论文翻译:Real-Time High-Resolution Background Matting
论文地址:https://arxiv.org/pdf/2012.07810.pdf
文中所有图片与表格统一移动至了文末
实时高分辨率背景抠图
摘要
我们介绍了一种实时的、高分辨率的背景替换技术。使用现代GPU,在4K分辨率下,该技术的可以以30fps运行;在HD分辨率下,该技术可以以60fps运行。我们的技术基于背景抠图(Background Matting),即捕获一帧额外的背景并用于恢复alpha matte和前景层。主要的挑战是在实时处理高分辨率图像的同时,计算出高质量的alpha matte,并保留发丝级的细节。为了实现这一目标,我们采用了两个神经网络;一个base网络计算出一个低分辨率的结果,该结果由第二个网络在高分辨率下对选择性的修补进行完善。我们引入了两个大规模的视频和图像抠图数据集:VideoMatte240K,PhotoMatte13K/85。我们的方法与之前背景抠图的SOTA相比,产生了更高质量的结果,同时在速度和分辨率上都有很大的提升。我们的代码和数据可以在https://grail.cs.washington.edu/ projects/background-matting-v2/上找到。
1.引言
背景替换是电影特效中的主力军,现在也在Zoom、Google Meet和Microsoft Teams等视频会议工具中得到了广泛的应用。除了增加娱乐价值外,背景替换还可以增强隐私性,特别是在用户可能不想向通话中的其他人分享其位置和环境的细节的情况下。这种视频会议应用的一个关键挑战是,用户通常无法使用绿幕或其他物理道具,来做到像电影特效中的背景替换。
虽然现在很多工具都提供了背景替换功能,但它们在边界处会产生伪像,特别是在有头发或眼镜等细节的区域(图1)。相比之下,传统的图像抠图方法[6,16,17,30,9,2,7]可以提供更高质量的结果,但其不能实时、高分辨率地运行,而且经常需要用户完成手动输入。在本文中,我们介绍了第一个全自动、实时、高分辨率的抠图技术,在4K(3840×2160)30fps和HD(1920×1080)60fps下达到了SOTA。我们的方法依赖于捕获一个额外的背景图像来计算alpha matte和前景层,这种方法被称为背景抠图。
设计一个能够在高分辨率的人物视频上实现实时抠图的神经网络是非常具有挑战性的,特别是当发丝等细节十分重要的时候;相比之下,之前的SOTA[28]在8fps的情况下只能达到512×512。在如此高分辨率上训练一个深度网络是极其缓慢和内存密集型的。此外,它还需要大量高质量的alpha matte图像来进行泛化;而公开数据集[33,25]过于有限。
由于很难收集大量高质量手工裁剪的alpha matte数据集,我们使用一系列数据集来训练我们的网络,每个数据集都有不同的特点。为此,我们引入了VideoMatte240K和PhotoMatte13K/85,它们有高分辨率的alpha matte;以及用chromakey提取的前景层。我们首先在这些较大的alpha matte数据集上训练我们的网络,这些数据具有显著的人类姿势多样性,以学习鲁棒的先验。然后,我们在公开的数据集[33,25]上进行训练,这些数据集都是经过人工整理的,以学习精细的细节。
为了设计一个能够实时处理高分辨率图像的网络,我们注意到图像中只有相对较少的区域需要精细化处理。因此,我们引入了一个base网络,它可以在较低的分辨率下预测alpha matte和前景层,以及一个预测误差图,它指定了可能需要高分辨率精细化的区域。然后,使用一个refinement网络将低分辨率的结果和原始图像结合在一起,只在选定区域生成高分辨率的输出。
我们在充满挑战的真实世界视频和人物图像上实时做到了SOTA背景抠图结果。我们会公布VideoMatte240K,PhotoMatte85数据集以及我们的模型实现。
2.相关工作
背景替换可以通过分割(segmentation)或抠图(matting)来实现。虽然二元分割速度快、效率高,但所产生的合成图会产生令人反感的伪像。alpha matting可以产生视觉上令人愉悦的合成图,但通常需要人工标注或已知的背景图像。在本节中,我们将讨论用分割或抠图进行背景替换的相关工作。
分割(Segmentation): 实例和语义分割方面的文献浩如烟海,超出了本文的讨论范围,所以我们只回顾最相关的工作。Mask RCNN[11]仍然是实例分割的首选,而DeepLabV3+[5]是语义分割网络的SOTA。我们将DeepLabV3[4]和DeepLabV3+中的Atrous Spatial Pyramid Pooling(ASPP)模块纳入我们的网络中。由于分割算法往往会产生粗糙的边界(尤其是在更高的分辨率下),Kirillov等人提出了PointRend[15],它对边缘附近的点进行采样,并迭代完善分割。这在高图像分辨率下产生高质量的分割,而内存和计算量却大大降低。我们的方法通过学习精细区域选择和改善接受野的卷积细化架构,将这一思想应用到了抠图领域。在最近的工作中,人物分割与解析的具体应用也受到了相当的关注[34,19]。
基于三元图的抠图(Trimap-based matting): 传统的(非学习型)抠图算法[6,16,17,30,9,2,7]需要用到
人工标注(一个三元图),并求解三元图"未知区域"中的alpha matte。Wang和Cohen[32]的调查中回顾了不同的抠图技术。Xu等人[33]引入了一个抠图数据集,并使用一个带有三元图输入的深度网络来预测alpha matte。最近的许多方法都依赖于这个数据集来学习抠图,例如,Context-Aware Matting[13]、Index Matting[21]、Sampling based matting[31]和基于opacity propagation based matting[18]。虽然这些方法的性能取决于标注的质量,但最近的一些方法考虑了粗糙[20]或存在错误人工标注[3]的情况下来预测alpha matte。
无外部输入的抠图(Matting without any external input): 最近的方法也关注在没有任何外部输入对人像进行抠图。由于人像与人体全身图像相比,变化较小,因此,不使用三元图的人像抠图[36,29]是比较成功的应用之一。自然图像的软分割也曾在[1]中进行过探索。最近的方法,如Late Fusion Matting[35]和HAttMatting[25],目标直接从图像中求解alpha matte,但这些方法往往不能通用,如[28]所示。
已知自然背景的抠图(Matting with a known natural background): 曾在[24]、Bayesian matting[7]和Poisson matting[30,10]中进行过已知自然背景的抠图的探索,这也需要一个三元图。最近Sengupta等人[28]引入了背景抠图(Background Matting,BGM),其捕获了一个额外的背景图像,它提供了一个重要的线索来预测alpha matte和前景层。虽然这种方法展示了高质量的抠图结果,但该架构仅限于512×512的分辨率,并且只能以8fps的速度运行。相比之下,我们介绍了一种实时统一的抠图架构,它可以在30fps的4K视频和60fps的HD视频上运行,并产生比BGM更高质量的结果。
3.数据集
由于要获得大规模、高分辨率、高质量的抠图数据集是非常困难的,其中的alpha matte是由手工处理的,我们依靠多个数据集,包括我们自己的收藏和公开的数据集。
公开数据集: Adobe Image Matting(AIM)数据集[33]提供了269个人类训练样本和11个测试样本,平均分辨率约为1000×1000。我们还使用了Distinctions-646[25]的一个人类专用子集,包括362个训练样本和11个测试样本,平均分辨率约为1700×2000。这些抠图是手工创建的,因此是高质量的。然而631张训练图像不足以在高分辨率下学习人类姿势的巨大变化和更精细的细节,因此我们引入了2个额外的数据集。
VideoMatte240K: 我们收集了484个高分辨率的绿幕视频,并通过Adobe After Effects生成了总共240,709帧单独的alpha matte和前景。这些视频都是作为素材购买或在网上找到的免版税素材。384个视频为4K分辨率,100个为HD分辨率。我们将视频按479 : 5分割,形成训练集和验证集。数据集由大量的人类主体、服装和姿势组成,对训练鲁棒模型很有帮助。我们将把提取的 alpha mattes和前景作为数据集对外公布。据我们所知,到目前为止,我们的数据集比所有现有的公开的抠图数据集都要大,它是第一个公开的视频抠图数据集,其中包含了连续的帧序列而不是静止的图像,这可以在未来的研究中用来开发包含运动信息的模型。
PhotoMatte13K/85: 我们获得了13665张用摄影棚质量的灯光和摄像机在绿屏前拍摄的图像集合,以及通过chromakey算法提取的抠图,并进行手动调整与错误修复。我们将图像按13165 : 500分割,形成训练和验证集。这些抠图包含的姿势范围很窄,但分辨率很高,平均约为2000×2500,并包含诸如单个发丝的细节。我们将这个数据集称为PhotoMatte13K。然而,隐私和许可问题使我们无法分享这套数据集;因此,我们还收集了另外一套85张质量类似的抠图作为测试集,我们将其作为PhotoMatte85进行公布。在图2中,我们展示了VideoMatte240K和PhotoMatte13K/85数据集的例子。
我们从 Flickr 和 Google 中抓取 8861 张高分辨率背景图片,并按 8636 : 200 : 25 分割,用于构建训练集、验证集和测试集。我们将公布测试集,其中所有图片都有CC授权(详见附录)。
4.方法
给定一个图像I和捕捉到的背景 B B B,我们预测alpha matte α \alpha α和前景 F F F,这将使我们可以通过 I ′ = α F + ( 1 − α ) B ′ I^{\prime}=\alpha F+(1-\alpha) B^{\prime} I′=αF+(1−α)B′在任何新的背景上合成,其中 B ′ B^{\prime} B′是新的背景。我们不直接求解前景,而是求解前景残差 F R = F − I F^{R}=F-I FR=F−I,然后,可以通过将 F R F^{R} FR加入到输入图像 I I I中,并进行适当的收缩: F = max ( min ( F R + I , 1 ) , 0 ) F=\max \left(\min \left(F^{R}+I, 1\right), 0\right) F=max(min(FR+I,1),0),来恢复 F F F。 我们发现这个公式提高了学习效果,并允许我们通过上采样将低分辨率的前景残差应用到高分辨率的输入图像上,改善我们的架构,如后所述。
高分辨率下的抠图充满挑战,因为应用深度网络直接导致不切实际的计算和内存消耗。如图4所示,人类的抠图通常是非常稀疏的,其中大面积的像素属于背景( α = 0 \alpha = 0 α=0)或前景( α = 1 \alpha = 1 α=1),只有少数区域涉及更精细的细节,例如,头发、眼镜和人的轮廓周围。因此,我们没有只设计一个对高分辨率图像进行操作的网络,而是引入了两个网络,一个在较低分辨率下操作,另一个在原始分辨率下根据前一个网络的预测对选定的区域进行操作。
