来源:https://mp.weixin.qq.com/s/Kv1Qq4118I2itYwPYyQUoA
1写在前面
天翼电子商务有限公司(简称“甜橙金融”)是中国电信的全资子公司,2011 年 3 月成立于北京,作为中国人民银行核准的第三方支付机构,是兼具金融、电信、互联网文化的跨界国家高新技术企业。目前公司对实时性计算的需要及应用越来越多,本文选取了其中之一的 Spark Streaming 来介绍如何实现高吞吐量并具备容错机制的实时流应用。在甜橙金融监控系统项目中,需要对每天亿万级(10T)的日志记录进行实时的指标统计,在生产者一端,我们通过 Flume 将数据存入 Kafka 当中, 而在消费者一端,我们利用 Spark Streaming 从 Kafka 中不断的拉取数据进行指标统计并存入外部存储中。
本文将从以下几个方面进行介绍,目的是带领大家对实时流处理有个初步的认识,一起交流学习。
监控系统架构及存在的主要问题
Spark Streaming 流处理框架介绍
Streaming 相关的优化
Streaming 任务的监控
写在最后
2监控系统架构及存在的主要问题系统架构介绍
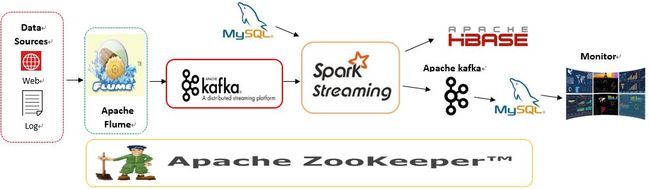
整个实时监控系统的架构是先由 Flume 收集服务器产生的日志 Log 和前端埋点数据, 然后实时把这些信息发送到 Kafka 分布式发布订阅消息系统,接着由 Spark Streaming 消费 Kafka 中的消息,同时消费记录由 Zookeeper 集群统一管理,这样即使 Kafka 宕机重启后也能找到上次的消费记录继而进行消费。在这里 Spark Streaming 首先从 MySQL 读取规则然后进行 ETL 清洗并计算多个聚合指标,最后将结果的一部分存储到 Hbase 中,另一部分重新发回到 Kafka 中再消费更新到 MySQL 中,监控前端实时获取指标进行展示。
主要问题
在上面的框架介绍中,下游监控系统的指标数据来源于 Spark Streaming 的实时计算,可见 Streaming 计算处于极为重要的环节,而计算性能不足就会成为整个系统的瓶颈。大部分时候我们 Spark 指标计算都能应付过来,但是在节日流量翻倍的情况下就力不从心了,为应对这种情况之前采取的措施一般是关闭一些非关键性日志接口把监控流量降下来。虽然此举能暂时解决问题,但仍需要治标更治本的方法。
首先来看看优化前 Streaming 的计算能力。
图一所示为每批次(30 秒)800W+ 日志流量下,Spark Streaming 计算大概需要 50 多秒。虽无明显延时,但计算能力很弱鸡 14w/s
图 1
随着流量不断的增大,如图 2 所示为每批次(时间 30 秒)1000W+ 条日志流量下,Spark 计算已严重超时,越来越多的 batch 加入到 queue 的队列等待处理,此时监控系统基本失效。
图 2
既然痛点已找到,那么剩下要做的就是想办法去优化。下文在讲如何优化前,先带大家认识下流式处理框架中的两个经典好搭档 Spark Streaming + Kafka。
3Spark Streaming + Kafka 流处理框架为什么选择 Spark Streaming 和 Kafka
Kafka 支持分布式及出色的吞吐量
-
Spark Streaming 流式处理框架已被各大公司广泛应用且成熟度高,支持大部分的数据源和存储,如下图所示其丰富生态圈
[图片上传中...(image-6bc74e-1536914295737-0)]
Kafka 与 Spark Streaming 集成度高
Spark Streaming 初识
Spark Streaming 接受实时输入数据并将数据切分成多个 batches, 然后由 Spark engine 进行计算并将结果输出到外部存储。

接下来看看 Spark Streaming 从 Kafka 中接受数据的两种方式。
基于 Receiver 方式
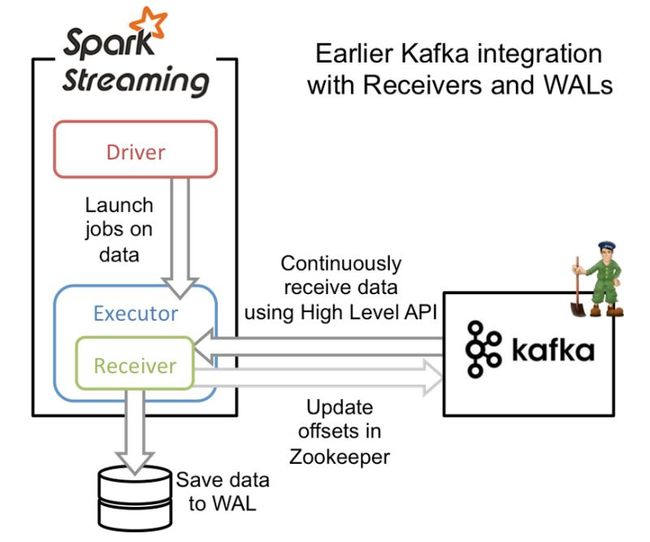
这种方式使用 Receiver 方式接受数据,实现是以 Kafka 高阶用户 API 接口,收到的数据会存到 Spark executor,之后 Spark Streaming 提交 Job 处理这些数据。为了保证数据不会丢失,需要开启 Write Ahead Logs,流程如下图所示:
基于 Direct 方式
在 Spark 1.3 之后,引入了 Direct 方式以提供更强的端到端的保证。不同于 Receiver 方式,其会周期性的获取 Kafka 每个 topic 中每个 Partition 最新的 offsets。之后 Spark job 会基于 Kafka simple API 读取 Kafka 相应 Offset 数据并进行处理,流程如下图所示:
该方式相对于 Receiver 方式具有以下优势:
简化的并行度:基于 Receiver 的方式中要提高数据传输并行度我们需要创建多个 Receiver 实例之后再 Union 起来合并成一个 Dstream。而 Direct 方式中提供了更为简单的映射关系,Kafka 中的 partition 与 Spark RDD 中的 partition 是一一映射的,因而可以并行读取数据。
高效性:在 Receiver 的方式中,为了达到零数据丢失需要将数据备份到 Write Ahead Log 中,这样系统中就保存了两份数据浪费资源。而 Direct 方式只要知道当前消费的 Offsets 就能恢复出相应的数据。
精确一次的语义保证:基于 Receiver 的方式中,通过 Kafka 的高阶 API 接口从 Zookeeper 中获取 offset 值,这也是传统的从 Kafka 中读取数据的方式,但由于 Spark Streaming 消费的数据和 Zookeeper 中记录的 offset 不同步,这种方式偶尔会造成数据重复消费。而第二种方式,直接使用了简单的低阶 Kafka API,Offsets 可以利用 Spark Streaming 的 checkpoints 进行记录来消除这种不一致性。
