tensorflow实战google第二版_机器学习实战:基于Scikit-Learn和TensorFlow---第二章笔记...
机器学习实战:基于Scikit-Learn和TensorFlow---第二章笔记
一、学习目标
以加州住房价格的数据集作为数据源,来进行构建一个完整的机器学习的项目。
二、完整的处理流程
2.1、目标问题
拿到数据集,搭建机器学习的项目,我们肯定是希望从这个数据中分析出什么结果。所以我们的目标就是:根据数据集,对一个区域的房价中位数进行预测。你肯定知道这是一个典型的监督式学习任务(因为已经给出了标记的训练示例),而且也是一个典型的回归任务(因 为你要对某个值进行预测)。更具体地说,这是一个多变量回归问题,因为系统要使用多个特征进行预测(使用到区域的人口、收入中位数等)。
2.2、性能指标
你辛苦构建完模型后,肯定要选择一个指标来测试下你的模型到底表现如何吧。回归问题的典型性能衡量指标是均方根误差(RMSE)。
公式1-1:均方根误差(RMSE)
$sqrt{frac{(sum_{i=1}^m(h(x^i) - y^i)^2)}{m}}$
解释下其中的符号:
- m是你在测量RMSE时,所使用的数据集中实例的数量(例如,如果你在评估RMSE时使用的验证集里包含2000个区域,则m=2000)
- $x^i$ 是数据集中,第i个实例的所有特征值的向量(标签特征除外),$y^i$是标签(也就是我们期待该实例的输出值)(例如,如果数据集的第一个区域位于经度-118.29°,纬度33.91°,居民数量为1416,平均收入为38372美元,房价中位数为156400美元(暂且忽略其他特征),那么:)
- $x^1$ = $ begin{pmatrix} -118.29 33.91 1416 38372 end{pmatrix} $
- $y^i$ = 156400
- h是系统的预测函数,也称为一个假设
即便RMSE通常是回归任务的首选性能衡量指标,但在某些情况下,其他函数可能会更适合。例如,当有很多离群区域时,你可以考虑使用平均绝对误差(也称为平均绝对偏差,参见公式1-2)
公式1-2:平均绝对误差(MAE)
$frac{sum_{i=1}^m vert h(x^i)-y^i vert}{m}$
均方根误差和平均绝对误差两种方法都是测量两个向量之间的距离:预测向量和目标值向量。距离或者范数的测度可能有多种。
2.3、数据分析
2.3.1、获取数据
此处假设我们已经下载好数据集(CSV格式)到本地项目文件夹中了,那么直接用Pandas加载即可。
2.3.2、分析数据
原书中进行了很详细的分析,此处只做个终结,同学们可以仔细阅读原书的思路。
- 数据每一行代表一个区,共有10列,也就是有10个属性:longitude,latitude,housing_median_age,total_rooms,total_bed rooms,population,households,median_income,median_house_value以及ocean_proximity。
- 数据集中包含20640个实例,注意,total_bed这个属性只有20433个非空值,这意味着有207个区域缺失这个特征。我们后面需要考虑到这一点
- 所有属性的字段都是数字,除了ocean_proximity。它的类型是object,因此它可以是任何类型的Python对象,不过你是从CSV文件中加载了该数据,所以它必然是文本属性。通过查看前五行,你可能会注意到,该列中的值是重复的,这意味着它有可能是一个分类属性。
2.3.3、创建测试集
数据窥探偏误(data snooping bias):
在这个阶段主动搁置部分数据听起来可能有点奇怪。毕竟,你才只是简单浏览了一下数据而已,在决定用什么算法之前,当然还需要了解更多的知识,对吧?没错,但是大脑是个非常神奇的模式检测系统,也就是说它很容易过度匹配:如果是你本人来浏览测试集数据,你很可能会跌入某个看似有趣的数据模式,进而选择某个特殊的机器学习模型。然后当你再使用测试集对泛化误差率进行估算时,估计结果将会过于乐观,该系统启动后的表现将不如预期那般优秀。------引自原书
Scikit-Learn提供了一些函数,可以通过多种方式将数据集分成多个子集。最简单的函数是train_test_split。
原书的思路是根据收入类别来进行分层抽样,可以仔细阅读原书的分析步骤。
2.3.4、寻找相关性
可以使用corr()方法轻松计算出每对属性之间的标准相关系数(也称为皮尔逊相关系数),最终发现最有潜力能够预测房价中位数的属性是收入中位数。
三、数据准备
3.1、数据清理
大部分的机器学习算法无法在缺失的特征上工作,所以我们要创建一些函数来辅助它。前面我们已经注意到total_bedrooms属性有部分值缺失,所以我们要解决它。有以下三种选择:
- 放弃这些相应的地区
- 放弃这个属性
- 将缺失的值设置为某个值(0、平均数或者中位数等都可以)
Scikit-Learn提供了一个非常容易上手的教程来处理缺失值:imputer。使用方法如下,首先,你需要创建一个imputer实例,指定你要用属性的中位数值替换该属性的缺失值:
from 3.2、处理文本和分类属性
分类属性ocean_proximity,因为它是一个文本属性,我们无法计算它的中位数值。大部分的机器学习算法都更易于跟数字打交道,所以我们先将这些文本标签转化为数字。
