Python爬虫爬取中国电影票房排行榜
Python爬虫
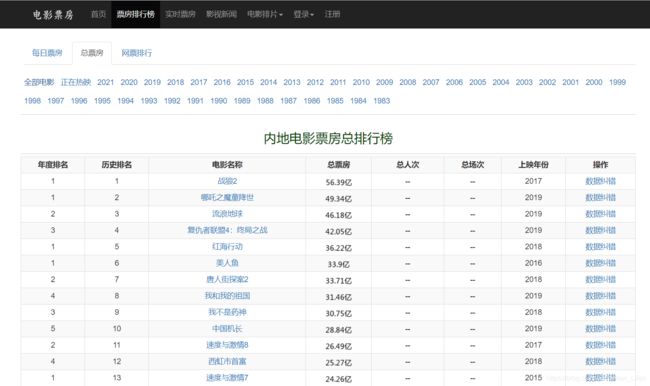
内地电影票房总排行榜
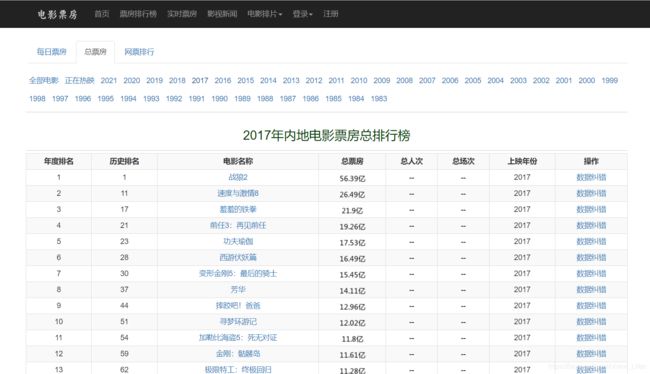
2017年内地电影票房总排行榜
这个网站对爬虫设置了重重阻碍
1、查看多页数据需要用户登录

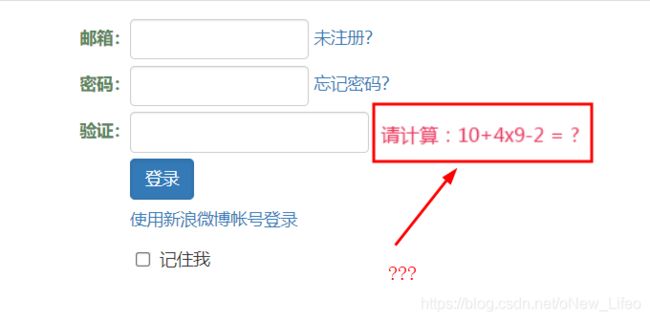
2、奇怪的登录验证码

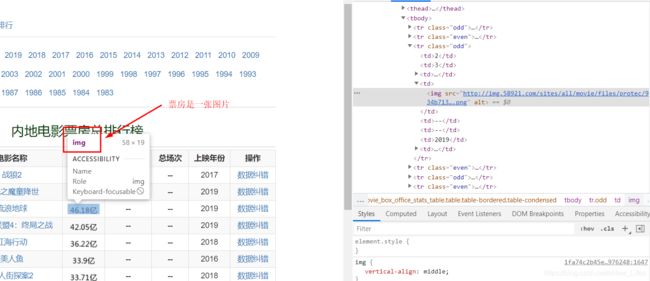
3、电影票房是一张图片
步骤
在开始爬虫前我们一步一步的解决阻碍
1、权限问题
在未登录时获取多页数据会让我们先登录,当我们在浏览器登录过后,使用python读取到的网页数据还是登录页的代码
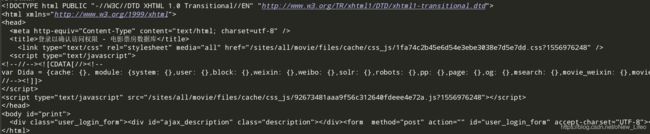
我们都知道浏览器向服务器发送请求时都会带上请求头,我们用python直接爬取网页源码时并没有设置请求头,所以服务器并不认识我们,认为我们没有登录。所以只要我们正确的设置了请求头就能正常获取数据了
获取请求头中的cookie(需要先登录)
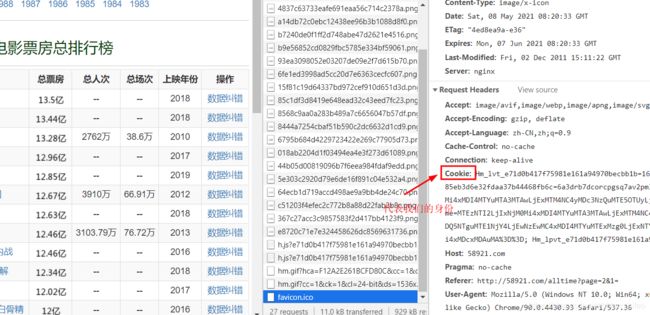
设置cookie后便能正确的获取网页数据
spider.py
# -*- coding: utf-8 -*-
# @File : spider.py
import requests
from bs4 import BeautifulSoup
import xlwt
'''
http://58921.com/alltime/2018
年份票房排行榜
1995 - 2021
'''
base_url = "http://58921.com"
year_url = "http://58921.com/alltime/"
all_url = "http://58921.com/alltime?page="
headers = {
# Cookie 登录验证
"Cookie":"这里是登录后获取到的cookie",
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/69.0.3947.100 Safari/537.36",
"Upgrade-Insecure-Requests":"1",
}
def get_html(url,encoding):
response = requests.get(url,headers=headers)
if response.status_code == 200:
# 判断请求是否成功
response.encoding = encoding
return response.text
else:
return None
def spider_year_list(url):
'''
根据url爬取排行榜 'http://58921.com/alltime/2019?page=1' 第二页
每一个年份的数据
:return:
'''
year = url.split("/alltime/")[1]
year_list = []
# 获取页数
html = get_html(url,encoding="utf-8")
soup = BeautifulSoup(html, "html.parser")
item_list = soup.find("div",class_="item-list")
if item_list is not None:
pager_number = item_list.find("li", class_="pager_count").find("span",class_="pager_number").get_text()
page = int(pager_number.split("/")[1])
else:
page = 1
for i in range(0,page):
page_url = '{}?page={}'.format(url,i)
print(page_url)
html = get_html(page_url,encoding="utf-8")
soup = BeautifulSoup(html, "html.parser")
center_table = soup.find("div",class_="table-responsive")
if center_table is not None:
trs = center_table.table.tbody.find_all("tr")
for tr in trs:
mv_info = []
tds = tr.find_all("td")
