推荐好文PCA的数学原理
本文将会用Python来实现PCA,帮助更好的理解
视频地址:https://www.youtube.com/watch?v=koiTTim4M-s
notebook地址:https://github.com/zhuanxuhit/nd101/blob/master/1.Intro_to_Deep_Learning/5.How_to_Make_Data_Amazing/pca_demo.ipynb
参考文章:https://plot.ly/ipython-notebooks/principal-component-analysis/
1. 获取数据
我们用的数据是150个鸢尾花,然后通过4个维度刻画
%matplotlib inline
%config InlineBackend.figure_format = 'retina'
import pandas as pd
df = pd.read_csv(
filepath_or_buffer='https://archive.ics.uci.edu/ml/machine-learning-databases/iris/iris.data',
header=None,
sep=',')
df.columns=['sepal_len', 'sepal_wid', 'petal_len', 'petal_wid', 'class']
df.dropna(how="all", inplace=True) # drops the empty line at file-end
df.head()
X = df.ix[:,0:4].values
y = df.ix[:,4].values
现在上面数据处理后,x是一个150 * 4 的矩阵,每一行都是一个样本,y是一个 150 * 1 是向量,每个都是一个分类
我们下一步是来看3类型的花怎么分布在4个特征上,我们可以通过直方图来展示
import plotly.plotly as py
from plotly.graph_objs import *
import plotly.tools as tls
# plotting histograms
tls.set_credentials_file(username='zhuanxuhit', api_key='30dCVmghG2CqKQqfSzsu')
traces = []
legend = {0:False, 1:False, 2:False, 3:True}
colors = {'Iris-setosa': 'rgb(31, 119, 180)',
'Iris-versicolor': 'rgb(255, 127, 14)',
'Iris-virginica': 'rgb(44, 160, 44)'}
for col in range(4):
for key in colors:
traces.append(Histogram(x=X[y==key, col],
opacity=0.75,
xaxis='x%s' %(col+1),
marker=Marker(color=colors[key]),
name=key,
showlegend=legend[col]))
data = Data(traces)
layout = Layout(barmode='overlay',
xaxis=XAxis(domain=[0, 0.25], title='sepal length (cm)'),
xaxis2=XAxis(domain=[0.3, 0.5], title='sepal width (cm)'),
xaxis3=XAxis(domain=[0.55, 0.75], title='petal length (cm)'),
xaxis4=XAxis(domain=[0.8, 1], title='petal width (cm)'),
yaxis=YAxis(title='count'),
title='Distribution of the different Iris flower features')
fig = Figure(data=data, layout=layout)
py.iplot(fig,filename = 'basic-line')
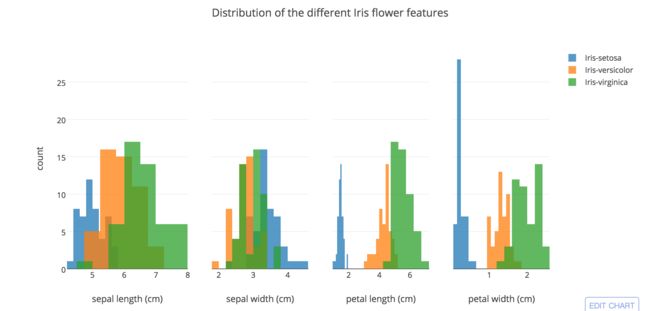
规范化
我们将数据转化为 mean=0 and variance=1 的数据
from sklearn.preprocessing import StandardScaler
X_std = StandardScaler().fit_transform(X)
X_std.shape
(150, 4)
import numpy as np
mean_vec = X_std.mean(axis=0)
mean_vec # 均值为0
array([ -4.73695157e-16, -6.63173220e-16, 3.31586610e-16,
-2.84217094e-16])
X_std.std(axis=0) # 方差为1
array([ 1., 1., 1., 1.])
