]纹理的图像。没有任何在普通服装下具有表面几何形状的大规模人体3D数据集是公开可用的。为了填补这个空白,我们提供了THuman数据集。我们利用最先进的DoubleFusion[63]技术进行实时人体网格重建,并提出了一种捕捉管道,用于快速有效地捕捉穿着具有中等表面细节和纹理的休闲服装的人体外部几何形状。基于这个管道,我们对人类数据集进行了捕获和重建,该数据集包含约7000个人体网格,约230种服装,在随机采样的姿势下。
我们的网络从人类数据集合成的训练语料库中学习。该网络利用数据集的数据多样性,对自然图像具有很好的泛化能力,仅对单一图像进行重建就能获得满意的结果。与目前最先进的方法相比,我们证明了改进的效率和质量。通过对单目视频的扩展应用,我们也证明了该方法的能力和鲁棒性。
2. 相关工作
多视图图像中的人体模型 以往的研究主要集中在使用多视图图像重建人体模型[26,47,30]。轮廓、立体声和阴影等形状线索已被整合在一起,以提高重建性能[47,30,58,57,55]。采用双目[12]或多视点立体匹配[13]算法,在数十台甚至数百台摄像机上演示了最先进的实时[11,10]和极高质量的[8]重建结果。为了捕捉多个交互角色的详细运动,超过600个摄像机已被用来克服遮挡挑战[24,25]。然而,所有这些系统都需要复杂的环境设置,包括相机校准、同步和照明控制。
为了降低系统设置的难度,最近通过使用cnn学习轮廓线索[15]和立体线索[20],研究了从极其稀疏的摄像机视图重建人体模型。这些系统需要大约4个相机视图来进行粗略的表面细节捕捉。还需要注意的是,尽管使用轻重量相机设置的时间变形系统[54,9,14]已经开发用于使用骨骼跟踪[54,31]或人体网格模板变形[9]的动态人体模型重建,这些系统假定预先扫描的特定对象的人体模板作为变形的关键模型。
人类模型从时间图像 为了探索低成本和方便的人体模型捕捉,许多研究试图通过聚合多个时间帧的信息,仅使用单一RGB或RGBD相机来捕捉人体。对于RGBD图像,DynamicFusion[38]打破静态场景假设,在标准静态模型上变形TSDF融合的非刚性目标。BodyFusion[62]试图通过添加关节先验来提高鲁棒性。DoubleFusion[63]在融合管道之前引入了人体形状,并实现了最先进的实时效率、鲁棒性和闭环性能,即使在快速运动的情况下,也能有效地重建人体模型。也有离线的方法对多个RGBD图像进行全局配准,以获得完整的身体模型[29]。为了使用单视图RGB相机重建人体,已经提出了在目标尽可能保持静态时旋转摄像机的方法[65],或在目标旋转时保持摄像机静态[3,2,1]。最近,人们提出了只使用一个RGB相机就能重建动态人体模型的人体性能捕捉方法[59,18];然而,类似于多摄像机场景[54,9,14],这种方法需要一个预扫描的人体模型作为输入。
人工解析单个图像 从单一的图像中解析人类是最近计算机视觉领域的一个热门话题。研究分为稀疏2D解析(2D骨架估计)[6,39]、稀疏3D解析(3D骨架估计)[33,44,64,48,50,35,61]、密集2D解析[17]和密集3D解析(形状和姿态估计)。由于人类统计模型如SCAPE[4]和SMPL[32]的出现,从单个图像进行密集的3D解析最近引起了极大的兴趣。例如,通过将SCAPE或SMPL模型拟合到检测到的2D骨架和图像的其他形状线索[5,28],或使用cnn对SMPL模型进行回归[27,49,51],可以从单个图像中自动获得形状和姿态参数。
