原创文章,转载注明出处,多谢合作。
经过前面的铺垫,这篇来看看硬件加速的绘制过程.
performTraversals方法中前面经过了measure、layout之后,View树也基本成型了。接下来就来分析下硬件加速的绘制过程,从performDraw()开始分析:
private void performDraw() {
...
Trace.traceBegin(Trace.TRACE_TAG_VIEW, "draw");//systrace对应的draw label
boolean canUseAsync = draw(fullRedrawNeeded);
Trace.traceEnd(Trace.TRACE_TAG_VIEW);
...
}
performDraw内主要执行draw方法
private boolean draw(boolean fullRedrawNeeded) {
...
if (!dirty.isEmpty() || mIsAnimating || accessibilityFocusDirty) {
//判断是否开启硬件加速
if (mAttachInfo.mThreadedRenderer != null && mAttachInfo.mThreadedRenderer.isEnabled()) {
...
//硬件加速绘制
mAttachInfo.mThreadedRenderer.draw(mView, mAttachInfo, this, callback);
} else {
...
//软件绘制
if (!drawSoftware(surface, mAttachInfo, xOffset, yOffset,scalingRequired, dirty, surfaceInsets)) {
return false;
}
}
...
}
这里就是软件绘制与硬件加速绘制的分歧点.因为前面ViewRootImpl通过enableHardwareAcceleration开启硬件加速,初始化了HardwareRenderer,因此满足硬件加速绘制流程.
这里简单再总结下软件绘制的流程:
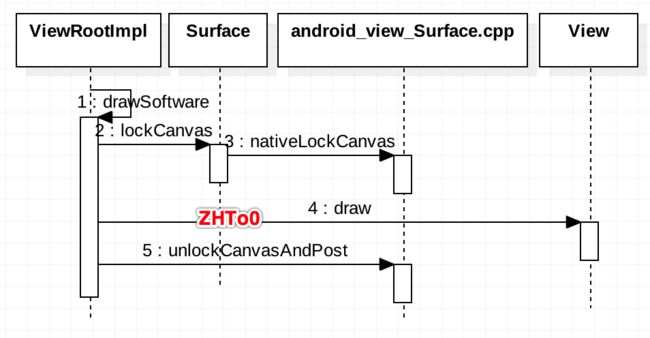
软件绘制走的drawSoftware方法:
1) 调用lockCanvas, 实际执行逻辑在native层对应的nativeLockCanvas中,实现:构造SkiaCanvas;向SurfaceFlinger dequeue一块GraphicBuffer. 前者用于绘制,后者用于存放并传输UI视图元素。
2) View.draw(canvas),通过构造的Canvas绘制视图,最终UI元素保存到申请到的GraphicBuffer,绘制API对应是底层Skia库。
3) 调用unlockCanvasAndPost 实现:queueBuffer给SurfaceFlinger 并且通知其消费。
整个过程都是在UI Thread完成的.
好的,言归正传,接着来看硬件绘制。
因为前面ThreadedRenderer已经初始化好了且设置了isEnabled,所以这里直接看下ThreadedRenderer.draw:
frameworks/base/core/java/android/view/ThreadedRenderer.java
void draw(View view, AttachInfo attachInfo, DrawCallbacks callbacks,
FrameDrawingCallback frameDrawingCallback) {
...
updateRootDisplayList(view, callbacks);//绘制视图
...
int syncResult = nSyncAndDrawFrame(mNativeProxy, frameInfo, frameInfo.length);//渲染视图
...
}
硬件加速绘制主要包括两个阶段:绘制阶段 和 渲染阶段,分别对应如上代码所示方法。
由于内容比较多,所以拆成两部分来写了, 这篇文章先看绘制阶段.