# 获得原矩阵的信息
scaler = StandardScaler().fit(X)
scaler.mean_
array([ 5.84333333, 3.054 , 3.75866667, 1.19866667])
scaler.scale_
array([ 0.82530129, 0.43214658, 1.75852918, 0.76061262])
x_scale = scaler.transform(X)
# np.mean(x_scale,axis=0) # 均值为0
特征分解
下一步我们就做PCA的核心:计算特征值和特征向量
列举下目前我们的状态
- 我们有150个4维的数据,组成了 4 * 150的矩阵 X
- 假设 C = 1/150 * X * T(X), 则C是一个对称矩阵,而且是 4 * 4 的,其对角是各个字段的方差,而第i行j列和j行i列元素相同,表示i和j两个字段的协方差。
X_scale = X_std.T
X_scale.shape
(4, 150)
cov_mat = X_scale.dot(X_scale.T)/X_scale.shape[1]
print('Covariance matrix \n%s' %cov_mat)
Covariance matrix
[[ 1. -0.10936925 0.87175416 0.81795363]
[-0.10936925 1. -0.4205161 -0.35654409]
[ 0.87175416 -0.4205161 1. 0.9627571 ]
[ 0.81795363 -0.35654409 0.9627571 1. ]]
print('NumPy covariance matrix: \n%s' %np.cov(X_scale))
NumPy covariance matrix:
[[ 1.00671141 -0.11010327 0.87760486 0.82344326]
[-0.11010327 1.00671141 -0.42333835 -0.358937 ]
[ 0.87760486 -0.42333835 1.00671141 0.96921855]
[ 0.82344326 -0.358937 0.96921855 1.00671141]]
接着我们计算协方差矩阵cov_mat的特征值和特征向量
cov_mat = X_scale.dot(X_scale.T)/X_scale.shape[1]
eig_vals, eig_vecs = np.linalg.eig(cov_mat)
print('Eigenvectors \n%s' %eig_vecs)
print('\nEigenvalues \n%s' %eig_vals)
Eigenvectors
[[ 0.52237162 -0.37231836 -0.72101681 0.26199559]
[-0.26335492 -0.92555649 0.24203288 -0.12413481]
[ 0.58125401 -0.02109478 0.14089226 -0.80115427]
[ 0.56561105 -0.06541577 0.6338014 0.52354627]]
Eigenvalues
[ 2.91081808 0.92122093 0.14735328 0.02060771]
# eig_vecs.T.dot(cov_mat).dot(eig_vecs) = eig_vals 对象矩阵
我们也可以通过其他命令一次性就获取特征向量和特征值:
cor_mat2 = np.corrcoef(X.T)
eig_vals, eig_vecs = np.linalg.eig(cor_mat2)
print('Eigenvectors \n%s' %eig_vecs)
print('\nEigenvalues \n%s' %eig_vals)
Eigenvectors
[[ 0.52237162 -0.37231836 -0.72101681 0.26199559]
[-0.26335492 -0.92555649 0.24203288 -0.12413481]
[ 0.58125401 -0.02109478 0.14089226 -0.80115427]
[ 0.56561105 -0.06541577 0.6338014 0.52354627]]
Eigenvalues
[ 2.91081808 0.92122093 0.14735328 0.02060771]
选择主成分
现在我们有了特征向量,特征向量中的每一个都可以认为是单位长度为1的基,我们来验证下:
for ev in eig_vecs:
print(ev)
np.testing.assert_array_almost_equal(1.0,
np.linalg.norm(ev))
print('Everything ok!')
[ 0.52237162 -0.37231836 -0.72101681 0.26199559]
[-0.26335492 -0.92555649 0.24203288 -0.12413481]
[ 0.58125401 -0.02109478 0.14089226 -0.80115427]
[ 0.56561105 -0.06541577 0.6338014 0.52354627]
Everything ok!
np.sum(( eig_vecs[0] )**2) # np.linalg.norm 范数
0.99999999999999922
现在有4个向量基,下一步要确定的是哪个方向上投影后能够让方差最大
# Make a list of (eigenvalue, eigenvector) tuples
eig_pairs = [(np.abs(eig_vals[i]), eig_vecs[:,i]) for i in range(len(eig_vals))]
# Sort the (eigenvalue, eigenvector) tuples from high to low
eig_pairs.sort()
eig_pairs.reverse()
# Visually confirm that the list is correctly sorted by decreasing eigenvalues
print('Eigenvalues in descending order:')
for i in eig_pairs:
print(i[0])
Eigenvalues in descending order:
2.91081808375
0.921220930707
0.147353278305
0.0206077072356
解释方差
分析完信息最多的投影方向后,下面就是要决定我们要选择多少个投影基来投影了
tot = sum(eig_vals) # 所有特征值的和
var_exp = [(i / tot)*100 for i in sorted(eig_vals, reverse=True)] # 每个特征值的百分比
