目标检测综述
文章目录
- 目标检测综述
-
- 深度目标检测算法进程
-
- 双阶段目标检测器
-
- RCNN
- SPPNet
- Fast RCNN
- FasterRCNN
- FPN
- 单阶段目标检测器
-
- YOLO
- SSD
- RetinaNet
- 目标检测最新进展
-
- 更好的特征提取网络
- 定位损失函数的改进
- 基于无锚框的网络设计
-
- FSAF用于尺度选择
- FCOs
- 总结与展望
-
- 总结
- 展望
目标检测综述
目标检测是一项重要的计算机视觉任务,用于检测数字图像中某一类视觉对象(如人、动物或汽车)的实例。作为一个计算机视觉领域的一个基本问题(如实例分割、图像捕捉、目标跟踪等等),目标检测已经形成了一定的基础。在近几年,深度学习技术的快速发展给目标检测带来了生机,导致了显著的突破并且成为了当下的研究热点。目标检测也被广泛应用于真实世界中,例如自动驾驶、机器人视觉、视频监控等等。所以本文将对从深度学习引入目标检测开始,直到现在state-of-art的目标检测算法进行介绍。然后针对近期提出的新颖算法中的思路进行分析。最后,进行总结与对未来目标检测方向的展望。
深度目标检测算法进程
在深度学习流行之前,目标检测都是基于人工特征进行的。由于缺乏有效的图像表示方法,研究者们只能通过设计复杂而精致的特征表示(比如颜色特征)[1]和一系列加速技巧(比如滑动窗口机制[2])来满足当时缺乏的计算资源。
而当人工特征的性能逐渐饱和,目标检测的发展在2010年后陷入了瓶颈。直至2012年AlexNet的诞生,研究者们看到了卷积神经网络能够在图像上学习到鲁棒的特征表示。从那时起,目标检测开始以前所未有的速度发展。
在深度学习邻域,目标检测可以被分为两个类别:“two-stage detection”和“one-stage detection”,前者将检测定义为一个“由粗到细“的过程,而后者将其定义为”一步完成“的过程。
双阶段目标检测器
RCNN
RCNN(Regions with CNN features)[3]作为第一个基于深度学习的目标检测器在2014年被提出。其背后的原理很简单:先对一系列目标候选框进行提取(由selective search[4]完成)。然后把每个候选框修正到固定大小送入训练好的ImageNet模型中(比如AlexNet)来提取出特征。最终,用线性SVM分类器来预测物体时候出现在候选框中以及其类别。

图1-1 RCNN 网络架构图
RCNN在在VOC07数据集上取得了极佳的表现,把在该数据集上的平均准确率(mAP)从33.7%提升到了58.5%(前者为效果最好的传统目标检测算法DPM-v5)。
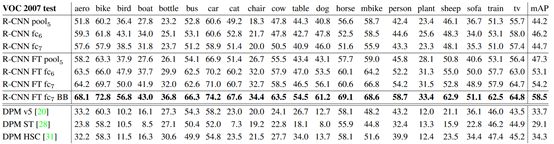
表1-1RCNN在VOC 2007上的精度
尽管RCNN取得了如此的进步,然仍留下了如下缺陷:其在大量的重叠候选目标(一张图片超过2000个候选框)上存在冗余的特征计算,这导致了检测速度极慢(在GPU上每检测一张图片需要14s)。而这一问题在同年何凯明提出的SPPNet[5]中得到了解决。
SPPNet
在2014年,在微软亚洲研究院的何凯明提出了Spatial Pyramid Pooling Networks(SPPNet)[5]。之前的CNN模型需要把输入图像的大小固定为224×224来作为AlexNet的输入。SPPNet的主要贡献为提出了一个空间金字塔池化层(Spatial Pyramid Pooling,SPP),这使得CNN可以生成固定长度的表示形式,而与感兴趣的图像/区域的大小无关,而无需对其进行重新缩放。当使用SPPNet进行目标检测时,只需要在原始图像上计算一次特征图,然后可以生成任意区域的固定长度表示形式以训练检测器,从而避免了重复计算卷积特征。SPPNet能在不牺牲任何检测精度的情况下速度比RCNN快20倍以上。