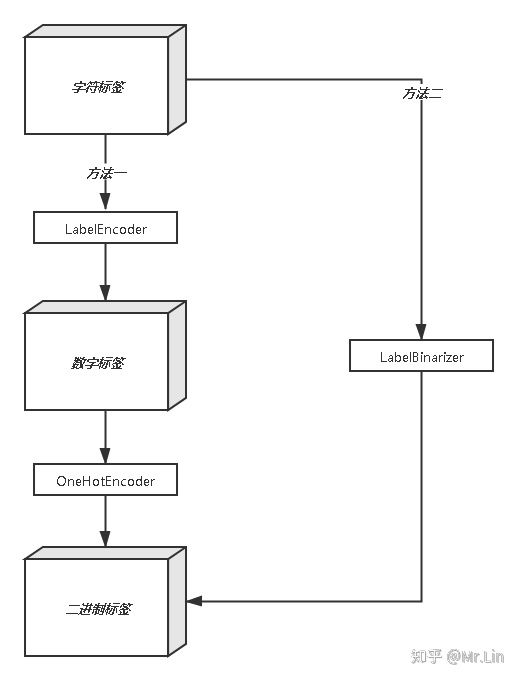
Scikit-Learn为这类任务提供了一个转换器LabelEncoder。但是这样会有一个问题,比如:假如有三种颜色特征:红、黄、蓝。 在利用机器学习的算法时一般需要进行向量化或者数字化。那么你可能想令 红=1,黄=2,蓝=3. 那么这样其实实现了标签编码,即给不同类别以标签。然而这意味着机器可能会学习到“红<黄<蓝”,但这并不是我们的让机器学习的本意,只是想让机器区分它们,并无大小比较之意。所以这时标签编码是不够的,需要进一步转换。因为有三种颜色状态,所以就有3个比特。即红色:1 0 0 ,黄色: 0 1 0,蓝色:0 0 1 。如此一来每两个向量之间的距离都是根号2,在向量空间距离都相等,所以这样不会出现偏序性,基本不会影响基于向量空间度量算法的效果。
Scikit-Learn提供了一个OneHotEncoder编码器,可以将整数分类值转换为独热向量。我们用它来将类别编码为独热向量。
使用LabelBinarizer类可以一次性完成两个转换(从文本类别转化为整数类别,再从整数类别转换为独热向量)
处理思路如下:
3.3、特征缩放
最重要也最需要应用到数据上的转换器,就是特征缩放。如果输入的数值属性具有非常大的比例差异,往往导致机器学习算法的性能表现不佳,当然也有极少数特例。案例中的房屋数据就是这样:房间总数的范围从6到39320,而收入中位数的范围是0到15。注意,目标值通常不需要缩放。
最小-最大缩放(又叫作归一化)很简单:将值重新缩放使其最终范围归于0到1之间。实现方法是将值减去最小值并除以最大值和最小值的差。对此,Scikit-Learn提供了一个名为MinMaxScaler的转换器。如果出于某种原因,你希望范围不是0~1,你可以通过调整超参数feature_range进行更改。
3.4、转换流水线
许多数据转换的步骤需要以正确的顺序来执行。而Scikit-Learn正好提供了Pipeline来支持这样的转换。
下面是一个数值属性的流水线例子:
from Pipeline构造函数会通过一系列名称/估算器的配对来定义步骤的序列。除了最后一个是估算器之外,前面都必须是转换器(也就是说,必须有fit_transform()方法)。
当调用流水线的fit()方法时,会在所有转换器上按照顺序依次调用fit_transform(),将一个调用的输出作为参数传递给下一个调用方法,直到传递到最终的估算器,则只会调用fit()方法。流水线的方法与最终的估算器的方法相同。在本例中,最后一个估算器是StandardScaler,这是个转换器,因此Pipeline有transform()方法可以按顺序将所有的转换应用到数据中(如果不希望先调用fit()再调用transform(),也可以直接调用fit_transform()方法)。
四、选择和训练模型
现在,我们已经完成了前面的所有步骤,现在是时候来进行模型的训练了。
4.1、线性回归模型
训练一个线性回归模型:
lin_reg 使用Scikit-Learn的mean_squared_error函数来测量整个训练集上回归模型的RMSE得出数据为:68628.413493824875
这显然不是一个好看的成绩:大多数地区的median_housing_values分布在120000到265000美元之间,所以典型的预测误差达到68628美元只能算是差强人意。这就是一个典型的模型对训练数据拟合不足的案例。
这种情况发生时,通常意味着这些特征可能无法提供足够的信息来做出更好的预测,或者是模型本身不够强大。
来训练一个DecisionTreeRegressor(决策树)。这是一个非常强大的模型,它能够从数据中找到复杂的非线性关系
tree_reg 发现输出为0.0,难道我们训练出了一个完美的模型,先别急,我们要验证下。
4.2、使用交叉验证来更好地进行评估
使用Scikit-Learn的交叉验证功能。以下是执行K-折(K-fold)交叉验证的代码:它将训练集随机分割成10个不同的子集,每个子集称为一个折叠(fold),然后对决策树模型进行10 次训练和评估——每次挑选1个折叠进行评估,使用另外的9个折叠进行训练。产出的结果是一个包含10次评估分数的数组。
from 顺便与线性回归模型进行对比:
lin_reg 最终发现决策树模型确实是严重过度拟合了,以至于表现得比线性回归模型还要糟糕。
试试最后一个模型:RandomForestRegressor。:
forest_reg 五、微调模型
5.1、网格搜索
用Scikit-Learn的GridSearchCV来替你进行探索。你所要做的只是告诉它你要进行实验的超参数是什么,以及需要尝试的值,它将会使用交叉验证来评估超参数值的所有可能的组合。
from 5.2、通过测试集评估系统
经过各种尝试后,现在是时候用测试集来评估最终模型的时候了。
final_model 至此我们完成了整个构建的流程。
- 参考资料 <<机器学习实战:基于Scikit-Learn和TensorFlow>>
- 源码地址:https://github.com/LinZiYU1996/My_MachineLearning/tree/master/Base_On_Scikit-Learn_TensorFlow/Chapter_2/Demo_2