该架构由一个基础网络 G b a s e G_{base} Gbase和一个细化网络 G r e f i n e G_{refine} Grefine组成。给定原始图像 I I I和捕获的背景 B B B,我们首先对 I c I_c Ic和 B c B_c Bc进行系数为 c c c的下采样。基础网络 G b a s e G_{base} Gbase将 I c I_c Ic和 B c B_c Bc作为输入,并预测粗粒度的alpha matte α c \alpha _c αc、前景残差 F c R F_c^R FcR、误差预测图 E c E_c Ec和隐藏特征 H c H_c Hc。然后,细化网络 G r e f i n e G_{refine} Grefine利用 H c H_c Hc、 I I I和 B B B,只在预测误差 E c E_c Ec较大的区域对 α c \alpha _c αc和 F c R F_c^R FcR进行细化,并在原始分辨率下产生 α \alpha α和前景残差 F R F^R FR。我们的模型是完全卷积的,并且经过训练可以在任意尺寸和长宽比上工作。
4.1.基础网络
基础网络(base network)是一个受DeepLabV3[4]和DeepLabV3+[5]架构启发的全卷积编码器-解码器(encoder-decoder)网络,它们在2017年和2018年的语义分割任务上取得了SOTA。我们的基础网络由三个模块组成:Backbone、ASPP和Decoder。
我们采用ResNet-50[12]作为编码器主干,这可以用ResNet-101和MobileNetV2[27]替代,以在速度和质量之间进行权衡。我们按照DeepLabV3的方法,在主干后采用ASPP(Atrous Spatial Pyramid Pooling)模块。ASPP模块由多个膨胀卷积滤波器组成,不同的膨胀率有3,6和9。我们的解码器网络在每一步都应用了双线性上采样,与来自主干的跳连接并联,然后是3×3卷积、Batch Normalization[14]和ReLU激活[22] (最后一层除外)。解码器网络输出粗粒度的alpha matte α c \alpha _c αc、前景残差 F c R F_c^R FcR、误差预测图 E c E_c Ec和一个32通道的隐藏特征 H c H_c Hc。隐藏特征 H c H_c Hc包含了对细化网络有用的全局上下文。
4.2.细化网络
细化网络(refinement network)的目标是减少冗余计算,恢复高分辨率的抠图细节。基础网络对整个图像进行操作,而细化网络只对误差预测图 E c E_c Ec选择的块进行操作。我们执行两阶段的细化,首先是原始分辨率的 1 2 \frac{1}{2} 21,然后再全分辨率。在推理过程中,我们对 k k k个块进行细化, k k k可以事先设定,也可以根据阈值设定,在质量和计算时间之间进行权衡。
给定原始分辨率 1 c \frac{1}{c} c1的粗误差预测图 E c E_c Ec,我们首先将其重新采样到原始分辨率 E 4 E_4 E4的 1 4 \frac{1}{4} 41,即图上的每个像素对应原始分辨率上的一个4×4的块。我们从 E 4 E_4 E4中选取预测误差最大的 k k k个像素来表示k个4×4块的位置,这些位置将被我们的细化模块细化。原始分辨率下的细化像素总数为 16 k 16k 16k。
我们执行一个两阶段的细化过程。首先,我们对粗输出,即alpha matte α c \alpha _c αc、前景残差 F c R F_c^R FcR和隐藏特征 H c H_c Hc,以及输入图像 I I I和背景 B B B进行双线性重采样,使其达到原始分辨率的 1 2 \frac{1}{2} 21,并将其连成特征。然后我们在从 E 4 E_4 E4中选取的错误位置周围裁剪出8×8的块,并分别通过两层3×3卷积(带valid padding)、Batch Normalization和ReLU,将块的维度降低到4×4。然后将这些中间特征再次上采样到8×8,并与从原始分辨率、输入I和相应位置的背景 B B B中提取的8×8块进行连通。然后,我们应用额外的两层3×3卷积(带valid padding),Batch Normalization和ReLU(除了最后一层),以获得4×4的alpha matte和前景残差结果。最后,我们将粗alpha matte α c \alpha _c αc和前景残差 F c R F_c^R FcR上采样到原始分辨率,并换入各自已经细化的4×4块,得到最终的alpha matteα和前景残差 F R F^R FR,整个架构如图3所示。具体实现方式见附录。
4.3.训练
所有的抠图数据集都提供了一个alpha matte和一个前景层,我们将其合成到多个高分辨率背景上。我们采用了多种数据增强技术,以避免过拟合,并帮助模型泛化到具有挑战性的现实世界中。我们对前景层和背景层分别进行了非线性变换、水平翻转、亮度、色调和饱和度调整、模糊、锐化和随机噪声等数据增强。我们还略微移动背景以模拟错位,并创建人工阴影,以模拟主体如何在现实环境中投射阴影(详见附录)。我们随机裁剪每个minibatch中的图像,使高度和宽度分别均匀分布在1024和2048之间,以支持在任何分辨率和纵横比下进行推理。