简单来说,其空间池化层的具体做法是:将不同大小的特征图进行三次不同尺寸的池化,分别为4×4,2×2,1×1。那么最终卷积得到了三个长度分别为16,4,1的特征向量,然后将这三个向量拼接为一个16+4+1即21维的向量来作为全连接层的输入。
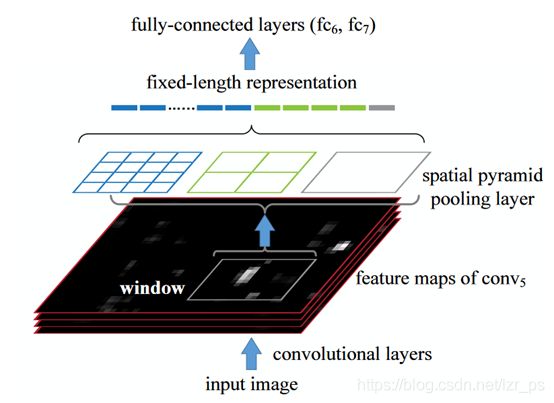
图1-2 SPPNet网络架构图
尽管SPPNet有效的提高了检测速度,但仍有一些缺陷:首先,训练仍是多阶段的(仍然要采用selective search找出候选项)。其次,SPPNet只对RCNN的全连接层进行了微调而忽略了之前的网络结构。在接下来的一年,研究者提出了Fast RCNN[6]来解决以上问题。
Fast RCNN
在2015年,R.Girshick 提出了Fast RCNN检测器[6],这是继RCNN和SPPNet之后的又一大进步。Fast RCNN使得我们能在同样的网络配置下同时训练一个检测器和一个边界框的回归器。在VOC07数据集上,Fast RCNN把平均准确率从58.5%(RCNN)提升到了70.0%,且其检测速度比RCNN要快200倍。
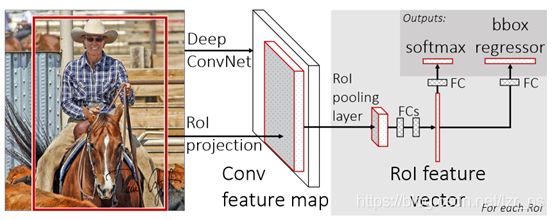
图1-3 Fast RCNN网咯架构图
由上图可知,在卷积网络的最后一层,FastRCNN采用了Rol pooling代替了之前的Max pooling,具体做法是把最后一层的特征图分为H×W个小格,然后对每个小格做Max pooling,最后得到的特征图则都是H×W大小。另外Fast RCNN去除了SVM分类器,而是用softmax分类实现了端到端的多任务训练(候选框生成除外,所以整个网络不是端到端的)。
虽然FastRCNN整合了RCNN和SPPNet的优势,但是其速度仍然受限于候选框的生成。所以我们能不能使用CNN模型来获得候选框呢?Faster RCNN回答了这一问题。
FasterRCNN
在2015年,S.Ren在FastRCNN提出后不久提出了Faster RCNN检测器。FasterRCNN[7]是第一个真正意义上的端到端的目标检测模型,并且能做到接近实时检测(在COCO数据集上mAP=42.7%,VOC07 Map=73.2% 17fps)Faster RCNN的主要贡献在于对区域候选网络的提出(Region Proposal Network ,RPN),这使得候选框的生成几乎不耗费时间。

图1-4 区域候选网络RPN
上图即为RPN的实现做法,可以看到RPN是通过滑动窗口的中心生成k个不同尺寸、不同大小的锚框(anchor box)作为候选框。这使得候选框的生成也被整合到了整个网络结构中。锚框也成为了主流目标检测器的必备组件。但是随着基于锚框的网络性能逐渐饱和,如今也有研究者开始基于无锚框的网络提出了一些思路(如FASF、FCOs,详情请看第2.4章节)。
尽管Faster RCNN突破了Fast RCNN的速度瓶颈,但是其对一些尺度相差较大的物体取得了较低的召回率。
FPN
在2017年,特征金字塔网络(Feature Pyramid Networks, FPN)[8]在Faster RCNN的架构上被提出。在FPN被提出之前,大多的检测器只对主干网络的最后一层进行检测。尽管层数越深的特征图包含的语义信息越丰富,但其不利于对目标的定位。为此,在FPN中开发了具有横向连接的自上而下的体系结构,用于构建各种规模的高级语义。

图1-5 各种主干网络图
上图为目标检测中常用的主干网络结构,其中(d)为FPN的结构。可以看到FPN中每一层的特征图都是由上一层的特征图的上采样与对原始图像的同一层进行1×1卷积而成。这使得整个网络能获得不同尺度上的语义信息而不用对原图像进行多次采样(比如a)。自从在主干网络上采用了金字塔结构,FPN展现了其在尺度变化较大的目标中的优势。现在,FPN已经成为了许多最新检测器的基本模块。
单阶段目标检测器
YOLO
YOLO(You Only Look Once)[10]是由R.Joseph等人在2015提出的。这是在深度学习领域第一个单阶段检测器。其特点是速度极快,在VOC上保证mAP=52.7%时能跑到155fps。作者摒弃了此前“候选检测+验证”的基本框架。相反,使用了一个新的思路:将一个单神经网络应用在一整张图片上。该网络将图像划分为多个区域,并同时预测每个区域的边界框和概率。随后,作者又提出了YOLO的v2和v3版本,进一步提高了检测精度且保持了其检测速度。
尽管YOLO的检测速度有了很大的提高,但与两级检测器相比,它的定位精度却下降了,特别是对于一些小物体。 YOLO的后续版本和后者提出的SSD更加关注了这个问题。
SSD
SSD[11]由W. Liu在2015年提出。它是深度学习时代的第二个一级检测器。 SS的主要贡献是引入了多参考和多分辨率检测技术(将在2.3.2节中介绍),从而显着提高了一级检测器的检测精度,尤其是对于某些小物体。SSD的优点是检测速度和准确性均达到了中间水平(VOC07 mAP = 76.8%)。,VOC12 mAP = 74.9%,COCO mAP @ .5 = 46.5%,快速版本的运行速度为59fps)。 SSD与以前的探测器之间的主要区别在于,前者可探测在网络的不同层上具有不同的规模的物体,而后者仅在其顶层上运行检测。
RetinaNet
尽管其速度快,操作简便,但多年来,一级检测器一直困扰于相比于二级检测器的准确性。T.-Y.Linetal在2017年发现了背后的原因并提出了RetinaNet[12]。 他们声称,在密集探测器的训练过程中遇到的前景-背景类别极度失衡是主要原因。 为此,通过重塑标准的交叉熵损失,在RetinaNet中引入了一个名为“Focal loss”的新损失函数,以便检测器在训练过程中将更多的注意力放在困难的,分类错误的示例上。Focal loss使一级检测器可以达到两级检测器相当的精度,同时保持非常高的检测速度。(COCO mAP @ .5 = 59.1%,mAP @ [。5,.95] = 39.1%)。
![]()
![]()
上式即为Retinanet在损失函数上的贡献,CE为普通的交叉熵函数,可以看到Focal loss加上了一个权重,这个权重在样本为正样本(前景)时大,样本为负样本(背景)时较小。以此缓解了单阶段检测器中前景-背景极度不均衡的问题。
目标检测最新进展
在上一章节,我们介绍了目标检测历程发展中里程碑式的算法,在这一章节我们将介绍一部分近三年在该领域上的一些state-of-art的算法和新思路。
更好的特征提取网络
近年来,深层CNN在许多计算机视觉任务中发挥了核心作用。 由于检测器的精度在很大程度上取决于其特征提取网络,因此在本文中,我们指的是骨干网络,例如 ResNet和VGG,作为检测器的“引擎”。 在本节中,我们将介绍深度学习时代的一些重要检测引擎。
