Mysql慢查询
select COUNT(a.id) ucount from table_a a
left join table_b b1 on a.userId1=b1.id
left join table_b b2 on a.userId2=b2.id
left join table_b b3 on a.userId3=b3.id
where a.add_time >= '2015-06-01 00:00:00' and a.add_time <= '2017-04-06 23:59:59'
# 这条sql语句耗时0.11s。
首先b表并不参与筛选条件,去除left join。
select COUNT(a.id) ucount from table_a a
where a.add_time >= '2015-06-01 00:00:00' and a.add_time <= '2017-04-06 23:59:59';
# 耗时0.03s。
给a表add_time添加索引,但是添加后同样sql查询时间并没有减少。
# 耗时0.03s。
+----+-------------+-------+------+---------------+------+---------+------+-------+-------------+
| id | select_type | table | type | possible_keys | key | key_len | ref | rows | Extra |
+----+-------------+-------+------+---------------+------+---------+------+-------+-------------+
| 1 | SIMPLE | a | ALL | idx_addTime | NULL | NULL | NULL | 73104 | Using where |
+----+-------------+-------+------+---------------+------+---------+------+-------+-------------+
# 执行计划中显示索引是没有用到的。
但是如果我把sql查询条件做修改索引即可用到。
select COUNT(a.id) ucount from table_a a
where a.add_time >= '2017-04-01 00:00:00' and a.add_time <= '2017-04-06 23:59:59';
# 耗时0.00s。
+----+-------------+-------+-------+---------------+-------------+---------+------+------+-------------+
| id | select_type | table | type | possible_keys | key | key_len | ref | rows | Extra |
+----+-------------+-------+-------+---------------+-------------+---------+------+------+-------------+
| 1 | SIMPLE | a | range | idx_addTime | idx_addTime | 8 | NULL | 1625 | Using where |
+----+-------------+-------+-------+---------------+-------------+---------+------+------+-------------+
当查询条件是'2015-06-01 00:00:00' - '2017-04-06 23:59:59' 时会命中a表中大部分数据;在这种情况下,Mysql会放弃使用索引改为全表搜索。
这样处理的原因是如果命中索引大多数数据,那么使用索引会造成大量随机I/O操作,这样是低效的;所以更好的办法是直接全表顺序扫描。
优先队列
Java中我们会经常使用到PriorityQueue(优先队列),那么优先队列内部是如何实现,原理又是什么呢。
一篇很棒的参考文档
堆(英语:Heap)是计算机科学中一类特殊的数据结构的统称。堆通常是一个可以被看做一棵树的数组对象。在队列中,调度程序反复提取队列中第一个作业并运行,因为实际情况中某些时间较短的任务将等待很长时间才能结束,或者某些不短小,但具有重要性的作业,同样应当具有优先权。堆即为解决此类问题设计的一种数据结构。 -- 维基百科
n个元素序列{k1,k2...ki...kn},当且仅当满足下列关系时称之为堆:
(ki <= k2i,ki <= k2i+1)或者(ki >= k2i,ki >= k2i+1), (i = 1,2,3,4...n/2)
堆的实现通过构造二叉堆(binary heap),实为二叉树的一种;由于其应用的普遍性,当不加限定时,均指该数据结构的这种实现。这种数据结构具有以下性质。
- 任意节点小于(或大于)它的所有后裔,最小元(或最大元)在堆的根上(堆序性)。
- 堆总是一棵完全树。即除了最底层,其他层的节点都被元素填满,且最底层尽可能地从左到右填入。
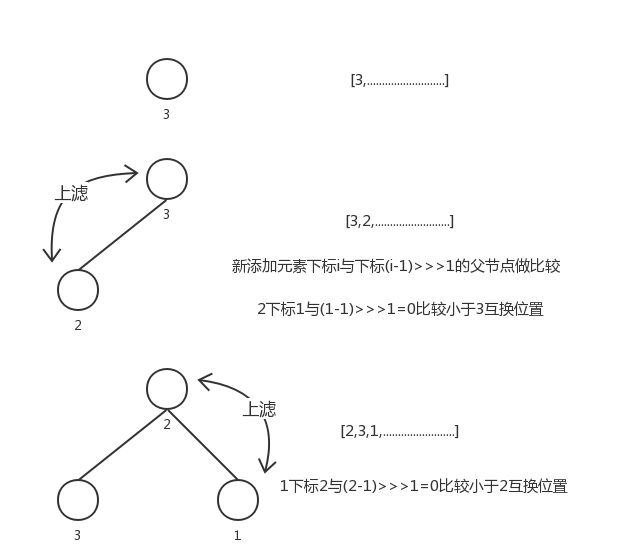
对一个优先队列依次添加3,2,1元素。
Intellij Idea使用
Key Promoter
快捷键总是记住了然后又忘记了,这个插件起了很好的提示作用;当你用鼠标进行某个操作时会提示你如何使用快捷键实现同样的操作。
它会提示你同样的操作该使用什么快捷键来实现,同时告诉你用鼠标执行了多少次。
Cmd + Shift + a
enter action or option name:想知道某个快捷键操作,输入关键字就会提示你。
比如我要找到如何删除行快捷键。
Git
受保护的分支
开发中,如果我们每个开发人员都可以对线上分支进行修改合并,那么可能会导致各种问题;把分支设置为受保护的即可解决这个问题。
Git角色:
| 名称 | 说明 |
|---|---|
| Owner | Git系统管理员 |
| Master | Git项目管理员 |
| Developer | Git项目开发人员 |
| Reporter | Git项目测试人员 |
| Guest | 访客 |
developer开发人员可以在开发完毕后发出Merge Request请求,然后由Master或Owner来审核决定是否通过。
tag标签
在我们发布一个新版本时,对当前版本做一个标记-tag,区别于其它提交。
git tag # 查看标签
git tag -l '1.*' # 搜索以1.开头的所有标签
git tag -a 1.0 -m 'my version 1.0' # 包含备注的标签 指定标签名字 与标签说明
git show 1.0 # 显示指定标签信息
git tag 1.0 # 轻量级标签 没有提交信息
git push origin 1.0/--tags # 推送标签到远程