NLP自然语言处理之基于BiLstm的短文本情感分析
1、BILSTM基本原理
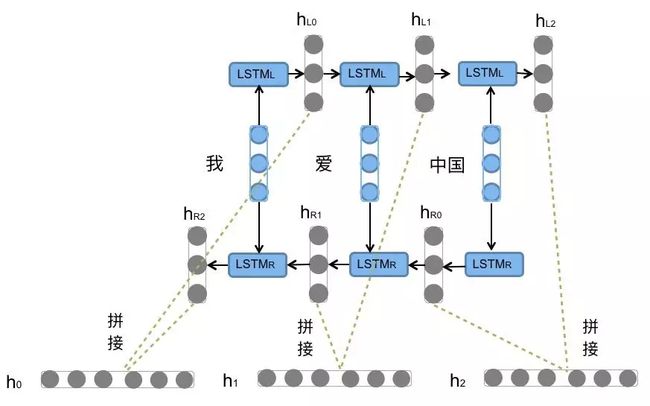
前向的LSTM与后向的LSTM结合成BiLSTM。比如,我们对“我爱中国”这句话进行编码,模型如图1所示。

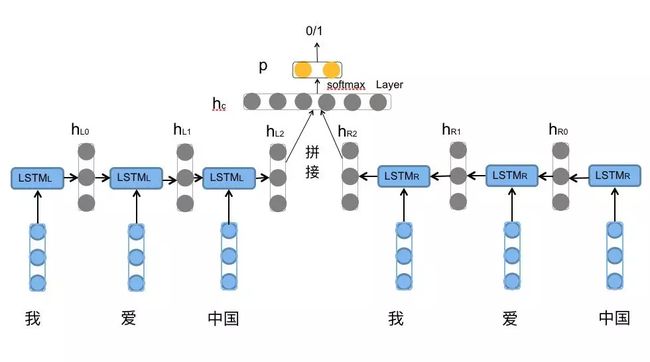
2、情感分析步骤
- 收集数据:爬虫爬取
- 数据预处理:特征:切词----停用词过滤----词嵌入(word2vec) 标签:类别数字化----onehot编码
- 搭建模型:bilstm----cnn----选择参数(k折验证|随机森林|autoML等)----选择优化器
- 训练:把词嵌入的结果输入模型设置迭代次数,批次的样本数量
- 评估模型:召回率|准确率|RMSE|
- 预测:输入新的样本,进行情感分析
可参考如下图,不一定网络规模一致:
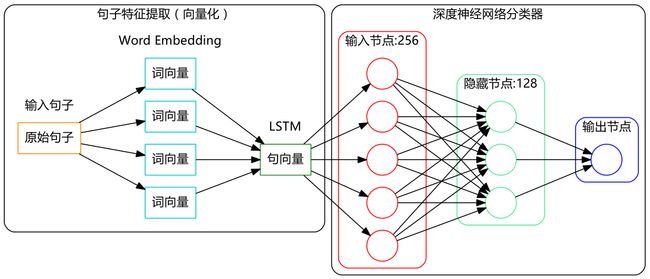
3、代码实现
import numpy as np
from gensim.models.word2vec import Word2Vec
from gensim.corpora.dictionary import Dictionary
from gensim import models
import pandas as pd
import jieba
import logging
from keras import Sequential
from keras.preprocessing.sequence import pad_sequences
from keras.layers import Bidirectional,LSTM,Dense,Embedding,Dropout,Activation,Softmax
from sklearn.model_selection import train_test_split
from keras.utils import np_utils
import pdb
"""
物流快递 医疗服务 金融服务 食品餐饮 旅游住宿
"""
# 读入数据
def read_data(data_path):
# 两个标签,一个放句子,一个放标签
senlist = []
labellist = []
# 开始读入进行处理
with open(data_path, "r",encoding='gb2312',errors='ignore') as f:
for data in f.readlines():
data = data.strip()
# 一行四个元素:文章序列、文本类型、文本、情感分类类型
sen = data.split("\t")[2]
label = data.split("\t")[3]
if sen != "" and (label =="0" or label=="1" or label=="2" ) :
senlist.append(sen)
labellist.append(label)
else:
pass
assert(len(senlist) == len(labellist))
return senlist ,labellist
sentences,labels = read_data("./data_train.csv")
""" 1、word2vec模型训练,后续使用直接加载即可
# 训练词向量,直接把句子放入,切词,训练成w2c向量,保存模型
def train_word2vec(sentences,save_path):
sentences_seg = []
# 使用'\n'连接句子
sen_str = "\n".join(sentences)
# 切词
res = jieba.lcut(sen_str)
# 使用空格连接好切好的词
seg_str = " ".join(res)
# 使用'\n'符号将切词分割开
sen_list = seg_str.split("\n")
# 构建列表添加切好的文本预料,仍然是以文本为单位,但已经是切词形态了
for i in sen_list:
sentences_seg.append(i.split())
print("开始训练词向量")
# logging.basicConfig(format='%(asctime)s : %(levelname)s : %(message)s', level=logging.INFO)
model = Word2Vec(sentences_seg,
size=100, # 词向量维度
min_count=5, # 词频阈值
window=5) # 窗口大小
model.save(save_path)
return model
model = train_word2vec(sentences,'./w2cmodel/word2vec.model')
# pdb.set_trace()
"""
model = Word2Vec.load('./w2cmodel/word2vec.model')
# 数据的预处理
# 返回值:w2id ---- {word:索引} embedding_weights ---- {索引:词向量}
# 逻辑就出来了:根据 word 查询 索引,根据索引查询词向量
def generate_id2wec(word2vec_model):
gensim_dict = Dictionary()
gensim_dict.doc2bow(model.wv.vocab.keys(), allow_update=True)
w2id = {v: k + 1 for k, v in gensim_dict.items()} # 词语的索引,从1开始编号 {word:索引}
w2vec = {word: model[word] for word in w2id.keys()} # 词语的词向量 {词:词向量}
# 获取词的长度
n_vocabs = len(w2id) + 1
# 初始化一个空白词向量
embedding_weights = np.zeros((n_vocabs, 100))
for w, index in w2id.items(): # 从索引为1的词语开始,用词向量填充矩阵
embedding_weights[index, :] = w2vec[w]
return w2id,embedding_weights
def text_to_array(w2index, senlist): # 文本转为索引数字模式
sentences_array = []
for sen in senlist:
new_sen = [ w2index.get(word,0) for word in sen] # 单词转索引数字