以上翻译自官方文档。既然 Direct 方式有这么多优点,那么在我们的监控系统中理所当然也用了这种方式,同时为了能使基于 Zookeeper 的 Kafka monitor 工具生效,我们也实现了 Offset 的管理,具体流程如下:
Spark Streaming 任务启动后首先去 Zookeeper 中去读取特定 topic 中每个 Partition 的 offset 并组装 fromOffsets 变量;
Spark Streaming 获取到 fromOffsets 后通过 KafkaUtils.createDirectStream 去消费 Kafka 的数据;
读取 Kafka 数据然后进行批的逻辑处理,如下图所示为该 Job 的 DAG,包括一些基本的 RDD 算子操作 (flatMap, reduceByKey, Map 等), 并将计算结果存储到 Hbase 和回吐到 Kafka 中,最后更新 offsets 到 Zookeeper 中。
4Spark Streaming 性能优化及任务监控
重点来了,那么说起优化,我们首先想到的就是最大限度利用集群资源,将硬件性能压榨到极致,先看看如何在用 spark-submit 提交命令的时候进行资源调优。
资源参数调优
增加 Driver 和 Executor 的内存(driver-memory、executor-memory)
通过增加 Driver 和 Executor 的内存数量,可以减小程序 Out of memory 和 意外崩溃 产生的概率,当然也不能无限制增加以免造成资源的浪费或者导致其它任务申请资源失败。
设置合理的 CPU 个数
--num-executors 和 --executor-cores 两个参数配合使用来调节计算资源占有情况。通常对于集群中一定量的 CPU Core,设置较多的 Executor 个数和较少的 Executor core 个数来达到资源最大使用率。
结合内存和 CPU 参数,我们来举个例子,看看怎么设置会比较合理。
假设在拥有 6 个节点,每个节点有 16 个 Core 和 64G 内存集群中提交 Job, 一种可能的配置参数如下:
--num-executors 6 –executor-cores 15 –executor-memory 63G
这种方式其实不太合理,原因如下:
由于我们的 OS 以及 Hadoop daemons 要占用一定内存,因此 yarn.nodemanager.resources.memory-mb 和 yarn.nodemanager.resources.cpu-vcores 不可能占用 100% 资源,一般是 63 * 1024 和 15Core.
Application master 也会占用一个 core, 因此在 master 节点上也不可能设置为 15 个 core
每个 executor 设置 15Core 会造成低效的 HDFS I/O 吞吐量
鉴于上面的原因,一种更为合理的的设置是:
--num-executors 17 –executor-cores 5 –executor-memory 19G
增加 parallelism:增加 Spark Partition 数量
Partition 即 Spark 中的数据分区,每个 task 在同一时间只能处理一个 Partition 的数据,这个值不能设置的太小也不能设置的太大。
设置的太大,每个分区中的数据很少,因此会需要更多的 task 来处理这些数据,增加任务调度器的负担
设置的太小,每个分区中的数据很多,也会对内存造成压力,executor 无法最大程度利用集群计算资源。
通过 spark.default.parallelism 可以设置 spark 默认的分区数量,在这里我们设置的 1000.
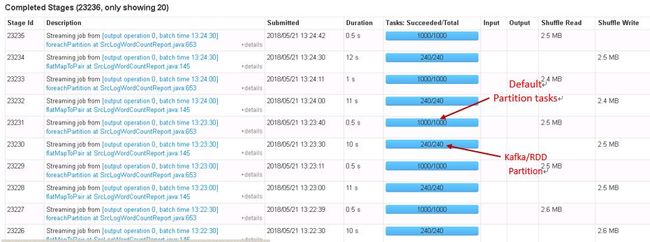
此外在 Spark Streaming + Kafka 的案例中,我们采用 Direct 方式从 Kafka 中获取数据,此时 Kafka partition 的数量和 Spark RDD 的分区数量是 1:1 映射的关系,而调优之前该 topic 创建时的分区数量是 64,并发度太小导致集群资源利用不够。我们一开始采取的优化方式是创建 InputDstream 之后先 Repartition 到一个更大的并行度,然后进行逻辑计算,结果证明该方式较之前性能上有一定提升但还是没有达到我们想要的理想结果,这是由于 repartition 会造成 Shuffle 操作,而 Shuffle 比较耗时,会引起大量的磁盘 IO, 序列化、反序列化、网络数据传输等操作,因此要尽量避免。之后我们直接从数据源头 Kafka 那边增加 Topic 分区数(240),从而极大的提升了处理效率。如图所示:
设置合理的批处理时间和 Kafka 数据拉取速率
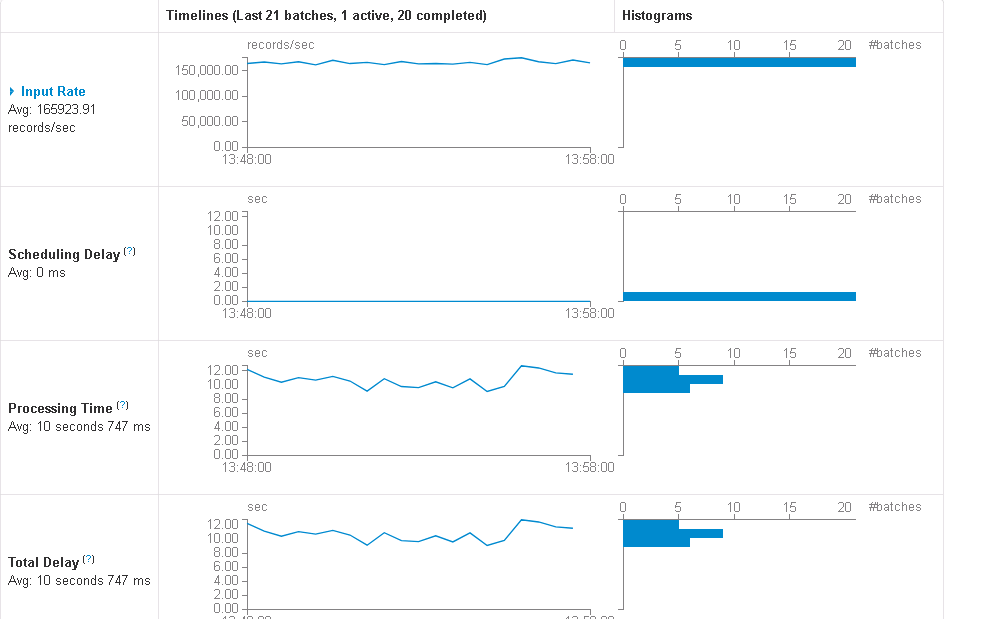
在 StreamingContext 初始化的时候需要设置批处理时间,而这个值不能设置的太小,太小不仅会导致 SparkStreaming 频繁的提交作业增加系统调度的负担,如果处理不过来容易造成作业的积压发生阻塞。此外还要根据生产者写入 Kafka 的速率以及 Streaming 本身消费数据的速率设置合理的 Kafka 读取速率(spark.streaming.kafka.maxRatePerPartition),使得 Spark Streaming 的每个 task 都能在 Batch 时间内及时处理完 Partition 内的数据,使 Scheduling Delay 尽可能的小。
