GloVe: Global Vectors for Word Representation阅读总结
论文:GloVe: Global Vectors for Word Representation
cs224视频:https://www.bilibili.com/video/BV1pt411h7aT?t=4017&p=3
目录
一、背景介绍
二、实验方法
三、模型理解
1、和其他模型的关系
2、模型复杂度
四、实验结果
0、实验设置
1、单词类比任务(word analogy task)
2、单词相似性(Word similarity)
3、命名实体识别(Named entity recognition)
五、实验分析
1、向量长度和上下文窗口大小
2、语料库大小
3、和word2vec模型进行比较
一、背景介绍
目前有两种主要的词向量表示模型:
- Shallow Window-Based Methods
- Matrix Factorization Methods
Shallow Window-Based Methods:基于局部上下文窗口的模型(Skip-gram,CBOW,NNLM,HLBL和RNN等)。之前介绍了词向量空间表示模型word2vec,该模型中的skip-gram模型在单词类比任务(analogy task)上表现较好,但是由于它是在单独的局部上下文窗口进行训练,而不是在全局共现计数上进行训练,所以对于语料库的统计信息利用不够
Matrix Factorization Methods:基于全局共现矩阵奇异值分解的模型(如LSA,HAL,COALS和Hellinger-PCA等)。用于生成低维词向量表示,通过对语料库中的大型词-词(或词-文档)共现矩阵进行奇异值分解以获取语料库信息。模型有效利用了统计信息,但在单词类比任务上表现较差,这表明这个向量空间结构不是最优的。其中比较典型的方法是LSA(Latent Semantic Analysis):
LSA的基本流程:
- 分析文档集合,建立单词-文本(term-document)矩阵A,矩阵元素Aij表示单词i在文本j中出现的次数
- 对矩阵A进行奇异值分解SVD
- 对SVD分解后的矩阵进行降维:
(S是
维,S'是
维,
)
- 使用降维后的矩阵构建潜在语义空间
其中,降维过程中,是对矩阵A作SVD后,选取S中较大的r个奇异值并排序得到r',![]() 可以近似A。
可以近似A。
在U'中,每一列代表一个潜在语义,S'中每个奇异值表示该语义的重要程度,![]() 中每一列仍是一篇文档,但此文档被映射了语义空间,可用
中每一列仍是一篇文档,但此文档被映射了语义空间,可用![]() 代替A进行之后的工作
代替A进行之后的工作
二、实验方法
所以,这篇文章结合这两种模型,提出了GloVe:直接获取全局语料库统计信息的词向量模型。该模型使用全局对数双线性回归模型(global log-bilinear regression model),并非基于语料库中整个的稀疏矩阵或局部上下文窗口进行训练,而是通过训练词-词共现矩阵中的非零元素,从而有效利用统计信息。
首先介绍一下文章中的符号表示:
:词-词共现计数矩阵
:单词j在单词i的上下文中出现的次数
:单词i的上下文中出现的单词总数
:在单词i的上下文中出现单词j的概率
接下来文章通过分析逐步确定目标函数形式
1、先举了一个简单的例子:

统计了目标词“ice”和“steam”在含60亿词的语料库上构建的共现概率,因为只有在这种规模的语料库下才能抵消“water”和“fashion”这样的噪声。从实验结果可以看到,比值更大的词(solid)与“ice”的特性跟相关,比值更小的词(gas)与“steam”的特性更相关。这种方式与原有概率比较可以发现,这个比值既能区分相关词和不相关词(solid、gas与water、fashion),也能很好地区分两个相关词(solid和gas),所以得出结论:
词向量学习应该基于比值而非概率本身:(式2-1)
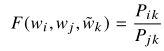
其中,![]() 是单词向量,
是单词向量,![]() 是上下文单词向量,方程左边F函数的具体形式暂时未定,方程右边概率来自于语料库中的计数统计
是上下文单词向量,方程左边F函数的具体形式暂时未定,方程右边概率来自于语料库中的计数统计
2、由于是在向量空间中进行表示,所以是一种线性结构形式,所以
只考虑由两个目标单词向量的差异决定函数F:(式2-2)

