PaddleOCR 安装和训练
PaddleOCR环境安装
- 安装Anaconda3-5.2.0
- 安装Pycharm
- 安装CUDA 和Cudnn
- 查询CUDA版本 11.0和Cudnn 8.0.5
Cuda链接
Cudnn
win10下查看nvidia情况 - 安装TensorRT
TensorRT 要与CUDA 和Cudnn版本对应。
- 查询CUDA版本 11.0和Cudnn 8.0.5
ncvv -V #查询cuda版本
nvidia-smi -l 2 #2秒刷新一次 GPU使用情况

- 安装Git
Windows系统Git安装教程(详解Git安装过程) - 安装Vim
在Windows中安装vim
Vim下载链接 - PaddleOCR虚拟环境创建
conda create -n paddle python=3.6 #创建虚拟环境
activate paddle #激活虚拟环境
pip install --upgrade pip # pip 升级
# 安装paddlepaddle
pip install paddlepaddle-gpu==2.0.0 -i https://mirror.baidu.com/pypi/simple
# 获取PaddleOCR
git clone https://github.com/PaddlePaddle/PaddleOCR
cd PaddleOCR
pip install -r requirements.txt #安装第三方库 paddleocr 路径下
## 如果anaconda navigator打不开,更新anaconda navigator
conda update anaconda-navigator
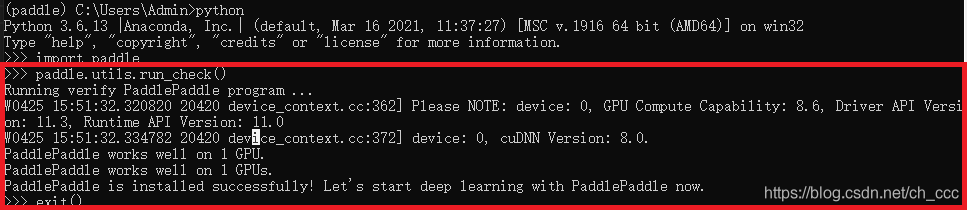
验证是否安装成功paddle ocr GPU
import paddle
paddle.utils.run_check()#如果出现PaddlePaddle is installed successfully!,说明您已成功安装。
- PaddleOCR 训练
PaddleOCR 也提供了数据格式转换脚本,可以将官网 label 转换支持的数据格式。 数据转换工具在ppocr/utils/gen_label.py, 这里以训练集为例:
# 将官网下载的标签文件转换为 train_icdar2015_label.txt
python gen_label.py --mode="det" --root_path="icdar_c4_train_imgs/" \
--input_path="ch4_training_localization_transcription_gt" \
--output_label="train_icdar2015_label.txt"
解压数据集和下载标注文件后,PaddleOCR/train_data/ 有两个文件夹和两个文件,分别是:
/PaddleOCR/train_data/icdar2015/text_localization/
└─ icdar_c4_train_imgs/ icdar数据集的训练数据
└─ ch4_test_images/ icdar数据集的测试数据
└─ train_icdar2015_label.txt icdar数据集的训练标注
└─ test_icdar2015_label.txt icdar数据集的测试标注
快速安装
经测试PaddleOCR可在glibc 2.23上运行,您也可以测试其他glibc版本或安装glic 2.23
PaddleOCR 工作环境
- PaddlePaddle 2.0.0
- python3.7
- glibc 2.23
- cuDNN 7.6+ (GPU)
建议使用我们提供的docker运行PaddleOCR,有关docker、nvidia-docker使用请参考链接。
如您希望使用 mac 或 windows直接运行预测代码,可以从第2步开始执行。
1. (建议)准备docker环境。第一次使用这个镜像,会自动下载该镜像,请耐心等待。
# 切换到工作目录下
cd /home/Projects
# 首次运行需创建一个docker容器,再次运行时不需要运行当前命令
# 创建一个名字为ppocr的docker容器,并将当前目录映射到容器的/paddle目录下
如果您希望在CPU环境下使用docker,使用docker而不是nvidia-docker创建docker
sudo docker run --name ppocr -v $PWD:/paddle --network=host -it paddlepaddle/paddle:latest-dev-cuda10.1-cudnn7-gcc82 /bin/bash
如果使用CUDA10,请运行以下命令创建容器,设置docker容器共享内存shm-size为64G,建议设置32G以上
sudo nvidia-docker run --name ppocr -v $PWD:/paddle --shm-size=64G --network=host -it paddlepaddle/paddle:latest-dev-cuda10.1-cudnn7-gcc82 /bin/bash