最后还可以设置 spark.steaming.backpressure.enabled 为 true,这就使得如果在某一时刻数据量突然增大导致处理时间远大于 Batch interval 的情况下,告诉 Kafka 你需要降低发送速率了。下图所示为理想的处理状态。
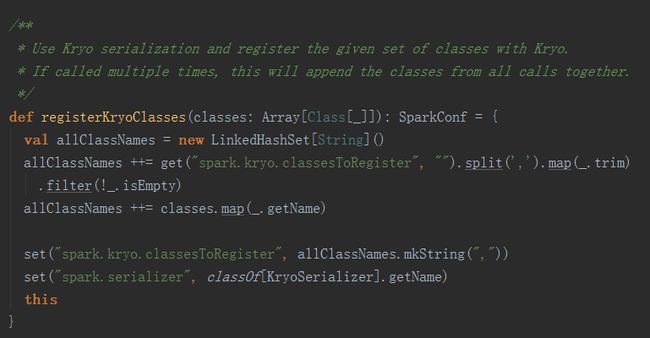
使用 Kryo 序列化
Spark Streaming 在传输、使用对象的时候要用到序列化和反序列化,而 Kryo 序列化方式比 Java 序列化机制性能高 10 倍,因此我们可在使用的时候注册自定义类型,如下函数所示:
设置 Streaming job 的并行度
这里的 job 主要由两个参数决定:
Spark.scheduler.mode(FIFO/FAIR)
Spark.streaming.concurrentjobs
在每个 batch 内,可能有一批 Streaming job, 默认是 1,这些 job 由 jobExecutor 执行并提交,而 JobExecutor 是一个默认池子大小为 1 的线程池,大小由参数 Spark.streaming 。concurrentjobs 控制。如果 concurrentjobs 设置为 2,那么只要资源允许,那么会同时提交执行两个 job,否则仍顺序执行。
开发调优
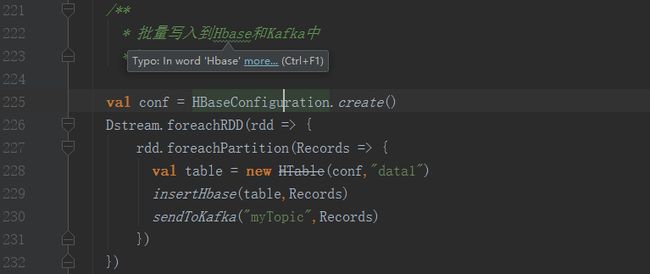
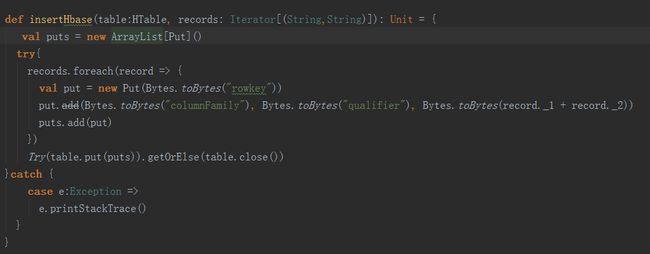
Hbase 输出操作
在我们的项目中,需要将 Spark Streaming 计算完的结果存入到 Hbase 中,这里我们采用的是批量 Put 数据到 Hbase 中,而非每次插入单条数据,参考如下事例:
输出到 Kafka
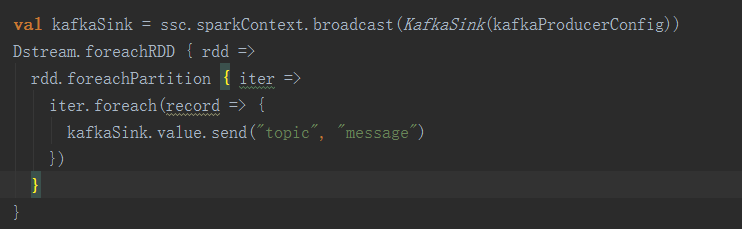
此外我们还会将计算结果回吐到 Kafka 中。通常你可能会 Google “Spark Streaming to kafka”来寻找案例,而大多数情况你会找到下面这样的例子,当然很大程度上你也会这么写。针对 Partition 中的每条数据建立一个 Kafka Producer, 然后再发送数据,这种做法不灵活且低效。
比较高效的做法有两种:
定义 Kafka producer 为 lazy 并广播到每个 executor 上,之后就可以用这个 producer 发送数据,事例如下:
使用也比较方便:
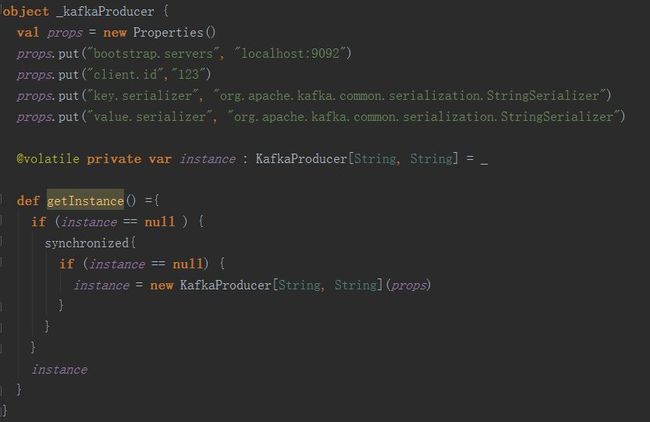
或者使用单例模式:
遇到的坑
经过上述调优方案后,Spark Streaming 实时处理能力较之前有了质的提高,但是我们也经常会发现一些异常现象。在流量逐步升高的情况下,会出现丢包的情况,Streaming 的计算性能也受到了很大的影响。通过使用 Zabbix 工具查看网卡流量,发现有时候 eth3 网卡出口流量能达到 638Mbps, 如下图所示,而我们的网卡是千兆网,并且在存在多个 kafka Consumer 的情况下就不难解释之前的丢包现象了,同样 spark 计算过程中需要传输数据,因为受到带宽的限制也会导致计算性能的下降。