var_exp
[72.770452093801353,
23.030523267680632,
3.6838319576273935,
0.51519268089062353]
cum_var_exp = np.cumsum(var_exp) # 计算累计
array([ 72.77045209, 95.80097536, 99.48480732, 100. ])
tot = sum(eig_vals)
var_exp = [(i / tot)*100 for i in sorted(eig_vals, reverse=True)]
cum_var_exp = np.cumsum(var_exp)
trace1 = Bar(
x=['PC %s' %i for i in range(1,5)],
y=var_exp,
showlegend=False)
trace2 = Scatter(
x=['PC %s' %i for i in range(1,5)],
y=cum_var_exp,
name='cumulative explained variance')
data = Data([trace1, trace2])
layout=Layout(
yaxis=YAxis(title='Explained variance in percent'),
title='Explained variance by different principal components')
fig = Figure(data=data, layout=layout)
py.iplot(fig)
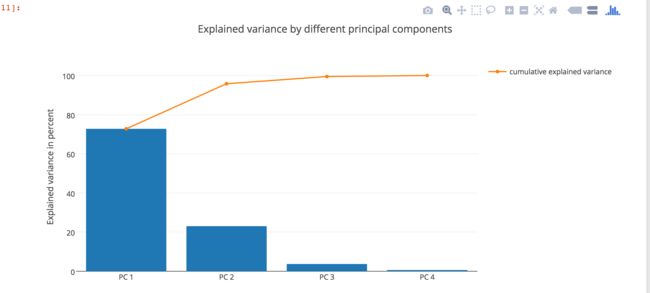
上图可以显示出:PC1的贡献最大
投影矩阵
投影矩阵就是我们之前计算出来的特征矩阵,选择前两个多的特征向量
cor_mat2 = np.corrcoef(X.T)
eig_vals, eig_vecs = np.linalg.eig(cor_mat2)
print('Eigenvectors \n%s' %eig_vecs)
print('\nEigenvalues \n%s' %eig_vals)
eig_vecs.T.dot(cov_mat).dot(eig_vecs)
Eigenvectors
[[ 0.52237162 -0.37231836 -0.72101681 0.26199559]
[-0.26335492 -0.92555649 0.24203288 -0.12413481]
[ 0.58125401 -0.02109478 0.14089226 -0.80115427]
[ 0.56561105 -0.06541577 0.6338014 0.52354627]]
Eigenvalues
[ 2.91081808 0.92122093 0.14735328 0.02060771]
array([[ 2.91081808e+00, 0.00000000e+00, 6.66133815e-16,
7.77156117e-16],
[ 8.32667268e-17, 9.21220931e-01, -4.16333634e-16,
1.94289029e-16],
[ 5.82867088e-16, -4.02455846e-16, 1.47353278e-01,
-2.08166817e-17],
[ 9.26342336e-16, 1.94505870e-16, -4.07660017e-17,
2.06077072e-02]])
# 此时我们的投影矩阵 P = eig_vecs.T
P = eig_vecs.T
matrix_w = P[[0,1]]
print('Matrix W:\n', matrix_w)
Matrix W:
[[ 0.52237162 -0.26335492 0.58125401 0.56561105]
[-0.37231836 -0.92555649 -0.02109478 -0.06541577]]
映射到新的2维空间
Y = matrix_w.dot(X_std.T).T
# Y 每一行代表一个数据
traces = []
for name in ('Iris-setosa', 'Iris-versicolor', 'Iris-virginica'):
trace = Scatter(
x=Y[y==name,0],
y=Y[y==name,1],
mode='markers',
name=name,
marker=Marker(
size=12,
line=Line(
color='rgba(217, 217, 217, 0.14)',
width=0.5),
opacity=0.8))
traces.append(trace)
data = Data(traces)
layout = Layout(showlegend=True,
scene=Scene(xaxis=XAxis(title='PC1'),
yaxis=YAxis(title='PC2'),))
fig = Figure(data=data, layout=layout)
py.iplot(fig)
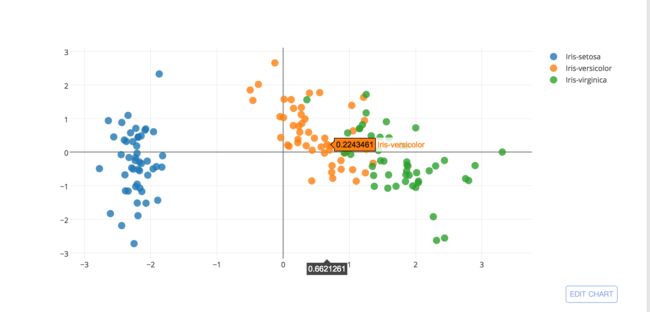
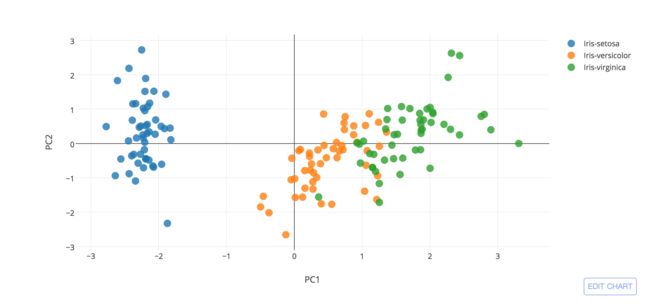
上面我们自己一步一步的实现了PCA,达到了降维度的目的,我们可以使用scikit-learn中的方法快速的实现:
from sklearn.decomposition import PCA as sklearnPCA
sklearn_pca = sklearnPCA(n_components=2)
Y_sklearn = sklearn_pca.fit_transform(X_std)
traces = []
for name in ('Iris-setosa', 'Iris-versicolor', 'Iris-virginica'):
trace = Scatter(
x=Y_sklearn[y==name,0],
y=Y_sklearn[y==name,1],
mode='markers',
name=name,
marker=Marker(
size=12,
line=Line(
color='rgba(217, 217, 217, 0.14)',
width=0.5),
opacity=0.8))
traces.append(trace)
data = Data(traces)
layout = Layout(xaxis=XAxis(title='PC1', showline=False),
yaxis=YAxis(title='PC2', showline=False))
fig = Figure(data=data, layout=layout)
py.iplot(fig)
总结
最后我们来总结下整个过程:
