第十二章:使用C语言(Python语言)操作Sqlserver2019数据库
目录
- 一、连接数据库的准备工作
- 二、使用 ODBC 连接数据库
-
- 1. ODBC 数据源简介
- 2. 配置 ODBC 数据库源
- 3. 连接数据库函数
- 4. C 语言通过 ODBC 操作数据库
- 三、非 ODBC 方式操作数据库
-
- 3.1 删除、修改、插入数据
- 3.2 查询数据
- 四、拓展:Python 操作 SQLServer
-
- 4.1 pymssql 模块
- 4.2 ORM 框架
-
- 4.2.1 连接数据库
- 4.2.2 创建数据表
- 4.2.3 添加数据
- 4.2.4 更新数据
- 4.2.5 查询数据
学前必备知识
- 第一章:SQL Server 数据库环境搭建与使用
- 第二章:SQL Server2019 数据库的基本使用之图形化界面操作
- 第三章:SQL Server2019 数据库 之 开启 SQL 语言之旅
- 第四章:SQL Server2019 数据库 之 综合案例练习、 使用SQL语句插入数据、更新和删除数据
- 第五章:SQL Server2019 数据库 之 综合案例练习、开启 SELECT 语句之旅
- 第六章:SQL Server2019 数据库 之 SELECT 语句的深入使用
- 第七章:SQL Server2019 数据库 之 单表查询综合练习 及SELECT 语句的进阶使用
- 第八章:SQL Server2019 数据库 之分组统计(GROUP BY)
- 第九章:SQL Server2019 数据库 之简单子查询
- 第十章:SQL Server2019 数据库 之多行子查询
- 第十一章:SQL Server2019 数据库 之多表连接
每日一句:一个人要有很强烈的成功愿望,除了奋斗之外,得不停息地去思考,忍受内心的炼狱和折磨,能够从灰烬中站起来,反败为胜。In order to have a strong desire to succeed,in addition to struggle,a person has to think continuously,endure inner purgatory and torture,and be able to rise from the ashes and turn defeat into victory。——张朝阳(搜狐公司首席执行官)
本章学习目标:
- 了解 SQL Server 的配置。
- 掌握使用 ODBC 连接数据库的方法。
- 掌握使用非 ODBC 连接数据库的方法。
- 拓展学习 Python 操作 SqlServer 数据库。
一、连接数据库的准备工作
1. 概述
C 语言连接 SQL Server 数据库的方法有两种,分别为非数据源方式和 ODBC 数据源方式。
2. 配置 SQL Server 环境
(1) 开启 SQLServer 服务。
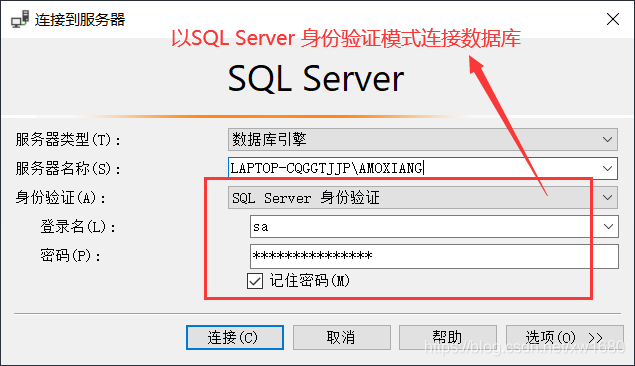
(2) 通过 SQL Server 身份验证模式连接数据库,即使用用户 sa 身份登录数据库,如下图所示:
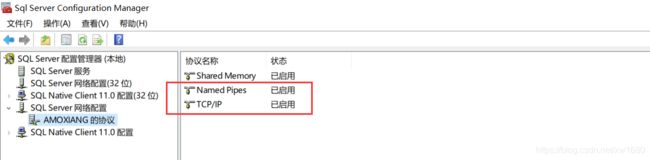
(3) 启用 SQL Server 协议,启用的方法是找到 SQL Server 配置管理器,将 SQL Server 网络配置的两个协议中的 Named Pipes 协议和 TCP/IP 协议全部启动,如下图所示:
3. 配置 C 语言环境
使用 Visual Studio 2019 创建一个空项目,步骤如下:
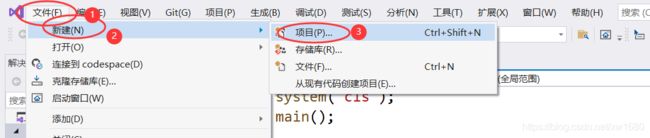
(1) 在编写程序之前,首先要创建一个新程序文件,具体方法是:在 Visual Studio 2019 欢迎界面选择 文件 菜单中的 新建 中的 项目 选项,或者按快捷键
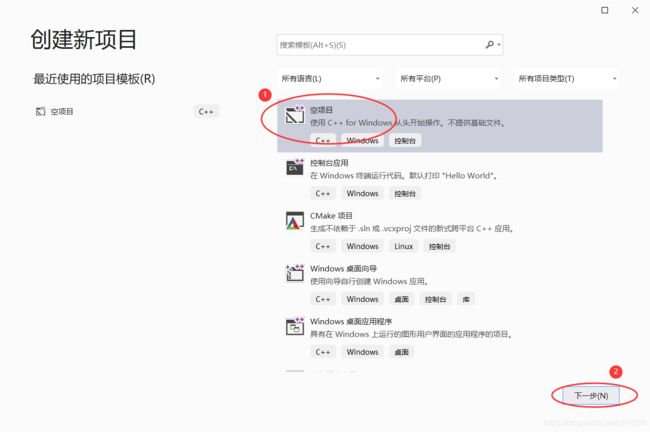
(2) 在 新建项目 界面中选择要创建的项目类型。选择创建项目的示意图如下所示:
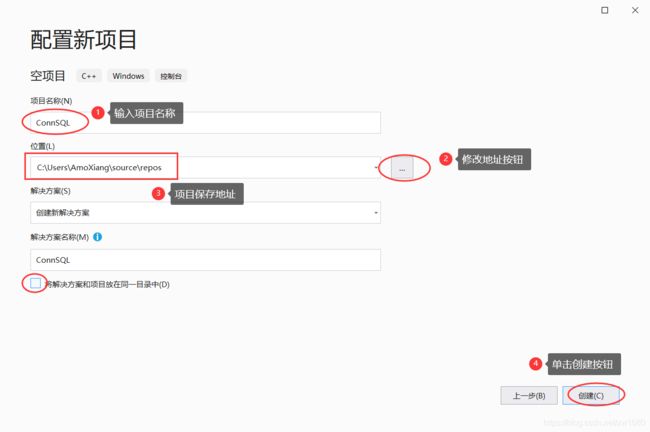
二、使用 ODBC 连接数据库
使用 ODBC 连接数据库,简单来说,就是通过一个媒介来连接数据库和程序代码。通过本节的学习,了解如何来创建 ODBC 数据源和使用 ODBC 数据源。
1. ODBC 数据源简介
ODBC 全称为 (Open DataBase Connectivity,开放数据库互连) 是 Microsoft 公司提供的有关数据库的一个组成部分,它建立一组规范并提供了数据库访问的标准 API(应用程序编程接口)。一个使用 ODBC 操作数据库的应用程序,基本操作都是由 ODBC 驱动程序完成的,不依赖于 DBMS(Database Management System,数据库管理系统)。
应用程序访问数据库时,首先要用 ODBC 管理器注册一个数据源,该数据源包括数据库位置、数据库类型和 ODBC 驱动程序等信息,管理器根据这些信息建立 ODBC 与数据库的连接。通过 ODBC 可以连接 MSSQLServer、MYSQL、DB2、Oracle、Access 等各种数据库,通过统一的函数进行访问(也就是访问各种数据库都可以使用统一的函数),改善了连接不同数据库的差异性。
2. 配置 ODBC 数据库源