为了学习 α \alpha α与ground-truth α ∗ {\alpha ^ * } α∗,我们在整个alpha matte与其(Sobel)梯度上使用L1损失: L α = ∥ α − α ∗ ∥ 1 + ∥ ∇ α − ∇ α ∗ ∥ 1 ( 1 ) \mathcal{L}_{\alpha}=\left\|\alpha-\alpha^{*}\right\|_{1}+\left\|\nabla \alpha-\nabla \alpha^{*}\right\|_{1} \quad (1) Lα=∥α−α∗∥1+∥∇α−∇α∗∥1(1) 我们从预测的前景残差 F R F^R FR中获得前景层,使用 F = max ( min ( F R + I , 1 ) , 0 ) F=\max \left(\min \left(F^{R}+I, 1\right), 0\right) F=max(min(FR+I,1),0)。我们只对 α ∗ > 0 {\alpha ^ * >0} α∗>0的像素计算L1损失: L F = ∥ ( α ∗ > 0 ) ∗ ( F − F ∗ ) ) ∥ 1 ( 2 ) \left.\mathcal{L}_{F}=\|\left(\alpha^{*}>0\right) *\left(F-F^{*}\right)\right) \|_{1} \quad (2) LF=∥(α∗>0)∗(F−F∗))∥1(2) 其中, α ∗ > 0 {\alpha ^ * >0} α∗>0是布尔表达式。
对于细化区域的选择,我们将ground truth误差图定义为 E ∗ = ∣ α − α ∗ ∣ E^{*}=\left|\alpha-\alpha^{*}\right| E∗=∣α−α∗∣。然后我们计算预测误差图和ground truth误差图之间的均方误差作为损失: L E = ∥ E − E ∗ ∥ 2 ( 3 ) \mathcal{L}_{E}=\left\|E-E^{*}\right\|_{2} \quad (3) LE=∥E−E∗∥2(3) 这种损失鼓励预测误差图拥有更大的值,在预测 α \alpha α和ground truth α \alpha α之间的差异很大。在训练过程中,随着预测 α \alpha α的提高,ground truth误差图会也随着迭代而变化。随着时间的推移,误差图逐渐收敛,并预测复杂区域的高误差,例如头发。如果简单地进行上采样,会导致糟糕的合成。
基础网络 ( α c , F c R , E c , H c ) = G base ( I c , B c ) \left(\alpha_{c}, F_{c}^{R}, E_{c}, H_{c}\right)=G_{\text {base }}\left(I_{c}, B_{c}\right) (αc,FcR,Ec,Hc)=Gbase (Ic,Bc)在原始图像分辨率的 1 c \frac{1}{c} c1处工作,并用以下损失函数进行训练: L base = L α c + L F c + L E c ( 4 ) \mathcal{L}_{\text{base}}=\mathcal{L}_{\alpha_{c}}+\mathcal{L}_{F_{c}}+\mathcal{L}_{E_{c}} \quad (4) Lbase=Lαc+LFc+LEc(4) 细化网络 ( α , F R ) = G refine ( α c , F c R , E c , H c , I , B ) (\alpha ,{F^R}) = {G_{ {\text{refine }}}}\left( { {\alpha _c},F_c^R,{E_c},{H_c},I,B} \right) (α,FR)=Grefine (αc,FcR,Ec,Hc,I,B)的训练方法是: L refine = L α + L F ( 5 ) \mathcal{L}_{\text {refine }}=\mathcal{L}_{\alpha}+\mathcal{L}_{F} \quad (5) Lrefine =Lα+LF(5) 我们在ImageNet和Pascal VOC数据集上初始化我们模型的主干和ASPP模块,并使用DeepLabV3权重进行语义分割的预训练。我们首先训练基础网络,直到收敛,然后添加细化模块并联合训练。在训练过程全程,我们使用Adam优化器,并 c = 4 c = 4 c=4, k = 5000 k = 5000 k=5000。在只训练基础网络时,我们对主干、ASPP和解码器设置batch size为8,学习率分别为[1e-4,5e-4,5e-4]。当联合训练时,主干、ASPP、解码器和细化模块分别设置batch size为4,学习率为[5e-5、5e-5、1e-4、3e-4]。
我们按照以下顺序在多个数据集上训练我们的模型。首先,我们只在VideoMatte240K上训练基础网络Gbase,然后在VideoMatte240K上联合训练整个模型 G b a s e G_{base} Gbase和 G r e f i n e G_{refine} Grefine,这使得模型对各种主体和姿势都很鲁棒。接下来,我们在PhotoMatte13K上联合训练我们的模型,以提高高分辨率的细节。最后,我们在Distinctions-646上联合训练我们的模型。该数据集只有362个独一无二的训练样本,但它的质量是最高的,并且包含了人工标注的前景,这对提高我们模型产生的前景质量非常有帮助。我们省略了在AIM数据集上的训练,作为可能的第四阶段,其最终只用于测试;因为使用它会导致质量下降,正如我们在第6节的消融研究中所显示的那样。
5.实验评估
我们将我们的方法与两种基于三元图的方法:深度图像抠图(Deep Image Matting,DIM)[33]和FBA抠图(FBA)[8],以及一种基于背景的方法:背景抠图(Background Matting,BGM)[28]进行比较。DIM的输入分辨率被固定为320×320,而FBA的输入分辨率由于内存限制,我们将其设置为HD左右。我们另外在数据集上训练BGM模型,并将其表示为BGMa(BGM改)。
我们的评估对照片采用 c = 4 c=4 c=4, k = 20000 k=20000 k=20000,对HD视频采用 c = 4 c=4 c=4, k = 5000 k=5000 k=5000,对4K视频采用 c = 8 c=8 c=8, k = 20000 k=20000 k=20000,其中 c c c是基础网络的下采样因子, k k k是得到细化的块数量。
5.1.在合成数据集上的评估
我们通过将AIM、Distinctions和PhotoMatte85数据集的测试样本分别合成到每个样本的5张背景图像上,构建测试基准。我们应用轻微的背景错位、颜色调整和噪声来模拟有缺陷的背景捕捉。我们使用阈值和形态学操作从ground truth α \alpha α生成三元图。我们使用[26]中的指标来评估抠图输出: α \alpha α和前景的MSE(均方误差),SAD(绝对差之和),Grad(空间梯度度量),以及仅 α \alpha α的Conn(连通性)。所有的MSE值都是以103为尺度,所有的指标都只在未知区域的trimap上计算,如上所述。前景MSE仅在ground truth alpha α ∗ > 0 {\alpha ^ * >0} α∗>0的地方额外度量。
表1显示,在所有数据集中,我们的方法都优于现有的基于背景的BGM方法。我们的方法比SOTA基于trimap的FBA方法稍差,但后者需要仔细标注手工trimap,比我们的方法慢得多,在后面的性能比较中可以看出。
5.2.在录制视频上的评估
虽然在上述数据集上的定量评估达到了量化不同算法性能的目的,但评估这些方法在无约束的真实数据上的表现是很重要的。为了在真实数据上进行评估,我们采集了一些包含不同姿势和周围环境的主体的照片和视频。这些视频是在三脚架上用消费级智能手机(三星S10+和iPhone X)与专业相机(索尼α7s II)拍摄的,分辨率为HD和4K。照片的拍摄分辨率为4000×6000。我们还使用了一些在BGM论文中公开的HD视频,来与我们的方法进行比较。
为了在实时场景下进行公平的比较,在无法制作手工trimap的情况下,我们按照[28]的建议,通过DeepLabV3+的变形分割结果来构建trimap。我们展示了两种trimap的结果,将使用这种全自动trimap的FBA记做为FBAauto。
图5显示,与其他方法相比,我们的方法在头发和边缘周围产生了更清晰、更细致的结果。由于我们的细化是在原生分辨率下操作的,所以质量相对于BGM要好得多,因为BGM调整了图像的大小,只能在512×512的分辨率下进行处理。FBA与手工trimap一起,在头发细节周围产生了出色的结果,然而无法在标准GPU上评估高于HD左右的分辨率。当FBA应用在用分割生成的自动trimap上时,经常会出现较大的伪像,主要是由于分割有问题。
我们从BGM论文分享的测试视频和我们采集的视频和照片中提取34帧来创建一个用户研究。40名参与者被呈现在一个互动界面上,以随机顺序显示每个输入图像以及由BGM和我们的方法产生的抠图。他们被鼓励放大细节,并要求评价其中一个抠图为 “好得多”,“稍好”,或 “类似”。结果,如表2所示,展示出相比BGM显著的质的改进。59%的情况下参与者认为我们的算法更好,而BGM只有23%。对于4K和更大的锐利样本,我们的方法在75%的情况下比BGM的15%更受欢迎。
5.3.性能比较
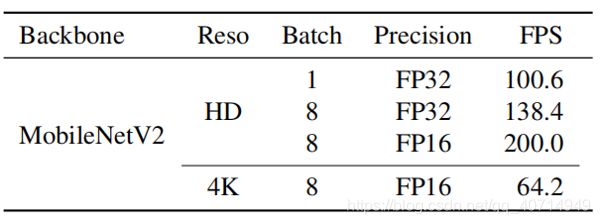
表3和表4显示,我们的方法比BGM更小、更快。与BGM相比,我们的方法只包含55.7%的参数。我们的方法可以在Nvidia RTX 2080 TI GPU上实现HD 60fps和4K 30fps(batch size为1),这对许多应用被认为是实时的。与只能以7.8fps处理512×512分辨率的BGM相比,这是一个显著的加速。如果换成MobileNetV2作为主干,性能可以进一步提升,达到4K 45fps和HD 100fps。更多的性能结果,如调整细化选择参数k和使用更大的batch size,都包含在消融研究和附录中。
5.4.实际应用
Zoom实现: 我们构建了一个Zoom插件,它可以拦截网络摄像头的输入,收集一个无人(背景)镜头,然后进行实时视频抠图和合成,将结果流回Zoom调用中。我们在Linux中使用720p网络摄像头进行测试。该升级在实际会议中引起了好评,证明了其在实际环境中的实用性。
与绿幕的比较: 使用绿幕进行色度抠像是创造高质量抠图的最常用方法。然而,它要求整个屏幕的光照均匀,背景和主体分离,以避免投射阴影。在图6中,我们将我们的方法与在相同照明下使用业余绿幕设置的色度抠像进行比较。我们发现,在光线不均匀的环境下,我们的方法优于为绿幕设计的方法。
6.消融研究
数据集的作用: 我们在多个数据集上进行训练,每个数据集都带来了独特的特征,帮助我们的网络在高分辨率下产生高质量的结果。表5显示了我们的方法在从训练流水线中添加或删除一个数据集下的指标。我们发现添加AIM数据集作为可能的第4阶段会造成指标恶化,即使在使用AIM本身进行测试的情况下也会恶化。我们认为这是因为AIM数据集中的样本与Distinctions相比,分辨率和质量都较低,样本数量少可能造成了过拟合。从训练流水线中移除VideoMatte240K、PhotoMatte13K和Distinctions数据集都会导致更差的指标,证明这些数据集对提高模型的质量有帮助。