AlexNet[16]:AlexNet是八层深度网络,是第一个CNN模型,它引发了计算机视觉的深度学习革命。 AlexNet赢得了2012年ImageNet LSVRC-2012竞赛的冠军[15.3%VS 26.2%(第二名)的错误率]。截至2019年2月,Alexnet论文已被引用超过30,000次。
VGG[17]:VGG由牛津视觉几何小组(VGG)于2014年提出。 VGG将模型的深度增加到16-19层,并使用了非常小的(3x3)卷积过滤器,而不是以前在AlexNet中使用的5x5和7x7。 VGG在当时的ImageNet数据集上达到了最先进的性能。
GoogLeNet[18]:GoogLeNet,又名Inception,是Google Inc.自2014年以来提出的CNN模型大家族。GoogLeNet增加了CNN的宽度和深度(最多22层)。 Inception系列的主要贡献是引入了分解卷积和批量归一化。
ResNet[19]:深度残留网络(ResNet),由K. He等人提出。是2015年推出的一种新型卷积网络架构,比以前使用的卷积网络架构要深得多(最多152层)。 ResNet旨在通过重新构造网络的层以参考层输入来学习残差函数,从而简化网络的培训。 ResNet在2015年赢得了多个计算机视觉竞赛,包括ImageNet检测,ImageNet本地化,COCO检测和COCO分割。
DenseNet[20]:DenseNet由G. Huang和Z. Liu等人提出。在2017年.ResNet的成功表明CNN中的快捷连接使我们能够训练更深,更准确的模型。作者接受了这一观察,并引入了紧密连接的块,该块以前馈的方式将每一层连接到其他每一层。
SENet[21]:挤压和激发网络(SENet)由J. Hu和L. Shen等人提出。它的主要贡献是集成了全局池化和转换,以学习特征图在通道方面的重要性。 SENet在ILSVRC 2017分类竞赛中获得第一名。
2.2更好的定位方法
为了提高定位精度,最近的检测器有两种方法:1)边界框优化,以及2)设计新的损失函数以进行精确定位。
2.2.1 边界框优化
提高定位精度的最直观的方法是边界框优化,可以将其视为检测结果的后处理。 尽管边界框回归已集成到大多数现代对象检测器中,但是仍然存在一些具有意外比例的对象,这些对象无法通过任何预先定义的锚点很好地捕获。 这将不可避免地导致对其位置的不准确预测。 由于这个原因,“迭代边界框修正”最近被引入,方法是将检测结果迭代地馈入边界框回归器,直到预测收敛到正确的位置和大小。 但是,也有研究者声称这种方法不能保证定位精度的单调性,换言之,如果边界框回归多次使用,可能会使定位退化。
定位损失函数的改进
在大多数现代检测器中,对象定位被视为坐标回归问题。但是,这种范例有两个缺点。首先,回归损失函数与定位的最终评估不符。例如,我们无法保证降低回归误差将始终产生更高的IoU预测,尤其是当对象具有较大的观测比时。其次,传统的边界框回归方法没有提供本地化的信心。当多个BB之间相互重叠时,这可能会导致非最大抑制失败。通过设计新的损耗函数可以缓解上述问题。最直观的设计是直接使用IoU作为定位损失函数。其他一些研究人员进一步提出了IoU指导的NMS,以改善训练和检测阶段的定位。此外,一些研究者还尝试在概率推断框架下改善定位。与直接预测框坐标的先前方法不同,此方法可预测边界框位置的概率分布。
基于无锚框的网络设计
自从锚框在2015年的Faster RCNN中被提出,便逐渐成为了所有检测器的必备组件。但基于锚框的网络也有一些缺点:锚框的超参数太多(锚框大小、尺寸、数量等)难以调参,锚框带来的交并比计算代价是巨大的。所以有不少学者钻研于基于无锚框的研究,以下两篇论文都出自于今年的CVPR,他们在取得了较高准确率的情况下为我们提供了一些新思路。