配置 ODBC 数据源的步骤如下:
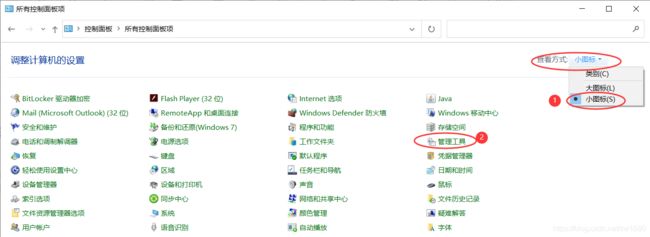
- 在 Windows 操作系统中,选择 “开始” → “控制面板” 选项,在 “查看方式” 处选择 “小图标(S)” 选项,然后单击 “管理工具” 选项,打开 “管理工具” 文件夹,如下图所示:
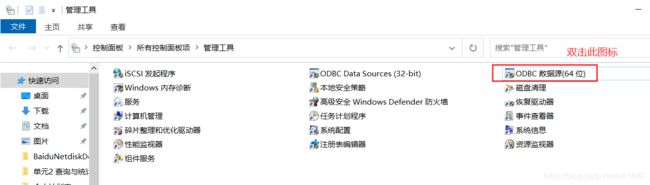
在 “管理工具” 文件夹中,双击 “数据源(ODBC)” 图标,打开 ODBC 数据源管理器,如图所示。
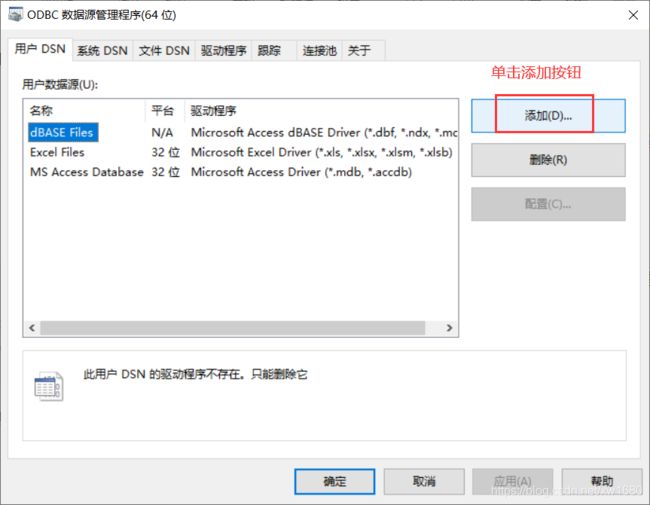
- 在 ODBC 数据源管理器中,单击“添加”按钮,打开“创建新数据源”对话框,如图所示:
- 在“创建新数据源”对话框中选择 ODBC 提供驱动程序的数据源,包括 Access 类驱动程序、dBase 类驱动程序、Excel 类驱动程序、FoxPro 类驱动程序、Visual FoxPro 类驱动程序、Paradox 类驱动程序、Text 类驱动程序、Oracle 类驱动程序和 SQL Server 类驱动程序。本章主要介绍创建 SQL Server 的数据源,所以在驱动程序名称菜单中,选择“SQL Server Native Client 11.0”,单击“完成”按钮,如下图所示:
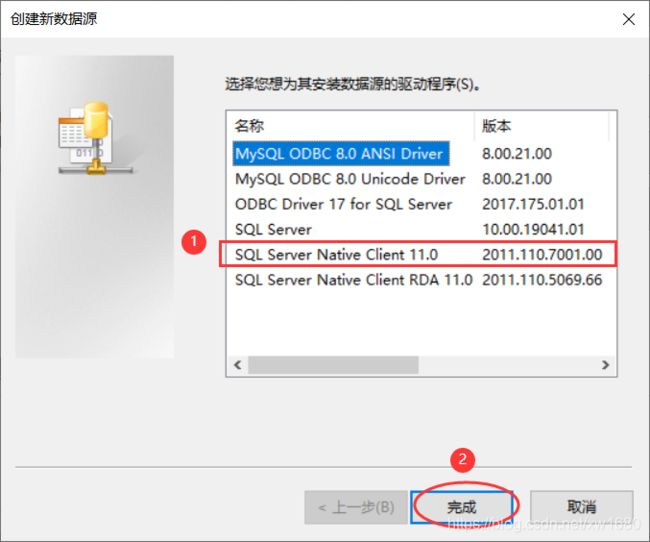
- 随后打开“创建到 SQL Server的新数据源”对话框。在“名称”文本框内输入新的数据源名,例如 csql。在“描述”文本框内输入对数据源的描述,也可以为空,这里没有输入内容。在“服务器”下拉列表框中选择需要连接的服务器,笔者这里直接输入的
LAPTOP-CQGGTJJP\AMOXIANG。然后单击“下一步”按钮,如图所示:
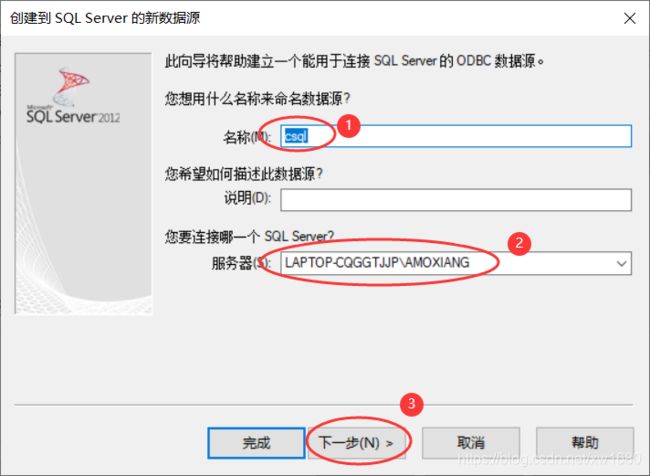
- 接下来选择 SQL Server 的登录验证方式,在“创建到SQL Server的新数据源”对话框中,选择第二个单选框“使用用户输入登录ID和密码的SQL Server验证(S)”,然后输入登录ID和密码,单击“下一步”按钮,如图所示。
在“登录ID”文本框中输入“sa”。
在“密码”文本框中输入密码,这个密码是安装 SQL Server 时设置的,如果为空,则不输入。
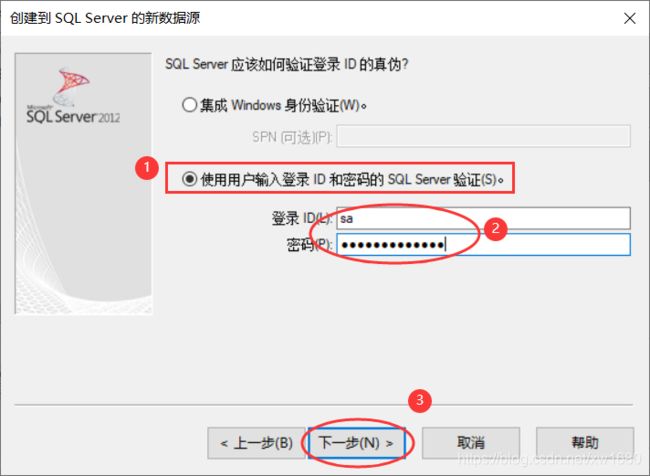
- 打开下图所示的对话框。选中“更改默认的数据库为”复选框,同时在下拉列表框中选择需要的 SQL Server 数据库(例如选择 student),然后单击“下一步”按钮。
- 在打开的对话框中使用默认选项,单击“完成”按钮,则打开“ODBC Microsoft SQL Server安装”对话框。单击“测试数据源”按钮,如果正确,则测试成功;如果不正确,系统会指出具体的错误,用户应该重新检查配置的内容是否正确。测试成功如图所示。
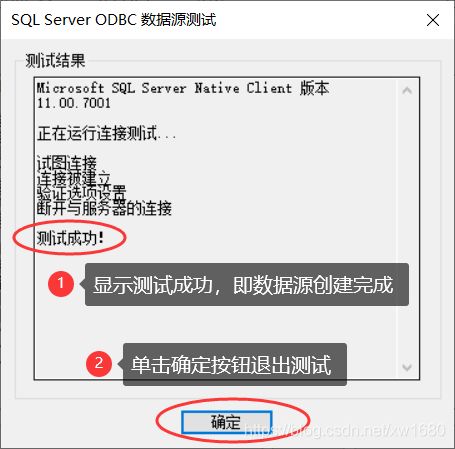
- 单击“确定”按钮,新创建的数据源就会添加到如下图所示对话框中的数据源列表框中,再单击“确定”按钮,一个新的 SQL Server 数据源就创建完成了。
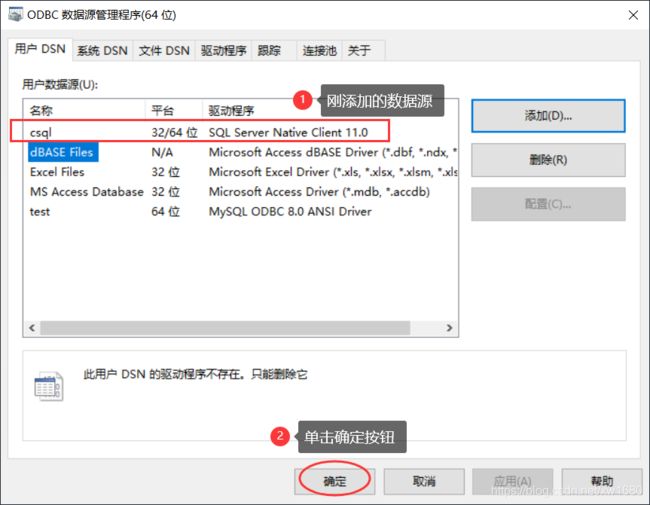
至此,ODBC 数据源 csql 就创建完成了,接下来就可以使用 ODBC 数据源进行数据库的连接。
3. 连接数据库函数
使用 C 语言连接数据库需要使用到一些函数,下面分别介绍。
(1) SQLAllocHandle() 函数。
该函数用来分配句柄,语法如下:
SQLRETURN SQLAllocHandle(
SQLSMALLINT HandleType,
SQLHANDLE InputHandle,
SQLHANDLE* OutputHandlePtr
);
参数说明:
-
HandleType:输入变量。该变量只能从下列四个值中选择其一:
- SQL_HANDLE_ ENV:用于申请环境句柄。
- SQL_HANDLE_DBC:用于申请连接句柄。
- SQL_HANDLE_DESC:用于申请描述符句柄。
- SQL_HANDLE_STMT:用于申请语句句柄。
-
InputHandle:该变量放入已经被分配好的前提句柄,如果第一个变量为环境句柄,则放入 SQL_NULL_HANDLE 即可;如果第一个变量为 SQL_HANDLE_DBC,则第二个变量必须为已分配的环境句柄;如果第一个变量为 SQL_HANDLE_DESC,SQL_HANDLE_STMT,则第二个变量必须为已分配好的连接句柄。
-
OutputHandlePtr:该变量为一个指针变量,用于保存申请来的句柄,申请句柄类型为第一个变量,在定义该指针的时候需要注意类型一致。返回值有四种:SQL_SUCCESS、SQL_SUCCESS_WTTH_INFO、SQL_INVALID_HANDLE、SQL_ERROR。
(2) SQLSetEnvAttr() 函数。
该函数用于设置环境属性值,语法如下:
SQLRETURN SQLSetEnvAttr(
SQLHENV EnvironmentHandle,
SQLINTEGER Attribute,
SQLPOINTER ValuePtr,
SQLINTEGER StringLength
);
参数说明:EnvironmentHandle:输入变量,需放入环境句柄。Attribute:输入变量。ValuePtr:输入变量。Attribute 和 ValuePtr 的取值如下表所示:
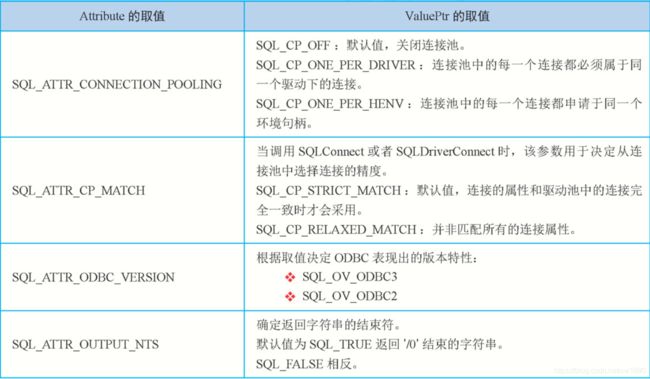
StringLength:输入变量如果 ValuePir 为一个整型指针,则可以被忽略。如果为二进制或字符串,那么就需要再次计算。返回值有四种:SQL_SUCCESS、SQL_SUCCESS_WTTH_INFO、SQL_INVALID_HANDLE、SQL_ERROR。
(3) 连接函数。
在分配环境和连接句柄并设置连接属性后,应用程序将连接到数据源或驱动程序。有三种可用于连接的函数:SQLConnect() 函数、SQLDriverConnect() 函数、SQLBrowseConnect() 函数
-
SQLConnect() 函数。SQLConnect() 是最简单的连接函数。它接受三个参数:数据源名称、用户ID 和密码,这三个参数包含连接到数据库所需的所有信息。若要执行此操作,生成使用的数据源的名称 SQLDataSources,提示用户输入数据源、用户ID 和密码,然后调用 SQLConnect。
-
SQLDriverConnect() 函数。SQLDriverConnect() 函数是在数据源名称、用户ID 和密码的详细信息同时都存在的情况下使用。参数之一的 SQLDriverConnect() 是一个包含特定于驱动程序信息的连接字符串。使用 SQLDriverConnect() 函数而不是 SQLConnect() 函数的原因如下:
- 在连接时指定特定于驱动程序的信息。
- 请求驱动程序提示用户输入连接信息。
- 不使用 ODBC 数据源进行连接。
SQLDriverConnect() 函数连接字符串包含一系列指定 ODBC 驱动程序支持的所有连接信息的关键字/值对。每个驱动程序都支持标准 ODBC 关键字(DSN、FILEDSN、DRIVER、UID、PWD和SAVEFILE),以及用于驱动程序支持的所有连接信息的特定于驱动程序的关键字。SQLDriverConnect() 函数可以用于不使用数据源连接。例如,应用程序,旨在使“dsn”连接到的实例 SQL Server 可以调用 SQLDriverConnect() 函数与定义的登录ID、密码、网络库和服务器名称到一个连接字符串连接和默认数据库以使用。
使用 SQLDriverConnect() 函数,用于提示用户为任何所需的连接信息的两个选项:应用程序对话框:可以创建一个应用程序对话框,提示输入连接信息,然后呼叫 SQLDriverConnect() 函数,带有 NULL 窗口句柄和 DriverCompletion 设置为 SQL_DRIVER_NOPROMPT。这些参数设置将禁止 ODBC 驱动程序打开自己的对话框。在对应用程序的用户界面进行控制时,使用此方法。驱动程序对话框:可以编写代码,应用程序传递的有效的窗口句柄 SQLDriverConnect() 函数并设置 DriverCompletionSQL_DRIVER_COMPLETE、SQL_DRIVER_PROMPT 或 SQL_DRIVER_COMPLETE_ 参数必填。驱动程序然后生成一个对话框,以便提示用户输入连接信息。此方法可以简化应用程序代码。 -
SQLBrowseConnect() 函数。SQLBrowseConnect() 函数与SQLDriverConnect() 函数类似,功能都是连接字符串。但是,通过使用 SQLBrowseConnect() 函数,应用程序可以在运行时构造完整连接字符串,以迭代方式与数据源。这允许应用程序执行以下两种操作:生成自己的对话框以提示输入此信息,因此保留对其用户界面的控制。浏览系统以找到可由特定的驱动程序使用的数据源,它需要执行若干步骤。例如,用户可能要首先浏览网络以找到服务器,然后再选择某一服务器后,浏览该服务器以找到驱动程序可访问的数据库。当 SQLBrowseConnect() 函数完成成功连接时,它返回的连接字符串,可在后续调用 SQLDriverConnect() 函数。
4. SQLExecDirect()函数
如果语句中存在任何参数,则 SQLExecDirect() 使用参数标记变量的当前值来执行可预准备语句。SQLExecDirect() 函数是提交一次执行的 SQL 语句的最快方式,语法格式如下:
SQLRETURN SQLExecDirect(
SQLHSTMT StatementHandle,
SQLCHAR *StatementText,
SQLINTEGER TextLength);
参数说明:
- StatementHandle:SQL 语句句柄。
- StatementText:要执行的 SQL 语句。
- TextLength:SQL字符串长度。
5. SQLPrepare() 函数
SQLPrepare() 是 ODBC 中的一个 API 函数,用来创建 SQL 语句,语法格式如下:
SQLRETURN SQLPrepare(
SQLHSTMT StatementHandle,
SQLCHAR * StatementText,
SQLINTEGER TextLength);
参数说明:
- StatementHandle:SQL 语句句柄。
- StatementText:要执行的 SQL 语句。