那么沿着updateRootDisplayList往下分析
private void updateRootDisplayList(View view, DrawCallbacks callbacks) {
Trace.traceBegin(Trace.TRACE_TAG_VIEW, "Record View#draw()");
updateViewTreeDisplayList(view);//更新displayList
//下面流程是保存RootRenderNode的displayList
…
if (mRootNodeNeedsUpdate || !mRootNode.isValid()) {
DisplayListCanvas canvas = mRootNode.start(mSurfaceWidth, mSurfaceHeight);
try {
final int saveCount = canvas.save();
canvas.translate(mInsetLeft, mInsetTop);
callbacks.onPreDraw(canvas);
canvas.insertReorderBarrier();
canvas.drawRenderNode(view.updateDisplayListIfDirty());
canvas.insertInorderBarrier();
callbacks.onPostDraw(canvas);
canvas.restoreToCount(saveCount);
mRootNodeNeedsUpdate = false;
} finally {
mRootNode.end(canvas);
}
}
Trace.traceEnd(Trace.TRACE_TAG_VIEW);
}
updateViewTreeDisplayList主要走了View的updateDisplayListIfDirty方法
frameworks/base/core/java/android/view/View.java
public RenderNode updateDisplayListIfDirty() {
//mRenderNode在View的构造方法中创建,与View一一对应: RenderNode.create(getClass().getName(), this);
final RenderNode renderNode = mRenderNode;
... //省略这部分是不需要更新的一些列判断, 并return 不看这部分 直接看下面的更新逻辑
//硬件加速对应的Canvas
final DisplayListCanvas canvas = renderNode.start(width, height);
try {
if (layerType == LAYER_TYPE_SOFTWARE) {
buildDrawingCache(true);//软件绘制
Bitmap cache = getDrawingCache(true);
if (cache != null) {
canvas.drawBitmap(cache, 0, 0, mLayerPaint);
}
} else {//硬件加速绘制
computeScroll();
canvas.translate(-mScrollX, -mScrollY);
mPrivateFlags |= PFLAG_DRAWN | PFLAG_DRAWING_CACHE_VALID;
mPrivateFlags &= ~PFLAG_DIRTY_MASK;
// 如果是ViewGroup则递归子View ,子View就调用自己的draw,通过Canvas绘制最终生成displayList
if ((mPrivateFlags & PFLAG_SKIP_DRAW) == PFLAG_SKIP_DRAW) {
dispatchDraw(canvas);
drawAutofilledHighlight(canvas);
if (mOverlay != null && !mOverlay.isEmpty()) {
mOverlay.getOverlayView().draw(canvas);
}
if (debugDraw()) {
debugDrawFocus(canvas);
}
} else {
draw(canvas);
}
}
} finally {
renderNode.end(canvas); //将View生成的DisplayList保存到对应的RenderNode中
setDisplayListProperties(renderNode);
}
} else {
mPrivateFlags |= PFLAG_DRAWN | PFLAG_DRAWING_CACHE_VALID;
mPrivateFlags &= ~PFLAG_DIRTY_MASK;
}
return renderNode;
}
这个方法包括两部分:
1 renderNode.start触发了一系列的初始化:
frameworks/base/core/java/android/view/RenderNode.java
public DisplayListCanvas start(int width, int height) {
return DisplayListCanvas.obtain(this, width, height);
}
static DisplayListCanvas obtain(@NonNull RenderNode node, int width, int height) {
if (node == null) throw new IllegalArgumentException("node cannot be null");
DisplayListCanvas canvas = sPool.acquire();
if (canvas == null) {
canvas = new DisplayListCanvas(node, width, height);
} else {
nResetDisplayListCanvas(canvas.mNativeCanvasWrapper, node.mNativeRenderNode,
width, height);
}
canvas.mNode = node;
canvas.mWidth = width;
canvas.mHeight = height;
return canvas;
}
先通过sPool初始化DisplayListCanvas , 这里引入了池的概念, 也就是复用对象,避免过多创建,整个池大小限制在25. 这里不管是创建DisplayListCanvas还是更新DisplayListCanvas, 对应方法都是在对应的native类RecordingCanvas.cpp中.
以nResetDisplayListCanvas为例
frameworks/base/libs/hwui/RecordingCanvas.cpp
void RecordingCanvas::resetRecording(int width, int height, RenderNode* node) {
LOG_ALWAYS_FATAL_IF(mDisplayList, "prepareDirty called a second time during a recording!");
mDisplayList = new DisplayList();
mState.initializeRecordingSaveStack(width, height);
mDeferredBarrierType = DeferredBarrierType::InOrder;
}
这里初始化了DisplayList.