# pdb.set_trace()
sentences_array.append(new_sen)
return np.array(sentences_array)
def prepare_data(w2id,sentences,labels,max_len=200):
# 切分训练集和测试集样本
X_train, X_val, y_train, y_val = train_test_split(sentences,labels, test_size=0.2)
# 按照词典将文本转化为索引文本,每个索引对应词向量
X_train = text_to_array(w2id, X_train)
X_val = text_to_array(w2id, X_val)
# 填充文本至统一长度max_len
X_train = pad_sequences(X_train, maxlen=max_len)
X_val = pad_sequences(X_val, maxlen=max_len)
# to_categorical()独热编码
return np.array(X_train), np_utils.to_categorical(y_train) ,np.array(X_val), np_utils.to_categorical(y_val)
# 是为了拿到传给后续情感分析模型的词典(w2id) 和 词向量矩阵(embedding_weights)
w2id,embedding_weights = generate_id2wec(model)
# 传入词典、句子文本、标签、最大长度
# 返回两个文本的索引形式 两个文本标签的独热编码形式
x_train,y_trian, x_val , y_val = prepare_data(w2id,sentences,labels,200)
# 定义了一个Sentiment类,封装了模型的构建,训练和预测方法
class Sentiment:
# 初始化
def __init__(self,w2id,embedding_weights,Embedding_dim,maxlen,labels_category):
self.Embedding_dim = Embedding_dim
self.embedding_weights = embedding_weights
self.vocab = w2id
self.labels_category = labels_category
self.maxlen = maxlen
self.model = self.build_model()
# 模型搭建,返回一个model
def build_model(self):
model = Sequential()
#input dim(140,100)
model.add(Embedding(output_dim = self.Embedding_dim, input_dim=len(self.vocab)+1, weights=[self.embedding_weights], input_length=self.maxlen))
model.add(Bidirectional(LSTM(50),merge_mode='concat'))
model.add(Dropout(0.3))
model.add(Dense(self.labels_category))
model.add(Activation('softmax'))
model.compile(loss='categorical_crossentropy', optimizer='adam', metrics=['accuracy'])
model.summary()
return model
def train(self,X_train, y_train,X_test, y_test,n_epoch=1, model_load=1, model_path=None):
if model_load:
self.model.fit(X_train, y_train, batch_size=320, epochs=n_epoch, validation_data=(X_test, y_test))
self.model.save('sentiment.h5')
else:
model = self.model
model.load_weights(model_path)
model.fit(X_train, y_train, batch_size=320, epochs=n_epoch, validation_data=(X_test, y_test))
model.save('sentiment.h5')
def predict(self,model_path,new_sen):
model = self.model
model.load_weights(model_path)
new_sen_list = jieba.lcut(new_sen)
sen2id =[ self.vocab.get(word,0) for word in new_sen_list]
sen_input = pad_sequences([sen2id], maxlen=self.maxlen)
res = model.predict(sen_input)[0]
return np.argmax(res)
# 构建模型,同时传人词典和词向量矩阵
senti = Sentiment(w2id,embedding_weights,100,200,3)
# 训练模型
# senti.train(x_train,y_trian, x_val ,y_val,n_epoch=2, model_load=0, model_path='./sentiment.h5')
# 模型预测
label_dic = {0:"消极的",1:"中性的",2:"积极的"}
# sen_new = "现如今的公司能够做成这样已经很不错了,微订点单网站的信息更新很及时,内容来源很真实"
# sen_new = '一点都不好,我们同事那一桌只剩下了这个点,就扣了我们50元钱,味道也是一般'
# sen_new = '活动很精彩,人很多,学到很多'
# sen_new = '携程不怎么样,服务不好,价格贵杀熟,跟不上市场形势,不会分析需求'
# sen_new = "买的这个鞋子有一点破旧,鞋帮有一点开裂,总之物流也非常慢,就是讨厌"
sen_new = '味道不好吃,不喜欢,太辣了'
pre = senti.predict("./sentiment.h5",sen_new)
print("'{}'的情感是:\n{}".format(sen_new,label_dic.get(pre)))