一、开头
Java是一种强类型的语言,这意味着必须为每一个变量声明一种类型
Java中一共有8种基本数据类型(整形有4种,浮点型有2种,字符型1种,还有一种布尔类型)
由于Java程序必须保证在所有机器上都能得到相同的运行结果,所以各种数据类型的取值范围必须是固定的
二、整形
整形共有4种
- byte:一个字节
- short:2个字节
- int:4个字节(刚好超过二十亿)
- long int:8个字节
这里要注意的一些地方是
- 长整形数值有一个后缀L或者l
- 十六进制数值有一个前缀0x或者0X
- 八进制有一个前缀0(容易混淆,不推荐使用)
- 从Java7(JDK1.7)开始可以使用0b或者0B写二进制
- 从JAVA7开始,还可以为数字字面量加下划线,如使用1_000_000表示100W(Java编译器会去除这些下划线)
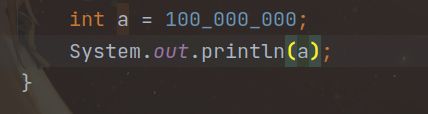
开头已经说了,各种数据类型的取值范围必须是固定的,所以4种整形的范围都为有符号位的范围,Java也因此没有Unsigned符号。
所以针对Unsigned的整形,基本数据类型的包装类有对应的API的
这里首先要认识的一点是,只要不溢出,加法、减法和乘法都能正常计算,但除法是会出问题的
三、Byte.toUnsignedInt
这个API的功能是针对Unsigned的Byte的转化成Unsigned

从源码上看,其实就是将其强制转换成int,相当于扩大了位数,然后通过与上0xff,0xff是十六进制,转化成二进制就是11111111,这个与运算的作用其实为了限制位数,因为byte是1个字节,顶多只有8位,超过8位的那些都不要,对于Unsigned来说,应该都为0.
四、Integer.divideUnsigned
这个API的功能是针对Unsigned的int类型除法的


可以看到,他的处理与Byte一样,都是转化成更高位的类型,这里转化成long,然后通过与运算舍弃后面多出来的位数(其实是改为0)
五、Integer.remainderUnsigned
这个是用来求余数的

可以看到同样也是转化成更高位去处理
六、Long.divideUnsigned
现在Long没有更高位了怎么办呢?
下面是源码
public static long divideUnsigned(long dividend, long divisor) {
//divisor是除数
//而divident是被除数
//首先判断除数是否为Unsigned(<0就代表为unsigned,只不过将符号位看成1,变为负数)
if (divisor < 0L) { // signed comparison
// Answer must be 0 or 1 depending on relative magnitude
// of dividend and divisor.
//可以看到这里的返回值只有0和1
//这是因为除数为unsigned,根据整形的向下取整规则
//得到的结果只能为1和0(dividend大于divisor就为1,小于就为0)
//dividend不可能为divisor的两倍(因为位数不过)
return (compareUnsigned(dividend, divisor)) < 0 ? 0L :1L;
}
//如果除数不是Unsigned,那么就判断被除数
if (dividend > 0) // Both inputs non-negative
//如果被除数不是Unsigned,就直接除就好
return dividend/divisor;
else {
/*
* For simple code, leveraging BigInteger. Longer and faster
* code written directly in terms of operations on longs is
* possible; see "Hacker's Delight" for divide and remainder
* algorithms.
*/
//如果是,那么就将除数和被除数换成更高位的BigInt型,去进行
return toUnsignedBigInteger(dividend).
divide(toUnsignedBigInteger(divisor)).longValue();
}
}
下面我们就来看看compareUnsigned方法


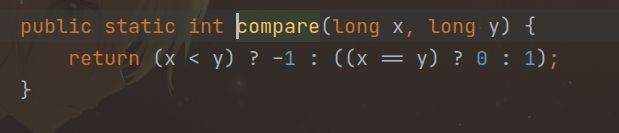
MIN_VALUE是代表长整形可以取的最小值,也就是 − 2 63 -2^{63} −263
可以看到,具体的过程就是让两个数减去最小值,然后进行比较
原理是,即使是Unsigned,只要减去了最小值,就不会超过有符号位的范围,然后通过比较减去后的大小,就可以判断除数和被除数谁大谁小,然后就返回0和1。
七、浮点型
浮点型有两种类型,一种为float,一种为double。
这里,我们认识一下精度损失
在两种浮点型,小数都是使用二进制表示的,比如 2 − 1 或 者 2 − 2 2^{-1}或者2^{-2} 2−1或者2−2,也就是0.5,0.125这些,也就是说,有一些小数是无法使用二进制表示的,只能通过后面的位数进行无限逼近,所以就会产生精度损失。
那什么是双精度和单精度呢?