随后我们将 Kafka 集群中的网卡换到万兆,重新提交 Spark Streaming 任务后发现计算性能提升数倍:上图为调优前约 15w/s 的处理量,下图为调优后每秒 50w/s 的处理量。
VS
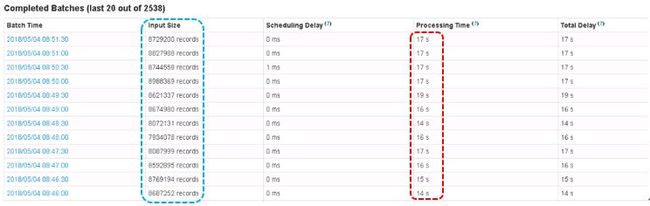
当在一个 Batch 时间内输入数据达到 1000W 以上事件时,Streaming 仍能很好的 handle,计算性能仍是 50W+/s 的处理速率,相比调优前基本失效的状态也大大提高了稳定性。
任务监控
对于 Spark Streaming 任务的监控可以直观的通过 Spark Web UI ,该页面包括 Input Rate, Scheduling Delay、Processing Time 等,但是这种方法运维成本较高,需要人工不间断的巡视。
另一种推荐的方式可以通过 StreamingListener 接口获取 Scheduling Delay 和 Processing Time,事例如下:
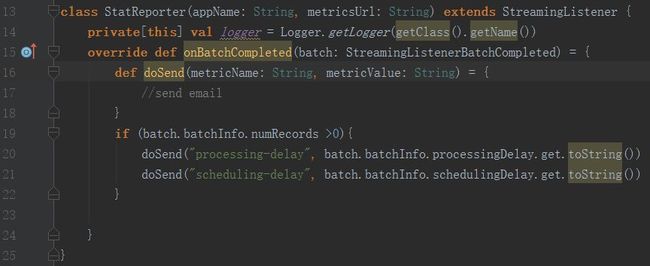
除此之外你还可以自己写 Python 脚本在 yarn 管理界面解析该应用的 ApplicationMaster 的地址,之后再通过 Spark Streaming 的 UI 去获取相关参数。
5写在最后
目前我们在做 Structured Streaming 的测试,相关文档参见:
http://spark.apache.org/docs/latest/structured-streaming-programming-guide.html
该实时流框架端到端的延迟为 100ms,而且在 Spark 最新版本 2.3 中支持 Continuous Processing 模式,延迟能降到更低 1ms,对比 Spark Streaming 就要好很多。
总之性能优化的路还很长,这就需要我们不断的尝试新的技术新的框架,最后希望本文能给正在做 spark streaming 实时流优化的同学带来一些帮助,欢迎大家一起交流。
6参考文献:
1.http://blog.cloudera.com/blog/2015/03/how-to-tune-your-apache-spark-jobs-part-2/
2.https://ngorchakova.github.io/jvmwarstories/spark-kafka-sink/
作者介绍
张璐波,甜橙金融大数据实时计算专家,高级架构师,对海量数据实时处理有深入的研究,涉及 Kafka, Spark Streaming, Structured Streaming, Flink, Strom 等开源流计算框架。目前主要工作集中在实时风控,智能风控以及流计算平台的搭建。