3、在式2-2中,右边是标量形式,所以左边的结果也应该是标量。如果使用神经网络,那么结果可能会比较复杂,不利于得到线性结构,所以
使用参数的内积形式以避免混入向量维度这一复杂信息:(式2-3)
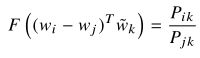
4、在词-词共现矩阵中,当前词和上下文词的角色可以互换(一个词既可能是当前词,也可能是上下文词),所以为了保持一致性,在交换![]() 同时考虑
同时考虑![]() ,所以
,所以
考虑对称性:(式2-4)
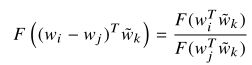
5、同时考虑式2-3和式2-4,可以得到:(式2-5)
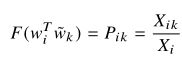
6、考虑式2-5,指数函数可以满足这种形式的F,然后两边取对数,可以得到对数形式的方程
使用对数函数(式2-6)
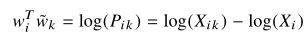
7、在式2-6中,如果没有![]() ,则可以保证对称性的要求。因为
,则可以保证对称性的要求。因为![]() 与k无关,所以可以将这项融合进
与k无关,所以可以将这项融合进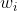 的偏置
的偏置![]() 中,同时,为了保持对称性,对
中,同时,为了保持对称性,对![]() 也增加偏置项
也增加偏置项![]()
加入偏置项:(式2-7)

8、式2-7能够较好满足目标要求,但是存在一个问题,当参数为0时,对数运算则会出现问题,所以考虑加入偏移量:![]()
但是这个模型仍存在一个问题:即使一些共现很少甚至不出现时,这个模型仍会对其进行考虑,这部分内容也是模型的噪声。尽管这些噪声含有的信息很少,但实际上占据了语料库的75%-95%。
所以考虑使用加权最小二乘回归模型构造损失函数:(式2-8)

其中,![]() 是权值函数,它应该具有以下特点:
是权值函数,它应该具有以下特点:
- f(0) = 0,并且
有限
- f(x)不减,以保证很少出现的共现词组的权值不会过高
- 当x较大时,f(x)相对较小,以保证频繁出现的共现词组不会权值过高
9、能够满足上述要求的函数很多,文章中使用:(式2-9)
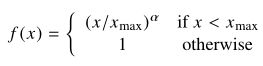
该模型的表现和![]() 的值有关,文章设定
的值有关,文章设定![]()
该函数的图像为:(图2-1)

三、模型理解
1、和其他模型的关系
和Matrix Factorization Methods相比,都是重点考虑共现矩阵,两者之间有不少共同点。所以文章重点讨论模型和Shallow Window-Based Methods的联系:
以skip-gram和ivLBL模型为例,他们的出发点都是考虑单词j出现在单词i上下文的概率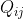 ,这个概率通过softmax计算得到:(式3-1)
,这个概率通过softmax计算得到:(式3-1)

所以,全局目标函数为:(式3-2)
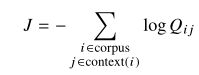
为了提高计算效率,通常将含相同值的项放在一起:(式3-3)
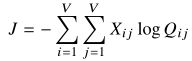
其中,相同项的数目是由共现矩阵X给出的。
由于关系式![]() 和
和![]() ,所以可以将式3-3改写成:(3-4)
,所以可以将式3-3改写成:(3-4)
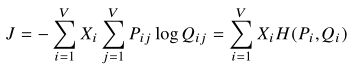
其中,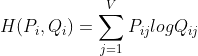 是分布Pi和Qi的交叉熵
是分布Pi和Qi的交叉熵
由于都是使用加权交叉熵误差作为目标函数,所以式3-4和式2-8具有一定的相似性。
相比于式3-4,式2-8可以解释为“全局skip-gram模型”,式2-8考虑的范围更广;而且式3-4存在一些缺点:
- 在长尾分布中,对于一些不太可能发生的事件,不应该赋予很高的权重
- 为了保证测量的有界性,需要对分布Q进行适当的规范化,会出现计算瓶颈
所以对模型进行改进,将最小二乘作为目标,同时舍弃了Q和P的正则化因子:(式3-5)
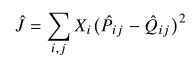
由于舍弃了规范化,所以当值过大时,优化会变得很复杂。所以考虑使用对数,并带入![]() 和
和![]() ,得到:(式3-6)
,得到:(式3-6)

然后考虑加权因子:(式3-7)
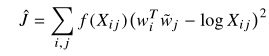
加权因子是由模型skip-gram和ivLBL固有的在线训练方法预先设定的,但不能保证它是最优的。可以通过过滤数据来提高性能,从而降低频繁词加权因子的有效值。
可以看到,通过这种方法得到的式3-7和之前推导的2-8是等价的
2、模型复杂度
从式2-8可以看到,模型的复杂度主要取决于共现矩阵X中非零元的个数。
因为非零元数目总小于矩阵元素个数,所以模型复杂度不会高于![]() 。
。
感觉这是对于Shallow Window-Based Methods(复杂度和语料库单词数目C成比例![]() )的改进,但是典型的词汇成千上万个,所以
)的改进,但是典型的词汇成千上万个,所以![]() 的数量级可能会比|C|大得多。因此,为了降低模型复杂度,需要对非零元进行更加严格的限制。
的数量级可能会比|C|大得多。因此,为了降低模型复杂度,需要对非零元进行更加严格的限制。
考虑单词i和单词j的共现频率排名![]() ,排名(
,排名(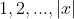 )名次越大,意味着出现次数越少,所以
)名次越大,意味着出现次数越少,所以![]() 与成反比,两者关系为:(式3-8)
与成反比,两者关系为:(式3-8)

语料库中单词总数与共现矩阵X所有元素的总和成比例:(式3-9)

其中,![]() 是广义调和函数,|x|是最大频率排名,它与矩阵X中非零元素的数量一样。
是广义调和函数,|x|是最大频率排名,它与矩阵X中非零元素的数量一样。
考虑出现频率最高的共现词组,其排名![]() ,此时有:(式3-10)
,此时有:(式3-10)
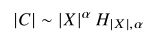
当|C|和|X|都很大时,考虑调和函数:(式3-11)

其中,![]() 是黎曼函数
是黎曼函数
于是,有关系式:(式3-12)
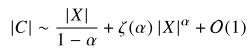
当X很大时,式3-12右端只与一项有关,根据![]() 是否成立决定具体和哪一项有关:(式3-13)
是否成立决定具体和哪一项有关:(式3-13)
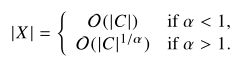
在文章使用的语料库中,根据式3-8,![]() 能够对进行建模的效果不错。在这种情况下,
能够对进行建模的效果不错。在这种情况下,![]() ,模型复杂度比最糟糕的情况
,模型复杂度比最糟糕的情况![]() 好很多,而且比基于上下文窗口的方法
好很多,而且比基于上下文窗口的方法![]() 也要好
也要好
四、实验结果
0、实验设置
在实验中,使用了权值递减函数,间隔d个单词的单词对占总数的1/d,间隔较远的单词对包含较少的相关信息
实验中设置![]() ,使用AdaGrad来训练模型,从X中随机采样非零元素,设置学习率为0.05。对于维度小于300的向量进行50次迭代,其他情况进行100次迭代。
,使用AdaGrad来训练模型,从X中随机采样非零元素,设置学习率为0.05。对于维度小于300的向量进行50次迭代,其他情况进行100次迭代。
模型会生成两组词向量W和![]() ,当X对称时,W和
,当X对称时,W和![]() 是等价的,仅仅由于随机初始化而有所不同。(参考某些神经网络,训练多个网络实例,然后对结果进行综合,可以有助于减少噪声和过拟合,从而在整体上改善结果)所以,使用向量和
是等价的,仅仅由于随机初始化而有所不同。(参考某些神经网络,训练多个网络实例,然后对结果进行综合,可以有助于减少噪声和过拟合,从而在整体上改善结果)所以,使用向量和![]() 作为词向量
作为词向量
1、单词类比任务(word analogy task)
单词类比任务是指“a is to b as c is to __ ?”,主要包含语义问题(semantic question)和语法问题(syntactic question)两种问题。
语义问题通常是关于人和地点,例如“Athens is to Greece as Berlin is to __ ?”
语法问题通常是关于动词和形容词形式,例如“dance is to dancing as fly is to __ ?”
为了回答问题“a is to b as c is to __ ?”,会根据余弦相似性寻找最接近表示为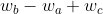 的单词d。
的单词d。
实验结果:(图4-1)

文章给出的是百分比形式的准确率,下划线分数表示相同规模的模型中最高得分,加粗分数表示所有模型中最高得分
实验结果显示:在单词类比任务上,GloVe模型在较小的向量维度和较小的语料库上表现明显优于其他模型
本文使用word2vec工具的实验结果也优于已有实验结果。原因:
- 使用负采样(通常优于分层采样)
- 负样本数目的选择
- 语料库的选择
另外,实验发现,单纯增加语料库的大小并不能保证实验结果得到提升,这可以从SVD-L模型在更大的语料库上的性能下降中看出。基本的SVD模型不能很好地扩展到大型语料库,这也验证了模型中提出的加权方案的必要性。因为实验结果和语料库的质量有很大关系,对于Wikipedia这种语料库,涵盖内容比较广,而且拼写错误比较少。而对于一些语料库,例如美国新闻,就会很少出现Abuja、Ashgabat这些词,所以很难捕捉这些词向量,从而会使得结果比较糟糕。
2、单词相似性(Word similarity)
首先对词汇表中的每个特征进行归一化,然后计算余弦相似度,从而得到词向量的相似性得分。
在五个不同的语料库中进行了对比试验:(如图4-2)