for index,td in enumerate(tds):
# print(td)
if index == 3: # 票房的图片链接
mv_info.append(td.img['src'])
else:
mv_info.append(td.get_text())
year_list.append(mv_info)
else:
print("无该页数据")
print(year_list)
save_to_excel("./{}年票房排行榜.xls".format(year),year_list)
def spider_all_list(url):
'''
根据url爬取总票房排行榜 'http://58921.com/alltime?page=1' 第二页
:return:
'''
datalist = []
for i in range(0,206):
page_url = url+str(i)
print(page_url)
html = get_html(page_url,encoding="utf-8")
soup = BeautifulSoup(html, "html.parser")
center_table = soup.find("div",class_="table-responsive")
if center_table is not None:
trs = center_table.table.tbody.find_all("tr")
for tr in trs:
mv_info = []
tds = tr.find_all("td")
for index,td in enumerate(tds):
# print(td)
if index == 3: # 票房的图片链接
mv_info.append(td.img['src'])
else:
mv_info.append(td.get_text())
datalist.append(mv_info)
else:
print("无该页数据")
print(datalist)
save_to_excel("./中国电影票房排行榜.xls",datalist)
def save_to_excel(savepath,datalist):
book = xlwt.Workbook(encoding="utf-8", style_compression=0) # 创建workbook对象
sheet = book.add_sheet('票房排行榜', cell_overwrite_ok=True) # 创建工作表
col = ("年度排名", "历史排名", "电影名称", "总票房", "总人次", "总场次","上映年份","操作")
for i in range(0,8):
sheet.write(0, i, col[i]) # 列名
for i in range(0, len(datalist)):
print("第{}条".format(i + 1))
data = datalist[i]
if len(data) >= 8:# 数据完整才保存
for j in range(0, 8):
sheet.write(i + 1, j, data[j])
book.save(savepath) # 保存
def url_list():
'''
拼接url
:return:
'''
return [year_url+str(i) for i in range(1995,2021)]
def main():
for url in url_list():
spider_year_list(url)
spider_all_list(all_url)
if __name__ == '__main__':
main()
爬取到的数据
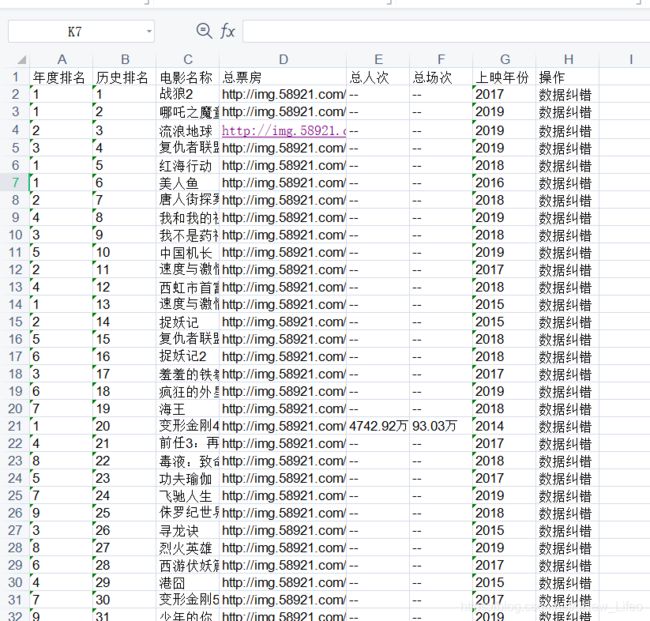
票房是一张图片链接
2、处理票房图片
使用百度图像识别api来读取图片数据
参考链接:https://blog.csdn.net/cool_bot/article/details/90150512
代码
img2num.py
调用百度api识别图片数据
# -*- coding: utf-8 -*-
# @File : img2num.py
from aip import AipOcr
import urllib.request
'''
使用百度api读取图片中的文字
'''
""" 你的 APPID AK SK """
APP_ID = 'APPID '
API_KEY = 'AK'
SECRET_KEY = 'SK'
client = AipOcr(APP_ID, API_KEY, SECRET_KEY)
