xgboost是一个系统
必考题:xgb和gbdt的区别xgb重新定义了树构建时切割的标准,以及子节点具体的取值
一、模型上: 1. 加了正则项(叶子结点的数量和score,score的计算方法就是G**2/(H+lambda)); 2. 二阶泰勒展开,收敛更快,精度更高;3.每一步学习完子树之后乘上一个学习率之后加到模型里,为后续的学习留出一定的空间
二、算法上:1. sparse aware algorithm,能处理缺失值,而且处理方式比较tricky,计算左孩子之后,右孩子直接通过G和H减去左孩子的GL和H得到:GR= G - GL,HR=H - HL;2. weighted approximate quantile sketch,二阶导的系数作为权重,提出一种在线的带权重的分位数计算方法。
三、系统上:1. 提前使用block结构(稀疏矩阵存储格式CSC)保存所有连续特征的排序值,用的时候直接调用;2. 特征的计算是多线程并行计算;
其他:借鉴了随机森林的思想,支持行采样和列采样。为什么xgboost要用二阶泰勒展开?
泰勒展开的本质是拟合一个函数,二阶泰勒展开可以近似大量的损失函数,比如回归的平方损失函数,分类的对数似然损失函数。通过二阶泰勒展开推导出来的最终式子(叶子结点的得分和分裂标准),具有通用性,也就是说,任何一个损失函数,只要它能够二阶求导,就能够使用这套分裂标准和叶子的score来构造xgboost模型,也就是自定义损失函数。-
 xgb算法整理
xgb算法整理 -
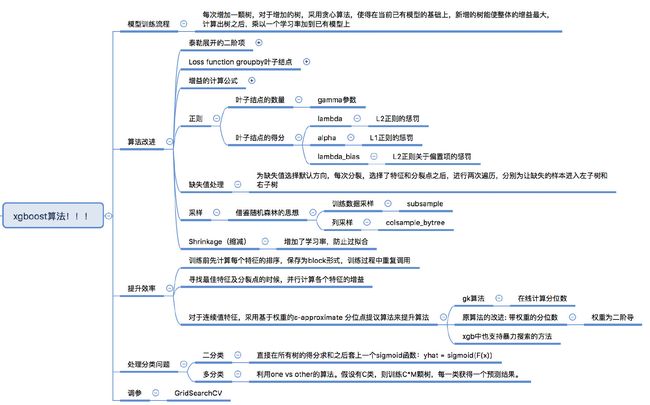
模型训练流程
for i in range(1, M): # M是迭代的次数 每次增加一棵树f_(i) 对于f(i),采用贪心算法,目标是新增的树可以使得在当前的F(i-1)的情况下增益(包含正则的惩罚项)最大 注意:xgboost中的分裂标准是根据一阶导和二阶导计算出来的,并不是常规的ID3,C4.5或者gini系数 F_(i) = F_(i-1) + learning_rate * f_(i)loss function包括两项,误差项和正则项
-
 loss function
loss function -
正则项主要是针对叶子结点,包括叶子结点的个数和得分。
-
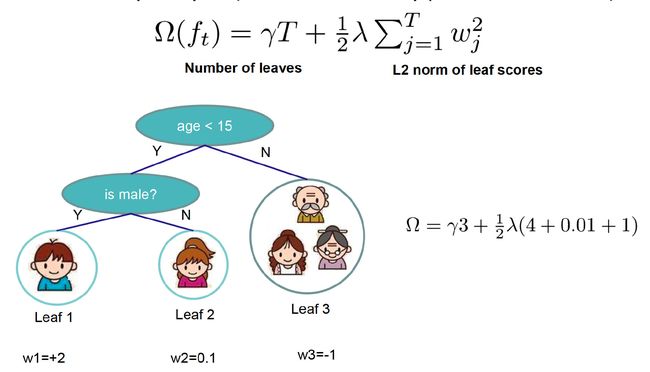 正则项
正则项
-
重点是loss function的设计:从sample-wise loss到 tree-structure-wise loss,样本误差group by叶子,正则项也是叶子结点的参数,实现统一。
-
 sample-wise loss到 tree-structure-wise loss
sample-wise loss到 tree-structure-wise loss 选择某个特征和对应的分裂点后,增益的计算方法
-
 增益的计算方法
增益的计算方法
-
求解过程,包括数学上和工程上,为了提高准确率和效率所采取的措施
- 采用了二阶泰勒展开,推导过程如下(以平方损失函数为例)
-
 二阶泰勒展开推导
二阶泰勒展开推导 - 最终得到(推导中注意l(y_i,yhat_i)已经被放到const里面了):
-
 loss function
loss function
xgboost分裂标准的推导(所有推导从loss function出发)