基础网络的作用: 我们实验用ResNet-101和MobileNetV2代替ResNet-50作为基础网络中的编码器主干。表6中的指标显示,ResNet-101在某些指标上比ResNet-50有轻微的改进,而在其他指标上表现较差。这说明ResNet-50通常足以获得最佳质量。而MobileNetV2在所有指标上都比ResNet-50差,但如表3和表4所示,它比ResNet-50快得多,体积也小得多,而且仍能获得比BGM更好的指标。
细化网络的作用: 我们的细化网络图7中的粗结果中提高了细节清晰度,即使在4K分辨率下也是有效的。图8显示了增加和减少细化区域的效果。只在图像分辨率的5%到10%的范围内进行细化,就可以实现大部分的改善。表7显示,与细化整个图像相比,只细化选定的块可以提供显著的加速。
基于块的细化与基于点的细化: 我们的细化模块使用3×3的卷积核栈,为每个输出像素创建一个13×13的接受野。另一种方法是只使用1×1的卷积核对点进行细化,这将导致我们的方法产生2×2的接受野。表6显示,3×3的核由于接受野较大,可以达到比基于点的核更好的指标。
局限性: 我们的方法可以通过在每一帧的背景上应用同构对齐来用于手持输入,但它被限制在小运动上。其他常见的限制如图 9 所示。我们建议使用我们的方法时使用一个简单的纹理背景,固定的曝光/焦距/白平衡设置和三脚架,以获得最佳效果。
7.结论
我们提出了一种实时、高分辨率的背景替换技术,它可以在4K 30fps和HD 60fps下运行。我们的方法只需要一个输入图像和一个预先捕获的背景图像,这在许多应用中很容易获得。我们提出的架构在高分辨率下只有效地细化容易出错的区域,从而减少了冗余计算,使实时高分辨率抠图成为可能。我们引入了两个新的大规模抠图数据集,帮助我们的方法推广到现实生活中的场景。我们的实验表明,我们的方法在背景抠图上创造了新的SOTA。我们通过将我们的结果以流式传输到Zoom来证明我们方法的实用性,并实现了更真实的虚拟电话会议。
道德声明: 我们的首要目标是通过视频通话中的背景替换,实现创造性的应用,给用户提供更多的隐私选择。然而,我们意识到图像编辑也可能被用于负面目的,这可以通过水印和其他商业应用中的安全技术得到缓解。
附录
A.综述
我们在本附录中提供了更多细节。在Sec.B中,我们描述了我们的网络架构和实现细节。在Sec.C中,我们阐明了我们使用哪些关键字来抓取背景图像。在Sec.D中,我们解释了我们如何训练我们的模型,并展示了我们数据增强的细节。在Sec.E中,我们展示了关于我们方法性能的额外指标。在Sec.F中,我们展示了我们用户研究中使用的所有定性结果,以及每个样本的平均得分。
B.网络
B.1.结构
主干: ResNet和MobileNetV2都采用了原始的实现方式,但做了一些小的修改。我们改变了第一个卷积层,使输入和背景图像都接受6个通道。我们遵循DeepLabV3的方法,将最后一个下采样块用膨胀卷积来维持16的输出步长。为了简单起见,我们不使用DeepLabV3中提出的多网格膨胀技术。
ASPP: 我们遵从DeepLabV3中提出的ASPP模块的原始实现。我们的实验表明,将膨胀率设置为(3,6,9)会产生更好的结果。
解码器: C B R 128 − C B R 64 − C B R 48 − C 37 CBR128 - CBR64 - CBR48 - C37 CBR128−CBR64−CBR48−C37 "CBRk"表示 k k k个3×3卷积滤波器,具有相同的填充,无偏置,然后进行Batch Normalization和ReLU。"Ck "表示 k k k个具有相同填充和偏置的3×3卷积滤波器。在每一次卷积之前,解码器使用规模因子为2的双线性上采样,并与主干网进行相应跳连接。37个通道的输出包括1个通道的 α c \alpha _c αc、3个通道的前景残差 F c R F_c^R FcR、1个通道的误差图 E c E_c Ec和32个通道的隐藏特征 H c H_c Hc。我们将 α c \alpha _c αc和 E c E_c Ec收缩到0至1,对 H c H_c Hc应用ReLU。
细化器: F i r s t s t a g e : C ∗ B R 24 − C ∗ B R 16 First{\text{ }}stage:{\text{ }}C*BR24{\text{ }} - {\text{ }}C*BR16 First stage: C∗BR24 − C∗BR16 S e c o n d s t a g e : C ∗ B R 12 − C ∗ 4 Second{\text{ }}stage:{\text{ }}C*BR12{\text{ }} - {\text{ }}C*4 Second stage: C∗BR12 − C∗4 "C ∗ * ∗BRk "和 "C ∗ * ∗k "遵循上述相同的定义,只是卷积不使用填充。
细化器首先将粗输出 α c \alpha _c αc、 F c R F_c^R FcR、 H c H_c Hc和输入图像 I I I、 B B B重新采样为 1 2 \frac{1}{2} 21分辨率,并将它们连成 [ n × 42 × h 2 × w 2 ] \left[n \times 42 \times \frac{h}{2} \times \frac{w}{2}\right] [n×42×2h×2w]特征。根据误差预测Ec,我们裁剪出前k个最容易出错的块 [ n k × 42 × 8 × 8 ] [n k \times 42 \times 8 \times 8] [nk×42×8×8]。应用第一阶段后,块维度变成 [ n k × 16 × 4 × 4 ] [n k \times 16 \times 4 \times 4] [nk×16×4×4]。我们用最近邻上采样法对块进行上采样,并与 I I I和 B B B中相应位置的块进行连接,形成 [ n k × 22 × 8 × 8 ] [n k \times 22 \times 8 \times 8] [nk×22×8×8]特征。经过第二阶段,块维度变成 [ n k × 4 × 4 × 4 ] [n k \times 4 \times 4 \times 4] [nk×4×4×4]。4个通道分别是 α \alpha α和前景残差。最后,我们对粗 α c \alpha _c αc和 F c R F_c^R FcR进行双线性上采样,使其达到全分辨率,并将细化后的块替换到相应位置,形成最终的输出 α \alpha α和 F R F^R FR。
B.2.实现
我们在PyTorch[23]中实现了我们的网络。块的提取和替换可以通过原生的向量化操作来实现,以获得最大的性能。我们发现,PyTorch的最近邻上采样操作在小分辨率块上比双线性上采样快得多,所以我们在上采样块时使用它。
C.数据集
VideoMatte240K 该数据集包含484个视频片段,共240709帧。每段视频的平均帧数为497.3,中位数为458.5。最长的片段有1500帧,最短的片段有124帧。图10显示了VideoMatte240K数据集的更多例子。
背景: 我们用来爬取背景图片的关键词是:机场内部、阁楼、酒吧内部、浴室、海滩、城市、教堂内部、教室内部、空城、森林、车库内部、健身房内部、房子户外、内部、厨房、实验室内部、景观、演讲厅、商场内部、夜总会内部、办公室、雨林、屋顶、体育场内部、剧院内部、火车站、仓库内部、工作场所内部。
D.训练
表8记录了我们最终模型在不同数据集上的训练顺序、epoch和小时数。我们在只训练基础网络时使用1张RTX 2080 TI,在联合训练网络时使用2张RTX 2080 TI。
此外,我们还使用混合精度训练,以实现更快的计算速度和更少的内存消耗。当使用多个 GPU 时,我们会应用数据并行技术将 minibatch 分割到多个 GPU 上,并切换到使用 PyTorch 的同步Batch Normalization来跟踪跨 GPU 的batch统计数据。
D.1.数据增强
对于每一个alpha和前景训练样本,我们以"zip"的方式旋转与背景进行合成,形成一个epoch。例如,如果有60个训练样本和100张背景图像,那么一个epoch就是100张图像,其中60个样本首先与前60张背景图像配对,然后前40个样本再与其余40张背景图像配对。当一组图像用完后,旋转就停止了。由于我们使用的数据集大小差别很大,所以用这种策略来概括一个epoch的概念。
我们对每个样本的前景和背景分别应用随机旋转(±5deg)、缩放(0.3∼1)、平移(±10%)、剪切(±5deg)、亮度(0.85∼1.15)、对比度(0.85∼1.15)、饱和度(0.85∼1.15)、色调(±0.05)、高斯噪声(σ2≤0.03)、盒状模糊和锐化。然后我们使用 I = α F + ( 1 − α ) B I=\alpha F+(1-\alpha) B I=αF+(1−α)B对输入图像进行合成。
我们另外应用随机旋转(±1deg)、平移(±1%)、亮度(0.82~1.18)、对比度(0.82~1.18)、饱和度(0.82~1.18)和色调(±0.1),只在背景上应用30%次。这种输入 I I I和背景 B B B之间的小错位增加了模型在现实生活捕捉上的鲁棒性。
我们还发现创建人工阴影可以提高模型的鲁棒性,因为现实生活中的主体经常会在环境中投射阴影。在 I I I上创建阴影的方法是,按照被摄体的轮廓30%的范围,将被摄体后面的一些图像区域变暗。合成图像的例子如图11所示。最下面一行是阴影增强的例子。
D.2.测试增强
对于AIM和Distinctions,它们各有11个人类测试样本,我们将每个样本与背景测试集的5个随机背景配对。对于有85个测试样本的PhotoMatte85,我们只用1个背景对每个样本进行配对。我们使用[26]中描述的方法和指标来评估55、55和85图像的结果集。
我们仅对背景 B B B应用随机子像素平移(±0.3像素)、随机伽玛(0.85~1.15)和高斯噪声( μ \mu μ=±0.02,0.08≤σ2≤0.15),以模拟错位。
用作基于trimap的方法的输入和定义误差度量区域的trimap是通过在0.06和0.96之间对grouth truth alpha进行阈值化,然后使用3×3的圆核对其进行10次迭代的膨胀,再进行10次迭代的腐蚀得到的。
E.性能
表9显示了我们的方法在两个Nvidia RTX 2000系列GPU上的性能:旗舰级RTX 2080 TI和入门级RTX 2060 Super。入门级GPU产生的FPS较低,但对于许多实时应用来说,仍在可接受的范围内。此外,表10显示,切换到更大的batch size和更低的精度可以显著提高FPS。
F.额外结果
在图13、14、15中,我们展示了用户研究中所有34个例子,以及他们的平均评分和不同方法的结果。图12显示了我们用户研究的Web UI。
本文所有图片与表格
图1: 当前的视频会议工具,如Zoom,可以采取输入信号(左)并替换背景,通常会引入伪像,如中间结果所示,头发和眼镜的特写中仍然有原始背景的残留。利用一帧没有主体的视频(最左边的插图),我们的方法可以产生实时的、高分辨率的背景抠图,而没有那些常见的伪像。右边的图片是我们的结果与相应的特写,是我们Zoom插件实现的截图。