options = {
} # 配置字典
options["language_type"] = "CHN_ENG" # 识别文字类型
options["detect_direction"] = "true" # 是否检测图片的朝向
options["detect_language"] = "true" # 是否检测语言
options["probability"] = "true" # 是否返回置信度
def get_file_content(filePath): # 本地图片
with open(filePath, 'rb') as fp:
return fp.read() # 获取图片信息
def get_img_word(url):
res = urllib.request.urlopen(url)
result = client.basicGeneral(res.read(), options)
if "words_result" not in result.keys(): # 当识别失败时返回图片地址
print(result)
print("无结果")
return url
word = ""
for i in result["words_result"]:
word = i['words']
print(word)
return word
def main():
# 测试
get_img_word("http://img.58921.com/sites/all/movie/files/protec/b7240de0f1ff2d748abe47d2621e4516.png")
if __name__ == '__main__':
main()
处理票房图片.py
通过pandas读取上面爬取到的excel文件,然后调用img2num.py文件里 的get_img_word方法转换图片
# -*- coding: utf-8 -*-
# @File : 处理票房图片.py
import img2num
import pandas as pd
import xlwt
'''
处理图片
'''
data_df = pd.read_excel("./中国电影票房排行榜.xls").head(100)
data_df['总票房'] = data_df['总票房'].apply(lambda x: img2num.get_img_word(x))
def save_data():
'''
将处理后的数据保存到Excel
:return:
'''
datalist = []
for row in data_df.iterrows():
series = list(row)[1] # Series
datalist.append(list(series))
save_to_excel("./转换后的票房数据.xls", datalist)
def save_to_excel(savepath,datalist):
book = xlwt.Workbook(encoding="utf-8", style_compression=0) # 创建workbook对象
sheet = book.add_sheet('票房排行榜', cell_overwrite_ok=True) # 创建工作表
col = ("年度排名", "历史排名", "电影名称", "总票房", "总人次", "总场次","上映年份","操作")
for i in range(0,8):
sheet.write(0, i, col[i]) # 列名
for i in range(0, len(datalist)):
print("第{}条".format(i + 1))
data = datalist[i]
if len(data) >= 8:# 数据完整才保存
for j in range(0, 8):
sheet.write(i + 1, j, data[j])
book.save(savepath) # 保存
def main():
save_data()
# print(data_df['总票房'])
if __name__ == '__main__':
main()
转换过程

转换过程中有一些错误
{‘error_code’: 18, ‘error_msg’: ‘Open api qps request limit reached’}
查看官方文档错误码
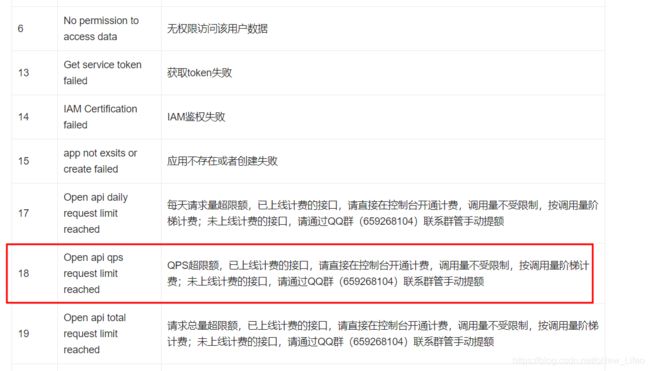
如果想要批量转换的话看来要收费
这里只作一点教程,具体需要批量转换的话可以去开通计费
转换后的数据

有的数据还是没有识别出来,如果想全部识别出来的话可以调整为高精度识别