这是根据double和float的位数来区分的,double为8字节,而float为4字节,所以double可以使用更多位数进行逼近,所以double会更加精确。
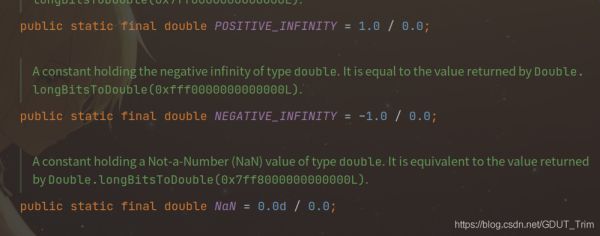
这里要注意的是,所有的浮点数计算都遵循IEEE754规范
对于表示溢出和出错情况,使用了三个特殊的浮点数值去表示
- 正无穷大
- 负无穷大
- NaN(不是一个数字)
八、字符型
char类型本来用来表示单个字符,但如今有些Unicode字符可以用一个char表示,也就是两个字节,但有时一些Unicode字符需要用多个字节表示,也就是使用多个char表示
char类型的值可以表示为十六进制值,从\u0000~\uffff。这里是\u充当了一个转义序列的功能,同时\u转义序列是可以出现在字符常量或字符串,所以使用注释和参数的时候,要注意一下
在Java中,char类型描述了UTF-16编码中的一个代码单元
九、Unicode
在认识UTF-16前,我们需要认识Unicode
Unicode其实相当于一本很厚的字典,里面储存了世界上所有语言的字符,使用Unicode码点唯一地对应一个字符。
Unicode是没有规定字符对应的二进制码占用的空间是多少,那么问题来了,以“汉”字为例,它的Unicode码点为0x6c49,对应的二进制为110110001001001,也就是15位二进制,也就说明了,这个字需要用2个字节去存储这个字,那么,对于其他字体,很有可能出现3个字节,或者更多的字节去存储,对于计算机来说,计算机怎么知道这两个字节表示的是一个字符,而不是与后面的字节形成一个字符?
所以,为了解决Unicode的这个问题,新的编码方式UTF-8、UTF-16和UTF-32就出现了
十、UTF-8
UTF其实是Unicode Transformation Format的缩写,即统一Unicode编码转换格式
UTF-8的特点就是可变长,即对于不同长度字节的字符有很好的兼容性
编码规则如下
对于单个字节的字符(也就是基本字符),也就是8位,会将第一位设为0,后面的七位会对应这个字符的Unicode码点,因此对于0~ 2 7 2^7 27号字符是完全可以的,甚至与ASCII(另一种编码方式,只不过不支持中文只有英文和符号)完全相同(这时候可能会有人说那么对于 2 8 至 2 7 2^8至2^7 28至27里面的字符呢?其实这一段被分在了使用2个字节表示)
对于需要使用N个字节来表示的字符(N>1),第一个字节的前N位都设为1,第N+1位设为0(用来记录这个字符是用多少个字节来存储的,让计算机可以识别出),剩余后面的N-1个字节的前两位都要设置为10,剩下的二进制位则使用这个字符的Unicode码点来进行补充
| Unicode十六进制码点范围 | UTF-8二进制 |
| 0000 0000 ~ 0000 007F(注意这里只有7位) | 0xxxxxxx(对应表示码点的七位) |
| 0000 0080 ~ 0000 07FF(注意这里为11位) | 110xxxxx 10xxxxxx (对应码点11位) |
| 0000 0800 ~ 0000 FFFF(注意这里位16位) | 1110xxxx 10xxxxxx 10xxxxxx(对应码点16位) |
| 0001 0000 ~ 0010 FFFF(这里为18位) | 11110xxx 10xxxxxx 10xxxxxx 10xxxxxx(虽然超过码点位数,但不影响表示) |
0000 0800 ~ 0000 FFFF(注意这里位16位)1110xxxx 10xxxxxx 10xxxxxx(对应码点16位)0001 0000 ~ 0010 FFFF(这里为18位)11110xxx 10xxxxxx 10xxxxxx 10xxxxxx(虽然超过码点位数,但不影响表示)
通过表格,可以看到UTF-8d的编码其实很简单,下面还是以"汉"为例,具体说一下如何进行UTF-8的编码和解码的
汉的编码为0x00006c49,对应在Unicode十六进制码点范围的第三行,所以对应的UTF-8二进制为 1110 x x x x 10 x x x x x x 10 x x x x x x 1110xxxx 10xxxxxx 10xxxxxx 1110xxxx10xxxxxx10xxxxxx,然后将0x0006c49变为二进制为0x0110110001001001,然后填入到x里面即可(从第最后一位开始),结果为111001101011000110001001,然后再转换成十六进制为:0xE6 0xB7 0x89
解码的过程也十分简单:专为二进制之后,先判断多少个字节,如果第一个字节的第一位是0,则代表是只有1和字节,如果不是,就判断前面总共有多少个1就碰到0,多少个1就是多少个字节,通过知道多少个字节,就可以知道后面要读多少个字节来对应这个字符,只要去掉开头的10就行
十一、UTF-16
在认识UTF-16之前,先认识平面这个东西
前面提到过Unicode编码是一本很厚的字典,将全世界的字符都定义在这个集合里面,但这本字典不是一次性完成的,而是经过持续地收集才完成的,所以也就产生了分区,进行分区定义。每个区可以存放65536,也就是2^16字符,一个区就称为一个平面。目前Unicode一共有17(2 ^ 4+1)个平面(剩余16个为辅助平面),所以整个Unicodez字符集大小为 2 21 2^{21} 221
第一个平面,也就是第一个区,被称为基本平面,前 2 16 2^{16} 216个字符也就被成为基本字符,码点范围也就是从0~ 2 16 − 1 2^{16}-1 216−1,写成十六进制就是从U+0000到U+FFFF,最常见的字符大多都在这个区了。那么剩余的17个区,对应的码点就是从U+10000到U+10FFFF(刚好16倍),那么要如何解决确定字符与字节对应的问题呢?
基本平面有一个很巧妙的地方,在基本平面内,从U+D800到U+DFFF是一个空段,也就是再这个区间内的码点是没有对应任何字符的,因此UTF-16就利用了这个空段来做了一个映射辅助平面的码点(利用基本平面来储存辅助平面)
在辅助平面码点对应的字符总共有 2 20 2^{20} 220个,所以至少需要20个二进制位才可以完全对应辅助平面码点的字符。
UTF-16将这20个二进制位分成一半,前十位映射在U+D800到U+DBFF之间(称为高位),后10位映射在U+DC00到U+DFFF之间(成为低位),所以当遇到多个字节时,如果发现有码点位于这两个段区间,这就意味着这是辅助平面码点的映射,辅助平面字符被拆分成多个基本平面的码点表示。
据个栗子
汉字"?“的 Unicode 码点为 0x20BB7,该码点显然超出了基本平面的范围(0x0000 - 0xFFFF),因此需要使用四个字节表示。首先用 0x20BB7 - 0x10000 计算出超出的部分,然后将其用 20 个二进制位表示(不足前面补 0 ),结果为0001000010 1110110111。接着,将前 10 位映射到 U+D800 到 U+DBFF 之间,后 10 位映射到 U+DC00 到 U+DFFF 即可。U+D800 对应的二进制数为 1101100000000000,直接填充后面的 10 个二进制位即可,得到 1101100001000010,转成 16 进制数则为 0xD842。同理可得,低位为 0xDFB7。因此得出汉字”?"的 UTF-16 编码为 0xD842 0xDFB7
现在我们回到字符型里面的重点在Java中,char类型描述了UTF-16编码中的一个代码单元,可以知道char类型采用的是utf-16编码方式,代码单元其实指的就是U+D800~U+DBFF和U+DC00~U+DFFF这两个映射区(这里是两个个代码单元,一个char只能使用一个代码单元,不过通常一个代码单元能表示绝大多数的字符了,但也是因为这个原因,有些字符char不可以完整表示),通过这个代码单元,就可以进行解码获取Unicode编码了
十二、布尔类型
boolean类型有两个值,false和true,用来判断逻辑条件,整形值和布尔值之间是不能互换的。
到此这篇关于Java数据类型之细讲char类型与编码关系的文章就介绍到这了,更多相关Java char类型与编码关系内容请搜索脚本之家以前的文章或继续浏览下面的相关文章希望大家以后多多支持脚本之家!