- TextLength:SQL字符串长度。
6. SQLBindCol() 函数
SQLBindCol() 函数可以实现将数据缓冲绑定到结果集的列,语法格式如下:
SQLRETURN SQLBindCol(
SQLHSTMT StatementHandle,
SQLUSMALLINT ColumnNumber,
SQLSMALLINT TargetType,
SQLPOINTER TargetValuePtr,
SQLINTEGER BufferLength,
SQLLEN * StrLen_or_Ind);
参数说明:
- StatementHandle:SQL 语句句柄。
- ColumnNumber:结果集里要绑定的列号。
- TargetType:*TargetValuePtr 所指缓冲的 C 数据类型的标识符。
- TargetValuePtr:用来绑定列的数据缓冲的指针。
- BufferLength:缓冲的字节数长度。
- StrLen_or_IndPtr:指向绑定列的长度。
7. SQLFetch() 函数
SQLFetch() 函数从结果集中提取下一行数据并返回所有绑定列的数据,语法格式如下:
SQLRETURN SQLFetch(
SQLHSTMT StatementHandle
);
参数说明:
- StatementHandle:SQL 语句句柄。
4. C 语言通过 ODBC 操作数据库
下面来讲解一个使用 ODBC 连接数据库的实例。
【实例01】:通过 C 语言代码操作数据库,向 student 数据库的 student 表中插入一条数据,代码如下。
#include执行代码前:
执行代码后:
三、非 ODBC 方式操作数据库
对数据的操作,简单来说可以分为两种,一种是对数据的操作,如删除、修改、插入等;另一种是对数据的查询,即从数据库中查询数据,下面分别进行介绍。
3.1 删除、修改、插入数据
C 语言对数据库的操作主要体现在 SQL 语句上,主要有两种,分别为:直接执行 SQL 语句方式和预编译执行 SQL 语句方式。
1. 直接执行 SQL 语句
通过 SQLExecDirect() 函数直接执行SQL语句。【实例02】:向 student 数据库的 student 表中插入一条数据,代码如下:
#include2. 预编译执行 SQL 语句
通过 SQLPrepare() 函数预编译执行 SQL 语句。【实例03】:向 student 数据库的 student 表中插入一条数据,代码如下:
#include3.2 查询数据
C 语言对数据库的操作,除了插入、删除和修改数据外,还可以查询数据,下面通过一个实例来介绍如何通过 C 语言程序查询数据库中的数据。
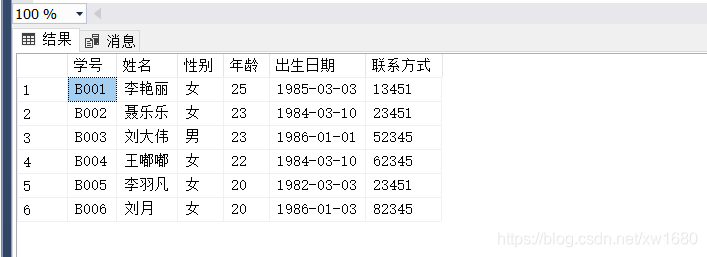
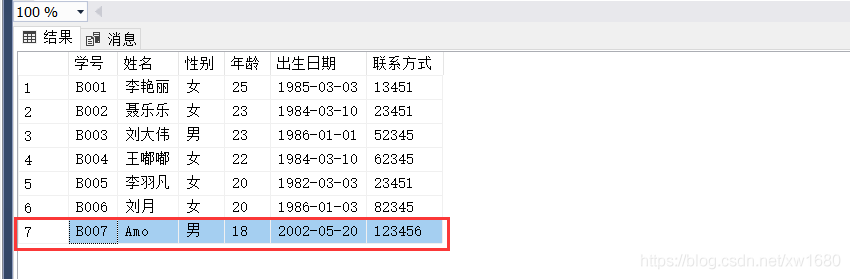
【实例04】查询 student 表中的所有数据,代码如下:
#include运行程序,结果如下图所示:
四、拓展:Python 操作 SQLServer
4.1 pymssql 模块
使用 pip 命令安装 pymssql 模块。如下图所示:
读者只需记住几个函数和方法,绝大多数的数据库的操作就可以搞定了。
(1) connect 函数:连接数据库,根据连接的数据库类型不同,该函数的参数也不同。connect 函数返回 Connection 对象。
(2) cursor 方法:获取操作数据库的 Cursor 对象。cursor 方法属于 Connection 对象。
(3) execute 方法:用于执行 SQL 语句,该方法属于 Cursor 对象。
(4) commit 方法:在修改数据库后,需要调用该方法提交对数据库的修改,commit 方法属于 Cursor 对象。
(5) rollback 方法:如果修改数据库失败,一般需要调用该方法进行数据库回滚,也就是将数据库恢复成修改之前的样子。
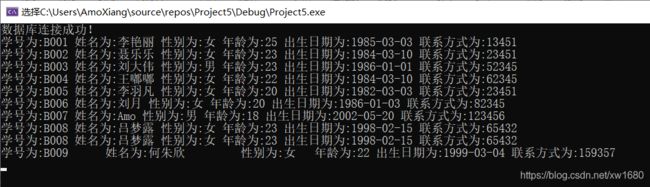
本例通过调用 pymssql 模块中的相应 API 对 SQLServer 数据库进行增、删、改、查操作。示例代码如下:
from pymssql import *
import json
# 打开 SQLServer 数据库,其中 LAPTOP-CQGGTJJP\AMOXIANG 笔者连接的SQLServer服务器
# sa 是用户名,sqlserver2019 是密码
# student 是数据库名
def connect_db():
db = connect(host="LAPTOP-CQGGTJJP\\AMOXIANG",
user="sa", password="sqlserver2019",
database="student", charset="utf8")
return db
db = connect_db()
# 创建 persons表
def create_table(db):
# 获取 Cursor对象
cursor = db.cursor()
sql = """CREATE TABLE persons
(id INT PRIMARY KEY NOT NULL,
name NVARCHAR(20) NOT NULL,
age INT NOT NULL,
address NCHAR(50),
salary REAL);
"""
try:
# 执行创建表的SQL语句
cursor.execute(sql)
cursor.close()
# 提交到数据库执行
db.commit()
return True
except:
# 如果发生错误则回滚
db.rollback()
return False
# 向persons表插入4条数据
def insert_records(db):
cursor = db.cursor()
try:
# 首先将以前插入的记录全部删除
cursor.execute("DELETE FROM persons;")
# 下面的几条语句向 persons表中插入4条记录
cursor.execute("INSERT INTO persons(id,name,age,address,salary) VALUES(1,'Paul',32,'Californis',20000.00)")
cursor.execute("INSERT INTO persons(id,name,age,address,salary) VALUES(2,'Allen',25,'Texas',15000.00)")
cursor.execute("INSERT INTO persons(id,name,age,address,salary) VALUES(3,'Teddy',23,'Norway',20000.00)")
cursor.execute("INSERT INTO persons(id,name,age,address,salary) VALUES(4,'Amo',18,'Rich-Mond',65000.00)")
# 提交到数据库执行
cursor.close()
db.commit()
return True
except Exception as e:
print(e)
# 如果发生错误则回滚
db.rollback()
return False
# 查询 persons表中全部的记录,并按age字段降序排列
def select_records(db):
cursor = db.cursor()
sql = "SELECT name,age,salary FROM persons ORDER BY age DESC;"
cursor.execute(sql)
# 调用fetchall()方法获取全部的记录
results = cursor.fetchall()
# 输出查询结果
print(results)
# 下面的代码将查询结果重新组织成其他形式
fields = ["name", "age", "salary"]
records = []
for row in results:
records.append(dict(zip(fields, row)))
cursor.close()
return json.dumps(records)
# if create_table(db):
# print("成功创建persons表")
# else:
# print("persons 表已经存在")
if insert_records(db):
print("成功插入记录")
else:
print("插入记录失败")
print(select_records(db))
db.close()
4.2 ORM 框架
开发人员经常接触的关系型数据库主要有 MySQL、Oracle、SQL Server、SQLite 和 PostgreSQL,操作数据库的方法大致有以下两种:
(1) 直接使用数据库接口连接。在 Python 的关系数据库连接模块中,分别有pymysql、cx_Oracle、pymssql、sqlite3 和 psycopg2。通常,这类数据库的操作步骤都是连接数据库、执行 SQL 语句、提交事务、关闭数据库连接。每次操作都需要 Open/Close Connection,如此频繁地操作对于整个系统无疑是一种浪费。对于一个企业级的应用来说,这无疑是不科学的开发方式。
(2) 通过ORM (Object/Relation Mapping,对象-关系映射) 框架来操作数据库。这是随着面向对象软件开发方法的发展而产生的,面向对象的开发方法是当今企业级应用开发环境中的主流开发方法,关系数据库是企业级应用环境中永久存放数据的主流数据存储系统。对象和关系数据是业务实体的两种表现形式,业务实体在内存中表现为对象,在数据库中表现为关系数据。内存中的对象之间存在关联和继承关系,而在数据库中,关系数据无法直接表达多对多关联和继承关系。因此,ORM 系统一般以中间件的形式存在,主要实现程序对象到关系数据库数据的映射。
常用的 ORM框架 模块有 SQLObject、Stom、Django的 ORM、peewee 和 SQLAlchemy。博文主要讲述 Python 的 ORM 框架 ⇒ SQLAlchemy。SQLAlchemy是 Python 编程语言下的一款开源软件,提供 SQL 工具包及对象(关系映射工具),使用 MIT 许可证发行。
SQLAlchemy 采用简单的 Python 语言,为高效和高性能的数据库访问设计,实现了完整的企业级持久模型。SQLAlchemy 的理念是,SQL 数据库的量级和性能重要于对象集,而对象集合的抽象又重要于表和行。因此,SQLAlchmey 采用类似 Java 里 Hibernate 的数据映射模型,而不是其他 ORM 框架采用的 Active Record 模型。不过,Elixir 和 declarative 等可选插件可以让用户使用声明语法。
SQLAlchemy 首次发行于2006年2月,是 Python 社区中被广泛使用的 ORM 工具之一,不亚于 Django 的 ORM 框架。SQLAlchemy 在构建于 WSGI 规范的下一代 Python Web 框架中得到了广泛应用,是由 Mike Bayer 及其开发团队开发的一个单独的项目。使用 SQLAlchemy 等独立 ORM 的一个优势就是允许开发人员首先考虑数据模型,并能决定稍后可视化数据的方式 (采用命令行工具、Web框架还是GUI框架)。这与先决定使用 Web框架或GUI框架,再决定如何在框架允许的范围内使用数据模型的开发方法极为不同。SQLAlchemy 的一个目标是提供能兼容众多数据库 (如SQLite、MySQL、Postgres、Oracle、MS-SQL、SQLServer 和 Firebird) 的企业级持久性模型。安装 SQLAlchemy 时,建议直接使用 pip 安装,命令如下:
pip install SQLAlchemy
如下图所示:
使用 SQLAlchemy 连接数据库实质上还是通过数据库接口实现连接,安装 SQLAlchemy 后还需要安装对应数据库的接口模块,下面以 SQLServer 为例安装 pymssql 模块:
pip install pymssql
完成安装后,打开 CMD 窗口,通过导入模块测试是否安装成功:
4.2.1 连接数据库
SQLAlchemy 连接数据库使用数据库连接池技术,原理是在系统初始化的时候,将数据库连接作为对象存储在内存中,当用户需要访问数据库时,并非建立一个新的连接,而是从连接池中取出一个已建立的空闲连接对象。使用完毕后,用户也并非将连接关闭,而是将连接放回连接池中,以供下一个请求访问使用。而连接的建立、断开都由连接池自身来管理。同时,还可以通过设置连接池的参数来控制连接池中的初始连接数、连接的上下限数以及每个连接的最大使用次数、最大空闲时间等。也可以通过其自身的管理机制来监视数据库连接的数量、使用情况等。通过了解 SQLAlchemy 的原理有利于理解 SQLAlchemy 连接数据库的代码,代码如下:
from sqlalchemy import create_engine
"""
create_engine:
(数据库类型+数据库驱动名称://用户名:密码@数据库服务器的名称或(IP地址:端口号)/数据库名称?")
"""
engine = create_engine("mssql+pymssql://sa:sqlserver2019@LAPTOP-CQGGTJJP\\AMOXIANG/student?charset=utf8", echo=True,
pool_size=5, pool_timeout=30, max_overflow=4, pool_recycle=7200)
(1) “mssql+pymssql://sa:sqlserver2019@LAPTOP-CQGGTJJP\AMOXIANG/student?charset=utf8”:mssql 指明数据库系统类型,pymssql 是连接数据库接口的模块,sa 是数据库系统用户名,sqlserver2019 是数据库系统密码,LAPTOP-CQGGTJJP\AMOXIANG 是本地的数据库系统服务器的名称,student 是数据库名称,charset 指的是编码。
(2) echo=True:用于显示 SQLAlchemy 在操作数据库时所执行的 SQL 语句情况,相当于一个监视器,可以清楚知道执行情况,如果设置为 False,就可以关闭。
(3) pool_size:设置连接数,默认设置5个连接数,连接数可以根据实际情况进调整,在一般的爬虫开发中,使用默认值已足够。
(4) max_overflow:默认连接数为10。当超出最大连接数后,如果超出的连接数在 max_overflow 设置的访问内,超出的部分还可以继续连接访问,在使用过后,这部分连接不放在 pool (连接池) 中,而是被真正关闭。
(5) pool_recycle :连接重置周期,默认为-1,推荐设置为7200,即如果连接已空闲 7200 秒,就自动重新获取,以防止 connection 被关闭。
(6) pool_timeout:连接超时时间,默认为30秒,超过时间的连接都会连接失败。
(7) ?charset=utf8:对数据库进行编码设置,能对数据库进行中文读写,如果不设置,在进行数据添加、修改和更新等时,就会提示编码错误。上述代码只是给出连接 SQLServer 的语句,其他数据的连接如下图所示:

4.2.2 创建数据表
完成数据库的连接后,可以通过 SQLAlchemy 对数据表进行创建和删除,使用 SQLAlchemy 创建数据表,代码如下:
# -*- coding: UTF-8 -*-
from sqlalchemy.ext.declarative import declarative_base
from sqlalchemy import Column, Integer, String, DateTime
from sqlalchemy import create_engine
"""
create_engine:
(数据库类型+数据库驱动名称://用户名:密码@数据库服务器的名称或(IP地址:端口号)/数据库名称?")
"""
engine = create_engine("mssql+pymssql://sa:sqlserver2019@LAPTOP-CQGGTJJP\\AMOXIANG/student?charset=utf8", echo=True,
pool_size=5, pool_timeout=30, max_overflow=4, pool_recycle=7200)
Base = declarative_base()
print(1)
# 第一种创建数据表的方式
class MyTable(Base):
# 表名
__tablename__ = "mytable"
# 字段,属性
id = Column(Integer, primary_key=True)
name = Column(String(50), unique=True)
age = Column(Integer)
birth = Column(DateTime)
class_name = Column(String(50))
# 创建数据表
Base.metadata.create_all(engine)
引入 declarative_base 模块,生成其对象 Base,再创建一个类 MyTable。一般情况下,数据表名和类名是一致的,__tablename__ 用于定义数据表的名称,可忽略,忽略时默认类名为数据表名。然后创建字段 id、name、age、birth、class_name。最后使用 Base.metadata.create_all(engine) 在数据库中创建对应的数据表。上述是比较常见的创建数据表的方法之一,还有一种创建方法类似 SQL 语句的创建方法:
# 第一种表创建的导入方式
from sqlalchemy import create_engine
from sqlalchemy.ext.declarative import declarative_base
from sqlalchemy import Column, MetaData, Table
from sqlalchemy.dialects.mssql import (INTEGER, CHAR)
engine = create_engine("mssql+pymssql://sa:sqlserver2019@LAPTOP-CQGGTJJP\\AMOXIANG/student?charset=utf8", echo=True,
pool_size=5, pool_timeout=30, max_overflow=4, pool_recycle=7200)
Base = declarative_base()
meta = MetaData()
my_class = Table("myclass", meta,
Column("id", INTEGER, primary_key=True),
Column("name", CHAR(50)),
Column("class_name", CHAR(50))
)
# 创建数据表
my_class.create(bind=engine)
"""
总结:
第二种与第一种创建数据表的方法大有不同,代码比较偏向于SQL创建数据表的语法,两者引入的模
块也各不相同,导致在创建数据表的时候,创建语法也不一致。不过两者实现的功能是一样的,可以根据自己的
爱好进行选择。一般情况下,前者较有优势,在数据表已经存在的情况下,前者再创建数据表不会报错,
后者就会提示已存在数据表的错误信息。
"""
# 若要删除数据表
my_class.drop(bind=engine)
Base.metadata.drop_all(engine)
"""
在删除数据表的时候,一定要先删除设有外键的数据表,也就是先删除 myclass 后才能删除mytable,两者之
间涉及外键,这是在数据库中删除数据表的规则。
"""
总结: 第二种与第一种创建数据表的方法大有不同,代码比较偏向于SQL创建数据表的语法,两者引入的模块也各不相同,导致在创建数据表的时候,创建语法也不一致。不过两者实现的功能是一样的,读者可以根据自己的爱好进行选择。一般情况下,前者较有优势,在数据表已经存在的情况下,前者再创建数据表不会报错,后者就会提示已存在数据表的错误信息。若要删除数据表,则可用以下代码:
# 若要删除数据表
my_class.drop(bind=engine)
Base.metadata.drop_all(engine)
无论数据表是否已经创建,在使用 SQLAlchemy 时一定要对数据表的属性、字段进行类定义。也就是说,无论通过什么方式创建数据表,在使用 SQLAlchemy 的时候,第一步是创建数据库连接,第二步是定义类来映射数据表,类的属性映射数据表的字段。
4.2.3 添加数据
完成数据表的创建后,下一步对数据表的数据进行操作。首先创建一个会话对象,用于执行 SQL 语句,代码如下:
from sqlalchemy.orm import sessionmaker
DBSession = sessionmaker(bind=engine)
session = DBSession()
引入 sessionmaker 模块,指明绑定已连接数据库的 engine 对象,生成会话对象 session,该对象用于数据库的增、删、改、查。一般来说,常用的数据库操作是增、改、查,SQLAlchemy 对这类操作有自身的语法支持。对上面代码中创建的数据表添加数据,代码如下:
new_data = MyTable(name="AmoXiang", age=18, birth="2000-5-20", class_name="一年级一班")
session.add(new_data)
session.commit()
session.close()
要使用 SQLAlchemy 添加数据,必须已经定义 mytable 对象,mytable 是映射数据库里面的 mytable 数据表。然后设置类属性 (字段) 对应的添加值,将数据绑定在 session 会话中,最后通过 session.commit() 来提交到数据库中,就完成对数据库的数据添加了。session.close()用于关闭会话,关闭会话不是必要规定,不过为了形成良好的编码规范,最好添加上。注意,如果关闭会话放在 session.commit() 之前,这个添加语句就是无效的,因为当前的 session 已经被关闭和销毁。所以在使用 session.close() 时,要注意编写的位置。完整代码:
from sqlalchemy.orm import sessionmaker
from sqlalchemy import create_engine
from sqlalchemy.ext.declarative import declarative_base
from sqlalchemy import Column, Integer, String, DateTime
engine = create_engine("mssql+pymssql://sa:sqlserver2019@LAPTOP-CQGGTJJP\\AMOXIANG/student?charset=utf8", echo=True,
pool_size=5, pool_timeout=30, max_overflow=4, pool_recycle=7200)
Base = declarative_base()
DBSession = sessionmaker(bind=engine)
session = DBSession()
# 第一种创建数据表的方式
class MyTable(Base):
# 表名
__tablename__ = "mytable"
# 字段,属性
id = Column(Integer, primary_key=True)
name = Column(String(50), unique=True)
age = Column(Integer)
birth = Column(DateTime)
class_name = Column(String(50))
Base.metadata.create_all(engine)
# new_data = MyTable(name="AmoXiang", age=18, birth="2000-5-20", class_name="一年级一班")
# session.add(new_data)
new_data = MyTable(name="Li Lei", age=18, birth="2000-5-20", class_name="一年级一班")
session.add(new_data)
new_data = MyTable(name="AmoXiang", age=18, birth="2000-5-20", class_name="一年级一班")
session.add(new_data)
session.commit()
session.close()
4.2.4 更新数据
目前,数据库中已经添加了一条数据,如果要对这条数据进行更新,SQLAlchemy 提供了以下两种更新数据的方法。完整代码如下:
from sqlalchemy.orm import sessionmaker
from sqlalchemy import create_engine
from sqlalchemy.ext.declarative import declarative_base