您也可以访问[DockerHub](https://hub.docker.com/r/paddlepaddle/paddle/tags/)获取与您机器适配的镜像。
# ctrl+P+Q可退出docker 容器,重新进入docker 容器使用如下命令
sudo docker container exec -it ppocr /bin/bash
2. 安装PaddlePaddle 2.0
pip3 install --upgrade pip
如果您的机器安装的是CUDA9或CUDA10,请运行以下命令安装
python3 -m pip install paddlepaddle-gpu==2.0.0 -i https://mirror.baidu.com/pypi/simple
如果您的机器是CPU,请运行以下命令安装
python3 -m pip install paddlepaddle==2.0.0 -i https://mirror.baidu.com/pypi/simple
更多的版本需求,请参照[安装文档](https://www.paddlepaddle.org.cn/install/quick)中的说明进行操作。
3. 克隆PaddleOCR repo代码
【推荐】git clone https://github.com/PaddlePaddle/PaddleOCR
如果因为网络问题无法pull成功,也可选择使用码云上的托管:
git clone https://gitee.com/paddlepaddle/PaddleOCR
注:码云托管代码可能无法实时同步本github项目更新,存在3~5天延时,请优先使用推荐方式。
4. 安装第三方库
cd PaddleOCR
pip3 install -r requirements.txt
注意,windows环境下,建议从这里下载shapely安装包完成安装,
直接通过pip安装的shapely库可能出现[winRrror 126] 找不到指定模块的问题。
中文OCR模型快速使用
- 环境配置
请先参考快速安装配置PaddleOCR运行环境。
注意:也可以通过 whl 包安装使用PaddleOCR,具体参考Paddleocr Package使用说明。
- inference模型下载
- 移动端和服务器端的检测与识别模型如下,更多模型下载(包括多语言),可以参考PP-OCR v2.0 系列模型下载
| 模型简介 | 模型名称 | 推荐场景 | 检测模型 | 方向分类器 | 识别模型 |
|---|---|---|---|---|---|
| 中英文超轻量OCR模型(8.1M) | ch_ppocr_mobile_v2.0_xx | 移动端&服务器端 | 推理模型 / 预训练模型 | 推理模型 / 预训练模型 | 推理模型 / 预训练模型 |
| 中英文通用OCR模型(143M) | ch_ppocr_server_v2.0_xx | 服务器端 | 推理模型 / 预训练模型 | 推理模型 / 预训练模型 | 推理模型 / 预训练模型 |
- windows 环境下如果没有安装wget,下载模型时可将链接复制到浏览器中下载,并解压放置在相应目录下
复制上表中的检测和识别的inference模型下载地址,并解压
mkdir inference && cd inference
# 下载检测模型并解压
wget {url/of/detection/inference_model} && tar xf {name/of/detection/inference_model/package}
# 下载识别模型并解压
wget {url/of/recognition/inference_model} && tar xf {name/of/recognition/inference_model/package}
# 下载方向分类器模型并解压
wget {url/of/classification/inference_model} && tar xf {name/of/classification/inference_model/package}
cd ..
以超轻量级模型为例:
mkdir inference && cd inference
# 下载超轻量级中文OCR模型的检测模型并解压
wget https://paddleocr.bj.bcebos.com/dygraph_v2.0/ch/ch_ppocr_mobile_v2.0_det_infer.tar && tar xf ch_ppocr_mobile_v2.0_det_infer.tar
# 下载超轻量级中文OCR模型的识别模型并解压
wget https://paddleocr.bj.bcebos.com/dygraph_v2.0/ch/ch_ppocr_mobile_v2.0_rec_infer.tar && tar xf ch_ppocr_mobile_v2.0_rec_infer.tar
# 下载超轻量级中文OCR模型的文本方向分类器模型并解压
wget https://paddleocr.bj.bcebos.com/dygraph_v2.0/ch/ch_ppocr_mobile_v2.0_cls_infer.tar && tar xf ch_ppocr_mobile_v2.0_cls_infer.tar
cd ..