图2: 我们引入了两个大规模的抠图数据集,包含240k单独帧和13k单独照片。

图3: 基础网络 G b a s e G_{base} Gbase(蓝色)对下采样输入进行操作,以产生粗结果和误差预测图。细化网络 G r e f i n e G_{refine} Grefine(绿色)选择容易出错的块,并将其细化至全分辨率。

图4: 我们只对易错的区域(b)进行细化,其余的直接上采样以节省计算量。

图5: 真实图像上的定性比较。我们以最小的用户输入在高分辨率下产生了卓越的结果。虽然FBA具有竞争力,但在基于分割的有误trimap的全自动应用中,它失效了。

图6: 当使用业余绿幕设置时,我们产生的效果比chroma-key软件更好。

图7: 细化的效果,从粗到HD和4K。

图8: Distinctions测试集上的指标,图像细化区域的百分比。Grad和Conn的比例为10-3。
 图9: 失效案例。当被摄体在背景上投下大量阴影或与背景颜色相匹配时(上),以及当背景高度纹理化时(下),我们的方法就会失效。
图9: 失效案例。当被摄体在背景上投下大量阴影或与背景颜色相匹配时(上),以及当背景高度纹理化时(下),我们的方法就会失效。
 图10: 来自VideoMatte240K数据集的更多例子。
图10: 来自VideoMatte240K数据集的更多例子。

图11: 带有增强的训练样本。底部一行是带有阴影增强的样本。实际样本有不同的分辨率和长宽比。

图12: 我们用户研究的web UI。用户会看到原始图像和来自我们的和BGM方法的两个结果图像。用户得到的指令是给一种算法打分,是 “好得多”、“稍好”,还是两种算法"相似"。

图13: 其他定性比较(1/3)。包括我们和BGM之间的平均用户评分。得分-10表示BGM “好得多”,-5表示BGM “稍好”,0表示"类似",+5表示我们 “稍好”,+10表示我们"好得多"。我们的方法平均得到3.1分。

图14: 其他定性比较(2/3)。

图15: 其他定性比较(3/3)。

表1: 对不同数据集的定量评估。†表示需要人工trimap的方法。

表2: 用户研究结果:我们的研究结果与BGM的比较。

表3: 在 Nvidia RTX 2080 TI 上测得的速度,在 FP32 精度和batch size为1的情况下,PyTorch 模型通过时没有数据传输。GMac 不考虑插值和裁剪操作。为了便于测量,BGM和FBAauto使用经过改编的PyTorch DeepLabV3+实现,以ResNet101为主干进行分割。

表4: 模型大小比较。BGM和FBAauto使用DeepLabV3+与Xception主干进行分割。
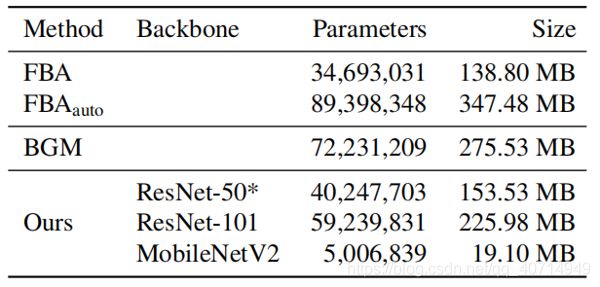
表5: 在训练流水线中删除或追加数据集的效果,在AIM测试集上评估。

表6: 在Distinctions测试集上的主干和细化内核的比较。

表7: 不同 k k k值的性能。用我们的方法测量,ResNet-50主干在HD下的性能。

表8: 不同数据集上的训练时间和小时数。以ResNet-50为主干测量。

表9: 不同GPU上的性能。以batch size为1和FP32精度测量。

表10: 使用不同batch size和精度的性能。在RTX 2080 TI上测量。