FSAF用于尺度选择
FSAF(Feature Selective Anchor-Free Module for Single-Shot Object Detection)[13]是一个基于无锚框的模块,可以在所有基于FPN的目标检测网络中使用(在论文中使用在了Retinanet上)。由前面章节可知,在FPN网络中把特征图分成了多层,然后根据真实框的大小来确定该框要被送往哪一层。这样的选择是启发式的,根据经验来选择并不科学。于是作者提出了如下问题:为什么不让网络自己选择合适的层来进行训练呢?基于此,作者设计了一个基于无锚框的分支网络来让网络自己选择每一个锚框应该处在的层。
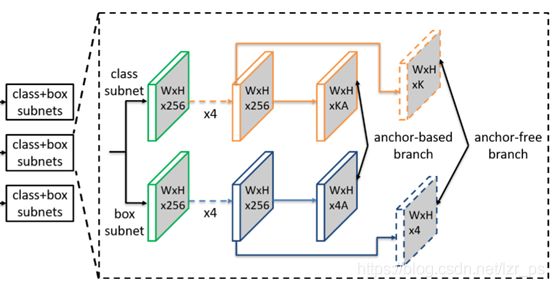
图2-1 FSAF网络的分支网络结构
由上图可知,作者在原来Retinanet的结构上增加了两个无锚框分支来模拟特征图尺度的选择。在反向传播时,选择损失最小的特征图进行反向传播。这样,在检测时,最适合的特征图所得到的目标框的置信度就会越高。
在实验中,该模块能显著的增加小目标被检测出来的概率,但是在精度表现上没有显著的提高(COCO mAP=42.8%)。
FCOs
不同于FSAF,FCOs(Fully Convolutional One-Stage Object Detection)[14]是一个完全脱离了锚框限制的基于全卷积的目标检测网络。其与锚框网络最大的不同之处在于,FCOs是基于像素进行检测(回归的是四条边离像素的距离和像素的类别)。

图2-2 FCOs网络结构图
如图,该架构还是保留了目标检测中最流行的特征金字塔主干网络+分支网络的架构。为了解决离目标中心过远的像素造成的低精度问题,作者平行于分类分支设计了center-ness分支使得离中心越近的点置信度越高,最终取得了不错的精度(COCO 44.7%)。
总结与展望
总结
在过去的20年中,在目标检测方面取得了显著成就。 本文不仅广泛回顾了一些里程碑式检测器(例如Faster-RCNN,YOLO,SSD等),关键技术,加速方法,还探讨了关于一些近年论文的新思路、社区当前面临的挑战,以及如何进一步扩展和改进这些检测器。
展望
目标检测的未来研究可能集中在但不限于以下几个方面:
轻量级物体检测:加快检测算法,使其能够在移动设备上平稳运行。一些重要的应用包括移动增强现实,智能相机,人脸检测等。尽管近年来已付出很大的努力,但机器和人眼之间的速度差距仍然很大,尤其是在检测一些小物体时。
弱监督检测:基于深度学习的检测器的训练通常依赖于大量标注良好的图像。注释过程耗时,昂贵且效率低下。开发弱监督检测技术,其中仅对检测器进行图像级注释训练,或者对检测器仅进行边界框注释训练,这对降低人工成本和提高检测灵活性非常重要。
小物体检测:在大型场景中检测小物体将面临长期挑战。该研究方向的潜在应用包括利用遥感图像对野生动物的种群进行计数并检测一些重要军事目标的状态。其他一些方向可能包括视觉注意机制的集成和高分辨率轻量级网络的设计。
视频中的检测:高清视频中的实时对象检测/跟踪对于视频监控和自动驾驶至关重要。传统的物体检测器通常设计用于图像检测,而只是忽略了视频帧之间的相关性。通过探索时空相关性来改善检测是重要的研究方向。
多模态融合的检测:具有多种数据源/模态(例如RGB-D图像,3d点云,LIDAR等)的对象检测对于自动驾驶和无人机应用非常重要。
一些悬而未决的问题包括:如何将训练有素的检测器迁移到不同的数据形式,如何进行信息融合以改善检测等。站在技术发展的高速路上,我们相信本文将帮助读者大致了解物体检测以及该快速发展研究领域的未来方向。