可以看到,即使所用语料库的大小不到CBOW使用的一半,但表现依然好于CBOW
3、命名实体识别(Named entity recognition)
基准数据集中标记了四种类型的实体:person,location,organization和miscellaneous(杂项)
当开发集在25次迭代中没有得到改进时,L-BFGS训练终止。除此之外,所有的配置都与 Effect of non-linear deep architecture in sequence labeling使用的相同
标记为Discrete的模型是基线,使用了斯坦福NER模型的标准分布所附带的一组全面的离散特征,但没有词向量特征
基于CRF模型的命名实体识别任务结果:(图4-3)
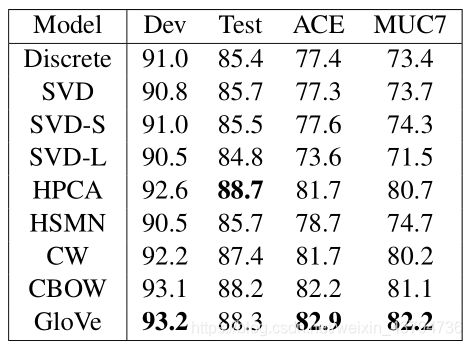
可以看到,除了在测试集CoNLL上HPCA方法略微表现好一点,在其他任何评价标准下,GloVe模型都比其他模型表现好。因此,可以得出结论:GloVe向量在下游NLP任务中都很有用
五、实验分析
1、向量长度和上下文窗口大小
考虑对称上下文(symmetric context):扩展到目标词上文窗口和下文窗口;不对称上下文(asymmetric context):只扩展到目标词的上文窗口或下文窗口
图5-1:

当向量维度较小时,实验结果比较差,随着向量维度增大,表现会逐渐变好。当向量维度为300时,实验结果达到最优,之后随着向量维度的增加,实验表现会有些微地下降。
上下文窗口大小为8时,实验表现最好。
但是,在上述两项对比中,如果考虑计算代价,当向量维度由200增加至300,或者窗口大小由4增加至8时,表现提升较小,但是所需代价太大,所以在实际应用中需要对其进行权衡。
另外,对于小而不对称的上下文窗口,语法子任务(syntactic subtask)的性能更好,这与直觉一致,即语法信息主要来自于直接的上下文,并且对词序依赖性较强
而语义信息(semantic information)更多是非局部的,常用较大的窗口来获取
2、语料库大小
图5-2:

在语法子任务(syntactic subtask)中,模型表现随着语料库增长而单调递增。这是因为更大的语料库通常会有更多的统计信息。
而对于语义子任务(semantic subtask),模型在较小的Wikipedia语料库的表现比较大的Gigaword语料库的差,这可能是因为类比关系很多都是基于城市和国家的,而Wikipedia中对于这些内容含有丰富的信息。而且,由于Wikipedia中的一些信息会不断更新新知识,而Gigaword相对比较固定,会包含一些过时的不正确的信息。
3、和word2vec模型进行比较
考虑训练时间:对于GloVe,相关参数是training iterations;对于word2vec,相关参数是training epochs。另一种选择是通过改变负样本数目来改变训练时间:增加负样本数目能有效增加训练单词的数目,从而增加训练时间。
图5-3:
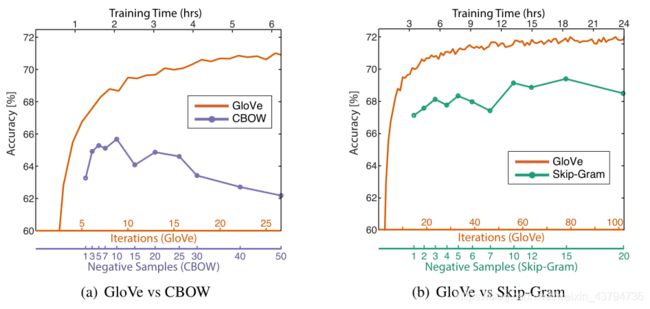
word2vec负样本数目超过10时,模型表现会下降,这可能是因为负采样方法不难很好近似目标概率分布。
对于相同的语料库、词汇量、窗口大小和训练时间,GloVe模型的表现都优于word2vec。