from sqlalchemy import Column, Integer, String, DateTime
engine = create_engine("mssql+pymssql://sa:sqlserver2019@LAPTOP-CQGGTJJP\\AMOXIANG/student?charset=utf8", echo=True,
pool_size=5, pool_timeout=30, max_overflow=4, pool_recycle=7200)
Base = declarative_base()
DBSession = sessionmaker(bind=engine)
session = DBSession()
# 第一种创建数据表的方式
class MyTable(Base):
# 表名
__tablename__ = "mytable"
# 字段,属性
id = Column(Integer, primary_key=True)
name = Column(String(50), unique=True)
age = Column(Integer)
birth = Column(DateTime)
class_name = Column(String(50))
Base.metadata.create_all(engine)
"""
首先查询 mytable 表id为1的数据,然后使用update对这条数据进行更新,update数据的格式是字典类型,
通过键值的方式对数据进行更新,接着使用 session.commit()执行更新语句,最后使用session.close()
关闭当前会话,释放资源。如果批量更新,就可以将filter_by(id=1)去掉,
这样能将mytable中age字段的值全部更新为12。filter_by 相当于SQL语句里面的where条件判断
"""
session.query(MyTable).filter_by(id=1).update({
MyTable.age: 12})
"""
使用赋值方式更新数据:
将数据查询出来,生成查询对象,然后对该对象的某个属性重新赋值,最后提交到数据库执
行。这种方法对批量更新不太友好,常用于单条数据的更新,若要用这种方法实现批量更新,
则只能循环每条数据进行赋值更改。但这种方法对性能影响较大,批量更新使用update()比较合理。
"""
get_data = session.query(MyTable).filter_by(id=1).first()
get_data.class_name = "三年级三班"
session.commit()
session.close()
4.2.5 查询数据
SQLAlchemy 对数据库多种查询方式有很好的语法支持。完整代码如下:
from sqlalchemy.orm import sessionmaker
from sqlalchemy import create_engine
from sqlalchemy.ext.declarative import declarative_base
from sqlalchemy import Integer, String, DateTime
from sqlalchemy import Column, MetaData, ForeignKey, Table
from sqlalchemy.dialects.mysql import (INTEGER, CHAR)
from sqlalchemy import or_
engine = create_engine("mssql+pymssql://sa:sqlserver2019@LAPTOP-CQGGTJJP\\AMOXIANG/student?charset=utf8", echo=True,
pool_size=5, pool_timeout=30, max_overflow=4, pool_recycle=7200)
Base = declarative_base()
DBSession = sessionmaker(bind=engine)
session = DBSession()
# 第一种创建数据表的方式
class MyTable(Base):
# 表名
__tablename__ = "mytable"
# 字段,属性
id = Column(Integer, primary_key=True)
name = Column(String(50), unique=True)
age = Column(Integer)
birth = Column(DateTime)
class_name = Column(String(50))
Base.metadata.create_all(engine)
# 创建数据表
# Base.metadata.create_all(engine)
meta = MetaData()
my_class = Table("myclass", meta,
Column("id", INTEGER, primary_key=True),
Column("name", String(50), ForeignKey(MyTable.name)),
Column("class_name", CHAR(50))
)
# 创建数据表
# 第一次的时候要把这个创建表的语句打开!!!否则程序会出错
# my_class.create(bind=engine)
# 查询 MyClass全部数据: 相当于SQL语句里面的select * from myclass;而all()是将数据以列表的形式返回。
get_data = session.query(my_class).all()
# [(1, 'AmoXiang', '三年级三班'), (2, 'Han meimei', '三年级二班'), (3, 'LILEI', '三年级一班')]
print(get_data)
for i in get_data:
# print(type(i))
print(f"我的名字是: {i.name}, 班级是: {i.class_name}")
# 查询某一字段
get_data = session.query(MyTable.name, MyTable.age).all()
for i in get_data:
print(f"我的名字是: {i.name}, 年龄是: {i.age}")
session.close()
# 根据条件查询某条数据
# 筛选方法一:
# get_data = session.query(MyTable).filter(MyTable.id == 1).all()
# print(get_data)
# 筛选方法二:
get_data = session.query(MyTable).filter_by(id=1).all()
print("数据类型是: " + str(type(get_data)))
for i in get_data:
print("我的名字是: " + i.name)
"""
总结:
(1) 字段写法: filter 筛选的字段是带类名(表名)的,而filter_by只需筛选字段即可。
(2) 判断条件: filter 比 filter_by 多出一个等号。
(3) 作用范围: filter 可以用于单表或者多表查询,而filter_by只能用于单表查询。
all() 方法是将查询数据以列表的形式返回,但只查询一条数据的时候,可以用first()返回第一条数据。
"""
# get_data = session.query(MyTable).filter(MyTable.id >= 2, MyTable.class_name == "三年级二班").first()
# print(f"我的名字是: {get_data.name}")
get_data = session.query(MyTable).filter(or_(MyTable.id >= 2, MyTable.class_name == "三年级一班")).all()
# print(type(get_data))
# for i in get_data:
# print(i.name)
# 内连接
get_data = session.query(MyTable).join(my_class).filter(MyTable.class_name == '三年级二班').all()
print('数据类型是:' + str(type(get_data)))
for i in get_data:
print('我的名字是:' + i.name)
print('我的班级是:' + i.class_name)
# 外连接
get_data = session.query(MyTable).outerjoin(my_class).filter(MyTable.class_name == '三年级二班').all()
for i in get_data:
print('我的名字是:' + i.name)
print('我的班级是:' + i.class_name)
"""
一般来说,如果涉及复杂的查询语句,特别涉及多表查询和复杂的查询条件时,SQLAlchemy还可以直接执行SQL语句
"""
sql = "select * from mytable "
session.execute(sql)
# 如果涉及更新、添加数据,就需要session.commit()
session.commit()
session.close()