关于单视角人体模型重建,近期的研究只有几篇。在第一项研究中,用于网络训练的3D人类数据集缺乏几何细节,在输出中导致类似SMPL的体素几何。第二项研究显示了输出高质量细节的能力,但他们的训练集受到了高度限制,导致难以泛化,例如,对不同的人体姿态。Natsume等人同时进行的工作[36]预测了多视图的二维轮廓来重建三维模型,但是他们的重建结果只有有限的位姿变化。
3D人体数据集 现有的三维人体数据集大多用于三维姿态和骨骼检测。HumanEva[46]和Human3.6M[21]都包含了多视图的人类视频序列,并带有基于标记的动作捕捉系统获得的地面真实3D骨骼注释。由于需要穿戴标记或特殊的服装,两个数据集的服装差异有限。MPI-INF-3DHP[34]数据集通过使用多视图无标记动作捕捉系统丰富了布料外观。然而,所有这些数据集都缺乏每个时间框架的三维模型。为了满足单幅图像姿态和形状重建的要求,通过在不同服装纹理下绘制不同形状和姿态参数的SMPL模型,建立了合成的超现实[53]数据集。“Unite the People”数据集[28]提供了带有3D SMPL模型的半自动标注的真实世界的人类图像。这两个数据集,与我们的数据集相比,不包含表面几何细节。
3. 概述
给出一个穿着休闲服的人的图像,用I表示,我们的方法旨在用合理的几何细节重建他/她的全身三维表面。由于深度模糊、身体自遮挡和输出空间的高度自由度,直接从图像中恢复主体的表面模型非常具有挑战性。因此,我们以一种由粗到细的方式进行三维人体重建。我们的方法从参数体估计开始,然后进行全身表面重建,最后细化表面可见区域的细节。
我们利用最先进的方法HMR[27]和SMPLify[5]来估计I的SMPL模型;更多细节请参见补充文档。为了将SMPL估计输入CNN,我们根据其静止姿态的空间坐标为SMPL上的每个顶点预先定义语义码(一个三维向量)。根据SMPL估计,我们先将SMPL模型体素化到体素网格中,然后将语义码传播到被占用的体素中,将语义码渲染到图像平面获得语义映射,并生成语义体。我们的密集语义表示有三个优点:(1)它对身体的形状和姿态信息进行了编码,从而为网络提供了合理的初始化,并约束了输出空间的自由度;(2)提供三维体素与二维图像像素对应关系的线索;(3)易于融入神经网络。更多细节见补充文件。
对于表面几何重建,我们采用占用体积来表示表面[52]。具体来说,我们定义了一个3D占用体素网格Vo,其中表面内的体素值设置为1,其他的体素值设置为0。所有占用体积的固定分辨率为128×192×128,其中y轴的分辨率设置较大,可以自动适应所观察人体的长轴。为了在I和Ms的帮助下从vs中重建vov,我们提出了一种图像引导的体-体转换网络(Sec.4.1),其中我们使用多尺度体积特征变换(Sec.4.1.1)将二维图像引导信息融合到三维体中。因此,该网络将利用来自二维图像和三维体积的信息。
由于分辨率的限制,体素网格总是无法捕捉细微的细节,比如衣服的褶皱。为了进一步丰富和细化表面可见部分的几何细节,我们建议直接从Vo(Sec.4.1.2)投射2D法线图N,并使用U-net (Sec.4.1)进行细化。换句话说,我们使用二维法线贴图来编码可见表面的几何细节,从而降低了内存需求。
为了在监督下训练网络,我们提供了一个真实世界的3D人体模型数据集THuman(第5节)。我们从数据集合成训练语料库。一旦网络被训练,它可以预测一个人的图像和相应的SMPL估计的占用量和可见表面的法线贴图。首先利用移动立方体算法从占用体中提取出一个三角形多边形网格,然后利用[37]中的方法根据法线贴图进行细化,得到最终的重建结果。
4. 方法
4.1 网络体系结构
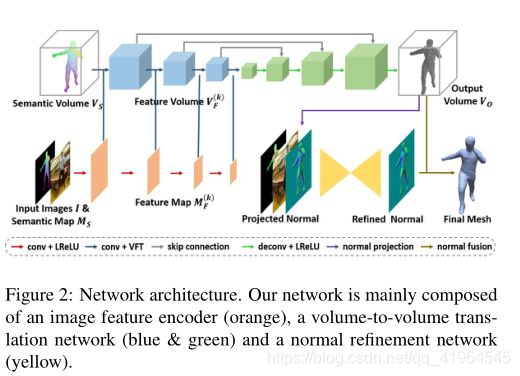