解压完毕后应有如下文件结构:
├── ch_ppocr_mobile_v2.0_cls_infer
│ ├── inference.pdiparams
│ ├── inference.pdiparams.info
│ └── inference.pdmodel
├── ch_ppocr_mobile_v2.0_det_infer
│ ├── inference.pdiparams
│ ├── inference.pdiparams.info
│ └── inference.pdmodel
├── ch_ppocr_mobile_v2.0_rec_infer
├── inference.pdiparams
├── inference.pdiparams.info
└── inference.pdmodel
- 单张图像或者图像集合预测
以下代码实现了文本检测、方向分类器和识别串联推理,在执行预测时,需要通过参数image_dir指定单张图像或者图像集合的路径、参数det_model_dir指定检测inference模型的路径、参数rec_model_dir指定识别inference模型的路径、参数use_angle_cls指定是否使用方向分类器、参数cls_model_dir指定方向分类器inference模型的路径、参数use_space_char指定是否预测空格字符。可视化识别结果默认保存到./inference_results文件夹里面。
# 预测image_dir指定的单张图像
python3 tools/infer/predict_system.py --image_dir="./doc/imgs/11.jpg" --det_model_dir="./inference/ch_ppocr_mobile_v2.0_det_infer/" --rec_model_dir="./inference/ch_ppocr_mobile_v2.0_rec_infer/" --cls_model_dir="./inference/ch_ppocr_mobile_v2.0_cls_infer/" --use_angle_cls=True --use_space_char=True
# 预测image_dir指定的图像集合
python3 tools/infer/predict_system.py --image_dir="./doc/imgs/" --det_model_dir="./inference/ch_ppocr_mobile_v2.0_det_infer/" --rec_model_dir="./inference/ch_ppocr_mobile_v2.0_rec_infer/" --cls_model_dir="./inference/ch_ppocr_mobile_v2.0_cls_infer/" --use_angle_cls=True --use_space_char=True
# 如果想使用CPU进行预测,需设置use_gpu参数为False
python3 tools/infer/predict_system.py --image_dir="./doc/imgs/11.jpg" --det_model_dir="./inference/ch_ppocr_mobile_v2.0_det_infer/" --rec_model_dir="./inference/ch_ppocr_mobile_v2.0_rec_infer/" --cls_model_dir="./inference/ch_ppocr_mobile_v2.0_cls_infer/" --use_angle_cls=True --use_space_char=True --use_gpu=False
通用中文OCR模型
请按照上述步骤下载相应的模型,并且更新相关的参数,示例如下:
# 预测image_dir指定的单张图像
python3 tools/infer/predict_system.py --image_dir="./doc/imgs/11.jpg" --det_model_dir="./inference/ch_ppocr_server_v2.0_det_infer/" --rec_model_dir="./inference/ch_ppocr_server_v2.0_rec_infer/" --cls_model_dir="./inference/ch_ppocr_mobile_v2.0_cls_infer/" --use_angle_cls=True --use_space_char=True
- 注意:
- 如果希望使用不支持空格的识别模型,在预测的时候需要注意:请将代码更新到最新版本,并添加参数
--use_space_char=False。 - 如果不希望使用方向分类器,在预测的时候需要注意:请将代码更新到最新版本,并添加参数
--use_angle_cls=False。
- 如果希望使用不支持空格的识别模型,在预测的时候需要注意:请将代码更新到最新版本,并添加参数
更多的文本检测、识别串联推理使用方式请参考文档教程中基于Python预测引擎推理。
此外,文档教程中也提供了中文OCR模型的其他预测部署方式:
- 基于C++预测引擎推理
- 服务部署
- 端侧部署(目前只支持静态图)
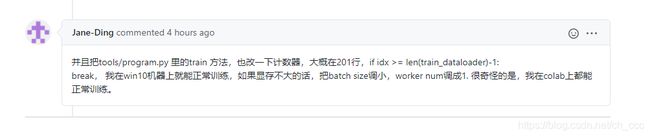
如果训练中,训练不了可以将batch_size和num_workers减小
batch_size_per_card: #将其参数减少
num_workers:
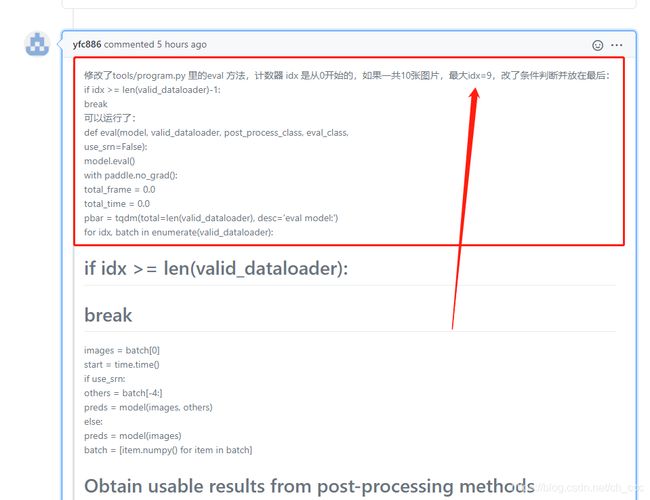
训练测试中遇到的问题:
- 训练检测器,当一个epoch后中断,也不报错
解决:
# program.py 大概201行 修改为if idx >= len(train_dataloader) -1
# train
if idx >= len(train_dataloader)-1: #原始 if idx >= len(train_dataloader)
break
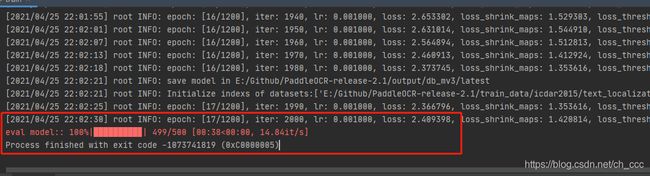
- eval model 报错
eval model:: 100%|█████████▉| 499/500 [00:38<00:00, 12.99it/s]
改完上面epoch错误后训练到eval model也会报错,大概339行也将if idx >= len(train_dataloader)改为if idx >= len(train_dataloader)-1
# eval
if idx >= len(train_dataloader)-1: #原始 if idx >= len(train_dataloader)
break
eval model:: 0%| | 0/36 [00:00 win10 训练中断 #2636