分裂标准:
叶子结点score的计算:
预测值的传播,boost的理解:第一颗树的,之后的值为这个样本在之前所有树所落到的叶子结点的score之和。score不断叠加,达到了boost的效果。
-
xgboost和gbdt的区别
- XGB加了正则项,普通的GBDT没有,用于防止过拟合。正则项包括:叶子节点的数量T(gamma参数控制),叶子的权重W(lambda参数控制)。回想一下使用xgb时候的参数设置。
- 增加了二阶泰勒展开,损失函数的定义更加精确,优化的方向更准确,提高拟合能力。
- Shrinkage(缩减),增加了学习率,防止过拟合
- 为了提升效率所做的处理
- 在训练前先保存每个特征值的排序(用于确定最佳分割点)为block,训练时重复使用这个block,各个特征的增益计算开多线程进行
- 基于权重的ε-approximate 分位点提议算法
- xgboost提供了两种greedy来学习每一颗子树的方法。一种是精确的方法,就是每次都遍历所有特征的所有可能分裂点。另一种是近似的算法,根据特征值的百分位来提议分裂点。近似的算法里面又分为两种,一种是global,在最开始的时候对每个特征都提议一些分裂点,在训练过程中这些可能的分裂点不变;另一种是local的方法,在每次分裂的时候重新提议分裂点。
- 这种基于分位数来提议分裂点的方法能加快训练速度,而且在性能上和精确的方法接近。当数据量特别大的情况下,把所有数据进行排序然后获得分位点的方法非常消耗内存和时间,需要使用ε-approximate 分位点算法,对于权重一致的情况,已经存在quantile sketch算法来进行排序。可以参考ε-approximate quantiles
- 但是在xgb中,每个点的权重是不一致的,权重系数是二阶导h(具体可以看论文,是从obj function推出来的),关于权重怎么理解,可以参考XGBoost之分位点算法,里面给了手写的例子,有助于理解原文中的排序函数r(z)。xgb中提出了基于权重的quantile sketch算法,也就是weighted quantile sketch。
- 采样,借鉴随机森林的思路,支持训练数据采样和特征采样。
- 训练数据采样比例 subsample[default=1]。Subsample ratio of the training instances. Setting it to 0.5 means that XGBoost would randomly sample half of the training data prior to growing trees. and this will prevent overfitting. Subsampling will occur once in every boosting iteration.
- 列采样比例 colsample_bytree[default=1],控制每棵随机采样的列数的占比(每一列是一个特征)
- 能够处理缺失值
- 为缺失值选择默认方向的方法:一个结点要对某一个特征选择分裂点时,每个分裂点的gain都计算两次,分别为让缺失的样本进入左子树和右子树。
-
 image
image - 文中还说到这种处理缺失值的方法在数据稀疏的时候计算效率提升了很多,和naive version对比,不确定这种naive version是怎么处理缺失值的?