我们的网络由3个组件组成,分别是图像编码器G、volume-to-volume (vol2vol)转换网络H和普通细化网络R,如图2所示。图像编码器G的目标是提取多尺度二维特征图Mf(k) (k = 1,…, K)由I和Ms组合而成。vol2vol网络是一个体积型U-Net[60],其中Vs 和 Mf(k) (k = 1,…, K)作为输入,输出占用体积Vo,表示曲面。我们的vol2vol网络H融合了多尺度语义特征Mf(k) (k = 1,…, K)通过多尺度体积特征转换器进入其编码器。在生成Vo后,一个normal refinement U-Net[45] R进一步精化 normal map N,通过一个volume-to - normal投影层直接计算它。网络中的所有操作都是可微分的,因此,可以以端到端的方式对其进行训练或微调。实施细节载于补充文件。
4.1.1 多尺度体积特征转换器
在这项工作中,我们扩展了空间特征变换层[56]来处理多尺度特征金字塔中的2D-3D数据对,并提出了多尺度V体积特征变换(VFT)。在[56]中首次使用SFT实现基于语义分类先验的图像超分辨率,以避免回归均值问题。SFT层根据输入先验学习输出调制参数对(α,β)。然后对特征图F进行变换:SFT (F) =α⊙F +β,其中⊙为Hadamard乘积。
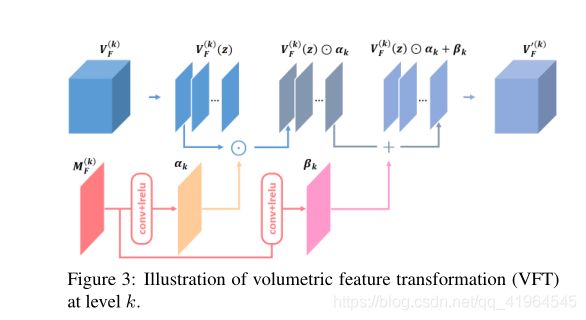
在我们的网络中,在每个级别k上,由之前的编码层提供一个特征体Vf(k) (图2中的蓝色立方体)和一个特征图Mf(k) (图2中的橙色正方形)。与[56]类似,我们首先通过卷积+激活层将特征映射Mf(k) 映射到调制参数(αk,βk)(见图3第二行)。注意,SFT(·)中的操作不能直接应用于Vf(k) 和Mf(k) ,因为尺寸不一致(Vf(k) 有z轴,而(αk,βk)没有)。因此,我们沿着z轴将feature volume切成一系列的feature slice,每个feature slice在z轴上的厚度都是1。然后我们对每个特征z切片分别应用相同的元素仿射变换。

其中Vf(k)(zi)是平面z = zi, zi= 1,2,…Z和Z是Z轴的最大坐标。VFT层的输出是变换后的特征切片的重新组合。图3为VFT的图示。
VFT的优势有三方面。首先,与将特征体积/地图转换为潜在代码并在网络瓶颈处进行连接相比,该方法保留了图像/体积特征的形状原始性,从而编码了更多的本地信息。其次,它是高效的。使用VFT,feature refusionin可以实现单个pasofaffine转换,而不需要额外的卷积或完全连接。第三,它具有灵活性。VFT可以在原始图像/体积上执行,也可以在下采样的特征地图/体积上执行,这使得融合不同尺度的特征成为可能,并使更深入的特征转移成为可能。
为了最大限度地整合图像特征,我们对多尺度feature金字塔进行了体积特征变换;参考图2中的蓝箭头/线。我们只在vol2vol网络的编码器部分执行VFT;然而,转换信息可以通过跳过连接传播到解码器。如第6.3节所述,与在网络瓶颈处直接连接潜在变量相比,多尺度特征转换有助于恢复更精确的表面几何。
4.1.2 体积到法线的映射层
我们的目标是获得人体模型可见表面的几何细节(如皱纹和布料边界)。然而,由于分辨率的限制,基于体积的表示方式无法捕捉到这种细粒度的细节。因此,我们将可见的几何细节编码在二维法线贴图上,这可以通过使用我们的可微的体积到法线投影层直接从占用体积计算出来。该层首先直接从占用空间投影深度映射,将深度映射转换为顶点映射,然后通过一系列数学运算计算法线映射。
