一、爬虫的目标
网址:http://www.gdgpo.gov.cn/queryMoreInfoList/channelCode/0008.html
这是广东省政府采购网公布的中标公告,网站如下:
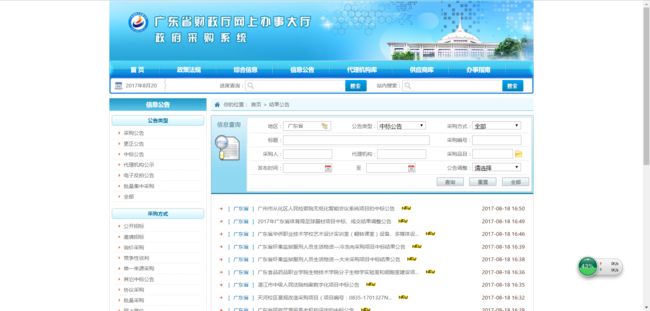
我们要进入具体的公告中,爬一下内容:

将红色框里的数据整理表格形式。
二、分析网站
具体爬虫之前分析一下网站,决定如何进行爬虫。
翻页
留意一下,我们进入该网站后,点击跳转到第2页或别的页,可以发现浏览器的网址框中的网址是一样的。我们用控制台看一下,可以发现,页数的跳转是用JavaScript处理的,如下图:

所以,我们不能直接借助网址跳到不同的页数去,我想到的办法是借助Python的selenium包。它可以借助浏览器,模拟鼠标操作,待JavaScript处理完后再获取网页源码。
标题链接
通过看网页源码,其实发现源码是很清晰的,可以直接爬到链接。

这个网址看得出来是个相对路径,我们进去之后可以在浏览器看到完整路径。
具体内容
通过看网页源码,要爬的内容在源码中也都有了。

小结
小结一下,这次的爬虫难点主要在于翻页,中间过程要爬的标题链接和最终要爬的具体内容,都可以用一般的爬虫方法得到。
所以,爬虫的思路是:
- 借助selenium实现翻页;
- 翻页过程中把标题链接爬下来;
- 循环进入各个公告,把要爬的具体数据爬下来。
三、编程
先把要引用的包引用进来:
import urllib.request
import re
from selenium import webdriver
import csv
实现翻页
首先,使用selenium打开网站。
url = 'http://www.gdgpo.gov.cn/queryMoreInfoList/channelCode/0008.html'
browser = webdriver.Firefox() # 使用Firefox浏览器
browser.set_page_load_timeout(5)
browser.get(url) # 打开指定网站
browser.maximize_window() # 最大化浏览器窗口
注意:使用selenium打开浏览器时,需要在电脑上装一个浏览器的驱动。网页会跳转提示,根据提示下载安装即可!
然后,锁定源码中<下一页>按钮的位置。<下一页>按钮的标签比较难以确定位置,在这里我使用find_element_by_xpath()函数,来确定位置。至于该按钮的xpath,我们可以借助chrome直接复制出来。

完善修改代码:
url = 'http://www.gdgpo.gov.cn/queryMoreInfoList/channelCode/0008.html'
browser = webdriver.Firefox() # 使用Firefox浏览器
browser.set_page_load_timeout(5)
browser.get(url) # 打开指定网站
browser.maximize_window() # 最大化浏览器窗口
# 经对比发现,第一页和其他页中的<下一页>按钮的xpath不一致
# 首先点击第一页中的<下一页>按钮
browser.find_element_by_xpath("//*[@id='contianer']/div[3]/div[2]/div[3]/div/form/a[8]/span").click()
# 这里点击其余页中的<下一页>按钮
for i in range(1): # 写一个循环,翻多少页就循环多少次
browser.find_element_by_xpath("//*[@id='contianer']/div[3]/div[2]/div[3]/div/form/a[10]/span").click()
注意:第一页和其余页的<下一页>按钮的xpath不一样,需要留意一下!
爬取标题链接
首先,写一个爬取标题链接的函数:
# 获取标题链接
def getConn(html):
# 利用正则表达式匹配网页内容找到标题地址
reg = r'(/showNotice/id/[^s]*?html)'
imgre = re.compile(reg)
imglist = re.findall(imgre, str(html)) # 找出匹配的内容,即链接
return imglist
这只是一个函数,我们结合之前写好的翻页的代码,爬一下前两页的标题链接,看看效果:
# 获取标题链接
def getConn(html):
# 利用正则表达式匹配网页内容找到标题地址
reg = r'(/showNotice/id/[^s]*?html)'
imgre = re.compile(reg)
imglist = re.findall(imgre, str(html)) # 找出匹配的内容,即链接
return imglist
url = 'http://www.gdgpo.gov.cn/queryMoreInfoList/channelCode/0008.html'
browser = webdriver.Firefox() # 使用Firefox浏览器
browser.set_page_load_timeout(5)
browser.get(url) # 打开指定网站
browser.maximize_window() # 最大化浏览器窗口
list = []
link = getConn(browser.page_source) # 爬取标题链接,browser.page_source是网页源代码
list.append(link)
# 经对比发现,第一页和其他页中的<下一页>按钮的xpath不一致
# 首先点击第一页中的<下一页>按钮
browser.find_element_by_xpath("//*[@id='contianer']/div[3]/div[2]/div[3]/div/form/a[8]/span").click()
link = getConn(browser.page_source)
list.append(link)
for item in list:
for link in item:
print(link)
运行结果为:

爬取具体的目标数据
前文已经说了,每一篇公告的网址都是由http://www.gdgpo.gov.cn加上爬到的标题链接组合起来。简单来说,我们可以通过直接输入网址访问每一篇公告。
对于这种情况,我选择使用urllib就足够了。毕竟selenium还需要打开浏览器,相对来说比较麻烦的,而且进入的网页如果有数百上千个,总不好在浏览器打开数百上千个标签页吧!这样做,费时不讨好。
所以,爬取具体的目标数据,我们使用urllib就足够了。
首先,写一个获取网页源码的函数:
# 获取网页源代码
def getHtml(url):
page = urllib.request.urlopen(url)
html = page.read()
html = html.decode('utf8') # 网页源码有中文,转码匹配
return html
接下来,我们把翻页和爬取标题链接封装成一个函数,将标题链接存进一个数组返回:
# 获取标题链接
def getConn(html):
# 利用正则表达式匹配网页内容找到标题地址
reg = r'(/showNotice/id/[^s]*?html)'
imgre = re.compile(reg)
imglist = re.findall(imgre, str(html)) # 找出匹配的内容,即链接
return imglist
# 使用浏览器翻页抓取标题链接
def getList(url):
list = []
browser = webdriver.Firefox() # 使用Firefox浏览器
browser.set_page_load_timeout(5)
browser.get(url) # 打开指定网站
browser.maximize_window() # 最大化浏览器窗口
link = getConn(browser.page_source) # 爬取标题链接,browser.page_source是网页源代码
list.append(link)
# 经对比发现,第一页和其他页中的<下一页>按钮的xpath不一致
# 首先点击第一页中的<下一页>按钮
browser.find_element_by_xpath("//*[@id='contianer']/div[3]/div[2]/div[3]/div/form/a[8]/span").click()
link = getConn(browser.page_source)
list.append(link)
# 这里点击其余页中的<下一页>按钮
for i in range(1): # 写一个循环,翻多少页就循环多少次
browser.find_element_by_xpath("//*[@id='contianer']/div[3]/div[2]/div[3]/div/form/a[10]/span").click()
link = getConn(browser.page_source)
list.append(link)
return list
通过上述函数,获取标题链接,写一个函数,爬取具体数据,存进csv文件:
# 根据标题链接,进入页面爬取所需数据
def getData(url):
list = getList(url) # 获取标题链接
str1 = 'http://www.gdgpo.gov.cn'
for item in list:
for link in item:
data = []
url_link = str1+link # 拼接网址
html_link = getHtml(url_link)
# 正则表达式匹配采购项目名称
xre = re.compile(r'(]+[^<]+[^>]+[^;]+[^&]+[^;]+;([^&]+)' # 匹配法人代表
r'[^>]+[^<]+[^>]+[^;]+[^&]+[^;]+;([^&]+)') # 匹配地址
try:
data2 = re.search(yre, str(html_link)).group(3)
data3 = re.search(yre, str(html_link)).group(4)
data4 = re.search(yre, str(html_link)).group(5)
data.append(data2)
data.append(data3)
data.append(data4)
except:
pass
# 数据已经存进data,用a+模式打开csv文件,可以添加data数据进去,不覆盖原数据
with open("yang.csv", "a+", newline="") as datacsv:
# dialect为打开csv文件的方式,默认是excel,delimiter="\t"参数指写入的时候的分隔符
csvwriter = csv.writer(datacsv, dialect=("excel"))
# csv文件插入一行数据,把下面列表中的每一项放入一个单元格(可以用循环插入多行)
csvwriter.writerow(data)
注意:写正则表达式的时候,有些地方是需要匹配中文的,在获取网页源码函数里面,我已经转码为utf8,所以写正则表达式的时候要把中文转成Unicode编码。
另外,这里要多说一句,我的正则表达式真的是渣渣水平,所以写得很长很不好看很不舒服。各位看官要是看不下去了,自己修改一下。[捂脸]
至此,这个函数写完了,调用这个函数就可以把数据爬下来了,可以得到一个csv文件,我们可以用Excel打开,就是表格的形式。
完整版代码
#!/usr/bin/env python
# -*- coding:utf-8 -*-
"""
@File:yang.py
@Time:2017/8/17 23:20
@Author:lgsen
"""
import urllib.request
import re
from selenium import webdriver
import csv
# 获取网页源代码
def getHtml(url):
page = urllib.request.urlopen(url)
html = page.read()
html = html.decode('utf8') # 网页源码有中文,转码匹配
return html
# 获取标题链接
def getConn(html):
# 利用正则表达式匹配网页内容找到标题地址
reg = r'(/showNotice/id/[^s]*?html)'
imgre = re.compile(reg)
imglist = re.findall(imgre, str(html)) # 找出匹配的内容,即链接
return imglist
# 使用浏览器翻页抓取标题链接
def getList(url):
list = []
browser = webdriver.Firefox() # 使用Firefox浏览器
browser.set_page_load_timeout(5)
browser.get(url) # 打开指定网站
browser.maximize_window() # 最大化浏览器窗口
link = getConn(browser.page_source) # 爬取标题链接,browser.page_source是网页源代码
list.append(link)
# 经对比发现,第一页和其他页中的<下一页>按钮的xpath不一致
# 首先点击第一页中的<下一页>按钮
browser.find_element_by_xpath("//*[@id='contianer']/div[3]/div[2]/div[3]/div/form/a[8]/span").click()
link = getConn(browser.page_source)
list.append(link)
# 这里点击其余页中的<下一页>按钮
for i in range(1): # 写一个循环,翻多少页就循环多少次
browser.find_element_by_xpath("//*[@id='contianer']/div[3]/div[2]/div[3]/div/form/a[10]/span").click()
link = getConn(browser.page_source)
list.append(link)
return list
# 根据标题链接,进入页面爬取所需数据
def getData(url):
list = getList(url) # 获取标题链接
str1 = 'http://www.gdgpo.gov.cn'
for item in list:
for link in item:
data = []
url_link = str1+link # 拼接网址
html_link = getHtml(url_link)
# 正则表达式匹配采购项目名称
xre = re.compile(r'(]+[^<]+[^>]+[^;]+[^&]+[^;]+;([^&]+)' # 匹配法人代表
r'[^>]+[^<]+[^>]+[^;]+[^&]+[^;]+;([^&]+)') # 匹配地址
try:
data2 = re.search(yre, str(html_link)).group(3)
data3 = re.search(yre, str(html_link)).group(4)
data4 = re.search(yre, str(html_link)).group(5)
data.append(data2)
data.append(data3)
data.append(data4)
except:
pass
# 数据已经存进data,用a+模式打开csv文件,可以添加data数据进去,不覆盖原数据
with open("yang.csv", "a+", newline="") as datacsv:
# dialect为打开csv文件的方式,默认是excel,delimiter="\t"参数指写入的时候的分隔符
csvwriter = csv.writer(datacsv, dialect=("excel"))
# csv文件插入一行数据,把下面列表中的每一项放入一个单元格(可以用循环插入多行)
csvwriter.writerow(data)
# 主程序
if __name__=="__main__":
url = 'http://www.gdgpo.gov.cn/queryMoreInfoList/channelCode/0008.html'
getData(url)
四、总结
我不是专门写爬虫的,编程水平也不高,看我的代码就知道了[捂脸]。就是这次爬虫用到了selenium这个包,感觉有点意思,就分享一下过程。
很多东西都是在网络上现查现用,并没有认真去理解。甚至有的代码是复制过来的,变量名都没改,如imglist,大家看看笑笑就好了。就爬虫而言,这次的难度并不高,感觉就新手练手的程度。毕竟,我就是个新手嘛!
最后,想提一下,其实有些公告里,中标供应商是有好几个,并不只有一个,我写的代码只是爬取了第一个,大家有兴趣可以自己去解决这个问题。重在学习嘛!