naive version是把所有缺失值和左孩子或者右孩子合并,计算Gain。
//todo
看一下训练好的xgb模型保存的结构
-
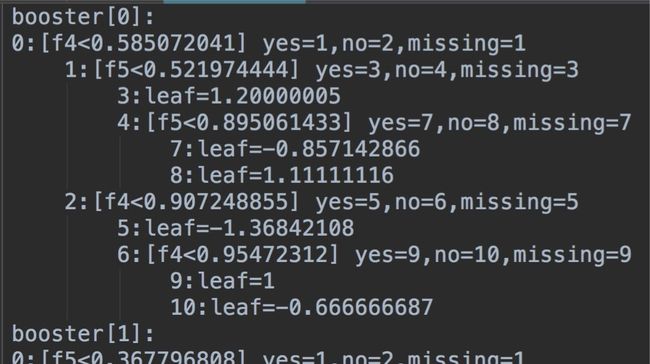 image
image- M颗树
- 对于每一颗树
- 非叶子结点保存的特征和对应的分裂点(如结点0,表示特征f4, 对应的分裂点为0.585072041;yes=1,no=2表示如果满足条件f4<0.585072041,走到结点1,否则走到结点2;missing=1表示如果是缺失值走到结点1)
- 叶子结点保存的是得分(如结点10,leaf=-0.666666687表示走到这个叶子结点,获得-0.666666687的得分)
-
xgb如何处理分类问题
- 处理二分类问题:直接在所有树的得分求和之后套上一个sigmoid函数:yhat = sigmoid(F(x))
- 处理多分类问题:利用one vs other的算法。假设有C类,则训练C*M颗树,每一类获得一个预测结果。
xgb的调参
import xgboost as xgb
import pandas as pd
from sklearn.model_selection import train_test_split
from sklearn.metrics import roc_auc_score
train_data = pd.read_csv('train.csv') # 读取数据
y = train_data.pop('30').values # 用pop方式将训练数据中的标签值y取出来,作为训练目标,这里的‘30’是标签的列名
col = train_data.columns
x = train_data[col].values # 剩下的列作为训练数据
train_x, valid_x, train_y, valid_y = train_test_split(x, y, test_size=0.333, random_state=0) # 分训练集和验证集
# 这里不需要Dmatrix
parameters = {
'max_depth': [5, 10, 15, 20, 25],
'learning_rate': [0.01, 0.02, 0.05, 0.1, 0.15],
'n_estimators': [500, 1000, 2000, 3000, 5000],
'min_child_weight': [0, 2, 5, 10, 20],
'max_delta_step': [0, 0.2, 0.6, 1, 2],
'subsample': [0.6, 0.7, 0.8, 0.85, 0.95],
'colsample_bytree': [0.5, 0.6, 0.7, 0.8, 0.9],
'reg_alpha': [0, 0.25, 0.5, 0.75, 1],
'reg_lambda': [0.2, 0.4, 0.6, 0.8, 1],
'scale_pos_weight': [0.2, 0.4, 0.6, 0.8, 1]
}
xlf = xgb.XGBClassifier(max_depth=10,
learning_rate=0.01,
n_estimators=2000,
silent=True,
objective='binary:logistic',
nthread=-1,
gamma=0,
min_child_weight=1,
max_delta_step=0,
subsample=0.85,
colsample_bytree=0.7,
colsample_bylevel=1,
reg_alpha=0,
reg_lambda=1,
scale_pos_weight=1,
seed=1440,
missing=None)
# 有了gridsearch我们便不需要fit函数
gsearch = GridSearchCV(xlf, param_grid=parameters, scoring='accuracy', cv=3)
gsearch.fit(train_x, train_y)
print("Best score: %0.3f" % gsearch.best_score_)
print("Best parameters set:")
best_parameters = gsearch.best_estimator_.get_params()
for param_name in sorted(parameters.keys()):
print("\t%s: %r" % (param_name, best_parameters[param_name]))
【注】以上代码引用自XGBoost和LightGBM的参数以及调参
- Complete Guide to Parameter Tuning in XGBoost
- xgb不错的解读
- 想更深入地理解请阅读原文和slides
- gk算法