RenderNode.start主要做了这么几件事:
1)初始化构建DisplayList的DisplayListCanvas.
2)初始化一个DisplayList与之一一对应 .
2 draw 这里硬件加速包括dispatchDraw 和 draw两部分
通过DisplayListCanvas对View tree的每一个子View进行绘制操作, 最终在底层RecordingCanvas.cpp中生产对应的Op操作
frameworks/base/libs/hwui/RecordingCanvas.cpp
void RecordingCanvas::drawLines(const float* points, int floatCount, const SkPaint& paint) {
if (CC_UNLIKELY(floatCount < 4 || paint.nothingToDraw())) return;
floatCount &= ~0x3; // round down to nearest four
addOp(alloc().create_trivial(
calcBoundsOfPoints(points, floatCount), *mState.currentSnapshot()->transform,
getRecordedClip(), refPaint(&paint), refBuffer(points, floatCount), floatCount));
}
这里以drawLines操作为例, 最后执行了addOp操作
int RecordingCanvas::addOp(RecordedOp* op) {
// skip op with empty clip
if (op->localClip && op->localClip->rect.isEmpty()) {
// NOTE: this rejection happens after op construction/content ref-ing, so content ref'd
// and held by renderthread isn't affected by clip rejection.
// Could rewind alloc here if desired, but callers would have to not touch op afterwards.
return -1;
}
int insertIndex = mDisplayList->ops.size();
mDisplayList->ops.push_back(op);
if (mDeferredBarrierType != DeferredBarrierType::None) {
// op is first in new chunk
mDisplayList->chunks.emplace_back();
DisplayList::Chunk& newChunk = mDisplayList->chunks.back();
newChunk.beginOpIndex = insertIndex;
newChunk.endOpIndex = insertIndex + 1;
newChunk.reorderChildren = (mDeferredBarrierType == DeferredBarrierType::OutOfOrder);
newChunk.reorderClip = mDeferredBarrierClip;
int nextChildIndex = mDisplayList->children.size();
newChunk.beginChildIndex = newChunk.endChildIndex = nextChildIndex;
mDeferredBarrierType = DeferredBarrierType::None;
} else {
// standard case - append to existing chunk
mDisplayList->chunks.back().endOpIndex = insertIndex + 1;
}
return insertIndex;
}
这里一些列操作就是把op操作集合封装到DisplayList中,DisplayList这个数据结构包含了绘制该View所需的全部信息。
最后看看RenderNode的end方法:
public void end(DisplayListCanvas canvas) {
long displayList = canvas.finishRecording();
nSetDisplayList(mNativeRenderNode, displayList);
canvas.recycle();
}
canvas.finishRecording()函数会直接返回native中RecordingCanvas所指示的DisplayList地址然后通过 nSetDisplayList将DisplayList保存到Native的RenderNode的mStagingDisplayList中.
end执行完之后,DisplayListCanvas会调用drawRenderNode将子View的RenderNode封装进一个RenderNodeOp插入到父容器的DisplayList中。
void RecordingCanvas::drawRenderNode(RenderNode* renderNode) {
auto&& stagingProps = renderNode->stagingProperties();
RenderNodeOp* op = alloc().create_trivial(
Rect(stagingProps.getWidth(), stagingProps.getHeight()),
*(mState.currentSnapshot()->transform),
getRecordedClip(),
renderNode);
int opIndex = addOp(op); //加入到DisplayList的ops中
if (CC_LIKELY(opIndex >= 0)) {
int childIndex = mDisplayList->addChild(op); //加入到 DisplayList的chirldren中,
// update the chunk's child indices
DisplayList::Chunk& chunk = mDisplayList->chunks.back();
chunk.endChildIndex = childIndex + 1;
if (renderNode->stagingProperties().isProjectionReceiver()) {
// use staging property, since recording on UI thread
mDisplayList->projectionReceiveIndex = opIndex;
}
}
}
最后来复盘一下updateRootDisplayList过程:
借用一张调用栈图总结下整个updateRootDisplayList递归调用过程:
经过层updateDisplayListIfDirty-draw-end-drawRenderNode 最终组织成如下数据结构:

对应的流程图简要归纳如下:

参考:
https://www.jianshu.com/p/7bf306c09c7e